Introduction to EfficientNet
Overview
One of the more important in a wide variety of Convolution Neural Networks is EfficientNet. It has offered better performance compared to all of its predecessors. EfficientNet is the product of Compound Scaling and Neural Architecture Search(NAS). We'll deep-dive into the specifics of EfficientNet in this article.
What is DenseNet?
DenseNet is a type of Deep Learning Architecture that uses convolution layers. It is an improved version of its predecessor, ResNet(Residual Network). Residual network improved on traditional Convnet architecture by concatenating the previous layer's output to the next layer. This architecture solves the problem of the vanishing/exploding gradient problem when the number of layers increases. DenseNet has lesser parameters to train than CNN or ResNet. CNN has many redundant layers which can be dropped. The DenseNet architecture overcomes that the previous layers are re-used, and only a small feature map is added in each layer.
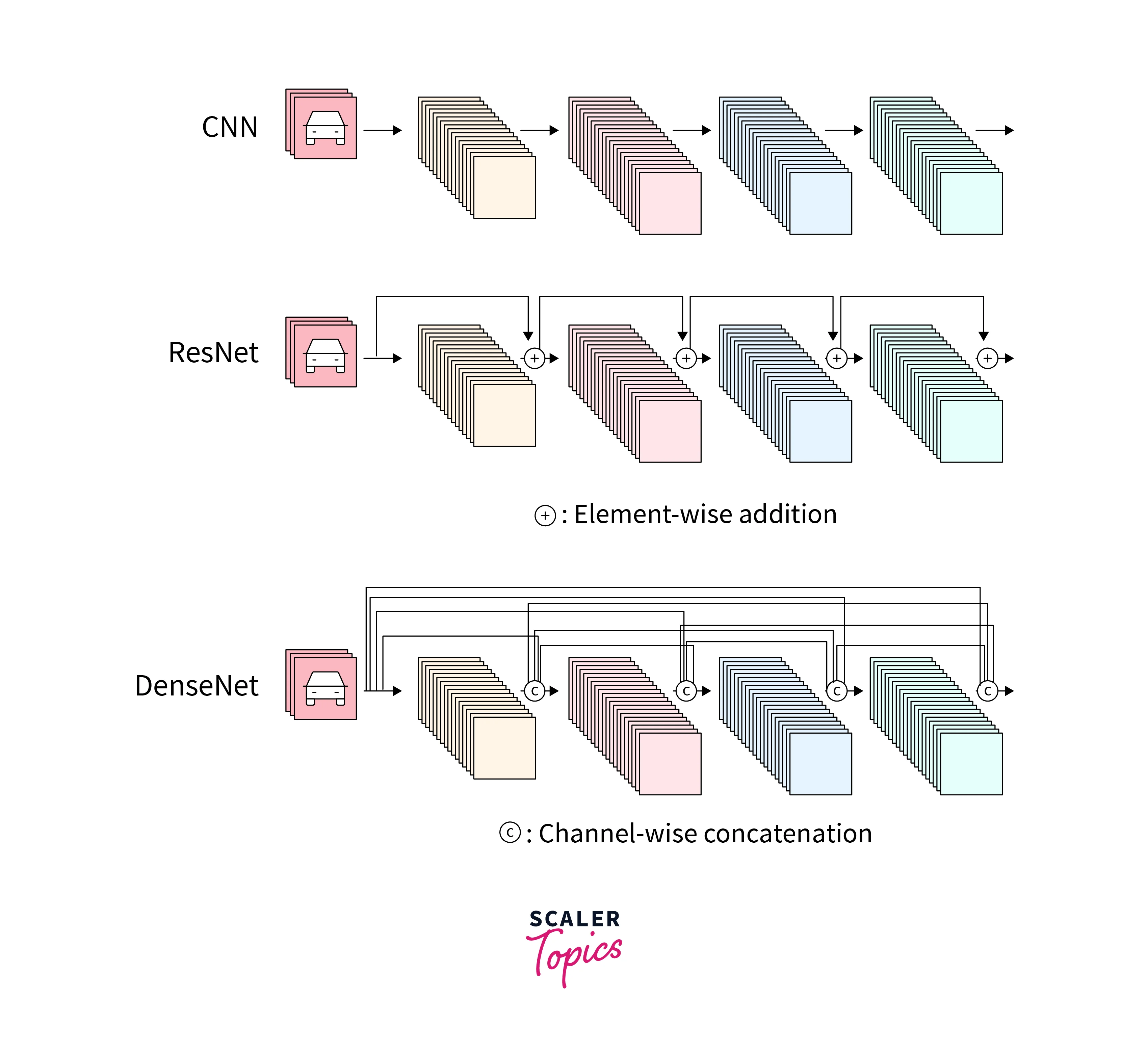
DenseNet improves on ResNet by concatenating all previous layer outputs to the next layer. , For example,, Layer 4 would have input containing output from layers 1, 2, and 3. This enables the deeper layers to carry the information of the initial layers and helps improve the performance.
