Depth First Search (DFS) is an algorithm that is mainly used to traverse the graph data structure. The algorithm starts from an arbitrary node (root node in case of trees) and explore as far as possible in the graph before backtracking.
After backtracking it repeats the same process for all the remaining vertices which have not been visited till now.
In this article, one of the main algorithm to traverse the graph have been discussed i.e. Depth First Search Algorithm (DFS).
It contains an example showing the working process of the DFS algorithm along with its code in three languages i.e. Java, C/C++, and Python. At last complexity, and applications of the algorithm have been discussed.
Introduction of Depth First Seacrh (DFS) Algorithm
In Types of Graphs in Data Structure, we have seen what are the various type of data structures and how they differ from each other.
Now we will see how we can traverse the elements (nodes) of a given graph. Broadly, there are **two methods to traverse the graph viz. BFS and DFS. Today we will see the complete DFS algorithm.
DFS stands for depth first search which is one of the main graph algorithms. As suggested by the name, the main idea of the DFS Algorithm is to go as deep as possible in the graph and to come back (backtrack) when there is no unvisited vertex remaining such that it is adjacent to the current vertex.
Let’s see how we can approach the depth first search algorithm.
Approach of DFS
The idea of the depth-first search algorithm is to start from an arbitrary node of the graph and to explore as far as possible before coming back
Then backtrack and check for other unvisited nodes and repeat the same process for them.
Here backtracking means, “When all the neighbors of a vertex (say x so we return and check neighbors of the vertex that initiated the call to vertex x“
Let us understand how we can traverse the graph using DFS Algorithm through the following example.
Depth First Search Example
Let this be the given undirected graph with 7 vertices and 8 edges –
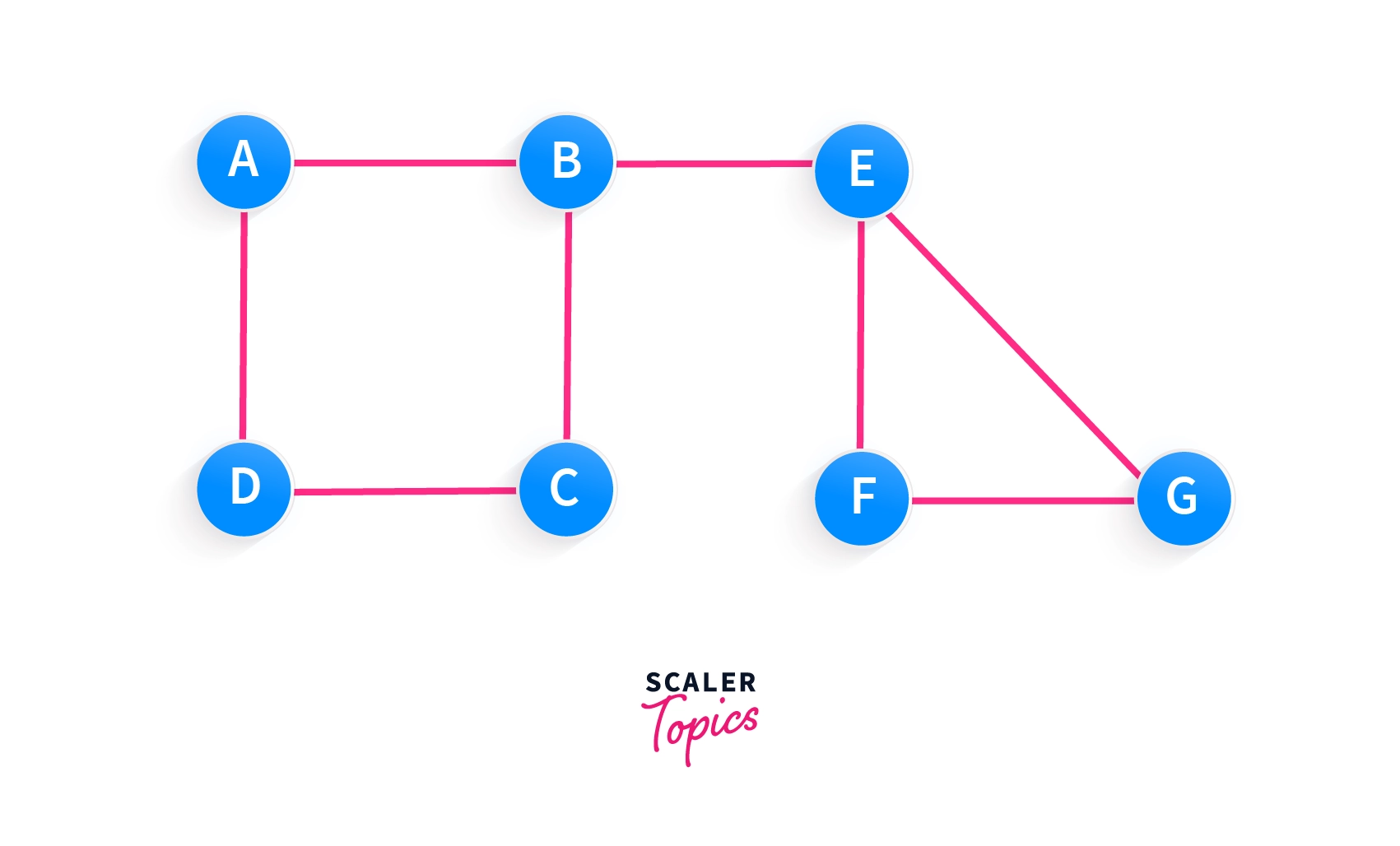
We can start our DFS process from any arbitrary vertex of the graph. Suppose we start our depth first search process from vertex A.
