Data Science Process
Embarking on the journey of extracting valuable insights from data involves a systematic and methodical approach known as the "data science process." This intricate process serves as the backbone for deriving meaningful conclusions from vast and complex datasets. In this comprehensive article, we will dive into the intricacies of the data science process, unraveling its various stages, exploring the essential components that drive it, examining the tools instrumental in its execution, and shedding light on the vital knowledge and skills that empower data science professionals in their analytical pursuits.
What is Data Science?
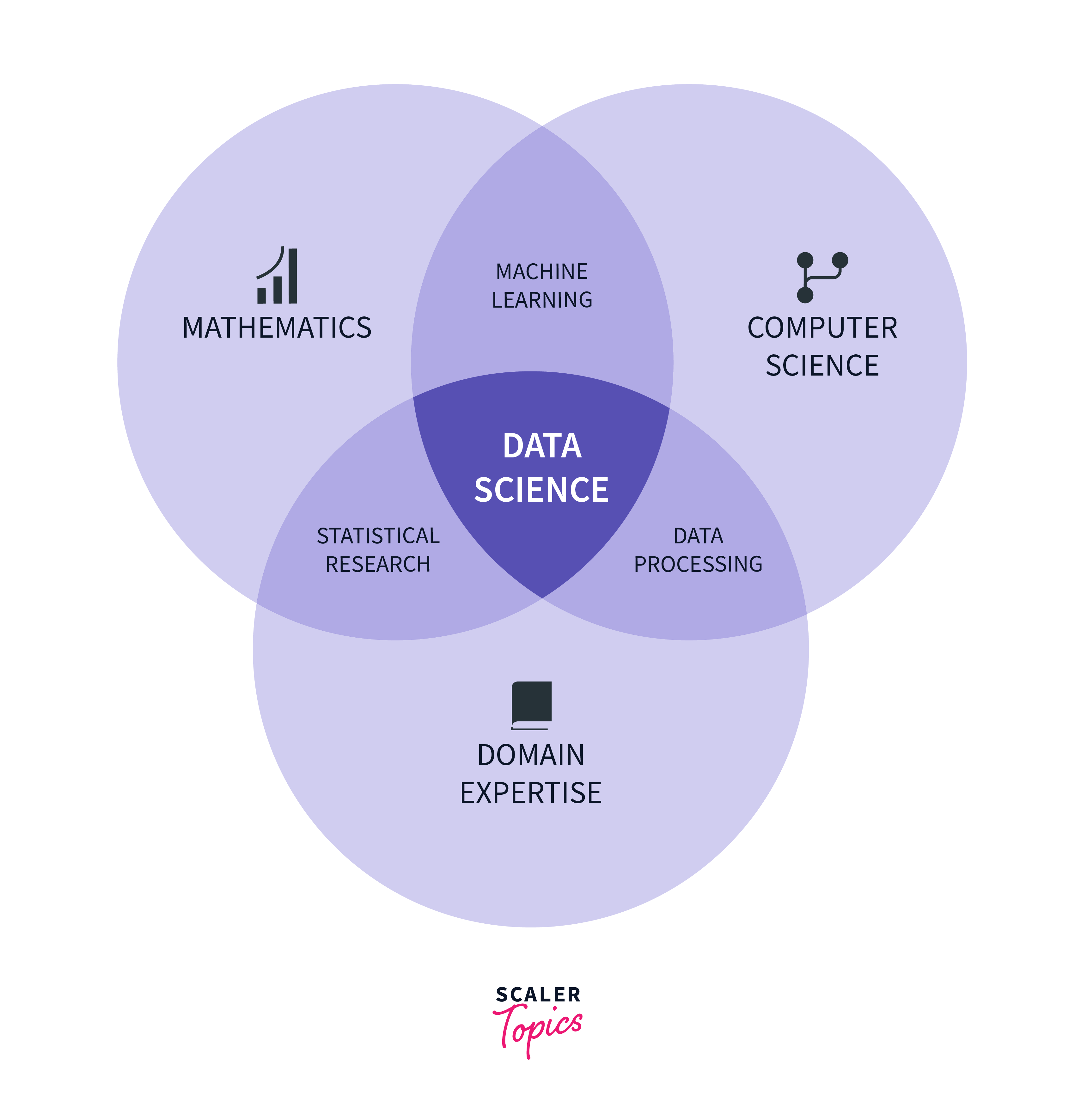
Data science represents a dynamic and interdisciplinary field that harnesses a spectrum of scientific methodologies, computational processes, advanced algorithms, and systematic systems to glean meaningful insights and knowledge from both structured and unstructured data sets. This multifaceted discipline merges the principles of statistics, computer science, and expertise from specific domains to unravel intricate patterns, discern trends, and extract valuable information that might be concealed within extensive and diverse datasets. In essence, data science serves as the conduit through which raw data is transformed into actionable insights, empowering decision-makers and researchers to make informed choices and discoveries in a wide range of applications.