Why Use DenseNet?
DenseNet has a few advantages over ResNet. Along with solving the problem of Vanishing/Exploding Gradient, DenseNet has improved performance. This is because DenseNet has a strong Gradient Flow, meaning the error correction in the training phase is better implemented. Even the initial layers are error corrected directly as passed to the last layer. This brings about "direct supervision". DenseNet has better parameters and computational efficiency compared to ConvNet and ResNet. It also maintains low-level features in the higher layers. For example, the feature map of the initial layers' low-level features is also used to identify higher-level features in the last layers.
Introduction to EfficientNet
EfficientNet is a type of Neural Network architecture that uses compound Scaling to enable better performance. EfficientNet aims to improve performance while increasing computational efficiency by reducing the number of parameters and FLOPs(Floating point Operations Per Second).
Generally, in CNN architectures, the scaling-up process(increasing the number of layers) is hard work, as there are numerous ways to scale up. Choosing the best combination is very time-consuming if done manually. The scaling-up process is also handled in EfficientNet using Compound Scaling and NAS(Neural Architecture Search), which is explained later in the article.
Efficient Net has two parts:
- Create an efficient baseline architecture using NAS
- Use the Compound Scaling Method while scaling up to enhance performance
EfficientNet Architecture

The baseline architecture is very important, as the scaling-up process enhances the baseline model performance. So better the baseline model, the better the final performance after scaling. The general compound scaling method can be applied to other architectures like ResNet, so baseline architecture performance is very important.
The above architecture is formed using NAS(Neural Network Architecture). NAS is the operation of searching for the most effective Neural Network architecture, which has