What is Supervised Learning?

Overview
We’ve all heard of the flashy newspaper headlines “Data is the sword of the 21st century” or “Data is the new oil”. As a science student, I became curious about learning and understanding what it means. Further, I got so interested in the field that I chose Data Science as my specialization of Masters. This article is to introduce you to some of the popular buzzwords of the Data Science world and more precisely Supervised Learning.
Artificial Intelligence
The branch of science that tries to replicate human intelligence artificially is AI. It ranges from the ability to see and process different images to the sense of identifying patterns and mapping them with past experiences, etc.
Machine Learning
In traditional rule-based learning, programmers would write code(rules) to make computers do certain tasks for them. The quality of the tasks performed would be as good as the code the machine was running. So, even though computers are extremely fast in calculations and are error-free, they lack the cognitive intelligence of humans, i.e., a machine can never learn from its own past experiences and would always depend on humans to configure it to perform tasks. ML is this new category of algorithms and ideology where machines can figure out patterns on their own and learn themselves without any human intervention. Tom Mitchell gave a formal definition of Machine Learning as,
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.
Let’s understand this with an example. Task T= filtering emails as spam/not spam. P= #of emails labeled correctly, E= exercise of labeling an email. So, according to the definition, a computer that can get better at labeling emails correctly, i.e., that can increase its performance of the task simply by doing it repeatedly and learning from it, can be said to be using ML.
::: -->
Supervised Learning
Remember learning as a kid where you try to find answers to a problem and to check if it was correct one, you’d go to your teacher and they would already know all the correct answers. Supervised learning is based on the same idea where you have labeled data, i.e., input and correct output is already given, and you try to create different models/hypotheses and then validate these models on the output you already have. Let’s learn this better with an e.g.
Suppose we have three pairs of input values (5,0),(4,3), and (3,4), and we know that the output of all these pairs is 25. Now the problem statement is to find an equation that satisfies all these three values. Now if you’ve already done a lot of algebra, you can easily figure out that the result is equivalent to the sum of squares of values in the input pair and can be satisfied with the equation x²+y²=25. Supervised learning is the same, where we have a lot of labeled data, and the machine is supposed to recognize these patterns from the data and validate the model based on the result. In the given example, the result of all 3 data is the same, but it can very well be different. All we care about is having an output associated with each input row and then trying to form a model which satisfies most, if not all, of these inputs to give correct outputs.
Supervised learning can then be subdivided into two problems:
| Classification | Regression |
|---|---|
| Split it | Fit it |
| Discrete or Categorical data | Real number data |
| Has category associated | Has associated number |
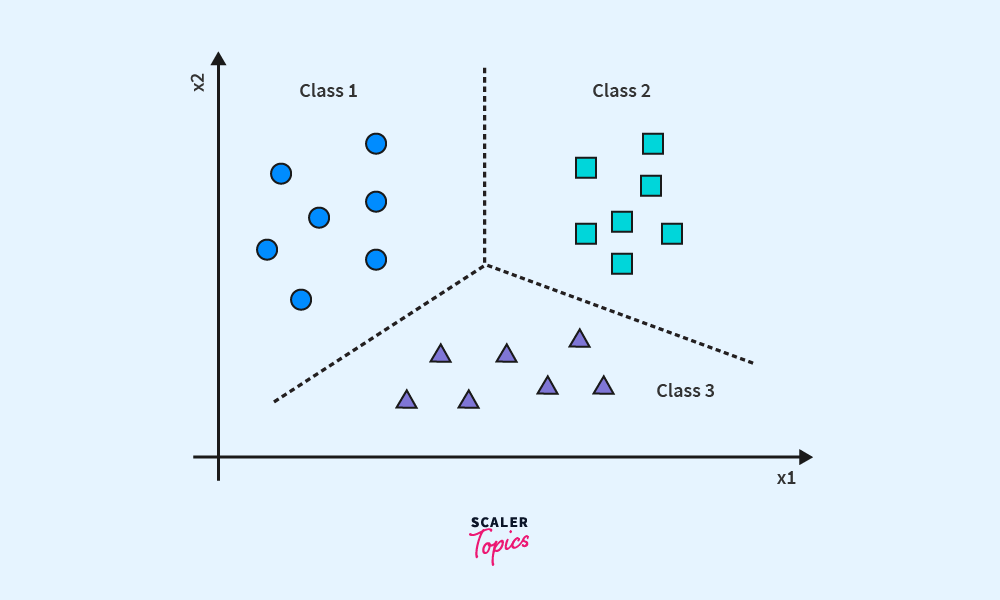
Classification
Problems, where you’ve output as categorical data, can be divided into categories, and these categories are well labeled and can be put in this class of problems. e.g., you have a lot of pet pictures, and you wish to classify them as dogs or cats, or rabbits. Here, we need a function or a model that, given the input as images, can correctly classify the image as cat/dog/rabbit.
