What is Data Extraction?

Overview
Data extraction can be defined as the process of collecting data from a variety of data sources, both structured and unstructured databases, transforming it, and storing it in a centralized location or data warehouse, from which it can be easily accessed for further analysis. It is the first step in the ETL (extract, transform, load) process to prepare the data for analysis and business intelligence.
What is Data Extraction?
-
In the context of ETL (extract, transform, load), data extraction refers to the first step in the ETL process, where data is collected and combined from a wide range of data sources. These data sources can be structured or unstructured databases, documents, or websites. After collecting data from multiple sources, it is transformed and loaded into a target database or data warehouse.
-
The goal of the extraction process in ETL is to collect the relevant data from multiple sources and prepare it for the next steps in the ETL process, which involve transforming and loading the data into data warehouses so that it can be easily accessed further for analysis and business intelligence.
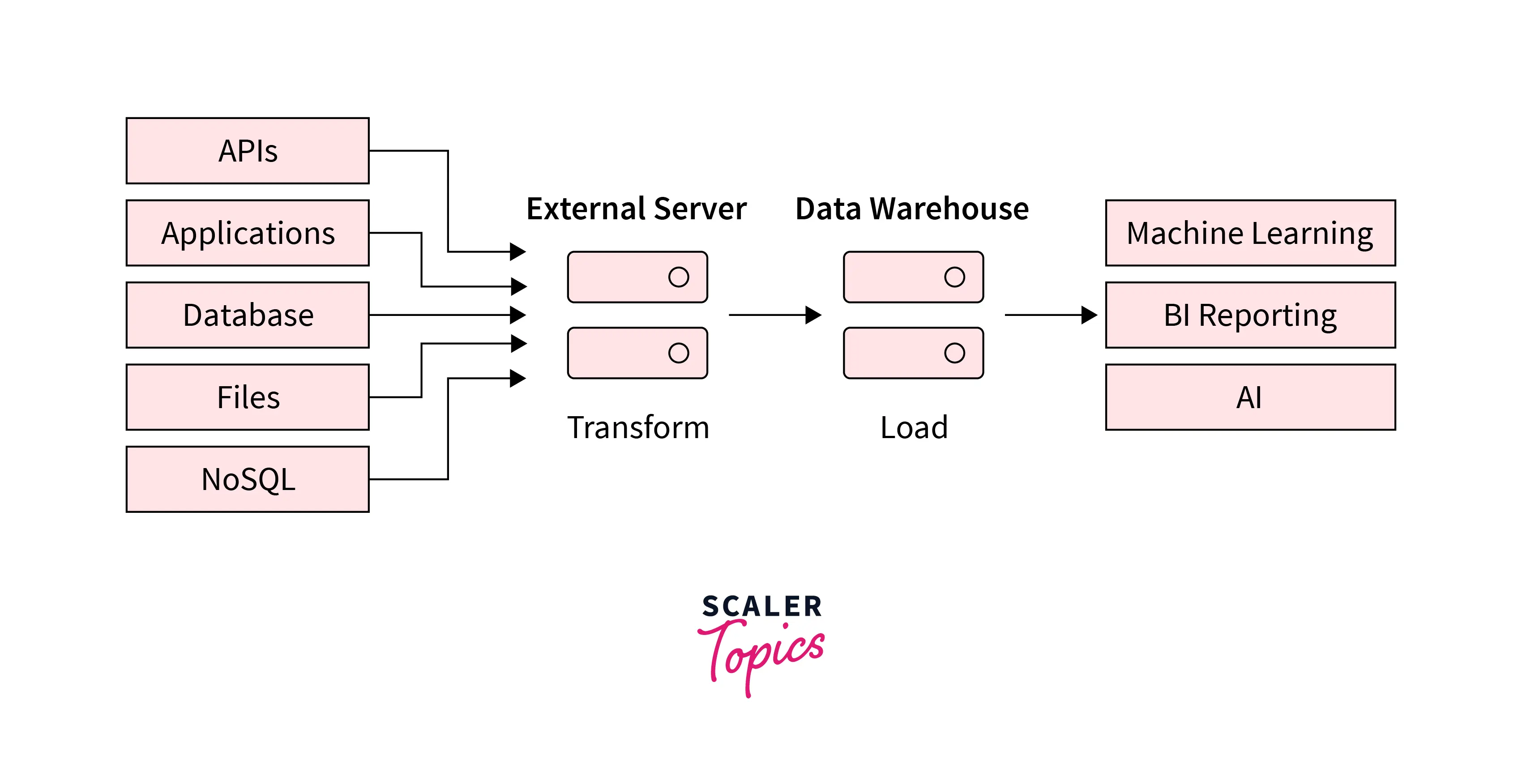
Process of Data Extraction
Data Extraction and ETL
- Data extraction is the first step in the ETL (extract, transform, load) process, in which the relevant data is retrieved from a wide range of data sources. This data is further transformed and loaded into the centralized location or data warehouses, where it can be easily accessed and used for various purposes, such as data analysis, business intelligence, etc.
