Data Sampling in Data Science

Data Sampling is a key statistical strategy in data science, crucial for analyzing subsets from extensive datasets efficiently. This technique simplifies the process of deriving meaningful conclusions about a larger population, bypassing the exhaustive analysis of every individual entry. It plays an indispensable role in minimizing computational demands and speeding up the generation of actionable insights, making the task of data analysis both time and cost-efficient. Ideal for a wide range of applications, this method underpins the accuracy and relevance of insights in an era overwhelmed by data.
What is Data Sampling?
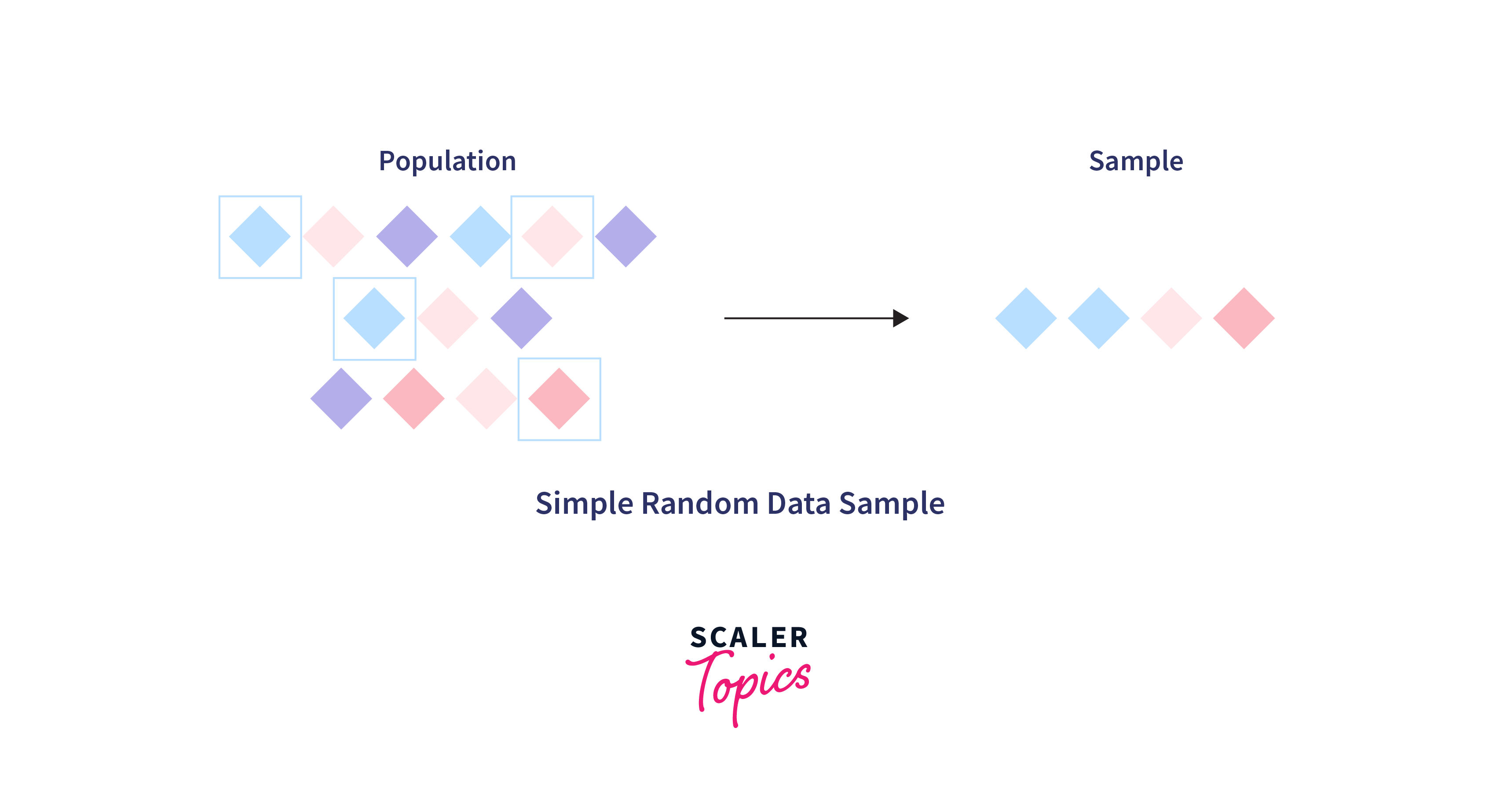
Data Sampling is the process of selecting a subset of individuals, observations, or items from a larger population to estimate the characteristics of the whole group. In data science, it is a crucial technique for handling large datasets, reducing computation time, and obtaining actionable insights quickly. Sampling allows for the analysis of data to be manageable and cost-effective, while still providing accurate estimates of the larger population's properties. This method is foundational in statistical analysis, machine learning model training, and data visualization, ensuring that the insights derived are both relevant and scalable.