Data Science Process Life Cycle
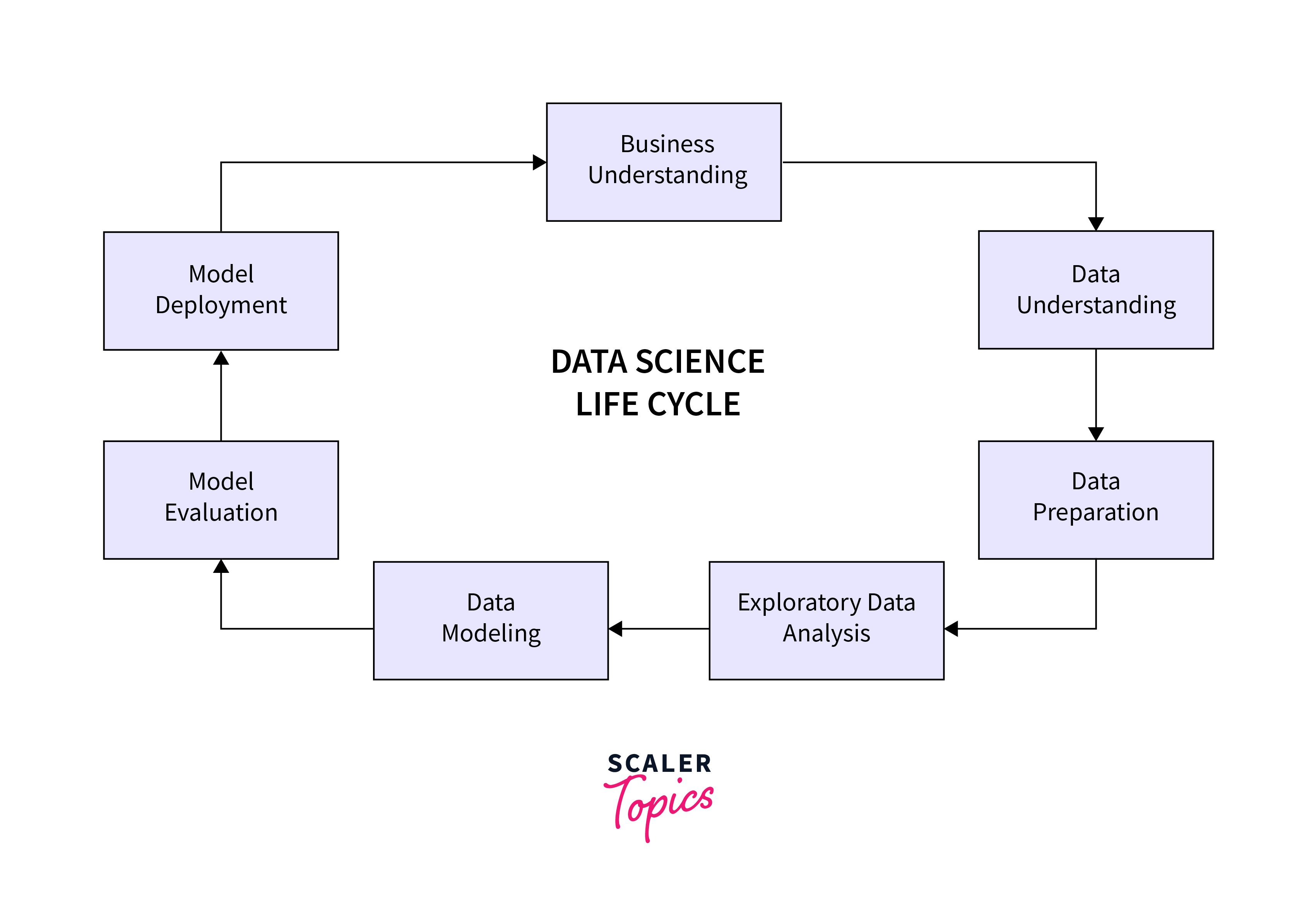
The five stages collectively form a comprehensive data science process, ensuring that insights derived from data are not only accurate but also actionable in real-world scenarios.
