Data Science Lifecycle

Overview
In the ever-evolving landscape of data-driven decision-making, the Data Science Life Cycle stands as a crucial framework for businesses to extract and derive valuable insights from data. This article explores various stages of a data science Life Cycle, including data collection, preprocessing, exploration, modeling, validation, and deployment. By understanding the iterative process of the life cycle of data science, businesses, and practitioners can harness the power of data science to transform raw data into actionable insights that drive innovation and informed choices.
What is Data Science?
Data Science is an interdisciplinary field that combines statistical analysis, machine learning, and domain expertise to extract meaningful insights and knowledge from raw data. It involves collecting, analyzing, and interpreting large and complex datasets to derive valuable insights and drive informed decision-making within an organization. Data science empowers organizations to uncover hidden patterns and trends that might not be apparent through traditional methods.
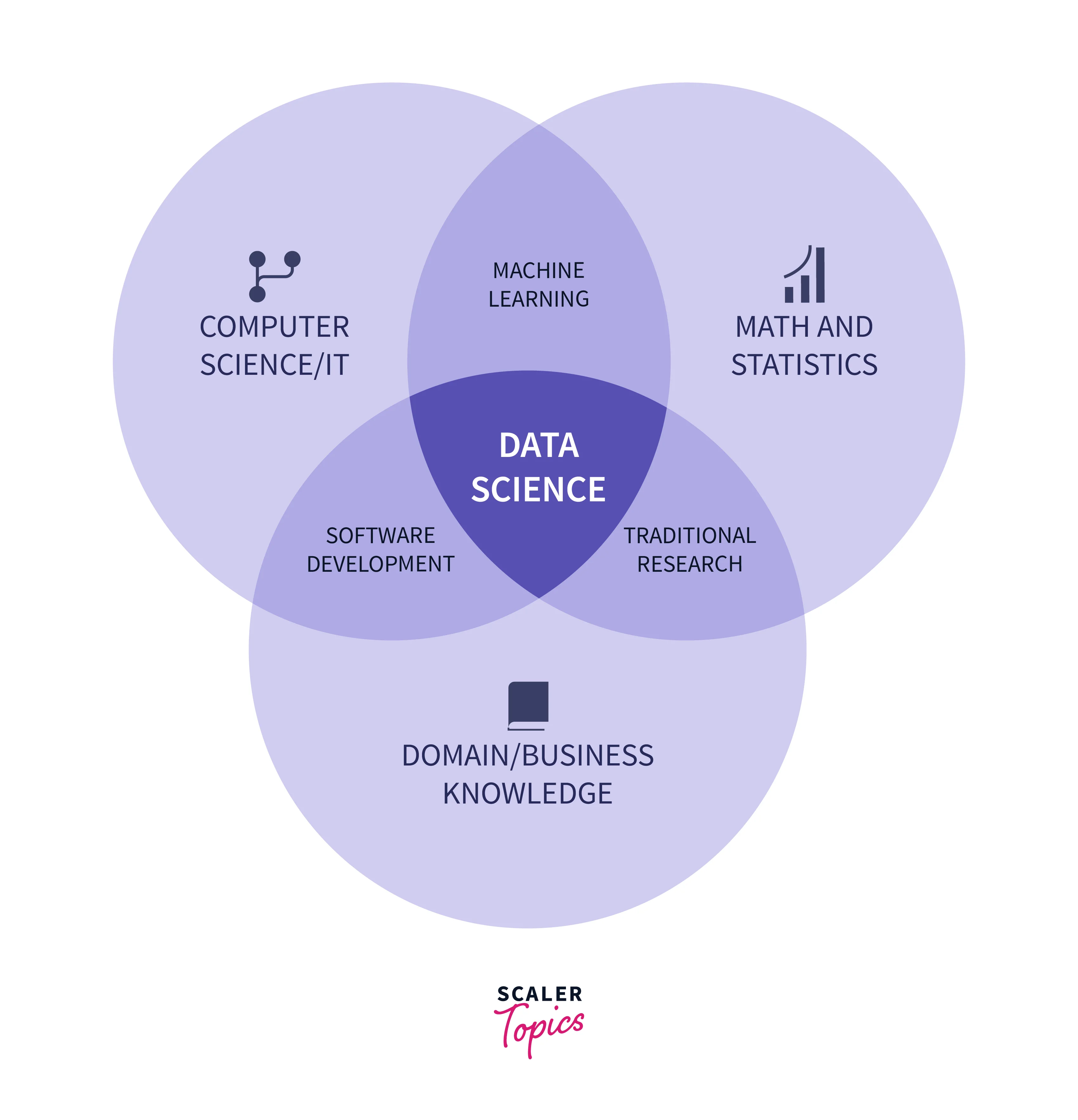
For instance, consider a retail company analyzing customer purchasing patterns. Using data science techniques, they can identify correlations between customer demographics, purchase history, and seasonal trends. This enables the company to tailor marketing strategies, optimize inventory, and enhance the overall customer experience, resulting in increased sales and customer satisfaction.
