Distributed Database System in DBMS

Overview
A distributed database is a database that is not limited to one computer system. It is like a database that consists of two or more files located in different computers or sites either on the same network or on an entirely different network. Instead of storing all of the data in one database, data is divided and stored at different locations or sites which do not share any physical component.
Introduction to Distributed Database System in DBMS
A distributed database is a database system that spans multiple computers or nodes that are connected by a network. Each node in a distributed database can store a portion of the data, and the entire database is made up of the sum of the data stored on each node.
In a distributed database, data is stored and processed in a distributed manner, and the system ensures that the data remains consistent and available to users despite network failures or other system errors. The primary goal of a distributed database is to provide high availability, scalability, and performance to applications that require access to large amounts of data.
Need of Distributed Database In Dbms
Let's start with the databases and their types,
- A database is an structured collection of information. The data can be easily accessed, managed, modified, updated, controlled, and organized in a database.
- Databases can be broadly classified into two types, namely Distributed and Centralized databases. The question here is why do we even need a Distributed Database In Dbms?. Let's assume for a moment that we have only centralized databases.
- We will be inserting all the data into one single database. Making it too large so that it will take a lot of time to query a single piece of record.
- Once a fault occurs, we no longer be able to serve user requests as we have only one database.
- No scaling is possible even if we wanted to and availability is also less which in turn affects the throughput.
Distributed databases resolve various issues, such as availability, fault tolerance, throughput, latency, scalability, and many other problems that can arise from using a single machine and a single database. That's why we need distributed databases. Let's discuss them in detail.
Distributed Databases
- A distributed database is a database that is not limited to one computer system. It is like a database that consists of two or more files located in different computers or sites either on the same network or on an entirely different network.
- These sites do not share any physical component. Distributed databases are needed when a particular data in the database needs to be accessed by various users globally. It needs to be handled in such a way that for a user it always looks like one single database.
- By contrast, a Centralized database consists of a single database file located at one site using a single network.
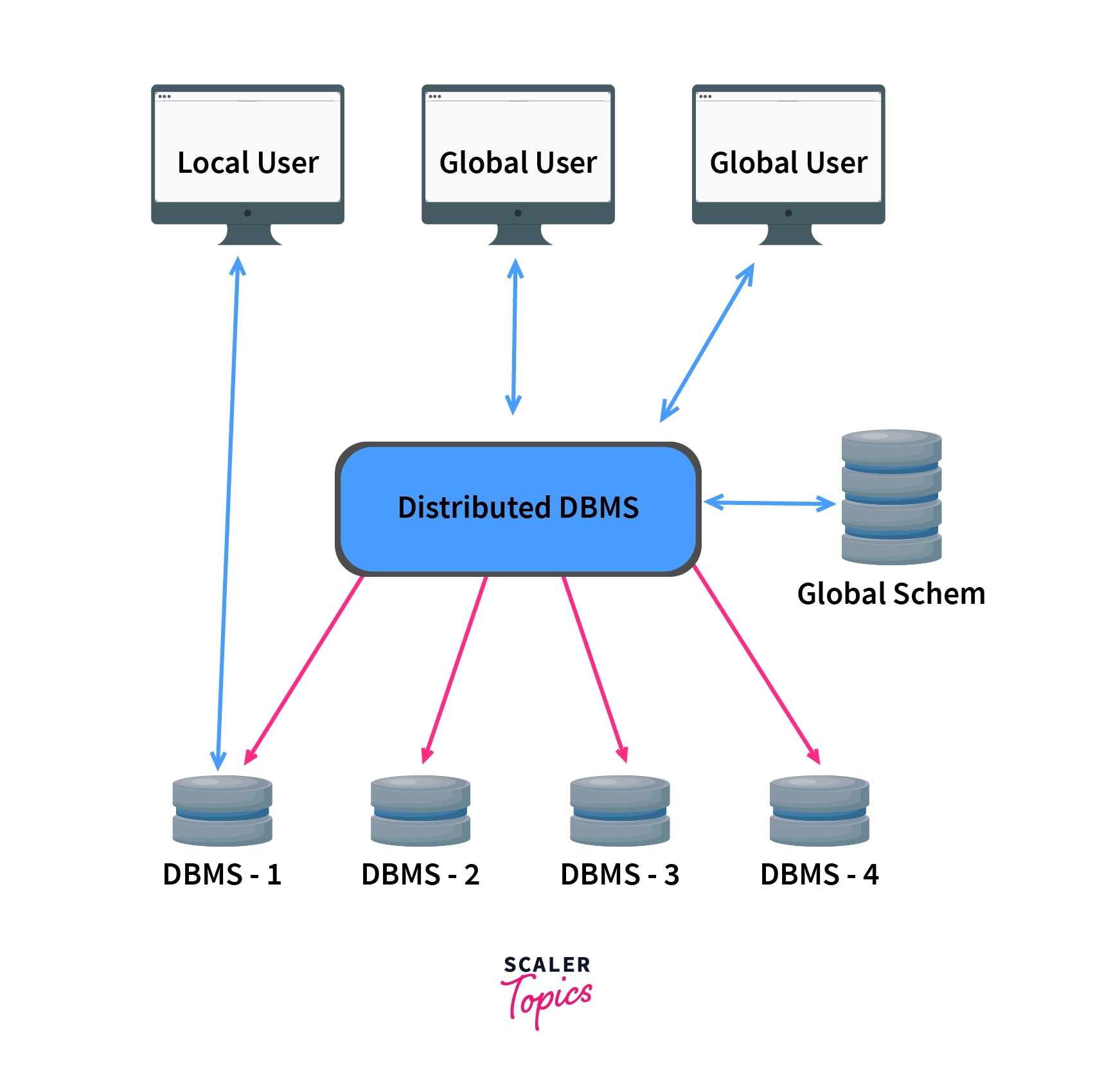
- Below is a reference diagram for distributed databases.