A. Data Collection
The goal of this stage is to gather relevant data that will be used for analysis. This may involve identifying the types of data needed to answer specific questions or achieve certain objectives. Data can be collected from various sources such as databases, APIs, external datasets, or manual inputs. The data collected should be in a raw and unprocessed form at this stage.
B. Data Cleaning
Raw data is often messy, containing errors, inconsistencies, and missing values. The purpose of data cleaning is to ensure that the data is accurate and reliable for analysis. Data cleaning involves tasks like handling missing values, correcting errors, removing duplicates, and transforming data into a format suitable for analysis. This step is crucial for obtaining meaningful and trustworthy results.
C. Exploratory Data Analysis (EDA)
EDA aims to understand the characteristics of the data and uncover patterns, relationships, or outliers that may inform subsequent modeling decisions. Visualization techniques, statistical summaries, and data exploration tools are used to analyze and interpret the data. EDA provides insights into the distribution of variables, correlation between features, and potential variables of interest for modeling.
D. Model Building
The core of data science involves constructing models that can make predictions or provide insights based on the data. This step includes selecting appropriate algorithms based on the nature of the problem, splitting the data into training and testing sets, training the model on the training set, and evaluating its performance on the testing set. Fine-tuning involves adjusting model parameters to optimize its predictive capabilities.
E. Model Deployment
Successful models need to be integrated into real-world systems so that their predictions can be used to make informed decisions. This step involves deploying the model in a production environment, making its predictions accessible to end-users or other systems. It may also include monitoring the model's performance over time and updating it as needed to maintain its accuracy and relevance.
Components of Data Science Process
The components of the data science process work in synergy, starting with data analysis and statistics to gain insights, followed by data engineering to ensure efficient data handling, and finally incorporating advanced computing techniques like machine learning and deep learning for predictive modeling and pattern recognition.
A. Data Analysis
Data analysis is a fundamental step in the data science process, involving the examination and interpretation of data to extract meaningful insights. Analysts explore patterns, trends, and relationships within the data, aiming to uncover valuable information. This process often includes tasks such as data cleaning, exploration, and visualization. The ultimate goal is to make data-driven decisions and formulate strategies based on the observed patterns and trends.
B. Statistics
Statistics provides the mathematical foundation for data science. It involves techniques for summarizing and interpreting data, making inferences about populations, and assessing the uncertainty associated with data. Hypothesis testing, regression analysis, and probability theory are essential statistical tools in data science. By leveraging statistical methods, data scientists can quantify the reliability of their findings and make informed decisions based on the available data.
C. Data Engineering
Data engineering focuses on the practical aspects of managing and processing data efficiently. This includes designing and implementing systems for data collection, storage, and retrieval. Data engineers ensure that data is properly formatted, cleaned, and available for analysis. They work on building robust data pipelines, databases, and storage systems to support the overall data science workflow. Effective data engineering is crucial for handling large volumes of data and ensuring its accessibility for analysis.
D. Advanced Computing
-
Machine Learning
Machine learning involves the development of algorithms that enable systems to learn and make predictions or decisions without being explicitly programmed. This includes supervised learning (predictive modeling), unsupervised learning (clustering and dimensionality reduction), and reinforcement learning (learning from interactions). Machine learning algorithms are trained on historical data, allowing them to generalize and make predictions on new, unseen data.
-
Deep Learning
Deep learning is a subset of machine learning that focuses on neural networks with multiple layers (deep neural networks). These networks can automatically learn hierarchical representations of data, making them particularly effective for tasks like image recognition, natural language processing, and speech recognition. Deep learning models, such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs), excel at capturing complex patterns in large datasets.
