Improving Model Accuracy in Image Classification
Overview
Improving image classification accuracy is one of the biggest hurdles in deep learning. Besides using a deeper network and better data, many techniques have been developed to optimize network performance. Some techniques, such as Dropout, target training bottlenecks in the architecture itself, while others, like Regularization, are more focused on improving the overall pipeline.
Pre Requisites
Before we get to the actual code, we must understand a few pre-requisite terms. They are explained here.
- Knowledge of training, test, and validation data splits.
- An understanding of the concept of image classification.
- Familiarity with simple neural network architectures.
- Awareness of the challenges in deep learning as outlined.
Introduction
In deep learning, having large amounts of data and complex models is only sometimes possible due to constraints such as limited resources, computational power, or access to data. These challenges can make it difficult for a model to generalize well and lead to overfitting, where the model becomes too complex and memorizes the training data, leading to poor performance on unseen data. In such scenarios, Regularization and transfer learning techniques can optimize the training time and compensate for the lack of data. Additionally, algorithms such as Dropout and Early Stopping can help address the problem of Overfitting.
This article introduces various algorithms and pipeline adjustments that can improve the accuracy of image classification models. By understanding these techniques, we can effectively tackle the challenges that arise during the training process and achieve better results.
Improving Model Accuracy
The two biggest hurdles in training neural networks are Overfitting and Underfitting. In the first case, the network memorizes the data; in the second, the network needs to learn more. The following techniques can be divided into categories based on these two concepts. Dropout layers, Data augmentation, Regularization, Early Stopping, tackle Overfitting. Transfer Learning and Hyperparameter Tuning tackle Underfitting. If there is a lack of data, we can use Transfer learning and Data Augmentation. The other algorithms can be experimented with if the model fails. The below sections explain all of these algorithms.