- Though there are many distributed databases to choose from, some examples of distributed databases include Apache Ignite, Apache Cassandra, Apache HBase, Amazon SimpleDB, Clusterpoint, and FoundationDB.
Features of Distributed Databases
In general, distributed databases include the following features:
- Location independency: Data is independently stored at multiple sites and managed by independent Distributed database management systems (DDBMS).
- Network linking: All distributed databases in a collection are linked by a network and communicate with each other.
- Distributed query processing: Distributed query processing is the procedure of answering queries (which means mainly read operations on large data sets) in a distributed environment.
- Query processing involves the transformation of a high-level query (e.g., formulated in SQL) into a query execution plan (consisting of lower-level query operators in some variation of relational algebra) as well as the execution of this plan.
- Hardware independent: The different sites where data is stored are hardware-independent. There is no physical contact between these Distributed Database In Dbms which is accomplished often through virtualization.
- Distributed transaction management: Distributed Database In Dbms provides a consistent distribution through commit protocols, distributed recovery methods, and distributed concurrency control techniques in case of many transaction failures.
Types of Distributed Database In Dbms
There are two types of distributed databases:
- Homogenous distributed database.
- Heterogeneous distributed database.
Homogenous Distributed Database
- A Homogenous distributed database is a network of identical databases stored on multiple sites. All databases stores data identically, the operating system, DDBMS and the data structures used – all are same at all sites, making them easy to manage.
- Below is a diagram for the same,
Heterogeneous Distributed Database
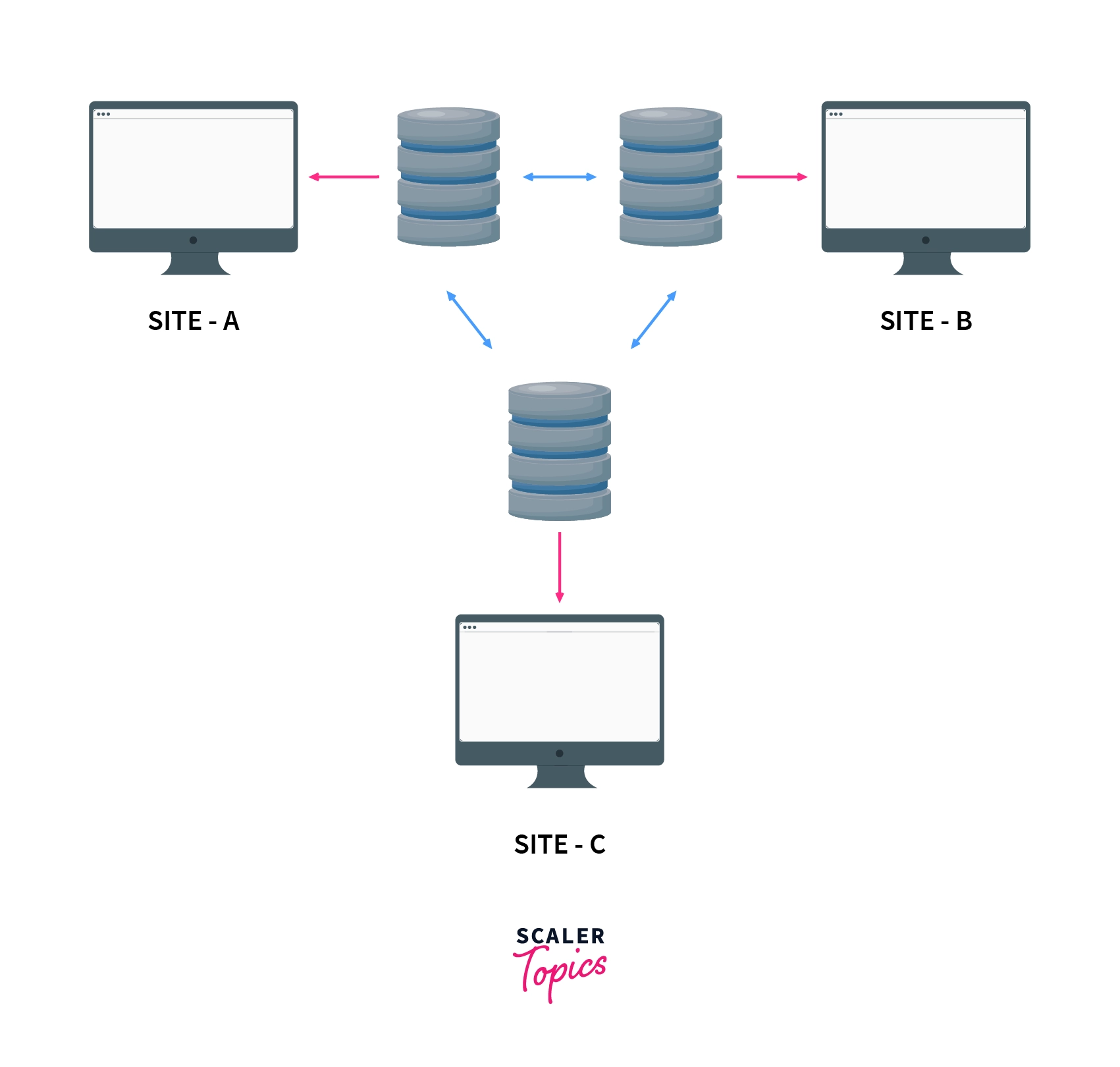
- It is the opposite of a Homogenous distributed database. It uses different schemas, operating systems, DDBMS, and different data models causing it difficult to manage.
- In the case of a Heterogeneous distributed database, a particular site can be completely unaware of other sites. This causes limited cooperation in processing user requests, this is why translations are required to establish communication between sites.
- Below is a diagram for the same,
Note: Heterogenous DDMS have local users while Homogenous DDMS does not have local users
Distributed Data Storage
In this section we will talk about data stored at different sites in distributed database management system.
-
There are two ways in which data can be stored at different sites. These are,
- Replication.
- Fragmentation.
Replication
- As the name suggests, the system stores copies of data at different sites. If an entire database is available on multiple sites, it is a fully redundant database.
- The advantage of data replication is that it increases availability of data on different sites. As the data is available at different sites, queries can be processed parallelly.
- However, data replication has some disadvantages as well. Data needs to be constantly updated and synchronized with other sites, if any site fails to achieve it then it will lead to inconsistencies in the database. Availability of data is highly benefitted from Replication.
- Constant updation complicates concurrency control and it is also overhead for the servers.
