Autoencoders with Convolutions
Overview
In the absence of labels in a dataset, only a few models can perform well. The Convolutional Autoencoder is a model that can be used to re-create images from a dataset, creating an unsupervised classifier and an image generator. This model uses an Encoder-Bottleneck-Decoder architecture to understand the latent space of the dataset and re-create the images.
Introduction
To be able to learn how to re-create a dataset, a model must have an understanding of the underlying latent space. The Convolutional Autoencoder compresses the information in an image dataset by applying successive convolutions. This output is passed to a Bottleneck layer, the smallest possible dataset representation. Using this compressed representation, the Decoder attempts to recreate the original dataset. In the process of re-creation, the compressed output resembles a sort of Dimensionality Reduction procedure, while the Reconstruction Loss can be used as a classification metric.
This article explores the architecture and methods behind creating a Convolutional Autoencoder.
What is an Autoencoder?
The convolutional Autoencoder is a type of neural network that can reduce noise in data by learning the underlying structure of the input. It comprises three parts: an Encoder that compresses the input while preserving useful features, a Bottleneck that selects important features, and a Decoder that reconstructs the data. The Encoder compresses the input data into a lower-dimensional representation, called the Bottleneck or latent space. The Decoder then takes the compressed input data and tries to reconstruct the original data. The bottleneck layer is responsible for choosing the most important features and passing them through to the Decoder. Training the Autoencoder involves comparing the original input data to the reconstructed data and adjusting the network weights to minimize the reconstruction error.
The architecture diagram of a convolutional autoencoder is shown below.
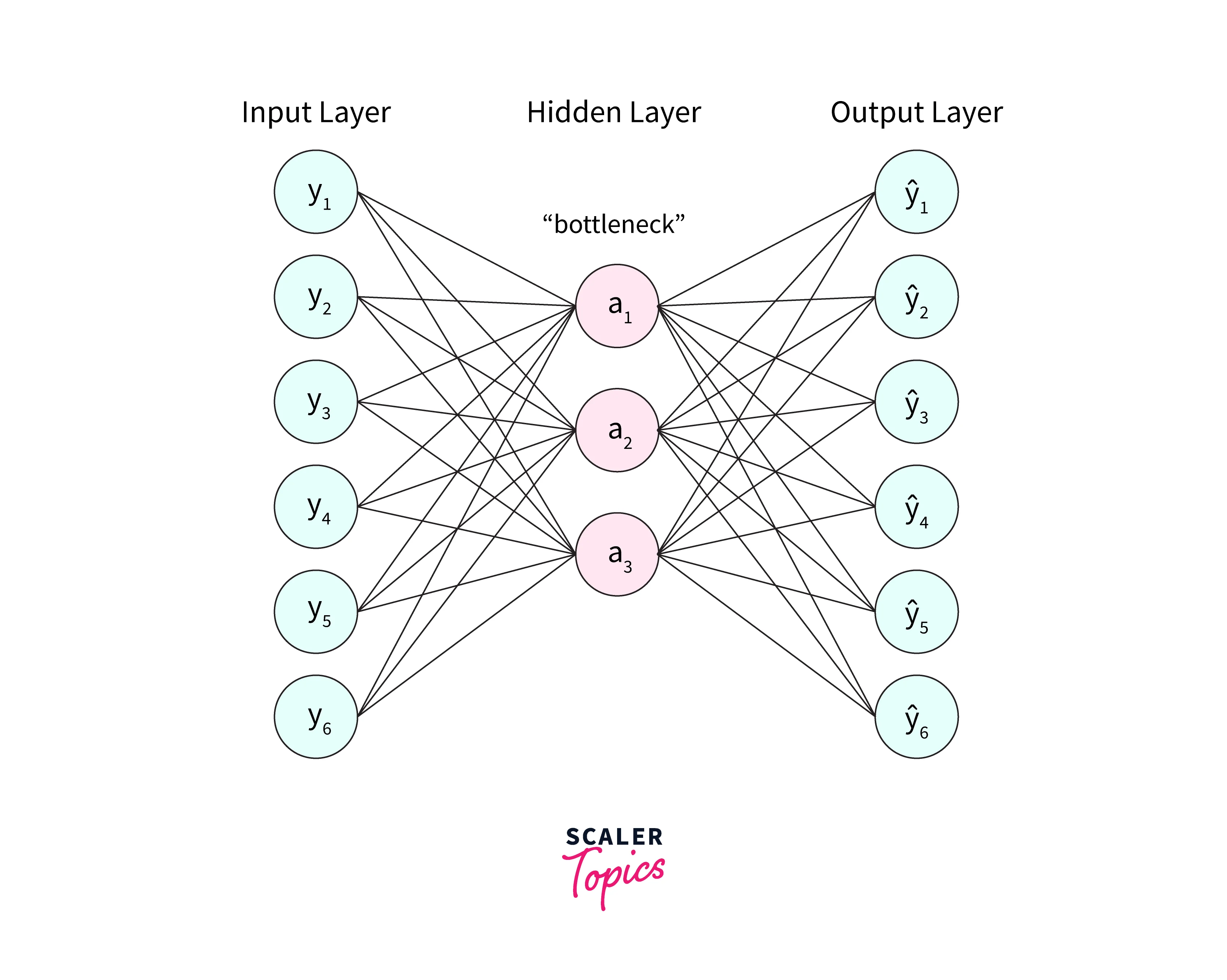
Encoder Structure
The Encoder part of the network is to compress the input data and passes it to the Bottleneck layer. The compression creates a knowledge representation much smaller than the original input but has most of its features.
