Types of Data Sources

Overview
Data Extraction is a process of acquiring, querying, and collecting large volumes of data. This data can be structured or unstructured and reside in many types of data sources. Data Scientists and Data Analysts need to have a good understanding of multiple types of data sources to interact with them efficiently during the Data Extraction phase.
What Is Data and Its Types?
There is no doubt that today’s world runs on data. Data has become integral to every organization’s decision-making and strategic planning process. Today, Organizations produce and store large volumes of data in multiple types of data sources. This data is typically in raw format that is not usable and understandable directly, but it needs to be collected, cleaned, and prepared before performing any analysis. Also, it is crucial to identify and collect information-rich data in the Data Extraction stage for an accurate and efficient analysis. Therefore, it is crucial to understand data and its types for various data professionals.
Types of Data
Data can be categorized into structured or unstructured formats. Based on statistics from Gartner, 80-90% of data is in unstructured format for most organizations. In the table below, let’s understand the key differences between these two data types -
| Structured Data | Unstructured Data |
| Structured Data is organized and has a fixed and defined schema. | Unstructured Data does not have any pre-defined structure to it. |
| Structured data is quantitative data that consists of numbers and values. | Unstructured data is qualitative data that consists of text, images, audio, video, etc. |
| Structured Data is stored in Relational Databases and Data warehouses. | Unstructured Data generally is stored in Data Lakes. |
| Structured Data is stored in tabular formats such as SQL databases. | It is typically stored in NoSQL databases. |
| It is collected from sensors, network logs, web server logs, OLTP systems, etc. | It is sourced from email messages, word-processing documents, pdf files, etc. |
| It requires less storage and is highly scalable. | It needs more storage space and is difficult to scale. |
Data Types Based on Its Collection
Based on how data is collected, it can be divided into two categories - Primary and Secondary data. Let’s review the key differences between these two types in the following table -
| Factor | Primary Data | Secondary Data |
| Definition | Primary Data refers to the first-hand data collected by the team. It is collected based on the researcher’s needs. | Secondary Data has been collected by other teams in the past. It does not necessarily need to be aligned with the researcher’s requirements. |
| Data | Real-time Data | Historical Data |
| Process | Time Consuming | Quick and Easy |
| Cost | Expensive | Economical |
| Collection Time | Long | Short |
| Available In | Raw and Crude form | Refined form |
| Accuracy and Reliability | Very high | Relatively less |
| Examples | Personal Interviews, Surveys, Observations, etc. | Websites, Articles, Research Papers, Historical Data, etc. |
Identifying and Gathering Data
In the Data Extraction stage, the first step is determining what data needs to be collected to solve the defined problem statement and objective. This data can reside in many types of data sources, and to collect it, we need to define a data collection strategy. In this step, we need to finalize how to interact with the respective source, how much duration of data is required, etc. So, let’s review some of the methods to gather data -
Databases
A Database can be defined as a systematic or organized collection of data. Database stores data in such a way that it can be easily accessed, retrieved, managed, and updated. A Database is usually controlled by a Database Management System (DBMS). Databases are prevalent in organizations for data storage because they make data management easy. A few of the most popular databases used are - MySQL, SQL Server, MongoDB, PostgreSQL, Oracle DB, etc.
Databases can be divided into various categories, but the most popular and common is Relational Databases (RDBMS). A Relational Database (RDBMS) can be defined as a collection of data items in tabular format, i.e., in the form of rows and columns. In RDBMS, the schema for each feature is pre-defined. A few of the most common Relational Databases are - MySQL, Oracle, etc. SQL (Structured Query Language) is used to interact with Relational Databases for data extraction. SQL is prevalent in organizations for information retrieval due to its simplified syntax.