Overfitting and Underfitting
It is important to remember that Overfitting and Underfitting are not binary states but a continuum. It is a balance between memorizing the training data and generalizing to unseen data, and finding the right balance can be difficult and require experimentation. In addition to Overfitting and Underfitting, we should monitor other metrics such as accuracy, precision, recall, and loss during training. These challenges make training a neural network a balancing act.
- Training accuracy is the model's accuracy during training time on the train/test split of the data.
- Validation accuracy is the model's performance when tested on real-world data that the model has never seen.
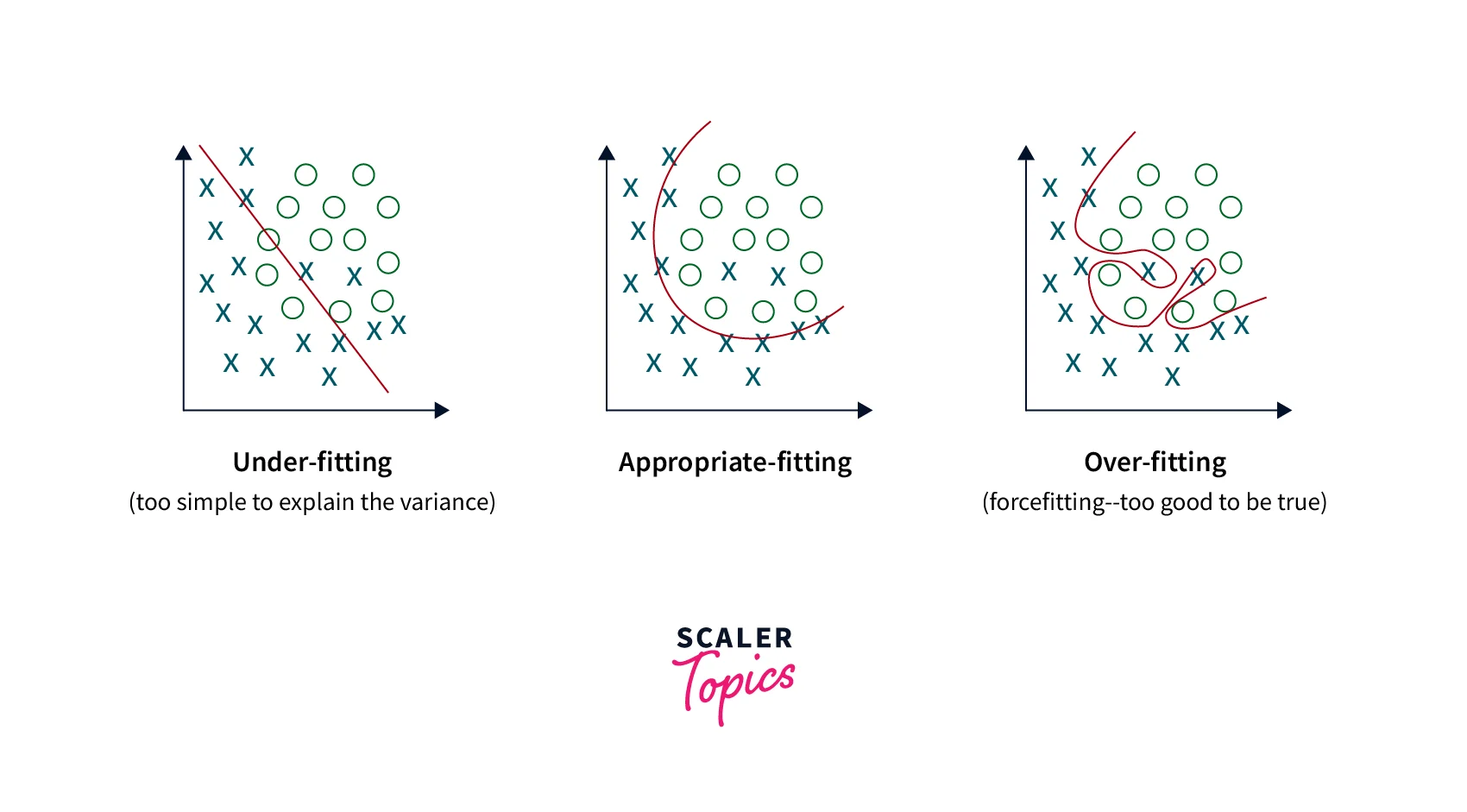
- Overfitting occurs when the training accuracy is far higher than the validation accuracy for many epochs.
- Underfitting occurs when the model focuses too heavily on the training data and fails to predict any sample it has yet to see.
If the training accuracy is very low and the validation accuracy seems to fluctuate or is much higher than the training accuracy, this is called Underfitting. In Underfitting, the model must be more powerful to fit the data. Both Overfitting and Underfitting can be countered in many ways, but it is to be noted that they have a delicate balance. Understanding which of these the network is going through is essential in improving image classification accuracy.
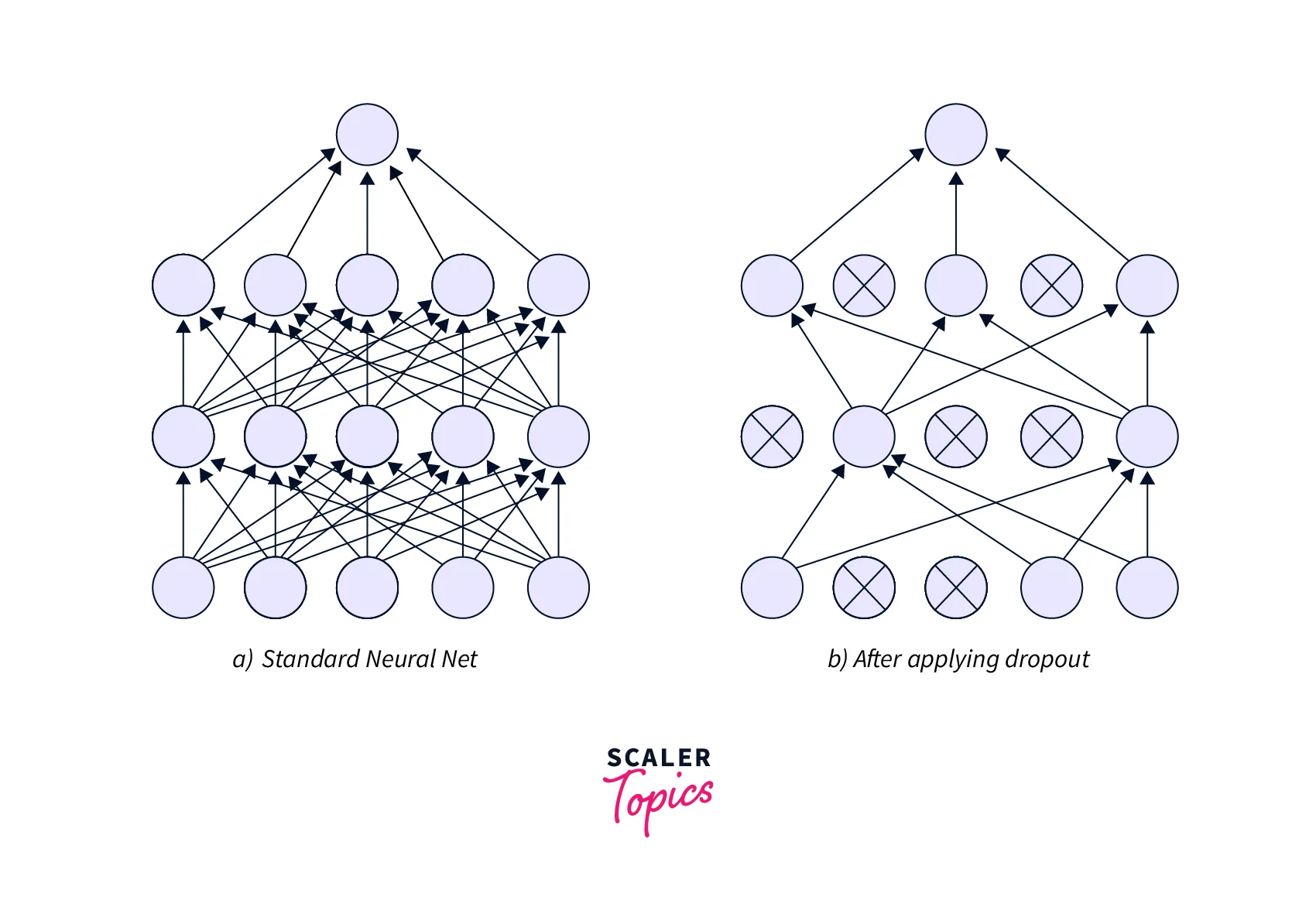
Dropout Layers
When the single unit in a network computes gradients wrt the error, it also considers the other units and tries to fix their mistakes. This dependency is known as Co Adaptation and leads to the formation of complex relations that encourages Overfitting. Dropout layers reduce co-dependence between the neurons in a