the least losses and is the most computationally efficient. This architecture uses Mobile inverted Bottleneck Convolution(MBConv), similar to the one found in MobileNetV2 architecture. This baseline architecture is then scaled up by compound scaling to obtain a family of EfficientNet models.
Compound Scaling
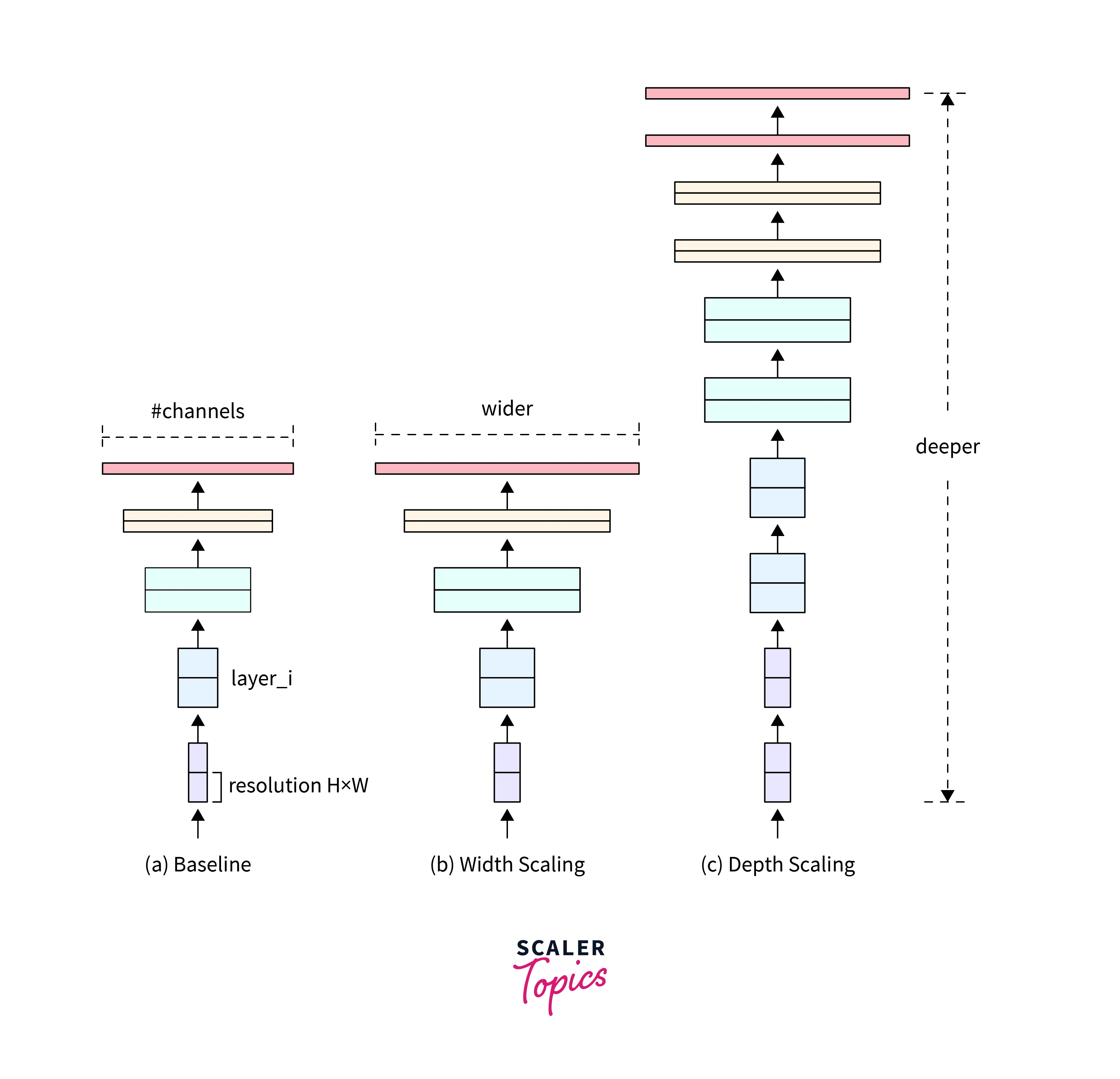
There are three ways to scale up:
- Width scaling
- Depth scaling
- Resolution scaling
Scaling up using either of the three methods results in better performance, but the increase in performance saturates and doesn't improve after a point. For example, a 100-layer network and a 500-layer Network would perform similarly.
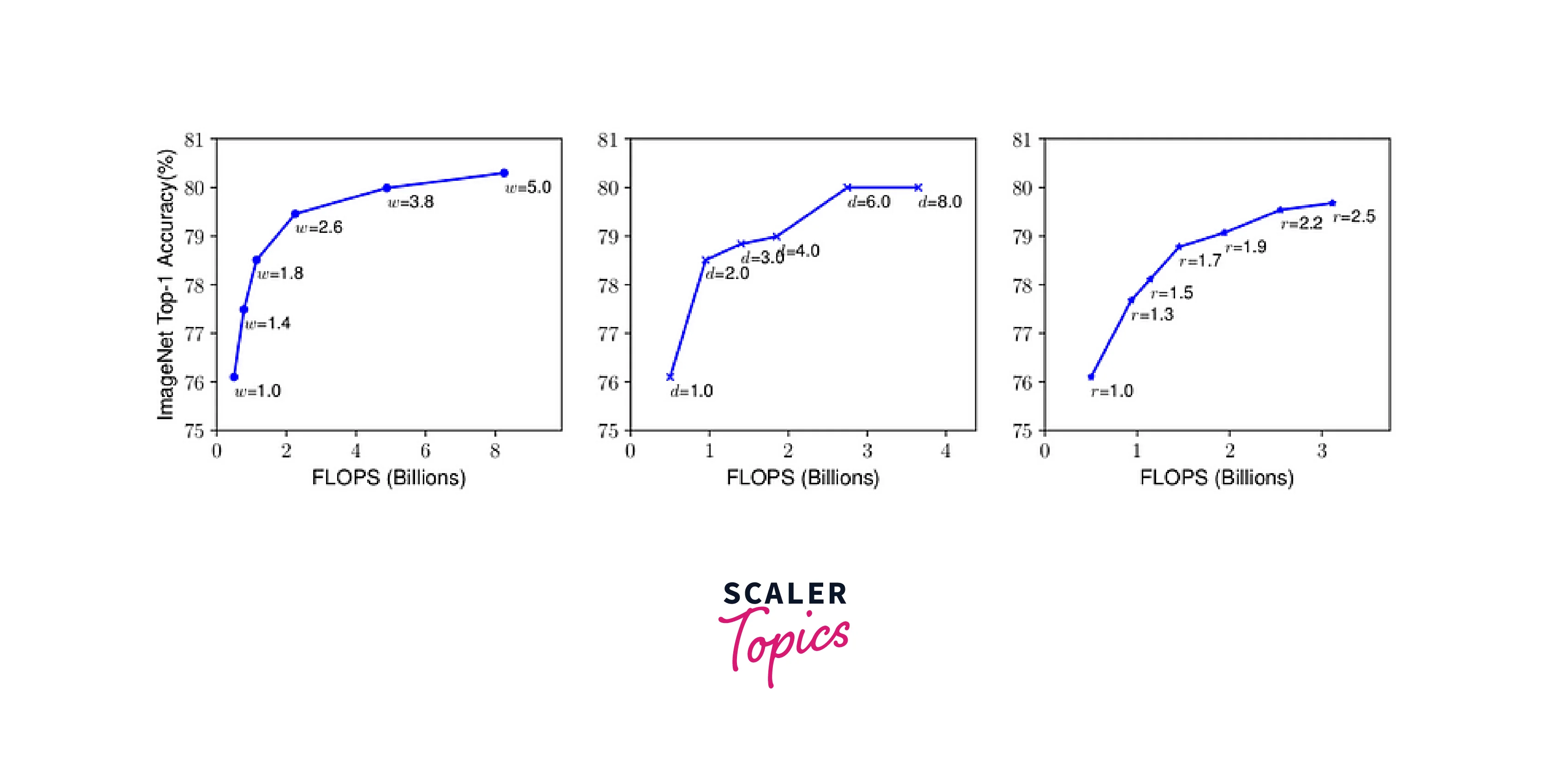
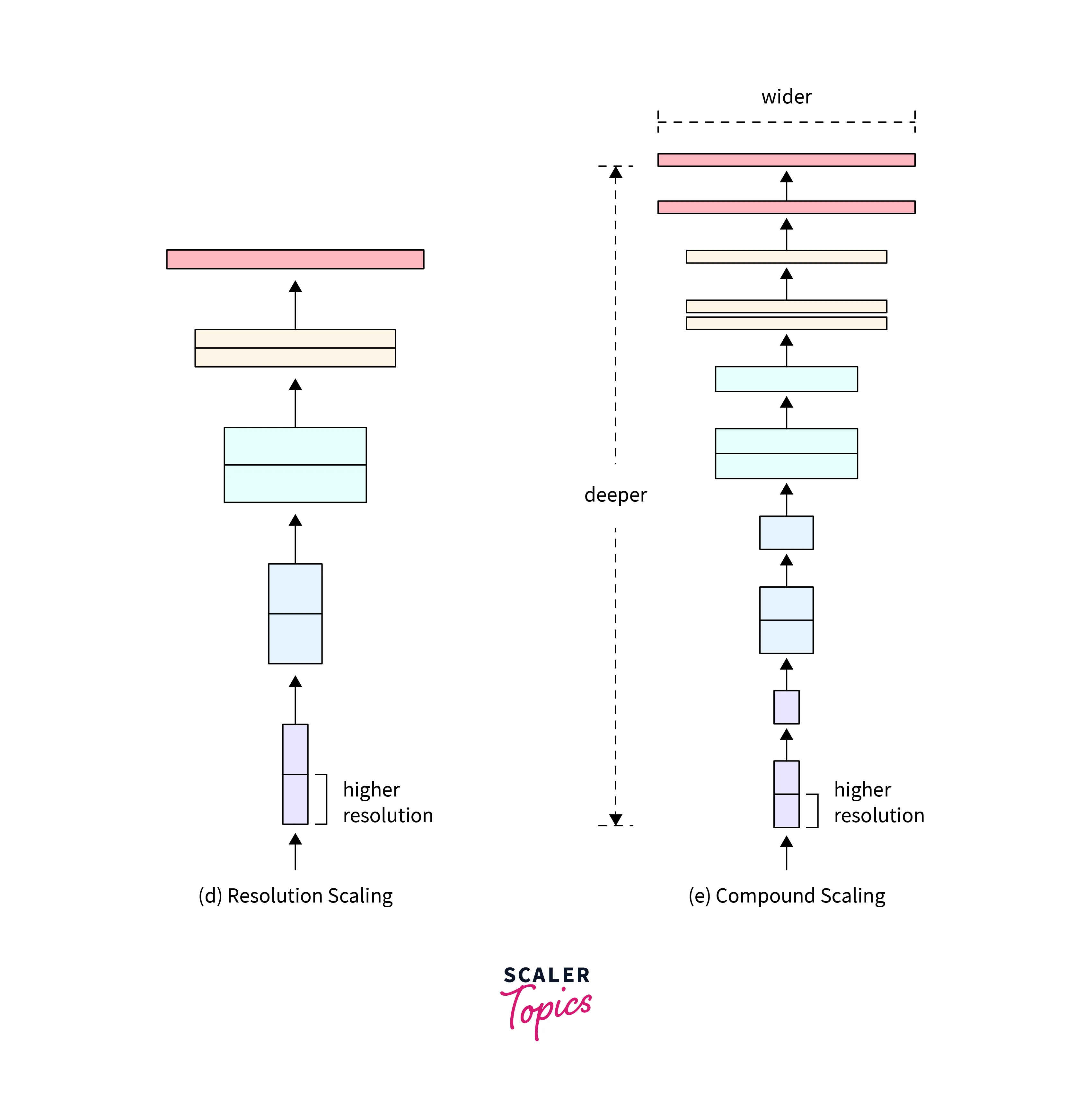
It was seen that better results were produced when a combination of the methods was used than just one method. For example, we can see from the below image that the best result is produced when both resolution and width are increased instead of increasing them individually.