Advantages
Data Sampling offers several benefits in data science and statistical analysis, making it a widely used technique across various fields. Here are some key advantages:
-
Efficiency:
Sampling significantly reduces the amount of data that needs to be processed and analyzed, making it possible to obtain results faster and with less computational resources. -
Cost-effectiveness:
Collecting and analyzing a full dataset can be expensive and time-consuming. Sampling reduces these costs by allowing for the analysis of a smaller, manageable subset. -
Feasibility:
In some cases, it's physically impossible or impractical to collect data from the entire population. Sampling provides a practical solution by allowing for the study of a portion of the population. -
Accuracy:
With properly chosen sampling techniques, the results from a sample can accurately reflect the larger population, enabling precise inferences about the population's characteristics. -
Flexibility:
Sampling methods can be adapted to suit different types of data and research questions, making it a versatile tool in the data scientist's toolkit.
Errors in Sample Selection
While data sampling is a powerful tool, it's important to be aware of potential errors that can arise during sample selection. These errors can affect the accuracy and reliability of the analysis. Two primary types of errors include:
-
Sampling Error:
This occurs due to the natural variation in choosing a sample from a population. Even with a well-designed sampling process, the sample may not perfectly represent the entire population's characteristics. The size of the sampling error typically decreases as the sample size increases. -
Non-sampling Error:
These errors arise from sources other than the act of sampling itself and can occur even in a census or a complete enumeration of the population. They include measurement errors, data processing errors, and bias in the way the sample is selected or in the way information is collected from respondents.
Mitigating these errors involves careful planning of the sampling process, including selecting appropriate sampling methods, ensuring accurate data collection and processing techniques, and using statistical adjustments when necessary. Awareness and management of these errors are crucial for maintaining the integrity and reliability of the analysis based on sampled data.
Sampling Process
The sampling process involves several key steps to ensure that the selected sample accurately represents the larger population, minimizing errors and biases. Here's an overview of the standard process:
-
Define the Population:
Clearly identify the entire group of interest from which the sample will be drawn. This includes specifying the characteristics that define membership in the population. -
Choose a Sampling Frame:
The sampling frame is a list or database from which the sample can be drawn. It should closely match the defined population to ensure that every member has a chance of being included in the sample. -
Select a Sampling Method:
Decide on the technique to select individuals or items for the sample. This could be a probability method (e.g., simple random sampling, stratified sampling) where each member has a known chance of being selected, or a non-probability method (e.g., convenience sampling, judgment sampling) where the selection is subjective. -
Determine the Sample Size:
Calculate the appropriate number of observations needed to achieve the desired level of accuracy and confidence in the results. This depends on factors like the population size, the variability of the data, and the margin of error that can be tolerated. -
Execute Sampling:
Carry out the process of selecting individuals or items based on the chosen method and sample size. This step must be conducted carefully to avoid biases and ensure that the sample is representative. -
Collect and Analyze Data:
Once the sample is selected, collect the data from the sample members. After data collection, perform the desired analysis to make inferences about the population based on the sample data. -
Review and Assess for Errors:
Evaluate the sampling process and the collected data for potential sampling and non-sampling errors. Adjustments or corrections may be necessary to ensure the validity of the analysis.