Knowledge and Skills for Data Science Professionals
A. Statistical/Mathematical Reasoning
Data scientists rely heavily on statistical and mathematical reasoning to extract meaningful information from vast datasets. A solid understanding of statistical concepts such as probability, hypothesis testing, regression analysis, and multivariate analysis is crucial. This foundation allows data scientists to uncover patterns, relationships, and trends within the data. Statistical reasoning enables the formulation and validation of hypotheses, ensuring that conclusions drawn from data are statistically sound. Moreover, it plays a pivotal role in the development and evaluation of predictive models, helping data scientists make informed decisions based on data-driven insights.
B. Business Communication/Leadership
Data scientists not only need to be adept at analyzing and interpreting data but must also excel in communicating their findings to non-technical stakeholders. Effective business communication involves translating complex technical jargon into clear, actionable insights that can guide decision-making. Data scientists should be skilled in creating compelling visualizations and reports to convey their analyses in a comprehensible manner. Additionally, leadership skills are essential for data scientists to play a strategic role in organizational decision-making processes. They need to guide and influence key stakeholders, ensuring that data-driven insights are integrated into the broader business strategy. This requires the ability to articulate the value of data science initiatives and align them with overall business goals.
C. Programming
Proficiency in programming languages such as Python or R is a fundamental skill for data scientists. These languages provide the tools and libraries necessary for data manipulation, analysis, and model building. With programming skills, data scientists can clean and preprocess raw data, apply statistical methods, and implement machine learning algorithms. This hands-on capability is essential for transforming theoretical concepts into practical solutions. Moreover, programming proficiency enables data scientists to automate repetitive tasks, streamline processes, and develop scalable solutions. It empowers them to work efficiently with large datasets and facilitates collaboration with software engineers and IT professionals in deploying data-driven applications.
Steps for Data Science Processes
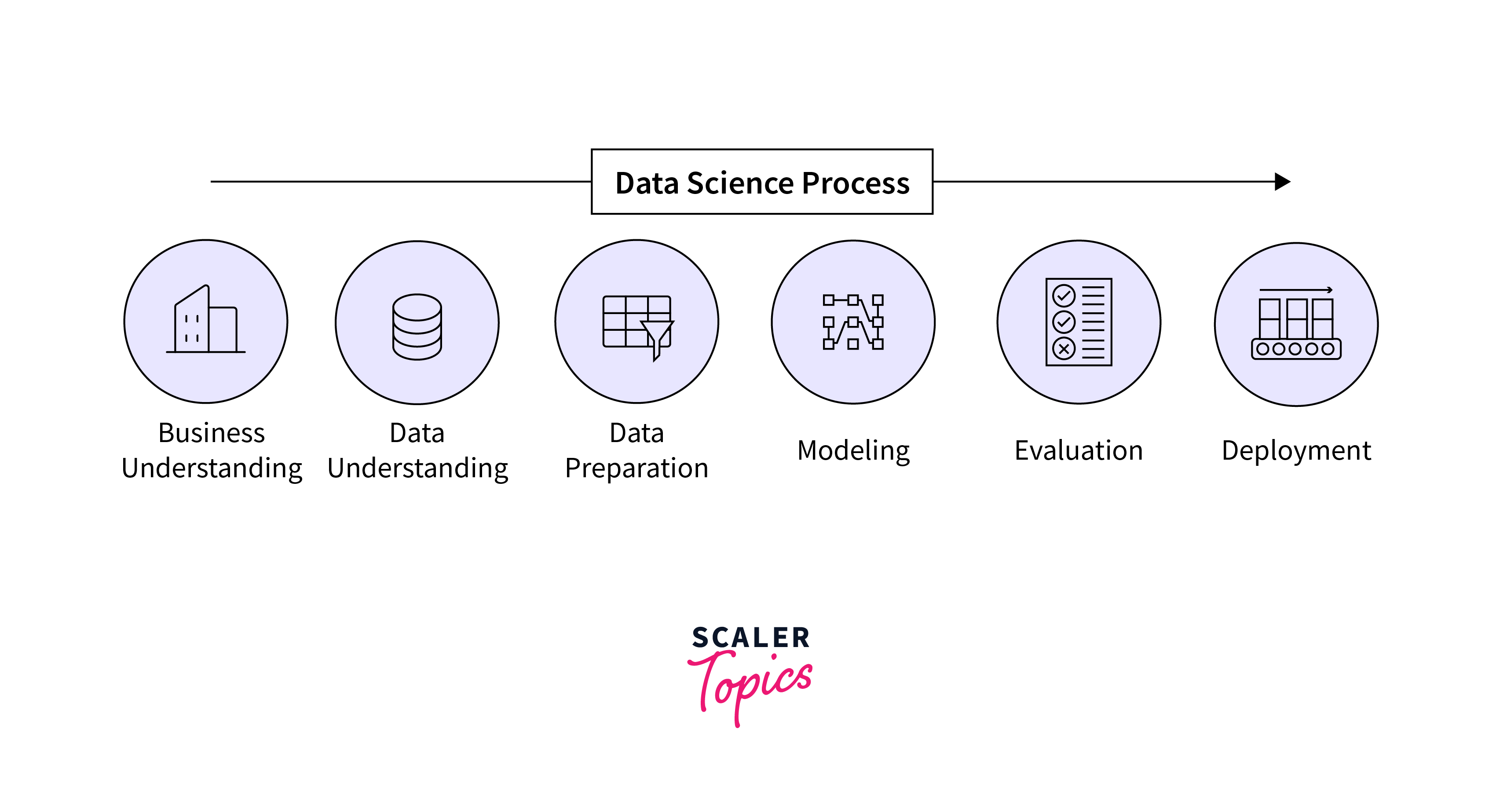
-
Problem Definition
The first step in any data science project involves clearly defining the problem at hand. This includes understanding the business objectives and identifying how data can contribute to solving the problem. The definition should be specific, measurable, and aligned with organizational goals. It sets the foundation for the entire data science process and ensures that efforts are focused on addressing the most relevant challenges.
-
Data Collection
Once the problem is defined, the next step is to gather relevant data. This involves identifying and collecting data from various sources, ensuring that the dataset is comprehensive and representative of the problem domain. The quality and quantity of data play a crucial role in the success of the analysis, so meticulous attention is given to acquiring diverse and meaningful datasets.