This part of the network comprises blocks of convolutions followed by pooling layers that, in turn, further help to create a compressed data representation. The output of an ideal Encoder should be the same as the input but with a smaller size. The Encoder should be sensitive to the inputs to recreate it and not over-sensitive. Being over-sensitive would make the model memorize the inputs perfectly and then overfit the data.
Bottleneck Layer
The Bottleneck is the most important layer of an Autoencoder. This module stores the compressed knowledge that is passed to the Decoder. The Bottleneck restricts information flow by only allowing important parts of the compressed representation to pass through to the Decoder. Doing so ensures that the input data has the maximum possible information extracted from it and the most useful correlations found. This part of the architecture is also a measure against overfitting as it prevents the network from memorizing the input data directly.
Note that smaller bottlenecks lead to lesser overfitting (to an extent).
Decoder Structure
This part of the network is a "Decompressor" that attempts to recreate an image given its latent attributes. The Decoder gets the compressed information from the Bottleneck layer and then uses upsampling and convolutions to reconstruct it. The output generated by the Decoder is compared with the ground truth to quantify the network's performance.
Latent Space Structure
The latent space of a network is the compressed representation it creates from an input dataset. This latent space usually has hundreds of dimensions and is hard to visualize directly. More complex neural networks have latent spaces so hard to visualize that they are generally called black boxes. In a convolutional autoencoder, the better the representation of the data, the richer the latent space. The space structure here is a large matrix of tensors that encode the weights of network layers.
Uses of Autoencoder
The Convolutional Autoencoder architecture is good for a lot of use cases. Some of these are explained below.
1. Reducing Complexity:
The Encoder of the model works very well as a dimensionality reduction technique. For example, if we consider an image dataset, we can compress every image before feeding it to another model. This compression reduces the number of input values and thus makes the model less likely to be biased toward smaller details. The Autoencoder thus helps in improving the performance of a second model.
2. Anomaly Detection:
An Autoencoder is generally used for reconstructing the base data using an Encoder-Bottleneck-Decoder architecture. Thus if the output reconstruction has a much larger error for a given sample, this sample could be an outlier. We can thus use the reconstruction error to find unusual data points in a dataset.

3. Unsupervised Learning:
A convolutional Autoencoder's information compression ability is a good start for an unsupervised learning problem. Using the Autoencoder as a dimensionality reduction technique allows the data to be clustered without any labels much more easily. This clustering may not be useful but can be a starting point for many other solutions.