The only thing we must take care of during the DFS process is that “we must not visit already visited vertices again.”
- We have two choices
- We are having three choices
Let’s say we went to vertex - Now at
Let’s say we went to vertex - From vertex
- We don’t have any unvisited vertex adjacent to
- Now from
- From
- You can see now all the vertices have been traversed in the following order —
Algorithm of DFS Algorithm
Given Input:
Adjacency list of the given graph.
Required Output:
DFS traversal of the given graph.
Procedure:
- Create a recursive function that takes arguments as a boolean array
- Mark the current node as visited
visited[u]=True. - Print the current node
Print(u) - Search for all the adjacent vertices
As soon as unvisited vertex adjacent tov.
Pseudocode of DFS Algorithm
For DFS we have used an auxiliary boolean array of size
The visited array will keep information about which vertices have been already visited and which are not.
If we do not include this as part of our algorithm we have no way to find whether the next vertex is visited or not and if we don’t care about visited status we will get into an infinite loop (as then we will cycle between some pair of nodes indefinitely).
DFS(visited, u):
visited[u]=True
Print u
for each v in adj[u]:
if(visited[v]=False)
DFS(visited,v)DFS Algorithm Implementation in C, C++, and Java
For implementing DFS it is better to define a class
Data Members –
– It is the adjacency list, which is used to store graph data structre. – It denotes the total number of vertices, also Methods/Functions –
– A void type function which take two arguments and . It will add an undirected edge between and . – Again, a void type function with single argument as index of the node . It will declare a boolean array of size to hold information of already visited nodes.
Then it will call another functionwith arguments as and . – A void type fnction with two arguments as index of the current node and array.
It will mark and print the current nodeand then search and call itself recursively for all the univisted vertices adjacent to .
C/C++ implementation of DFS algorithm
#include<bits/stdc++.h>
using namespace std;
class Graph{
// V denotes the number of vertices,
// adj is the adjacency list of
// the graph.
int V;
map<int, list<int>> adj;
public:
// Constructor
Graph(int v){
// Initializing V
V=v;
}
// Function to insert an edge
// in the graph.
void insertEdge(int u,int v){
// Adding edge from u to v.
adj[u].push_back(v);
// Adding edge from v to u.
adj[v].push_back(u);
}
// A helper function for DFS.
void DFS_helper(int u,bool visited[]){
// Marking u as visited
visited[u]=true;
// Printing it's value
cout<<u<<endl;
// Checking for all the
// nodes adjacent to u.
for(int v: adj[u]){
// If any node is not visited
// till now.
if(!visited[v])
{
// Then, call DFS_helper with index
// as v.
DFS_helper(v,visited);
}
}
}
// DFS function
void DFS(int u){
// Declaring a boolean
// visited array of size V.
bool visited[V];
// Calling DFS_helper function
// with index as u.
DFS_helper(u,visited);
}
};
// Driver Function
int main(){
// Declare a object
// of graph type.
Graph g(7);
// Add all the edges through
// insertEdge function.
g.insertEdge(0,1);
g.insertEdge(0,3);
g.insertEdge(1,4);
g.insertEdge(1,2);
g.insertEdge(2,3);
g.insertEdge(4,5);
g.insertEdge(4,6);
g.insertEdge(5,6);
cout<<"The DFS traversal of the given graph starting from node 0 is -"
// Call for DFS with
// index as 0.
g.DFS(0);
return 0;
}Implementation of DFS algorithm
// Java program tod print DFS
// traversal of a given graph.
// Importing necessary
// modules for Input/Output.
import java.io.*;
import java.util.*;
class Graph{
// V denotes the number of vertices,
// adj is the adjacency list of
// the graph.
private int V;
private List<List<Integer>> adj;
// Constructor
Graph(int V){
// Initializing V
// and adj.
this.V=V;
adj=new ArrayList<>();
// Inserting V empty lists
// in the adjacency list.
for(int i=0;i<V;i++)
adj.add(new ArrayList<>());
}
// Function to insert an edge
// in the graph.
void insertEdge(int u,int v){
// Adding edge from u to v.
adj.get(u).add(v);
// Adding edge from v to u.
adj.get(v).add(u);
}
// A helper function for DFS.
void DFS_helper(int u,boolean visited[]){
// Marking u as visited
visited[u]=true;
// Printing it's value
System.out.println(u);
// Checking for all the
// nodes adjacent to u.
for(int v: adj.get(u)){
// If any node is not visited
// till now.
if(!visited[v])
{
// Then, call DFS_helper with index
// as v.