Following these steps in the sampling process helps in obtaining a representative sample, enabling accurate and reliable inferences about the population from the analyzed data.
Data Sampling Techniques
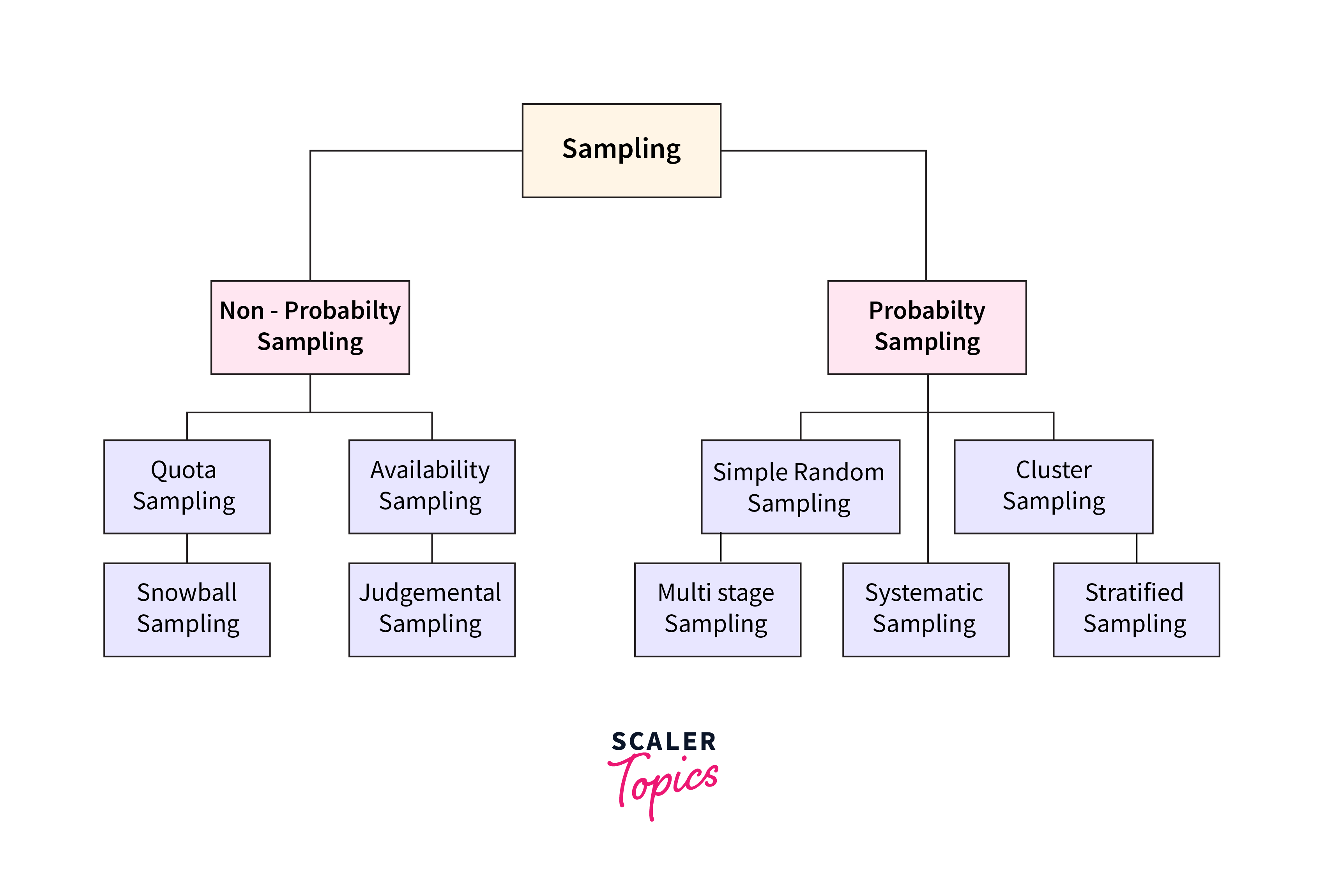
Data sampling techniques can be broadly categorized into two main types: Probability Sampling and Non-Probability Sampling. Each category has different methods suited for various research needs and scenarios, impacting how samples are selected and the types of inferences that can be drawn.