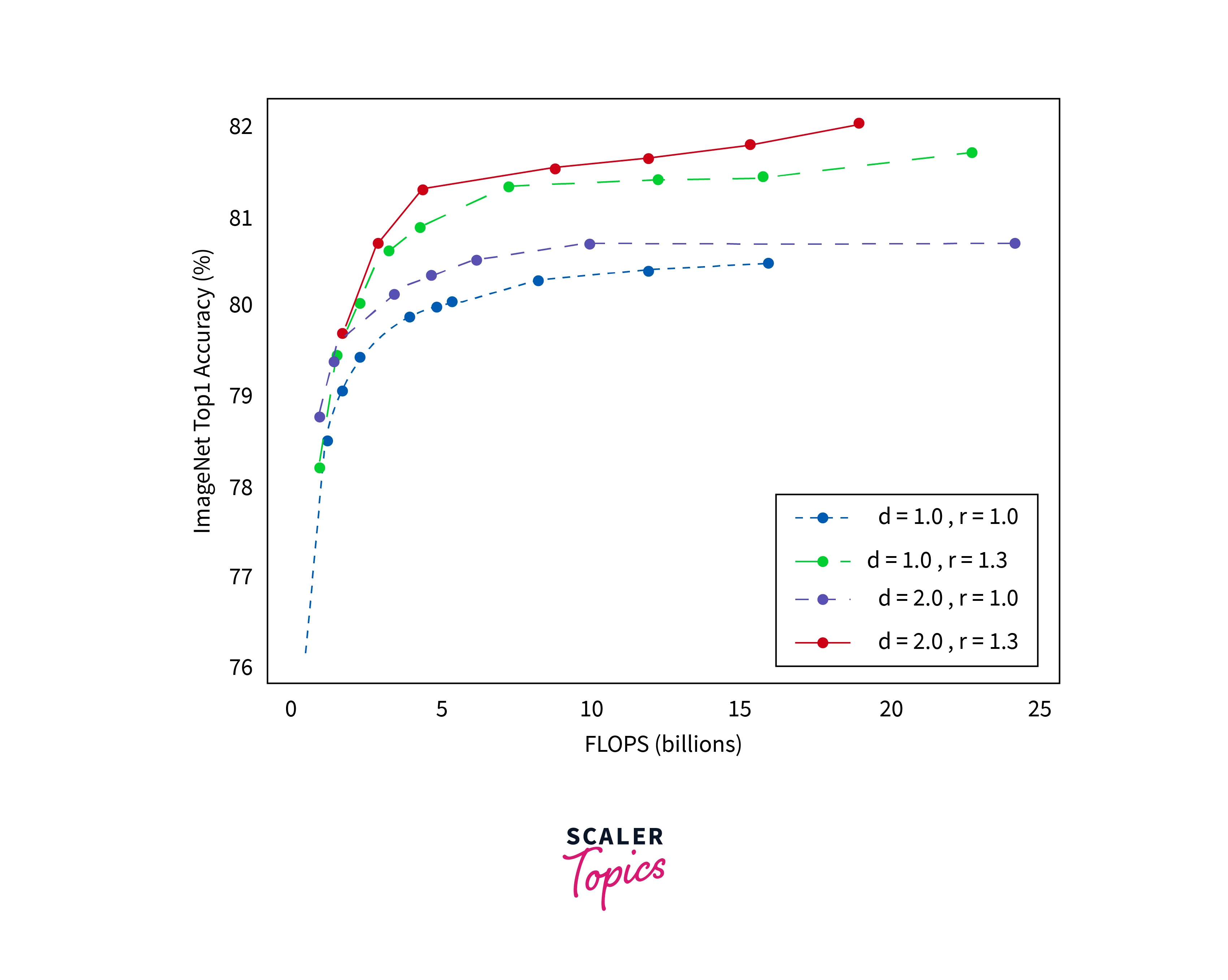
This can be understood more intuitively. When the width is increased, the number of pixels is increased. So now, the same number of Convolution layers will not be able to capture the same number of features as it could when the width is smaller. So the depth should also be increased to accommodate the increased width to capture the features.
This method of scaling up by using all three parameters is compound scaling. This is achieved by keeping the value of the parameters balanced. So that one parameter doesn't overshadow the other as it would reduce the performance. We use the below equation to keep it balanced.
depth : =
width : =
resolution: =
such that,
, ,
We can see that the values are expressed in terms of alpha, Beta, and Gamma and raised to a certain power. Their product is equated to zero. The goal is to maintain the constant to keep the scaling balanced. We notice width and resolution are raised to power 2. This corresponds to the effect that the variable has on FLOPS. Doubling the depth doubles the FLOPS value while doubling the width and resolution multiplies the FLOPS by 4 times, respectively. So those two parameters are raised to power 2. This compound scaling method is a general technique and can be applied to our EfficientNet-B0 architecture to obtain the EfficientNet family of models.