DFS_helper(v,visited);
}
}
}
// DFS function
void DFS(int u){
// Declaring a boolean
// visited array of size V.
boolean visited[]=new boolean[V];
// Calling DFS_helper function
// with index as u.
DFS_helper(u,visited);
}
// Driver Function
public static void main(String args[]){
// Declare an object
// of graph type.
Graph g=new Graph(7);
// Add all the edges through
// insertEdge function.
g.insertEdge(0,1);
g.insertEdge(0,3);
g.insertEdge(1,4);
g.insertEdge(1,2);
g.insertEdge(2,3);
g.insertEdge(4,5);
g.insertEdge(4,6);
g.insertEdge(5,6);
System.out.println("The DFS traversal of the given graph starting from node 0 is -");
// Call for DFS with
// index as 0.
g.DFS(0);
}
}Python Implementation of DFS algorithm
from collections import defaultdict
class Graph:
# Constructor
def __init__(self):
# Initializing Adajency list.
self.adj=defaultdict(list)
# Function to insert an edge
# in the graph.
def insertEdge(self, u, v):
# Adding edge from u to v.
self.adj[u].append(v)
# Adding edge from v to u.
self.adj[v].append(u)
# A helper function for DFS.
def DFS_helper(self, u, visited):
# Marking u as visited
visited.add(u)
# Printing its value
print(u)
# Checking for all the
# node adjacent to u.
for v in self.adj[u]:
# If any adjacent node is
# not visited till now.
if(v not in visited):
# Then, call DFS_helper with index
# as v.
self.DFS_helper(v, visited)
# DFS function
def DFS(self, u):
# Declaring a visited set.
visited=set()
# Calling DFS_helper function
# with index as u.
self.DFS_helper(u,visited)
# Declaring an object
# of graph type.
g=Graph()
# Add all the edges through
# insertEdge function.
g.insertEdge(0,1)
g.insertEdge(0,3)
g.insertEdge(1,4)
g.insertEdge(1,2)
g.insertEdge(2,3)
g.insertEdge(4,5)
g.insertEdge(4,6)
g.insertEdge(5,6)
# Call for DFS with
# index as 0.
print("The DFS traversal of the given graph starting from node 0 is -")
g.DFS(0)Output
The DFS traversal of the given graph starting from node
Complexity Analysis of DFS Algorithm
Time complexity: Since we consider every vertex exactly once and every edge at most twice, therefore time complexity isSpace Complexity:
Bonus Tip
The bonus tip here can be a savior for you, because it will save your code to fail on the edge cases. Because the above code is written by assuming that the provided graph is connected.
What if the given graph is disconnected in nature. If you don’t know what do connected and disconnected graphs mean how do they differ please refer to – Connected and Disconnected Graphs.
The above given code will only print the vertices of the component to which starting vertex belongs to. To overcome this problem we will tweak our code a little so that it can print all the vertices of the graph no matter whether they are connected or not.
We only need to change the
// DFS function
void DFS(int u){
// Declaring a boolean
// visited array of size V.
boolean visited[]=new boolean[V];
// Calling DFS_helper function
// with index as u.
DFS_helper(u,visited);
// After an initial call check
// if still, some vertex are
// not visited.
for(int i=0;i<V;i++)
// If found then, call
// DFS_helper for them with
// index as i.
if(!visited[i])
DFS_helper(i,visited);
}And that’s it  , by including three more lines of code we can also handle disconnected graphs.
, by including three more lines of code we can also handle disconnected graphs.
Applications of DFS Algorithm
There are numerous applications of the Depth first search algorithm in graph theory. DFS Algorithm can be used in solving most problems involving graphs or trees. Some of its popular applications are –
- Finding any path between two vertices
- Finding the number of connected components present in a given undirected graph.
- For doing topological sorting of a given directed graph.
- Finding strongly connected components in the directed graph.
- Finding cycles in the given graph.
- To check if the given graph is Bipartite in nature.
Equip yourself to tackle complex C++ projects with confidence. Enroll in Data Structures in C++ Course by Scaler Topics now!
Wrapping Up
- In this article, we have seen what is depth first search algorithm is, how it is implemented, and its time complexity.
- We have seen how we can implement it, PseudoCode along with codes in two main languages viz. Java and C/C++ have been discussed.
- Also in the bonus tip section, handling the corner cases involving the dis-connected graph has been explained.