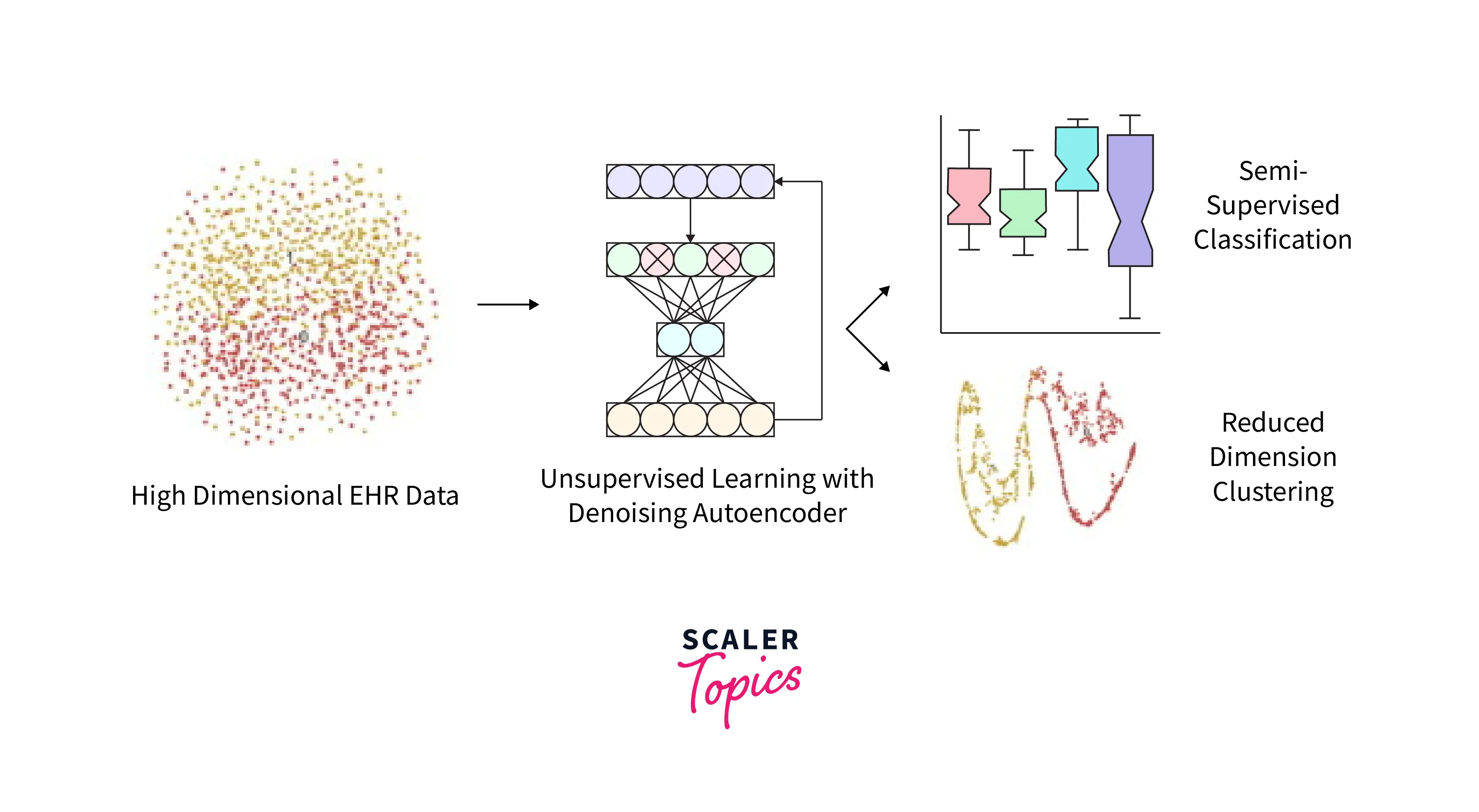
4. Image Compression:
Autoencoders can be used for image compression by training the network on a dataset of images and then using the encoder part of the network to compress new images. The compressed images can then be reconstructed by the decoder part of the network, resulting in a trade-off between image quality and compression ratio. This approach can achieve a high compression rate with minimal loss of image quality compared to traditional image compression methods. Autoencoders can also be used for lossy image compression, where some information is lost during the compression process, but the overall image quality is still maintained.
What is a Convolutional Neural Network?
A CNN, or convolutional neural network, is a key component of deep Learning that can learn to identify patterns in input data by analyzing examples of that data. A CNN generally comprises an input, multiple hidden layers, and an output. CNNs use groups of neurons to recognize patterns and perform various tasks like identifying objects, similar grouping items, and separate parts of an image. CNNs are useful because they can understand spatial and temporal dependencies given large amounts of data by learning feature "filters". Complex CNNs can model large amounts of data previously impossible for a computer to understand.
A simple CNN is shown below.