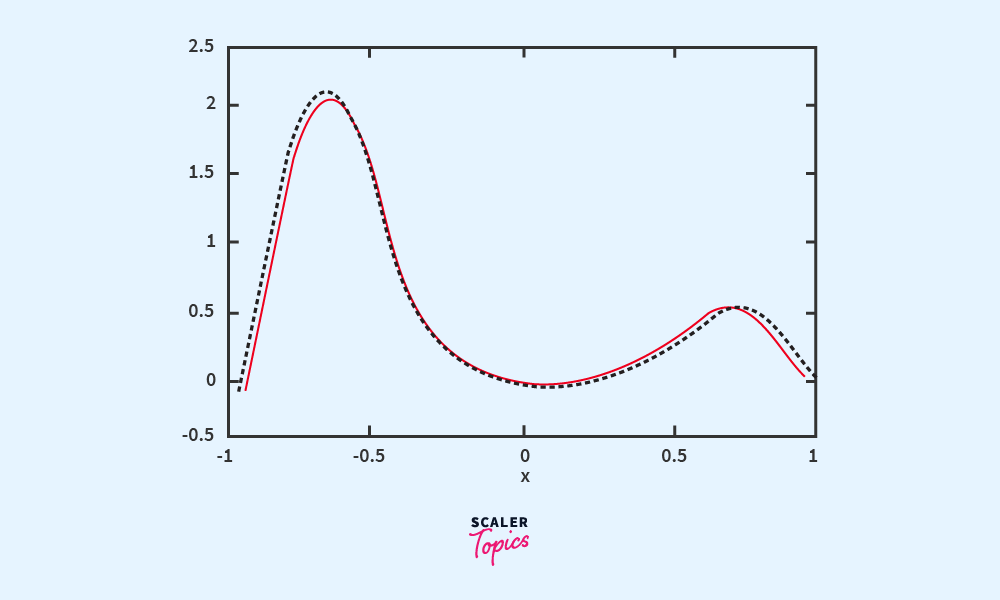
Regression
Here the output data is numbers instead of categories, e.g., predicting stock prices or prediction of marks of a student based on past performance.
Let’s have a small exercise to see if we notice the difference between classification and regression problems correctly.
Which of the following is/are classification problems?
- Predicting which political party wins the election based on area.
- Predicting your percentage in the board exams.
- Predicting if you’ll be selected for IIT-JEE exams.
- Predict the number of copies a music album will be sold next month
Answer: By definition, everything whose output is in the form of classes rather than numbers is a classification problem, and that’s why 1 and 3 are classification problems. Notice that it also makes sense to actually ask the question about your rank based on the score for IIT-JEE, and therefore it can be solved as a regression problem.
Implement Classification problem in Python
There are many different machine learning models readily available for all languages. These are known as classifiers, and popular examples include Logistic Regression, K-Nearest Neighbours (KNN), SVM, Kernel SVM, Naive Bayes, Decision Tree classification, XGBoost, RandomForest, etc. The mathematical understanding of how each of these classifiers works is beyond the scope of this article. The usual way the data scientists go about solving the classification problem is, they use their skills to understand which set of classifiers works best based on the data, and then run those on the dataset and pick the one that gets the best accuracy and/or precision, recall, etc.
Here we are looking at a simple implementation of one of the classifiers, Random Forest, to predict the optimal price of a mobile phone using data on phone prices of different brands and their specifications. The dataset can be downloaded from here.
Step 1: Importing libs: We are using some popular Python libraries like numpy, pandas, and matplotlib to get this working.
Step 2: Reading data from the training dataset.
Step 3: Here, we bifurcate the data into input, and output where everything except price_range is the input and y (price_range) is the output.
Step 4: Each dataset is broken into two parts. The first part is used to create/train the machine learning model, known as the training dataset, and the other part is used to test how our performance, known as test data.
Step 5: We use the sklearn library to implement random forest classifiers, and we give the input and output of our training data to do that.
Step 6: We calculate the accuracy of our test dataset using the same model, rfc.
The accuracy of this particular dataset comes up to 87.5%. You can look at the other classifiers at the link and see which ones work best for this dataset.
Advantages/Disadvantages Of Supervised Learning
- Supervised Learning only happens when the data is well trained, i.e., you’ve enough training data with correct output pre-defined.
- All supervised learning problems can be categorized into Classification or regression problems.
- Training data/Test data needs to have good pre-processing done on them. The classifiers will only be as good as the data it gets trained on.
- Overfitting is a problem that happens when you try to optimize to find the best accuracy/precision of the data at hand. Rather, building a good understanding of each of the classifiers and why they work is important to back the results.
Conclusion
- Machine learning is a new category of algorithms and ideology where machines can learn by themselves without human intervention by figuring out patterns on their own.
- Supervised learning is a type of machine learning in which labeled data is provided as input and the model is trained to recognize patterns in the data to give accurate outputs.