-
Data Exploration
With the data in hand, the data scientist engages in exploratory data analysis (EDA). This step involves examining the dataset's characteristics, identifying patterns, and understanding relationships between variables. Visualization techniques, statistical summaries, and data profiling are often used to gain insights into the data. EDA helps in forming hypotheses and guiding subsequent steps in the analysis.
-
Data Modeling
Building on the insights gained during data exploration, the data scientist proceeds to develop models. Depending on the goals of the analysis, these models can be predictive (forecasting future outcomes) or descriptive (summarizing and understanding the data). Machine learning algorithms are often employed in this stage, and the models are trained on a subset of the data to learn patterns and relationships.
-
Evaluation
After creating models, it's essential to evaluate their performance. This involves assessing how well the models generalize to new, unseen data. Evaluation metrics, such as accuracy, precision, recall, or others depending on the problem, are used to quantify the model's effectiveness. Rigorous evaluation ensures that the chosen models provide meaningful and reliable results.
-
Deployment
Once a model has proven effective, it is integrated into operational systems for practical use. Deployment involves making the model available to end-users or incorporating it into business processes. This step requires collaboration between data scientists and IT professionals to ensure a seamless transition from development to implementation.
-
Monitoring and Maintenance
Data science projects don't end with deployment; they require ongoing monitoring. Models can drift in performance over time due to changes in the underlying data distribution or other factors. Regular monitoring helps detect and address these issues, ensuring that models continue to provide accurate and relevant insights. Maintenance activities may include updating models, retraining them with new data, or adapting to changes in the business environment. This iterative process ensures the sustainability and longevity of the data science solution.
Benefits and Uses of Data Science and Big Data
The data science process, when applied effectively, yields numerous benefits, including:
A. Informed Decision-Making
The application of data science empowers organizations to make informed decisions by leveraging insights derived from large and complex datasets. Rather than relying on intuition or past experiences alone, decision-makers can use data-driven analyses to gain a comprehensive understanding of various factors influencing their operations. This results in more accurate and well-informed choices, contributing to increased efficiency and competitiveness in today's dynamic business environment. With data science, decisions are grounded in evidence and patterns extracted from extensive datasets, providing a solid foundation for strategic planning and execution.