Need for Data Science
Organizations today rely on Data Science for various reasons, as mentioned below:
- Informed Decision-Making:
Data-driven insights enable informed choices, guiding strategic planning and resource allocation. - Predictive Analytics:
Data Science models forecast trends, allowing businesses to anticipate customer behavior and market shifts. - Enhanced Customer Experience:
Personalized recommendations and tailored services based on data analysis lead to improved customer satisfaction. - Operational Efficiency:
Optimization of processes through data-driven insights reduces costs and enhances overall efficiency. - Innovation and Research:
Data Science fuels innovation by uncovering new opportunities, enabling product development and research breakthroughs. - Risk Management:
Data analysis helps assess and mitigate potential risks, supporting effective risk management strategies.
Phases of Data Science Lifecycle
The various phases of the data science life cycle are as mentioned below:
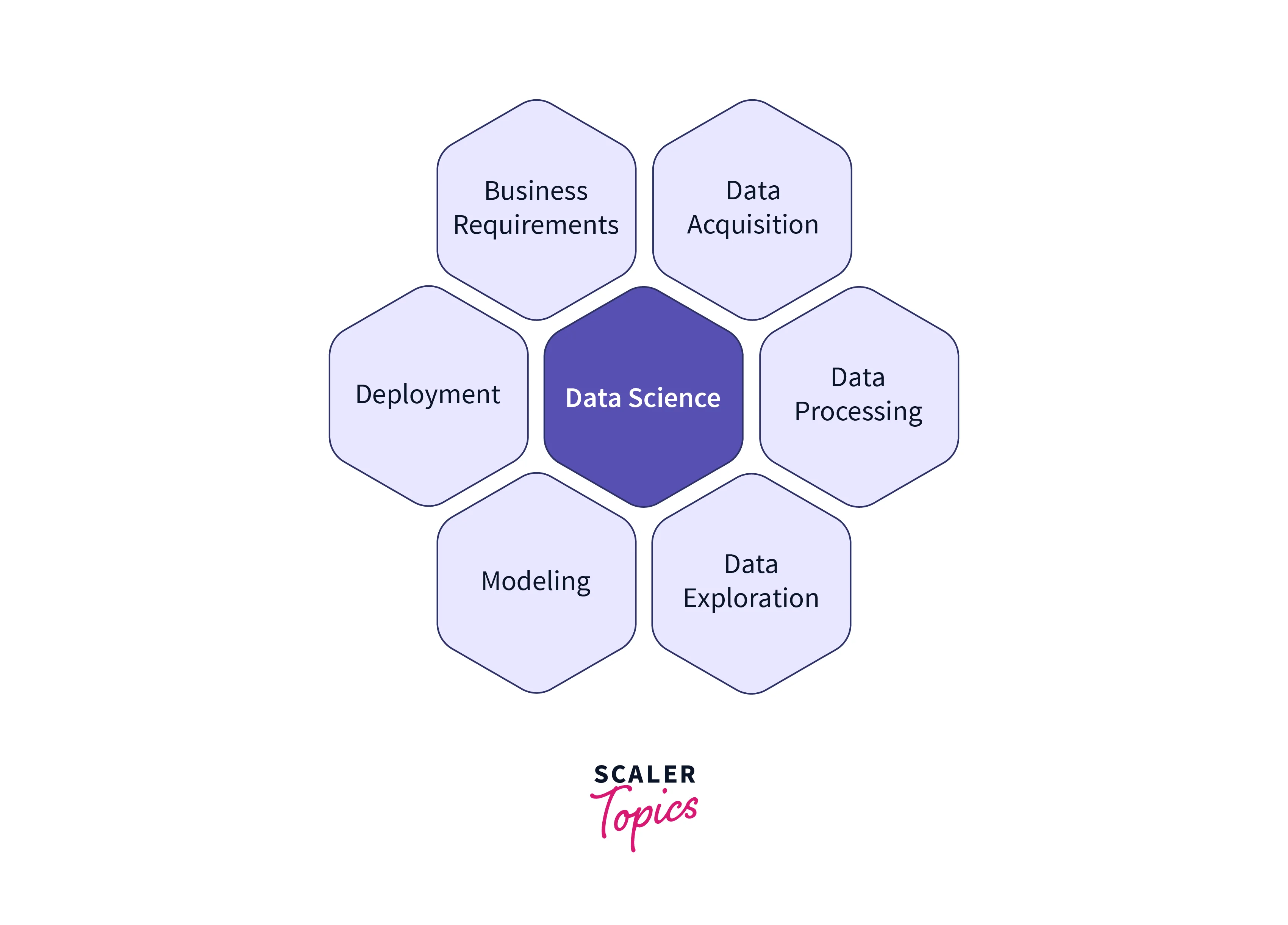
1. Business Understanding
The journey through the Data Science Life Cycle begins with gaining a deep understanding of the business problem at hand. This involves collaborating closely with stakeholders to define the objectives, requirements, and constraints of the project. For instance, consider an e-commerce company aiming to reduce customer churn. In the business understanding phase, data scientists would work with marketing and sales teams to outline the key metrics, identify the reasons behind churn, and clarify the desired outcomes. This stage sets the foundation for the entire project, ensuring that the subsequent data analysis is aligned with the overarching business goals.