- Using a combination of data extraction and ETL, organizations can effectively manage large amounts of data and leverage it to support their strategic planning and decision-making. The ETL process consists of three main steps: extract, transform, and load.
Extract:
In this step, data is retrieved from multiple sources, such as databases, documents, or websites. This typically involves using tools and algorithms to select the relevant data.
Transform:
In this step, the extracted data is cleaned, formatted, and transformed into a consistent format. This typically involves filtering out irrelevant data, combining data from multiple sources, and converting data into a format compatible with the target database or data warehouse.
Load:
The transformed data is loaded into the target database or data warehouse in the final load step.
-
These steps are generally performed in sequence, with one step's output used as the next input. Using ETL steps, organizations can effectively integrate data from multiple sources and make it easily available for analysis, reporting, and decision-making.
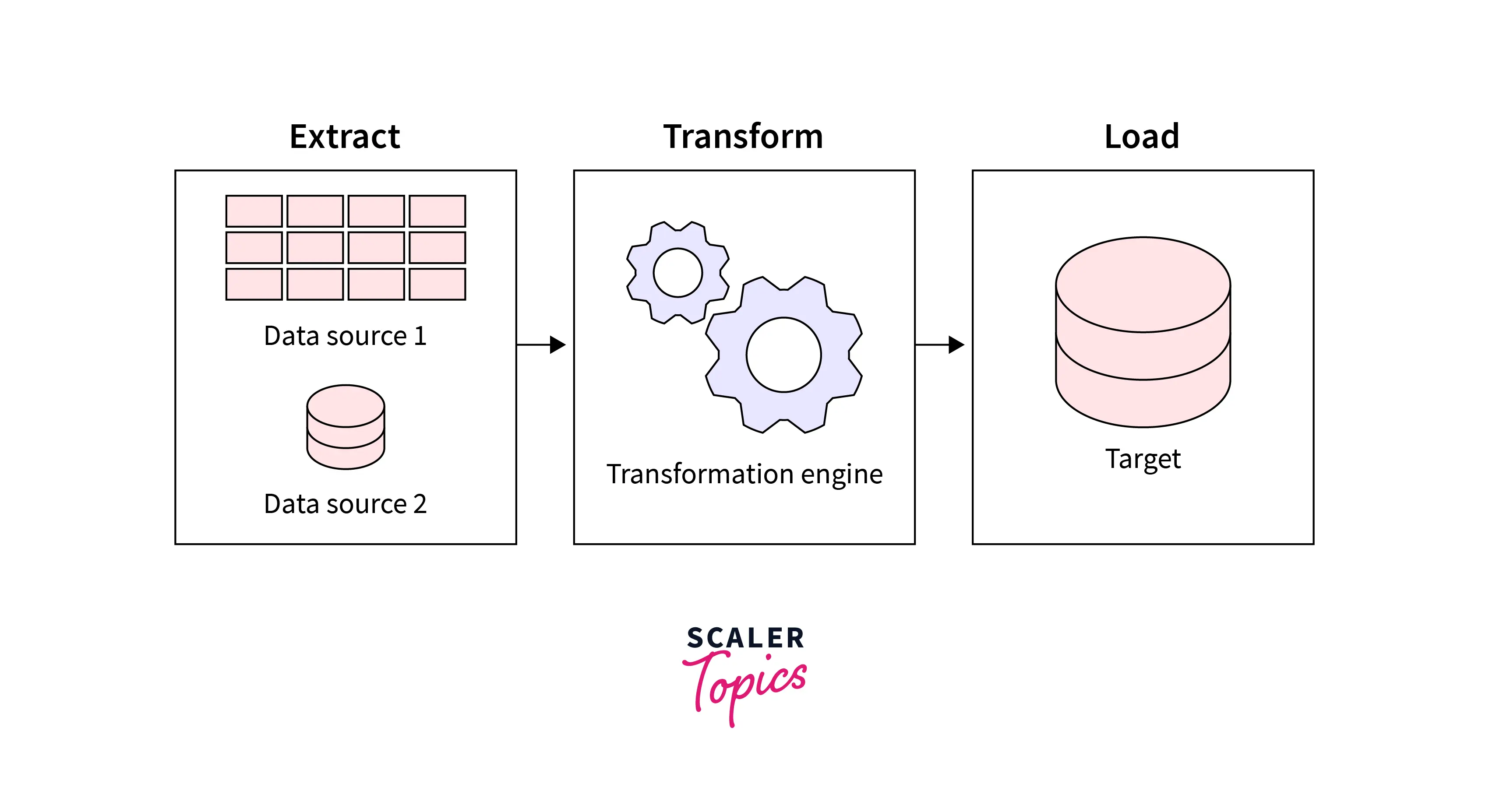
Data Extraction without ETL
- Data extraction can be used on its own without using it with ETL. In this case, the objective is to extract specific data from multiple sources and make it available for further use or analysis. In the case without ETL, the extracted data might not be transformed or loaded into a target database.
- One disadvantage of using data extraction without ETL is that extracted data may not be in an inconsistent format. This can make it challenging to organize or analyze the data, as it may require additional processing to convert it into a consistent format.