EfficientNet Architecture Using NAS
Neural Architecture Search or NAS is finding more efficient and Optimized architectures with better performance with several parameters in mind. It searches and evaluates many architectures within the search space to find the best model for the given task.
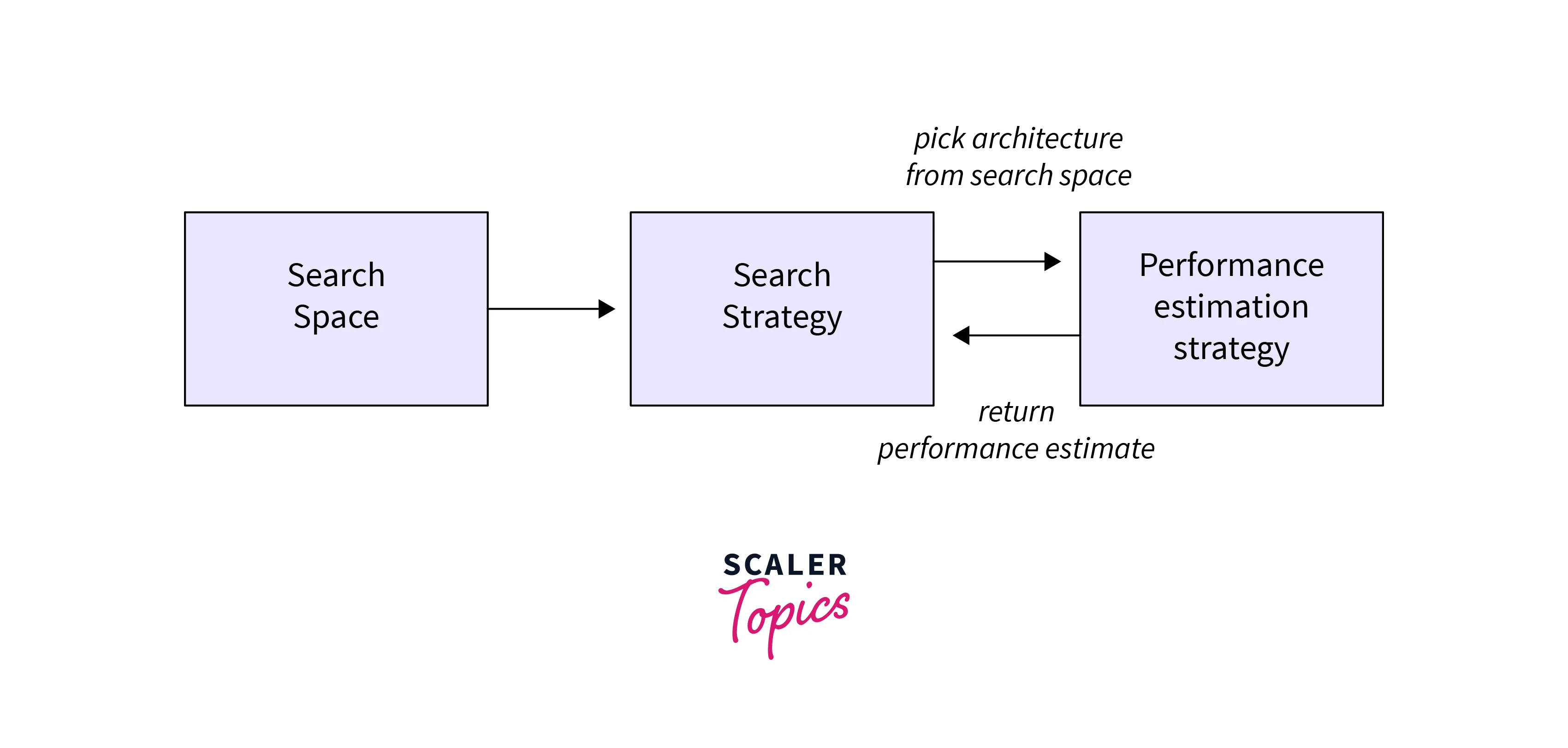
This NAS technique is at the core of the EfficientNet architecture. NAS is used to find the most powerful architecture while checking the number of parameters giving a very efficient and optimized model.
EfficientNet Performance
The EfficientNet Model is compared with other architectures, and their parameters are compared in the graph below.