B. Predictive Analytics
One of the key capabilities of data science is predictive analytics, where historical data is used to forecast future trends and outcomes. By employing advanced algorithms and machine learning models, organizations can anticipate changes in markets, customer behavior, and other critical variables. This proactive approach enables decision-makers to prepare for potential challenges and capitalize on emerging opportunities. Whether in finance, healthcare, marketing, or other industries, predictive analytics empowers organizations to stay ahead of the curve, fostering innovation and adaptability.
C. Personalization
Data science plays a pivotal role in delivering personalized experiences to customers. By analyzing individual preferences, behavior patterns, and historical interactions, organizations can tailor their products and services to meet the unique needs of each customer. This level of personalization enhances the overall user experience, leading to increased customer satisfaction and loyalty. From recommending personalized content on streaming platforms to suggesting products based on past purchase history in e-commerce, data science enables businesses to create targeted and meaningful interactions, ultimately driving customer engagement and retention.
Tools for Data Science Process

Various tools support different stages of the data science process:
-
Apache Kafka and AWS Kinesis are robust tools designed for efficient data collection at scale. They facilitate the seamless ingestion and streaming of large volumes of data, ensuring a reliable foundation for subsequent analysis.
-
Python libraries such as Pandas and NumPy are indispensable for data cleaning tasks. They offer powerful functionalities for handling missing values, removing outliers, and transforming data, streamlining the process of preparing datasets for analysis.
-
Tools like Tableau provide interactive and insightful data visualization, while Matplotlib, a Python library, offers a versatile platform for creating visualizations during the exploratory data analysis phase. These tools aid in uncovering patterns and trends within the data.
-
Scikit-learn and TensorFlow are widely used frameworks for model development and training. Scikit-learn offers a comprehensive set of tools for traditional machine learning, while TensorFlow is particularly powerful for building and training deep learning models, providing flexibility across a range of model complexities and types.
-
Docker and Kubernetes are instrumental in simplifying the deployment of machine learning models in production environments. They enable the creation of containerized applications, ensuring consistent and efficient deployment across various platforms, and enhancing scalability and manageability in real-world applications.
Usage of Data Science Process
-
Problem Definition:
Clearly defining the problem at the outset ensures a targeted and purposeful approach to data analysis. This step establishes the foundation for the entire data science process, guiding efforts toward addressing specific challenges in a focused manner.
-
Data Collection:
Gathering data from diverse sources is crucial, emphasizing the importance of data quality and relevance to the identified problem. The effectiveness of subsequent analyses and models depends on the comprehensive and representative nature of the collected data.
-
Data Exploration:
Exploratory data analysis provides insights into the characteristics of the dataset, uncovering patterns and relationships. This phase allows data scientists to form hypotheses and refine their understanding of the data, guiding the subsequent stages of the analysis.
-
Data Modeling:
Developing models tailored to the defined problem involves selecting appropriate algorithms and techniques. This step transforms raw data into actionable insights, leveraging statistical and machine learning methods to address the specific challenges outlined in the problem definition.
-
Evaluation:
Assessing model performance using relevant metrics is critical for validating its effectiveness. Rigorous evaluation ensures that the model generalizes well to new data, providing confidence in its ability to make accurate predictions or generate meaningful insights.
-
Deployment:
Integrating successful models into operational systems facilitates their practical application. Whether in business processes or software applications, deploying models ensures that data-driven insights are incorporated into decision-making, enhancing efficiency and effectiveness.
-
Monitoring and Maintenance:
Ongoing monitoring of model performance is essential to detect any deviations or changes in data patterns. Regular updates and maintenance activities, such as retraining models with new data, ensure that the deployed solutions remain accurate and relevant in dynamic environments, contributing to the longevity and sustainability of the data science solution.
Issues of Data Science Process
-
Data Quality and Availability:
The success of any data science project hinges on the quality and availability of data. Incomplete or biased datasets can significantly impact the accuracy and reliability of models. Ensuring data quality involves addressing issues such as missing values, outliers, and inconsistencies. Additionally, the availability of relevant data is crucial; without access to comprehensive and representative datasets, the effectiveness of the entire data science process is compromised. Data scientists must navigate these challenges to build models that provide meaningful insights and reliable predictions.