- Another disadvantage of using data extraction without ETL is that the extracted data may not be integrated with other data sources. The transform step in the ETL process transforms data into a consistent format that can help integrate it with other data sources. So, in this case, it may be less useful for analysis, reporting, or decision-making.
- Finally, performing data extraction without ETL may require more manual effort and intervention. The ETL process enables the automation of many steps to save time and reduce potential errors. Without ETL, these steps may need to be performed manually, which can be time-consuming and error-prone.
Curious to See These Concepts in Action? Our Data Science Course Provides Practical Insights. Enroll and Transform Your Knowledge into Proficiency!
Data Extraction Tools
- Most companies and organizations use ETL-based data extraction tools to manage the data extraction process end-to-end. An ETL tool can help automate and streamline the entire data extraction process, providing control, agility, and ease of sharing over manual or other data extraction processes.
- ETL tools can be divided into multiple categories - batch processing, cloud-based, and open-source ETL tools. Let’s explore a few of the most common ETL tools used by organizations.
Scrapestorm
- Scrapestorm is an AI-powered ETL tool that supports data extraction and web scraping. It can easily collect various data types and entities, such as emails, numbers, lists, forms, links, images, prices, etc., and is compatible with Windows, Mac, or Linux operating systems.
- It can also collect data from various sources, such as Excel, CSV, TXT, HTML, MySQL, MongoDB, SQL, PostgreSQL, Google Sheets, etc.