2. Data Acquisition and Understanding
Once the business objectives are clear, the next stage involves collecting the necessary data for further analysis. In this phase, data scientists identify the relevant data sources, including databases, APIs, or external datasets. For instance, continuing with the e-commerce example, data scientists might collect customer transaction records, website browsing behavior, and demographic information. Thoroughly understanding the acquired data is vital, including understanding its structure, schema, quality, and potential issues. In our scenario, data scientists would assess if the transaction data is complete, if any duplicate entries exist, and whether there are missing values. This stage ensures that the data is suitable for analysis and sets the stage for subsequent data preprocessing and transformation steps.
3. Data Preparation
In the data preparation stage, the raw data is refined and transformed into a suitable format for further analysis. This involves tasks such as data cleaning, normalization, and feature engineering. Using our e-commerce context, data scientists might remove duplicates, handle missing values (e.g., impute missing customer ages), and encode categorical variables (e.g., converting 'male' and 'female' to numerical values). Additionally, they could create new features like 'average purchase value' or 'time spent on the website,' which can enhance the predictive power and efficiency of the model. This phase is crucial for ensuring that the data is accurate, consistent, and ready for the subsequent modeling and analysis stages.
4. Exploratory Data Analysis (EDA)
In the Exploratory Data Analysis (EDA) phase of the data science life cycle, data scientists explore the prepared dataset to uncover patterns, relationships, and insights. Data scientists employ a wide range of visualization techniques, such as histograms, scatter plots, heatmaps, etc., to better understand the data's characteristics. For instance, in our e-commerce project, EDA might reveal that certain products have higher sales during specific seasons or that customer age correlates with purchasing behavior. These insights can guide subsequent modeling decisions and feature selection. EDA not only aids in identifying potential outliers or anomalies but also assists in formulating hypotheses and refining the problem statement. EDA also includes feature engineering by identifying key features that can significantly improve the efficiency and accuracy of the developed ML model. It's a crucial step in guiding the data science journey toward meaningful results.
5. ML Model Development
The ML Model Development stage involves selecting and building appropriate machine learning models to address the business problem. For our e-commerce case, data scientists might use a classification model to predict customer churn. They could use algorithms like Random Forest, Support Vector Machines, or Neural Networks, depending on the complexity of the problem and the available data. Features identified during EDA, such as purchase history, browsing patterns, and customer demographics, would be used as the model's input. The model is then trained on historical data, using techniques like cross-validation to optimize its performance.
6. Model Evaluation
In the Model Evaluation stage, the performance of the developed machine learning model is assessed using various metrics. Returning to our e-commerce project, let's assume a churn prediction model has been developed. Data scientists would evaluate its effectiveness using metrics like accuracy, precision, recall, and F1-score. For instance, the model's accuracy might be 85%, meaning it correctly predicts 85% of churn cases. However, precision (the proportion of actual churn cases among predicted churn cases) and recall (the proportion of predicted churn cases among actual churn cases) might differ. A well-balanced model should consider both precision and recall, as a high precision might mean fewer false positives (misclassifications), but a lower recall might mean missing potential churn cases. The model's performance is optimized through iterative adjustments and fine-tuning to strike the right balance for the specific business context, ensuring it provides reliable and actionable insights.
7. Model Deployment
In the Model Deployment stage, the developed and evaluated machine learning model is implemented within the production environment. Continuing with our e-commerce scenario, after achieving satisfactory performance during evaluation, the churn prediction model is integrated into the company's systems. For instance, whenever a customer interacts with the website or makes a purchase, the model could assess the likelihood of that customer churning shortly. If a high churn probability is detected, the system might trigger personalized offers or notifications to retain the customer's loyalty.
This stage involves collaboration between data scientists, software engineers, and domain experts to ensure a seamless integration that aligns with the overall business strategy. Regular monitoring and maintenance are crucial to ensure the model's ongoing accuracy and relevance in a dynamic business landscape.
Conclusion
- The Data Science Life Cycle empowers organizations to harness the full potential of their data, translating it into actionable insights that guide informed decision-making.
- The Data Science Life Cycle's iterative nature ensures a continuous loop of improvement, where each phase informs the next, fostering collaboration between data scientists, domain experts, and stakeholders.
- By diligently following this data science life cycle, organizations can effectively address complex challenges, from customer retention to process optimization, enhancing operational efficiency and innovation.
- From data acquisition and understanding to model deployment, this journey transforms raw data into predictive models that not only solve problems but also drive strategic growth.