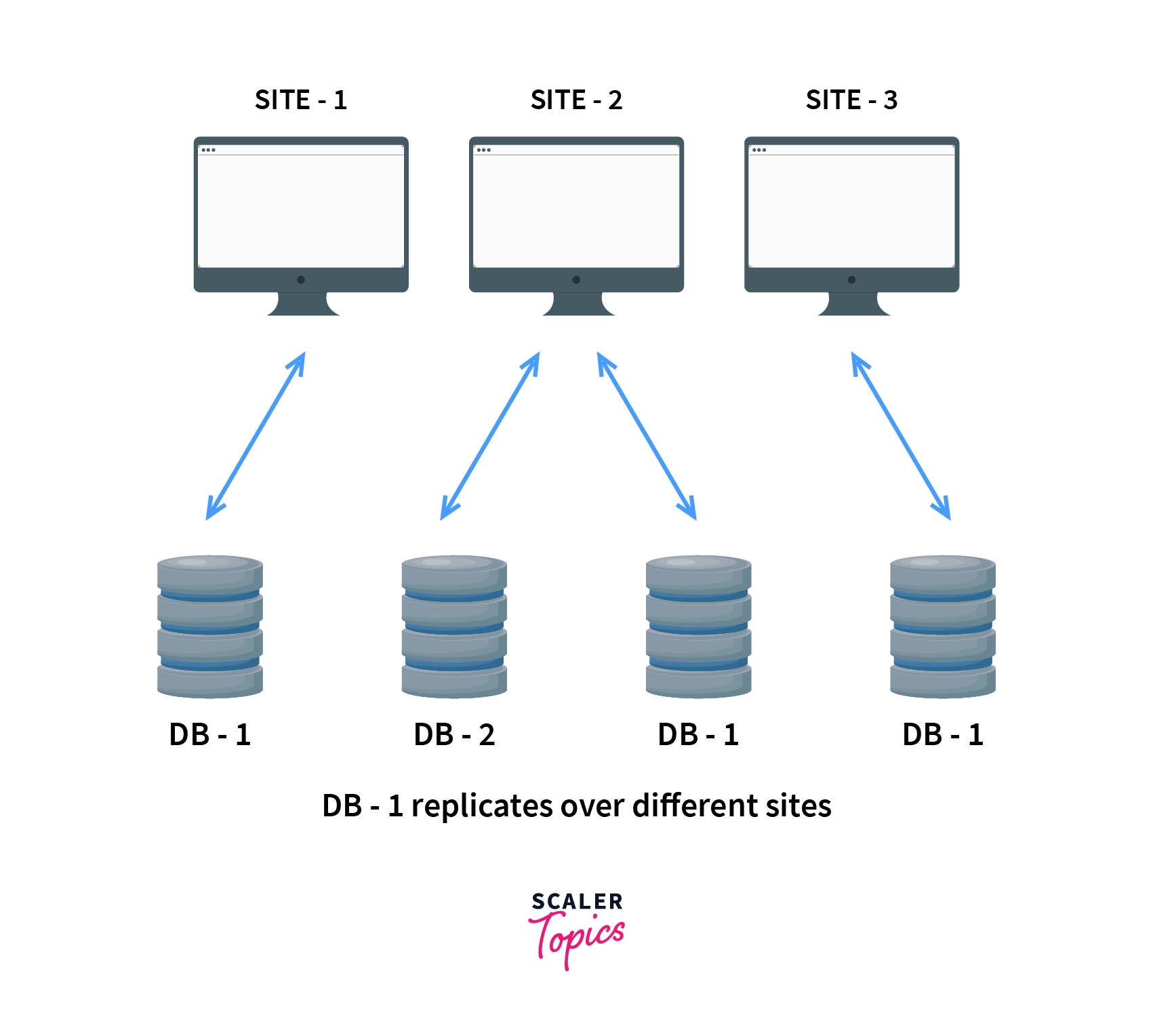
Note: DB-1 replicates on different sites, creating copies of the same data.
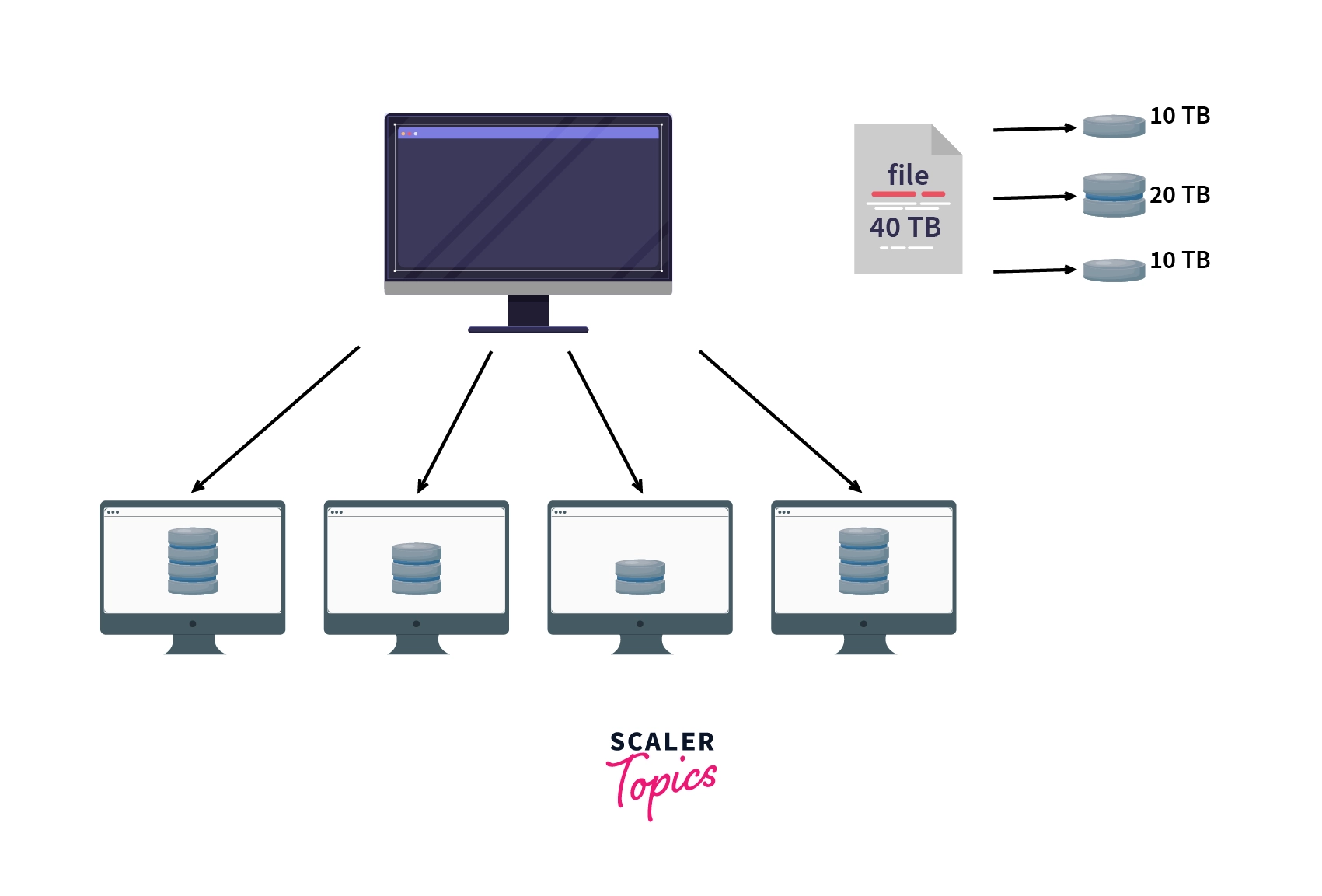
Fragmentation
- In Fragmentation, the relations are fragmented, which means they are split into smaller parts. Each of the fragments is stored on a different site, where it is required. In this, the data is not replicated, and no copies are created. Consistency of data is highly benefitted from Fragmentation.
- The prerequisite for fragmentation is to make sure that the fragments can later be reconstructed into the original relation without losing any data.
- Consistency is not a problem here as each site has a different piece of information.
- There are two types of fragmentation,
- Horizontal Fragmentation – Splitting by rows.
- Vertical fragmentation – Splitting by columns.
Horizontal Fragmentation(or Sharding)
- The relation schema is fragmented into group of rows, and each group is then assigned to one fragment.
Vertical Fragmentation
- The relation schema is fragmented into group of columns, called smaller schemas. These smaller schemas are then assigned to each fragment.
- Each fragment must contain a common candidate key to guarantee a lossless join.
Advantages of Distributed Database In Dbms
- Better Reliability: Distributed databases offers better reliability than centralized databases. When database failure occurs in a centralized database, the system comes to a complete stop. But in the case of distributed databases, the system functions even when a failure occurs, only performance-related issues occur which are negotiable.
- Modular Development: It implies that the system can be expanded by adding new computers and local data to the new site and connecting them to the distributed system without interruption.