Altair Monarch
- Altair Monarch is a desktop-based and self-serve ETL tool that requires no coding. It can connect to multiple data sources, such as structured or unstructured data, cloud sources, etc., and provides more than 80 in-built functions for data collection, cleaning, and processing.
Klippa
- Klippa is a cloud-based ETL tool that processes invoices, receipts, contracts, and passports. The data manipulation and classification can be done online.
- It supports processing a wide array of formats, such as PDF, JPG, PNG, etc., and can convert them into JSON, PDF/A, XLSX, CSV, and XML. Their conversion time is really fast, somewhere between 1 to and 5 seconds.
NodeXL
- It is a free, open-source add-on extension for Microsoft Excel. It is generally used for social media analysis and does not support data integration as it is just an add-on.
Types of Data Extraction
Data extraction can be defined into two categories, as mentioned below :
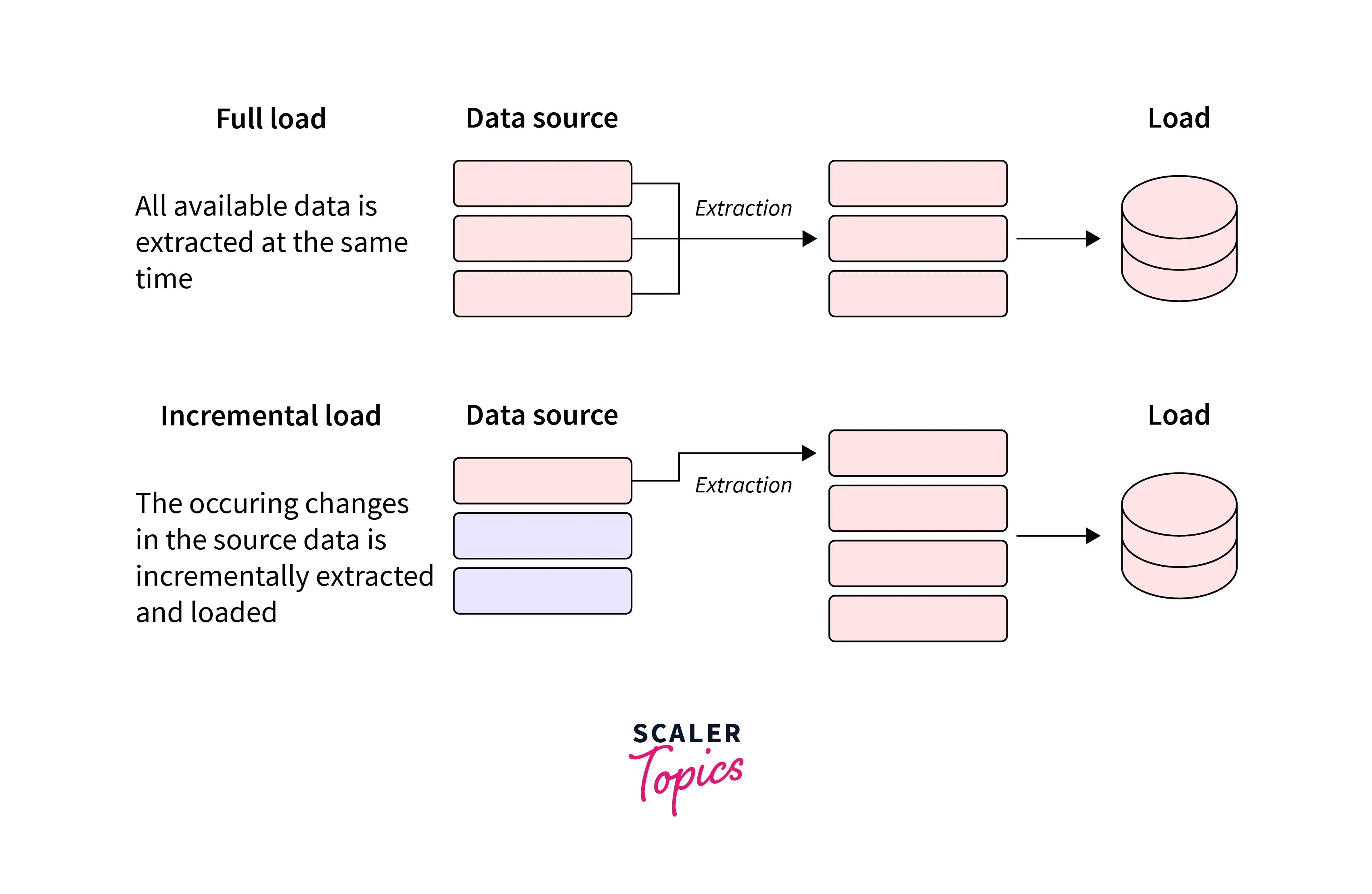
Full Data Extraction
-
In data extraction, a full extraction can be defined as the process of extracting all of the data from a specific data source, such as a database, website, etc. In this extraction type, it does not matter when the last data was extracted, as each extraction is independent and is a complete export of the current snapshot of the data.