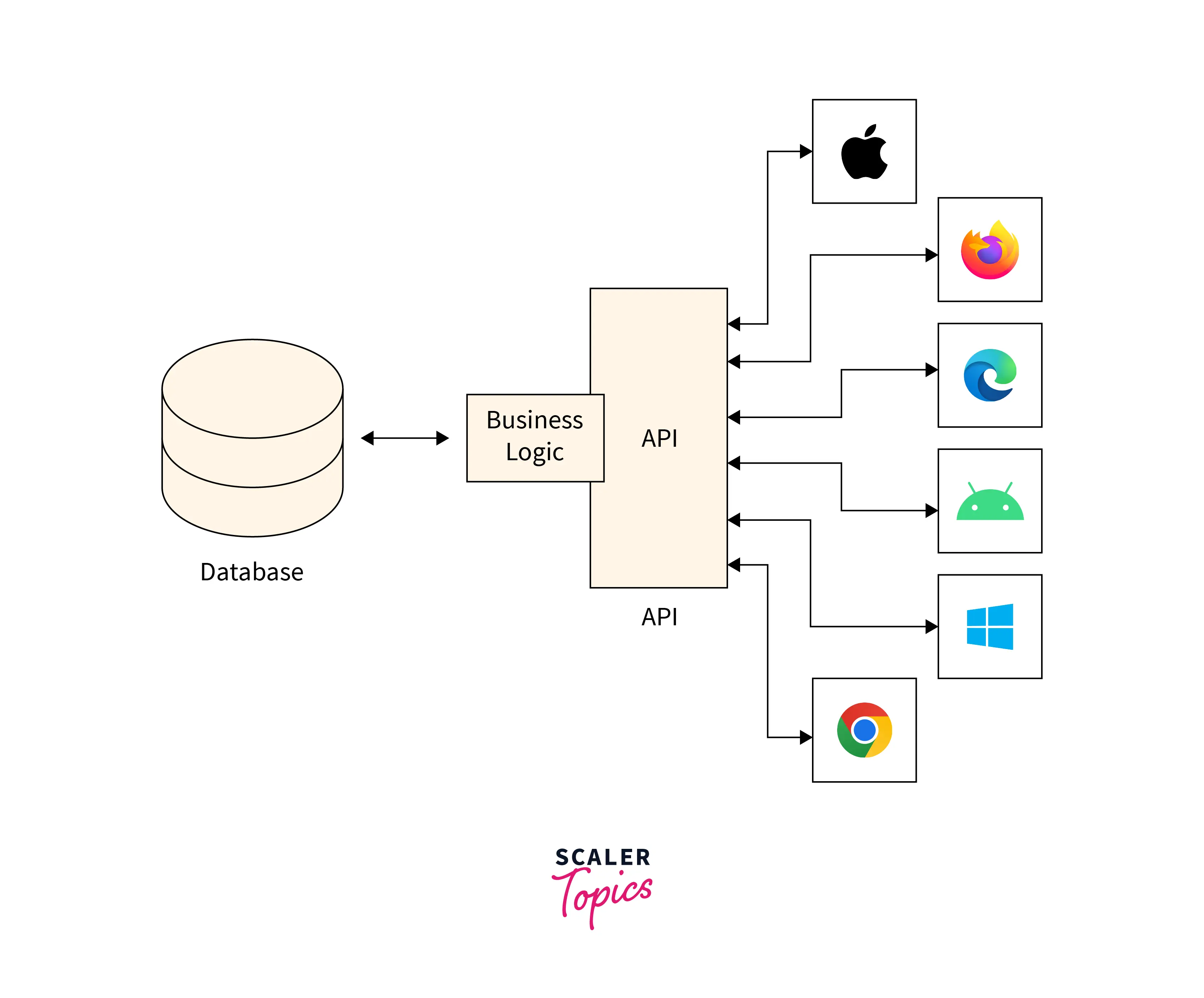
APIs
API stands for Application Programming Interface, enabling software components to communicate with each other using a set of defined protocols. Many Websites and Service Providers provide various APIs that allow users to access and extract data for further processing and analysis. Once a user or application calls an API, an HTTP/web request is made to the API provider’s server and returns specified data. APIs can return data in many formats, such as text, JSON, XML, HTML, etc.
Google provides various APIs to retrieve information from its search engine, maps, etc. Many popular social media websites, such as Twitter, Facebook, etc., provide APIs to access and extract required data for further analysis. For example, you can download tweets to perform sports analytics, sentiment analysis, consumer trends, etc.
Web Scraping
Web Scraping is a process of extracting content and data from the Internet. It provides automated methods to quickly scrape large amounts of data from websites or the Internet. Most of this data will be in unstructured or HTML format, which needs to be further parsed and transformed into a structured format. The most common data types extracted using Web Scraping include text, images, videos, pricing, reviews, product information, etc.
There are many ways you can perform Web Scraping to obtain meaningful data from websites. You can use online Web Scraping services or create custom-built code to scrape the information.
Data Streams
Data Streams provide continuously generated data, also called streaming data. Streaming data is continuously generated by thousands of sources such as IoT, sensors, social media, logs, etc., simultaneously sending in the data in small chunks. Streamed data is used for real-time data extraction, aggregation, and filtering. It allows Data Scientists and Analysts to access data instantly and derive actionable insights on the fly in real-time.
Don't miss out on the opportunity to become a data science expert. Enroll now in our free course and gain valuable insights into this exciting field.
Types of Data Sources
In today’s world, where data is the most crucial asset, organizations use a variety of data sources to collect data and support decision-making processes. Let’s look at different types of data sources organizations use for Big Data Analytics -
Internal Data
Internal data is the data captured and collected by an organization’s internal processes and systems. A few of the most common examples of internal data include -
- Transactional Data (customer purchase, equipment procurement, employee payroll, etc.)
- Sales and Marketing Data (Email opens, click rates, marketing campaigns, etc.)
- Consumer Data (Customer profiles, names, addresses, etc.)
- Customer Service and Support Data (customer calls, tickets, etc.)
- Online Activity/Browsing Data
Third-Party Analytics
In some case, when an organization does not have the capacity or resources to collect internal data for the analysis, they rely on third-party analytics tools and services to close internal gaps, collect required data and analyze it based on their requirements. For example, Google Analytics is a popular third-party analytics tool that can provide organizations insights to understand better how consumers use their websites.
External Data
As the name suggests, External Data is information that originates outside the organization and is available in the public domain. It can include social media posts, weather data, market prices, historical demographic data, etc. For example, organizations use social media posts from Twitter or Facebook to analyze consumer sentiment for their products.
Open Data
Open Data is accessible to everyone, and it is free to use. It comes with its own challenges, such as it can be highly aggregated, it might not be in the required format, etc. A few common examples of open data include - government data, health and science data, etc.
Conclusion
- In today’s world, data has become the most crucial asset for any organization worldwide. It has become integral to any organization's decision-making and strategic planning processes.
- Organizations rely on different types of data sources to collect data to drive their business decisions. These sources could be internal, external, or third-party. You need to define an efficient data collection strategy that can utilize databases, APIs, web scraping, etc., to collect data from various sources.
Ready to Dive Deeper? Explore the Practical Applications of These Concepts in Our Data Science Course and Turn Knowledge into Expertise.