- Lower Communication Cost: Locally storing data reduces communication costs for data manipulation in distributed databases. In centralized databases, local storage is not possible.
- Better Response Time: As the data is distributed efficiently in distributed databases, this provides a better response time when user queries are met locally. While in the case of centralized databases, all of the queries have to pass through the central machine which increases response time.
Disadvantages of Distributed Database In Dbms
- Costly Software: Maintaining a distributed database is costly because we need to ensure data transparency, coordination across multiple sites which requires costly software.
- Large Overhead: Many operations on multiple sites require complex and numerous calculations, causing a lot of processing overhead.
- Improper Data Distribution: If data is not properly distributed across different sites, then responsiveness to user requests is affected. This in turn increases the response time.
Conclusion
- A database is a structured collection of information. Databases can be broadly classified into two types, namely Distributed and Centralized databases.
- Distributed databases resolve various issues, such as availability, fault tolerance, throughput, latency, scalability, and many other problems that can arise from using a single machine and a single database.
- A distributed database is like a database that consists of two or more files located in different computers or sites either on the same network or on an entirely different network. These sites do not share any physical component.
- There are two types of distributed databases.
- Homogenous distributed database.
- Heterogeneous distributed database.
- There are many advantages of distributed databases Availability, Reliability, Better response time are a few of them. On the other hand, maintaining a Distributed Database In Dbms is very costly in terms of hardware cost and maintenance.