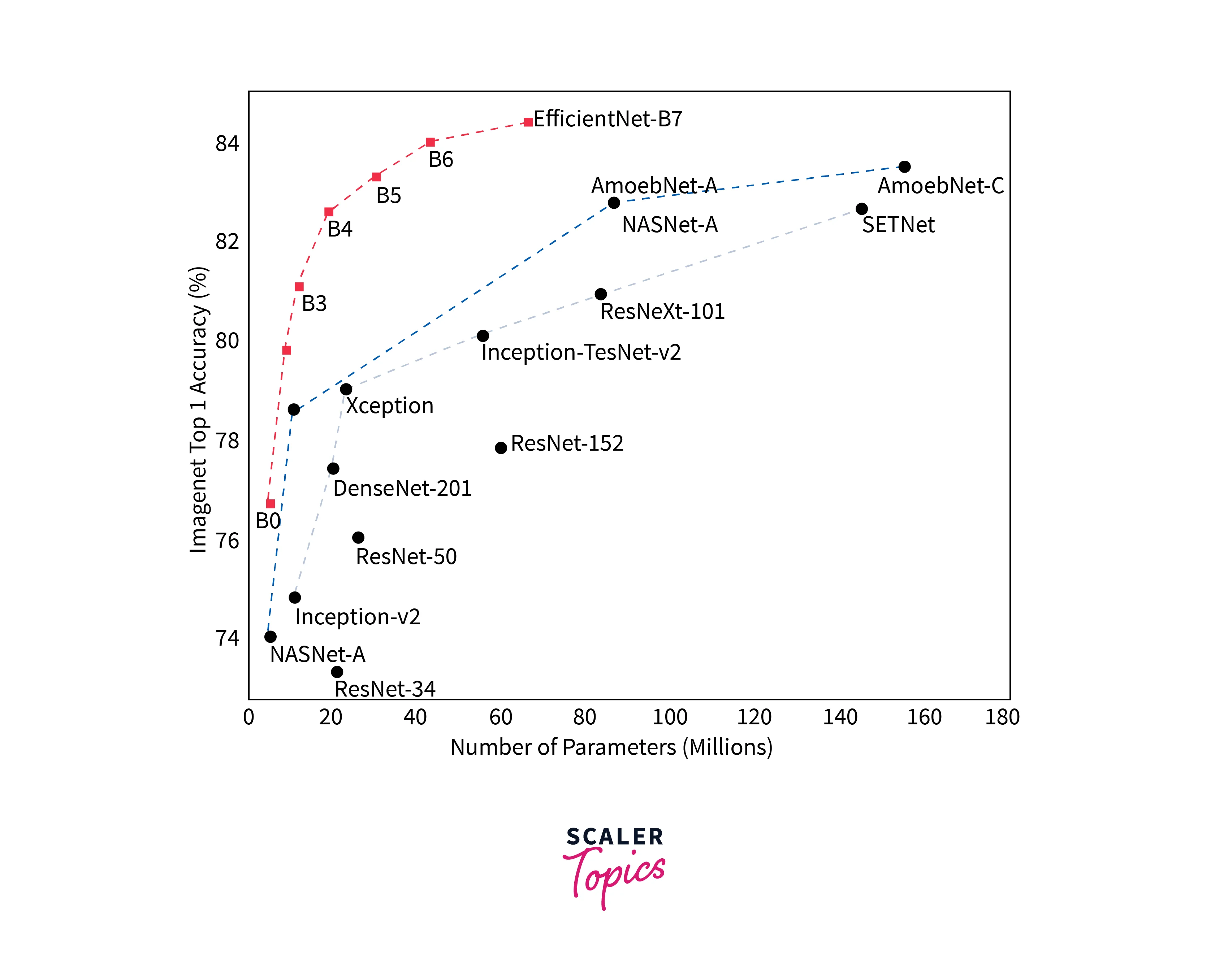
We can see that EfficientNet works much better than all its pre-existing models in terms of performance and number of Parameters. Furthermore, the FLOPS is significantly reduced while performing better than ResNet and other similar architectures. This drastic performance improvement is due to selecting optimal baseline architecture using NAS and using compound scaling when the model is scaled up.
Implementing EfficientNet
We will use TensorFlow to implement the EfficientNetB3 architecture and check the results.
Load Libraries and Data:
We are going to use the CIFAR10 image dataset. The train and test datasets are pre-split, so we don't have to do that.
Next, we split the training dataset into validation and training sets.
OneHot Encoding is used to encode the categorical data.
Data Augmentation:
We augment the image data using the image data generator method. You can play with the argument values to see which works best for that dataset.
Create our EfficientNet B3 Model:
We install the required packages and import the EfficientNet B3 architecture with the following lines of code.