Probability Sampling
In Probability Sampling, every member of the population has a known, non-zero chance of being selected in the sample. This approach ensures that the sample can be considered statistically representative of the population, allowing for generalizations to be made with a measurable level of confidence. Key methods include:
- Simple Random Sampling:
Every member of the population has an equal chance of being selected. - Stratified Sampling:
The population is divided into subgroups (strata) based on shared characteristics, and samples are drawn from each stratum. - Cluster Sampling:
The population is divided into clusters (groups) that are randomly selected, and all or a random selection of members from chosen clusters are included. - Systematic Sampling:
Every nth member of the population list is selected, starting from a random point.
Non-Probability Sampling
Non-probability sampling methods do not provide all members of the population with a known chance of being included. These techniques are often used when it is impractical or impossible to conduct probability sampling. They are less able to support generalizations about the population but are useful in exploratory research and where specific insights or depth is required. Common types include:
- Convenience Sampling:
Samples are selected based on ease of access, often leading to biased results. - Judgmental or Purposive Sampling:
The researcher uses their judgment to select members who are deemed most useful or representative. - Quota Sampling:
The researcher fills quotas from different subgroups, similar to stratified sampling, but without random selection. - Snowball Sampling:
Existing study subjects recruit future subjects from among their acquaintances, often used for hard-to-reach or specialized populations.
Choosing between probability and non-probability sampling methods depends on the research objectives, the nature of the study, the availability of a complete and accurate population list, and time, and budget constraints. Each method has its strengths and limitations, affecting the accuracy, validity, and applicability of the research findings. We will read about these techniques in depth further in this article.
Probability Sampling
Probability sampling is a methodological approach in data science and statistics where each member of the population has a known and equal chance of being selected for the sample. This approach ensures that the sample is representative of the population, allowing for unbiased inferences about the population's characteristics.
Simple Random Sampling
Simple Random Sampling is the most straightforward form of probability sampling, where every member of the population has an equal probability of being included in the sample. This method ensures that each subset of the population has the same chance of selection, providing a fair representation without bias.
Stratified Random Sampling
Stratified Random Sampling is a probability sampling method that divides the population into smaller groups, or strata, based on shared characteristics before sampling. This approach ensures that each subgroup is adequately represented in the final sample, enhancing the overall accuracy and reliability of the results, especially when there are significant differences between strata.
Cluster Sampling
Cluster Sampling is a probability sampling technique used when it is impractical or costly to conduct a simple random sample or a stratified random sample across an entire population. This method involves dividing the population into clusters (groups) that are representative of the entire population and then randomly selecting some of these clusters for the study. The selected clusters are then fully surveyed, or a sample of elements from each is chosen.
Systematic Sampling
Systematic Sampling is a probability sampling method that offers a simplified approach to selecting a sample from a larger population. This technique involves selecting elements from an ordered list at regular intervals, determined by the sampling interval. The starting point is chosen randomly within the first interval, and subsequent selections are made at consistent intervals until the desired sample size is reached.
Non-Probability Sampling
Non-probability sampling methods are used when the samples are collected without giving all the individuals in a population a chance to be included. These techniques are often employed due to practical, time, or financial constraints, and they rely on the subjective judgment of the researcher rather than random selection. While they may not offer the representativeness of probability sampling methods, they can still provide valuable insights, especially in exploratory research or when studying hard-to-reach populations.
Quota Sampling
Quota Sampling involves dividing the population into exclusive subgroups, similar to stratified sampling, and then determining a quota for each subgroup to be surveyed. The selection within each subgroup is not random but is based on specific characteristics that the researcher believes are important. The process continues until the quotas for each subgroup are filled.