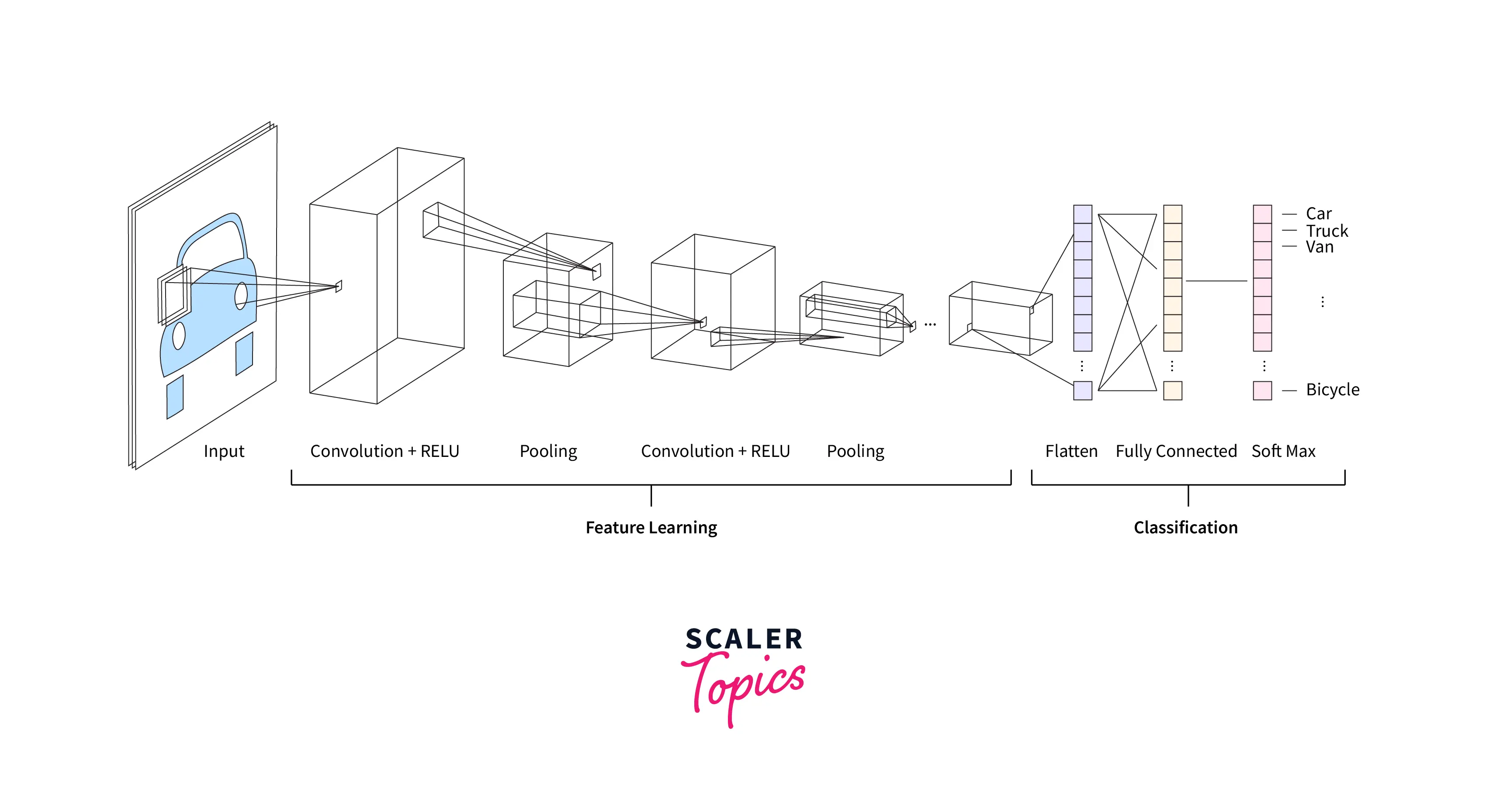
The convolutional Autoencoder, a CNN-based architecture, is the focus of this article.
Implementation of an Autoencoder
The Convolutional Autoencoder has a few hyper-parameters that must be tweaked before training. The section below discusses these hyper-parameters, the Reconstruction loss used, and the general implementation of the architecture of a simple convolutional Autoencoder.