We create our baseline EfficientnetB3 model. Then, we add ReLU layers to it, in the end, to reduce the number of output parameters gradually. The final layer is a softmax layer used for classification.
Model Training:
We define the learning rate, loss function, and optimizer. We use a Stochastic Gradient Descent as the optimizer and categorical cross entropy as our loss function. Finally, we compile the model with these values.
Now all that is left to do is train the model.
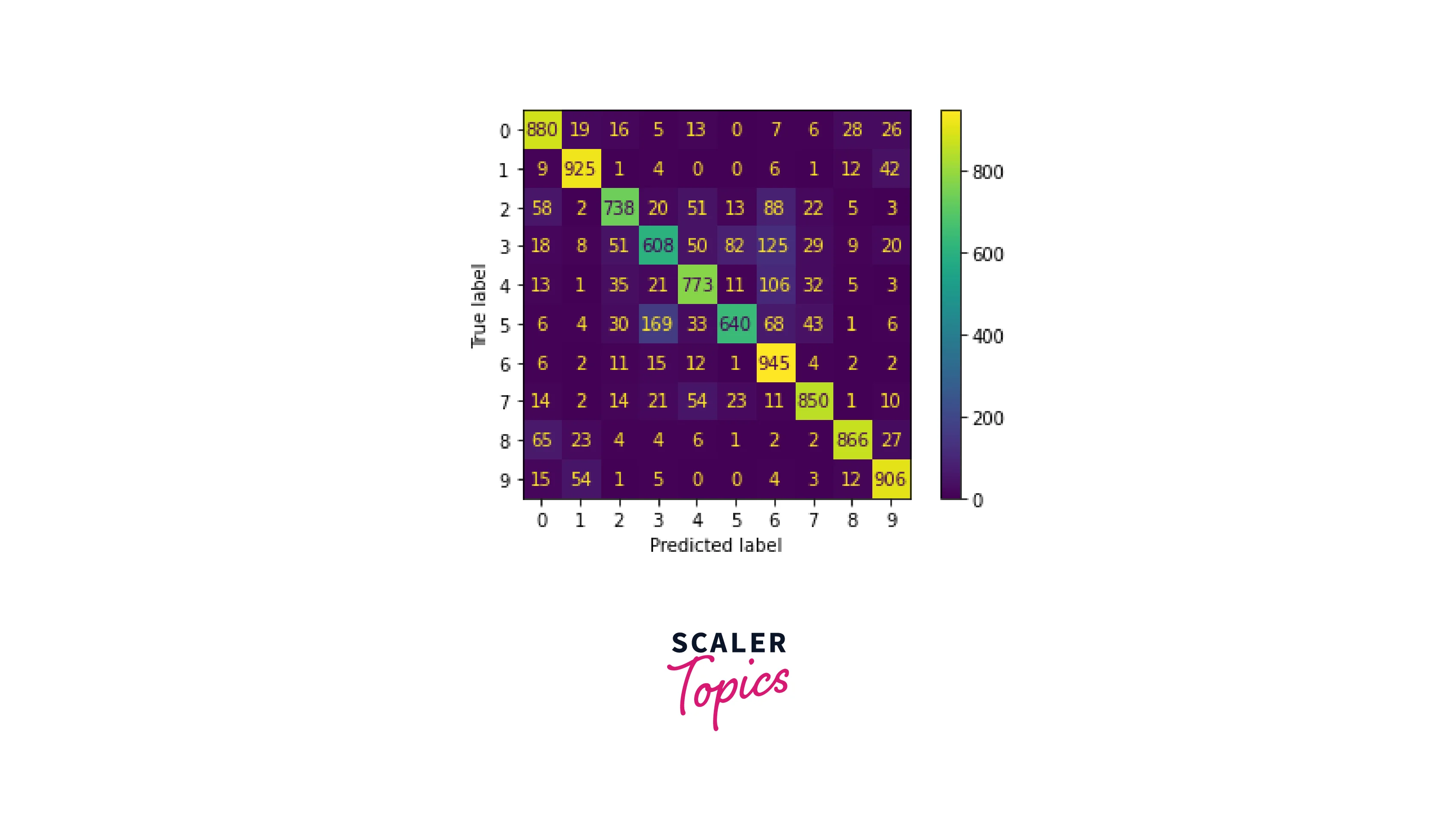
Plot Confusion Matrix:
Using a confusion matrix, let's predict the output values from our test dataset and see the accuracy.
Output:
Conclusion
- DenseNet is an improved version of ResNet by solving the Vanishing/Exploding Gradient problem.
- EfficientNet uses the technique of Compound Scaling to achieve better results.
- Compound Scaling with Neural Architecture Search gives rise to a family of EfficientNets.
- EfficientNet has outperformed all its predecessors concerning the number of Parameters.