What is Clustering in Data Mining?

Overview
Clustering in data mining is a technique used to group similar data points together based on their features and characteristics. It is an unsupervised learning method that helps to identify patterns in large datasets and segment them into smaller groups or subsets. Clustering can be used for various applications such as customer segmentation, image recognition, and anomaly detection.
What is Clustering in Data Mining?
Clustering in data mining is a technique that groups similar data points together based on their features and characteristics. It can also be referred to as a process of grouping a set of objects so that objects in the same group (called a cluster) are more similar to each other than those in other groups (clusters). It is an unsupervised learning technique that aims to identify similarities and patterns in a dataset. Clustering algorithms typically require defining the number of clusters, similarity measures, and clustering methods. These algorithms aim to group data points together in a way that maximizes similarity within the groups and minimizes similarity between different groups, as shown in the picture below.
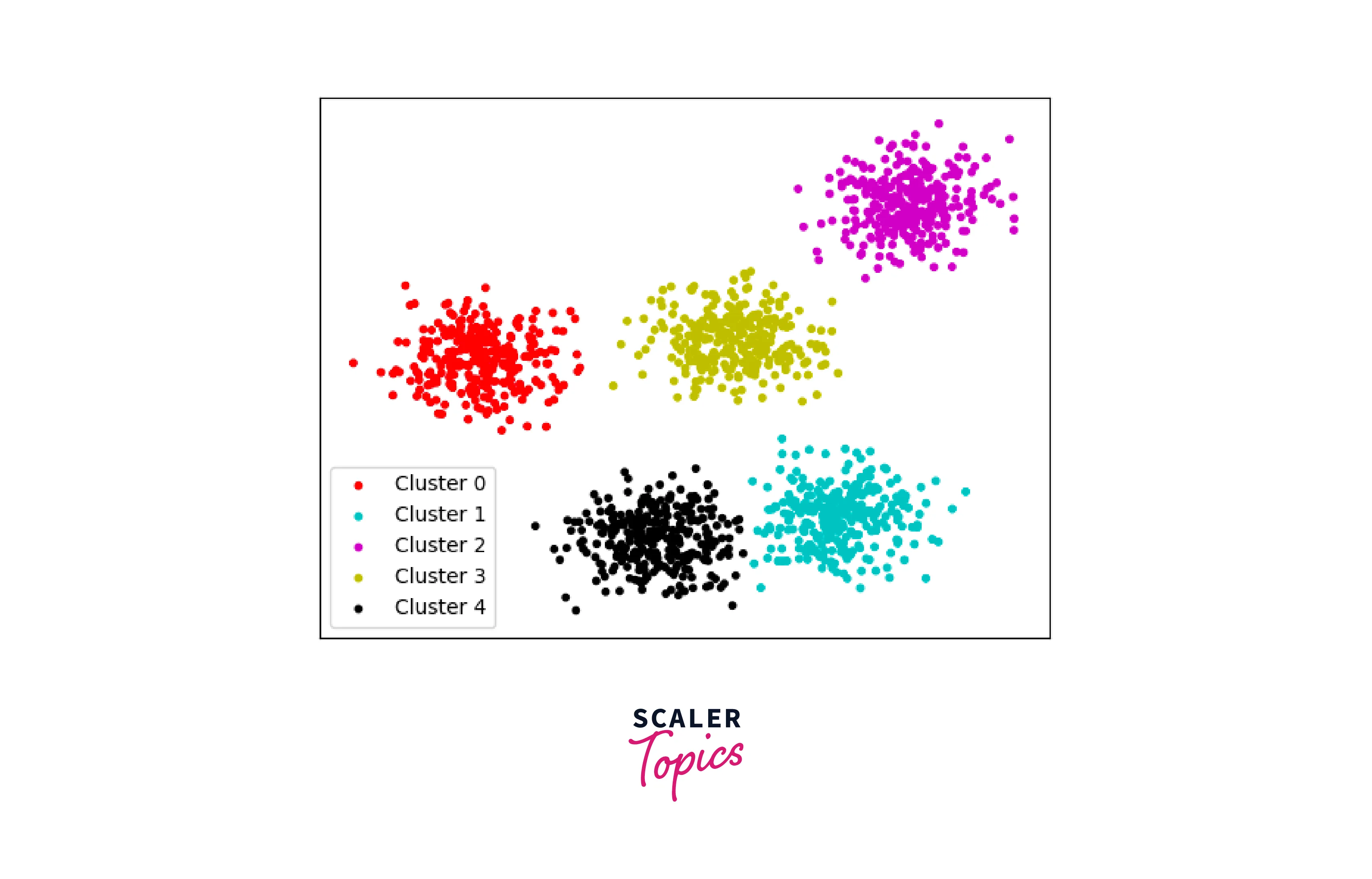
Clustering techniques in data mining can be used in various applications, such as image segmentation, document clustering, and customer segmentation. The goal is to obtain meaningful insights from the data and improve decision-making processes.
What is a Cluster?
In data mining, a cluster refers to a group of data points with similar characteristics or features. These characteristics or features can be defined by the analyst or identified by the clustering algorithm while grouping similar data points together. The data points within a cluster are typically more similar to each other than those outside the cluster. For example, in the above figure, there are 5 clusters present.