-
A full extraction can help create a complete, up-to-date snapshot of the data, but it can also be time-consuming and resource-intensive.
For example, if you are analyzing customer data, you can perform full extraction to get the current state of all customer data. As it does not filter anything and download the complete data, it can increase the system load if the data is significantly large.
Incremental Data Extraction
-
Incremental data extraction refers to the process of extracting only changed, new, or updated data from a data source rather than extracting all of the data each time the ETL process is run.
-
This approach can be more efficient and reduce the system load, as it focuses only on the data that has been updated or added since the last extraction.
Use Cases
Let’s review a couple of use cases to understand how implementing ETL-based data extraction can benefit organizations.
Domino’s Problem
- Domino’s is the world’s largest pizza company and has outlets in almost every city. It accepts orders from a variety of mediums, such as telephone, websites, food delivery apps, social media, etc. To run its global operations smoothly, it must combine massive amounts of generated data from each source.
- For this, Domino’s has implemented a data management platform that runs on its cloud servers and extracts data from all systems, such as POS, text messages, calls, online apps, websites, social media, etc. It further cleans, transforms, and stores it in a central location so that other teams can easily access it to derive insights into its global operations and customer preferences.
Improving Employee Productivity with Data Extraction
- Suppose a company deals with PDFs, scanned documents, etc. It requires all of the information contained in these documents to run its day-to-day business operations. If employees type or enter data manually into the systems, it is a complete waste of employees’ productivity and highly prone to human error.
- The company can implement an ETL-based data extraction tool that can utilize various techniques like Optical Character Recognition (OCR) to extract desired information from the documents automatically. This data can be sent to business intelligence applications to generate valuable insights that can help improve and streamline existing processes. Therefore, businesses can use data extraction tools to improve employee productivity and streamline data processes.
Don't miss out on the opportunity to become a data science expert. Enroll now in our free certification course and gain valuable insights into this exciting field.
Future of Data Extraction
- The advent of cloud storage and computing has greatly impacted how companies manage and store their data. Due to the increased adoption of big data and cloud technologies, ETL processes are more efficient and fast than ever before. Many organizations have already started to move from on-site storage systems to cloud and hybrid-based systems.
- With everything moving to the cloud and an increase in IoT devices and wearables, the volume of data is going to grow at an exponential rate in the future. Companies worldwide can implement ETL tools to extract, transform, and load this massive amount of data in real-time to derive valuable insights that can support decision-making and provide companies with a competitive advantage.
Conclusion
- Data extraction is the process of collecting data from various sources so that it can be transformed and stored in a centralized location or data warehouse. Data extraction is the first step in the ETL (extract, transform, load) process to prepare the data for analysis and business intelligence.
- Companies implement various ETL tools to manage and store their data. It can enable easy access to the company’s data to multiple stakeholders.