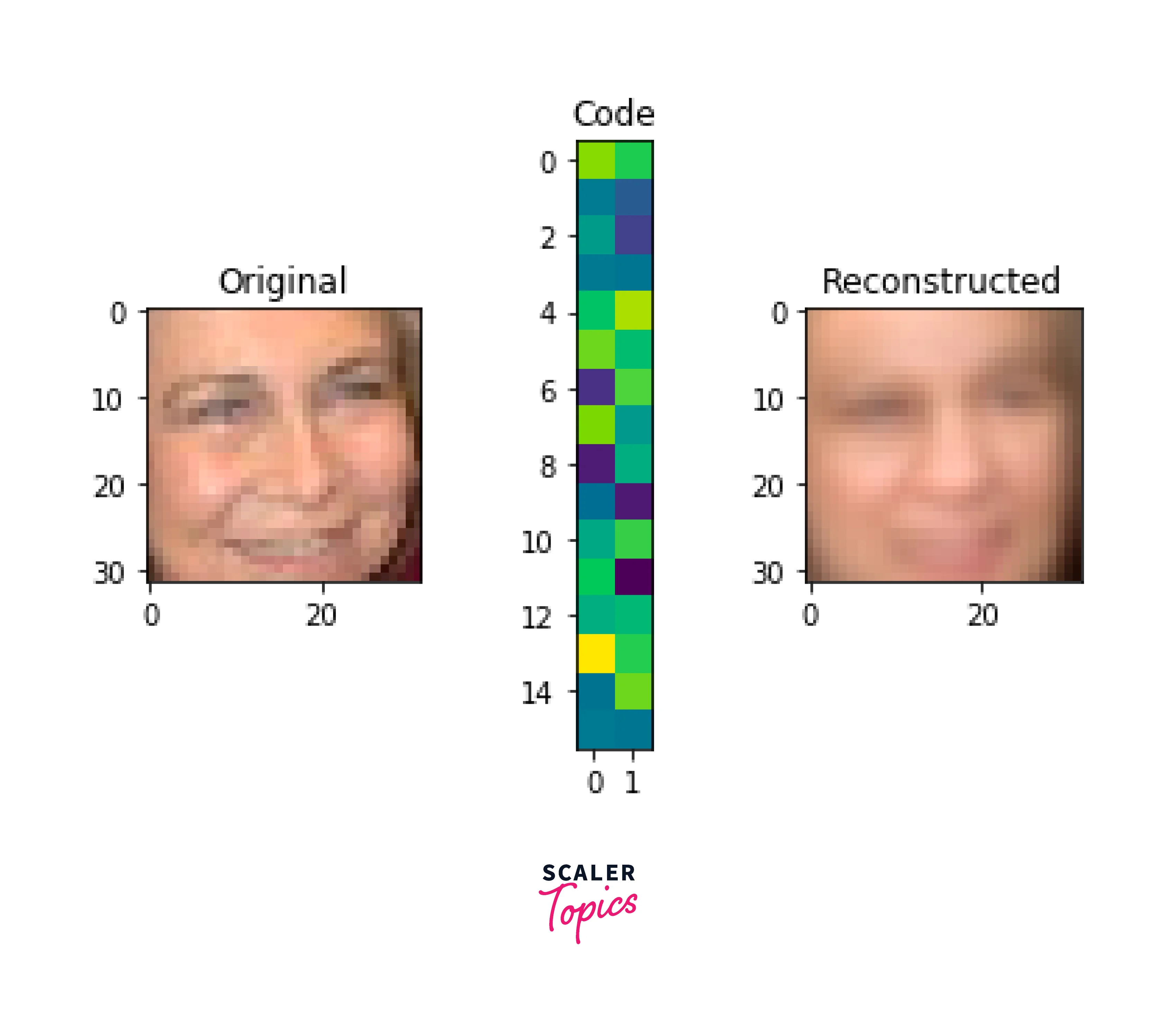
An example use case would be to re-create the MNIST dataset. The following image shows the input and output of an Autoencoder trained on such a task. The first row is the original input and the second row is the output of the Autoencoder. In this case, a perfect reconstruction is obtained.

Code Size
The code size is defined as how large the bottleneck layer is, consequently deciding to what extent the input data is compressed before being Decoded. The code size is the most important hyper-parameter to tune.
Number of Layers
The convolutional Autoencoder is similar to other types of networks in that the number of layers is a hyper-parameter. Note that increasing the number of layers increases the time to train a network. A higher model depth also increases inference time.
Number of Nodes Per Layer
This hyper-parameter controls the weights per layer. As a general rule, the number of nodes decreases in the Encoder and increases in the Decoder.
Reconstruction Loss
The loss function the convolutional Autoencoder is trained to minimize is called the reconstruction error. This loss function depends on the type of data we use. In the case of image-based data, the reconstruction loss can be either an MSE, an L1, or Binary Cross Entropy loss.
Encoder
The Encoder can be created with a stack of 2D Convolutions starting with a large size and slowly reducing in dimensions. Each of the convolutions is followed by a 2D Max-Pooling layer. The ReLU activation is used throughout.
In Keras, the Encoder can look something like this.
Decoder
The Decoder comprises blocks of 2D convolutions followed by Up Sampling layers. This part of the network looks something like the following in Keras.
We can find a complete demonstration of the code to re-create the MNIST dataset on this link.
Conclusion
- Convolutional Autoencoders are a powerful unsupervised learning technique.
- The article explained the Encoder-Bottleneck-Decoder architecture in detail.
- The Reconstruction Loss obtained is a valuable classification and image generation resource.
- The article also explained multiple use cases, such as Anomaly Detection, Complexity Reduction, etc.
- This article also provided a template for implementing a Convolutional Autoencoder in Tensorflow.