A cluster can have the following properties -
- The data points within a cluster are similar to each other based on some pre-defined criteria or similarity measures.
- The clusters are distinct from each other, and the data points in one cluster are different from those in another cluster.
- The data points within a cluster are closely packed together.
- A cluster is often represented by a centroid or a center point that summarizes the properties of the data points within the cluster.
- A cluster can have any number of data points, but a good cluster should not be too small or too large.
Applications of Clustering in Data Mining
Clustering is a widely used technique in data mining and has numerous applications in various fields. Some of the common applications of clustering in data mining include -
- Customer Segmentation
Clustering techniques in data mining can be used to group customers with similar behavior, preferences, and purchasing patterns to create more targeted marketing campaigns. - Image Segmentation
Clustering techniques in data mining can be used to segment images into different regions based on their pixel values, which can be useful for tasks such as object recognition and image compression. - Anomaly Detection
Clustering techniques in data mining can be used to identify outliers or anomalies in datasets that deviate significantly from normal behavior. - Text Mining
Clustering techniques in data mining can be used to group documents or texts with similar content, which can be useful for tasks such as document summarization and topic modeling. - Biological Data Analysis
Clustering techniques in data mining can be used to group genes or proteins with similar characteristics or expression patterns, which can be useful for tasks such as drug discovery and disease diagnosis. - Recommender Systems
Clustering techniques in data mining can be used to group users with similar interests or behavior to create more personalized recommendations for products or services.
Clustering Methods in Data Mining
There are several clustering techniques in data mining, each with its own strengths and weaknesses. Some of the most commonly used clustering techniques in data mining include -
- K-means Clustering
K-means clustering is a partitioning method that divides the data points into k clusters, where k is a pre-defined number. It works by iteratively moving the centroid of each cluster to the mean of the data points assigned to it until convergence. K-means aims to minimize the sum of squared distances between each data point and its assigned cluster centroid. - Hierarchical Clustering
Hierarchical clustering in data mining is a method that builds a tree-like hierarchy of clusters, either by merging smaller clusters into larger ones (agglomerative or bottom-up) or by splitting larger clusters into smaller ones (divisive or top-down). It does not require a pre-defined number of clusters. - Density-Based Clustering
Density-based clustering is a method that identifies clusters based on regions of high density in the data space. Points that are not in any high-density region are considered noise or outliers. The most commonly used density-based clustering algorithm is DBSCAN. - Model-Based Clustering
Model-based clustering is a method that assumes that a probabilistic model, such as a mixture of Gaussian distributions generates the data points. It seeks to identify the model parameters that best fit the data and assigns data points to clusters based on their likelihood under the model. - Fuzzy Clustering
Fuzzy clustering is a method that assigns data points to clusters based on their degree of membership in each cluster. This allows a data point to belong to multiple clusters with different degrees of membership.
Ready to Apply What You've Learned? Our Data Science Courses Provides a Platform for Real-world Practice. Enroll Now!
Why is Clustering Required in Data Mining?
Clustering is a critical technique in the data mining process, and it has various advantages, as mentioned below -
- Scalability
Clustering algorithms in data mining can handle large datasets efficiently, making it possible to extract useful insights and knowledge from massive amounts of data. - High Dimensionality
Clustering algorithms in data mining can efficiently handle high-dimensional datasets, making it possible to find patterns and relationships that may not be apparent in lower dimensions. - Discovery of Clusters with Arbitrary Shape
Clustering algorithms in data mining can discover clusters that have different shapes and sizes, making it possible to identify groups of data points that share common properties or features. - Interpretability
Clustering results can be easily interpreted by humans, making it possible to extract useful insights and knowledge from the data. - Ability to Deal with Different Kinds of Data
Clustering algorithms in data mining can handle different types of data, such as categorical, numerical, and binary, making it possible to cluster a wide range of data types.
FAQs
Q: What is the difference between clustering and classification?**
A: Clustering is an unsupervised learning technique that seeks to group similar data points into clusters without prior knowledge of the class labels. Classification, on the other hand, is a supervised learning technique that seeks to predict the class label of a new data point based on its features.
Q: What are some applications of clustering in real-world scenarios?**
A: Clustering has applications in various fields, such as customer segmentation in marketing, image segmentation in computer vision, anomaly detection in cybersecurity, document clustering in information retrieval, and gene expression analysis in bioinformatics.
Q: What is a cluster in clustering algorithms?**
A: A cluster is a group of data points that are similar to each other in some way, based on a clustering algorithm's similarity metric. A cluster can be considered a collection of data points that share some common characteristics or properties that distinguish them from other data points in the dataset.
Conclusion
- Clustering is a technique in data mining that groups similar data points together based on their similarity. It is used to discover patterns and relationships in large datasets, and it has applications in various fields such as marketing, bioinformatics, and image recognition.
- Clustering algorithms aim to partition the data into clusters such that the data points within a cluster are more similar than data points in other clusters.
- By clustering data, analysts can extract useful insights and knowledge that can be used to improve decision-making, optimize processes, and gain a better understanding of complex systems.