-
Bias in Data and Algorithms:
Data and algorithms can unintentionally perpetuate biases, leading to unfair and unequal outcomes. Biases present in historical data may be learned and replicated by machine learning models, reinforcing existing disparities. It is essential for data scientists to be vigilant in identifying and mitigating bias throughout the data science process. This involves thoroughly assessing both the data and the algorithms used, implementing fairness-aware models, and adopting ethical practices to minimize unintended consequences.
-
Model Overfitting and Underfitting:
Balancing the complexity of models is a critical challenge in data science. Overfitting occurs when a model becomes excessively complex, fitting the training data too closely and performing poorly on new, unseen data. On the other hand, underfitting occurs when a model is too simplistic, failing to capture the underlying patterns in the data. Achieving the right balance is crucial for optimal model performance and generalization to new data, highlighting the importance of model evaluation and fine-tuning.
-
Model Interpretability:
Some advanced machine learning models, such as deep neural networks, are often considered black boxes, making it challenging to interpret their decision-making processes. Model interpretability is essential for building trust and understanding in the predictions made by these models. Data scientists must explore methods for making complex models more interpretable, ensuring that stakeholders can comprehend and trust the insights derived from the models.
-
Privacy and Ethical Considerations:
The use of personal and sensitive data in data science projects raises ethical concerns regarding privacy and responsible practices. Data scientists must navigate a delicate balance between extracting valuable insights and safeguarding individual privacy rights. Implementing robust anonymization techniques, adopting privacy-preserving technologies, and adhering to ethical guidelines are essential to address these concerns and ensure the ethical use of data in the data science process.
-
Technical Challenges:
The technical aspects of data science present challenges related to the handling of large datasets, optimization of algorithms, and overcoming computational constraints. Processing and analyzing massive amounts of data require efficient algorithms and powerful computing resources. Additionally, optimizing models for performance and scalability is a continuous process, especially in the face of evolving technologies. Data scientists must navigate these technical challenges to ensure the efficiency and effectiveness of their analyses throughout the data science lifecycle.
FAQs
Q. Which Is the Most Crucial Step in the Data Science Process?
A. The problem definition emerges as the linchpin in the data science process, wielding significant influence over the subsequent stages. It serves as the guiding beacon, ensuring that the analytical efforts are purposeful and directed toward solving specific challenges. A well-defined problem sets the tone for the entire data science journey, steering the focus of analyses and model development in a targeted and impactful manner.
Q. Is the Data Science Process Hard To Learn?
A. While mastering the data science process poses its challenges, it is an achievable endeavor with dedication and access to the right learning resources. Data science encompasses a diverse set of skills, including statistical reasoning, programming, and domain knowledge. However, numerous educational resources, online courses, and practical applications are available to facilitate learning. With a systematic and persistent approach, individuals can navigate the complexities of the data science process and build a robust skill set over time.
Q. Are You Required To Use the Data Science Process?
A. Yes, the data science process stands as a fundamental framework for deriving meaningful insights from data. Its systematic approach ensures that data analysis is conducted in a structured manner, from defining the problem and collecting relevant data to building models and deploying solutions. Employing the data science process is not only a best practice but also a necessity to extract actionable insights, make informed decisions, and contribute to the advancement of various fields. Its application ensures a comprehensive and methodical exploration of data, enabling individuals and organizations to harness the full potential of their datasets.
Conclusion
- The data science process, marked by its systematic and iterative nature, guides practitioners through well-defined stages, ensuring a cohesive journey from problem definition to model deployment.
- Data science encompasses a diverse set of stages, components, and skills, making it a multidisciplinary field that draws upon statistical reasoning, programming acumen, and domain knowledge.
- The synergy of these elements contributes to the robustness of the data science process, creating a comprehensive framework for exploration and analysis.
- The process holds immense potential for extracting actionable insights from data, providing organizations with a reliable path to make informed decisions and unlock latent value within their data repositories.
- Despite challenges such as data quality concerns and the interpretability of complex models, the benefits of informed decision-making, predictive analytics, and tailored solutions underscore the significance of the data science process in today's data-driven landscape.
- As technology evolves, mastering the data science process transcends being a skill.
- It becomes a necessity for organizations aiming to harness the power of data and stay competitive in an increasingly data-centric world.
- Staying competitive requires not just an understanding but a mastery of the methodologies embedded in the data science process, turning the journey from raw data to actionable insights into a strategic imperative for thriving in the dynamic realm of data science.