Snowball Sampling
Snowball Sampling is used particularly for hard-to-reach or hidden populations where members are difficult to identify or locate. It starts with a small group of initial respondents who meet the research criteria and then expands by asking those respondents to refer others they know who also meet the criteria.
Judgment Sampling
Judgment Sampling, also known as Purposive Sampling, is a non-probability sampling technique where the researcher uses their own judgment to select the sample members. This method is based on the belief that certain individuals or scenarios are more likely to produce insightful data for the research objective.
Convenience Sampling
Convenience Sampling is a non-probability sampling method where samples are selected based on their availability and proximity to the researcher. It is one of the most straightforward and cost-effective sampling methods but is also prone to bias.
Applications of Data Sampling
Data sampling plays a crucial role across various fields and research domains, enabling efficient data analysis, model development, and decision-making. Its applications span from academic research to industry-specific uses, demonstrating the versatility and importance of sampling methods. Here are key areas where data sampling is extensively applied:
-
Market Research:
Companies use data sampling to understand consumer preferences, behaviors, and trends. By analyzing a representative sample of the target market, businesses can make informed decisions about product development, marketing strategies, and customer service improvements. -
Healthcare Research:
In medical and epidemiological studies, sampling is crucial for investigating the causes, treatments, and outcomes of diseases. It allows researchers to study patient populations, understand disease prevalence, and evaluate the effectiveness of medical interventions without needing to test every individual. -
Environmental Science:
Sampling methods are used to monitor air and water quality, assess biodiversity, and study environmental changes over time. By sampling specific locations or populations, scientists can estimate the health of ecosystems and the impact of human activities on the environment. -
Education:
Educational researchers employ sampling to study teaching methods, learning outcomes, and educational policies. Sampling allows for the assessment of student performance and educational trends across different schools, regions, or demographic groups. -
Finance and Economics:
Financial analysts and economists use sampling to predict market trends, evaluate economic policies, and assess investment risks. Sampling financial data helps in making projections and decisions without the need to analyze every transaction or economic indicator. -
Quality Control:
In manufacturing and production, sampling is essential for quality assurance. Inspecting a sample of products for defects or deviations from specifications can ensure the quality of the entire production batch. -
Social Science Research:
Sampling is a fundamental tool in sociology, psychology, and political science for studying attitudes, opinions, and behaviors. Through surveys and experiments, researchers can explore social phenomena and test theories about human behavior and societal dynamics. -
Machine Learning and Data Science:
In developing predictive models, data scientists often use sampling to manage large datasets, reduce training time, and improve model performance. Sampling is critical for training, testing, and validating models efficiently.
FAQs
Q. Can data sampling be used in qualitative research?
A. Yes, data sampling is widely used in qualitative research to select specific cases or participants that provide rich, in-depth insights.
Q. How does sampling help in big data analysis?
A. Sampling reduces the volume of big data to a manageable size, enabling quicker, more efficient analysis while preserving key insights.
Q. Is it possible to avoid bias in data sampling?
A. While eliminating bias entirely is challenging, using proper sampling techniques and careful design can significantly reduce bias and improve representativeness.
Q. Can the results from sampled data be generalized to the entire population?
A. Yes, if the sample is representative and properly selected through appropriate sampling methods, the results can be generalized to the entire population with a known level of confidence.
Conclusion
- Data sampling is an essential technique in data science, offering a practical and efficient way to derive insights from large datasets without the need to analyze every data point.
- By carefully selecting a representative subset of the population, researchers can make accurate inferences about the broader population, enabling informed decision-making across various fields such as market research, healthcare, and environmental studies.
- The choice between probability and non-probability sampling methods depends on the research goals, the nature of the study, and the available resources, with each method offering unique advantages and challenges.
- While data sampling facilitates efficient data analysis and model development, it is crucial to be mindful of potential biases and errors in sample selection to ensure the reliability and validity of the research findings.
- The widespread applications of data sampling across different domains highlight its versatility and importance, underscoring the need for rigorous sampling strategies to achieve meaningful and generalizable results from data-driven research.