network by randomly (with a probability p) setting neuron activations to 0. This layer is applied to Dense (Fully connected) layers in a network. Dropout helps with smaller datasets and slightly with larger ones. If the dataset is bigger, Dropout can help performance as more information is recovered. Similarly, if the dataset is too large, the model performance might also worsen. During testing, the weights are scaled by the probability p.
Data Augmentation
Neural networks are extremely data-hungry, and training them requires many training examples. It is, of course, only sometimes possible to have a large amount of training data. We can use Data Augmentation to expand the number of available examples artificially. Data Augmentation is the process of tweaking the given examples multiple times in different ways to generate new training samples from the existing images. Some examples of Data Augmentation for image data include Random Flipping, Jittering Brightness/Contrast, Random Resizing, and Random Cropping. Some Data Augmentation techniques are shown below.

Data augmentation is a good method for improving image classification accuracy. This technique is not restricted to images; we can apply similar concepts to every other data domain. Data Augmentation also has the added benefit of being a regularizer by showing the model data from different perspectives.
Regularization
One of the biggest challenges neural networks face during training is Overfitting. Penalizing complex models that perform better during training but not during validation is one way of reducing the effects of Overfitting. The objective of training neural networks is to use them on real data outside the training set. Penalizing models that learn too much of the training set is called Regularization. A regularization term is used to control the penalty applied to the model. This term is also a hyperparameter, as increasing it too much may hurt model performance. Many algorithms perform Regularization during training, such as Data Augmentation, Early Stopping, Dropout, etc.
Early Stopping
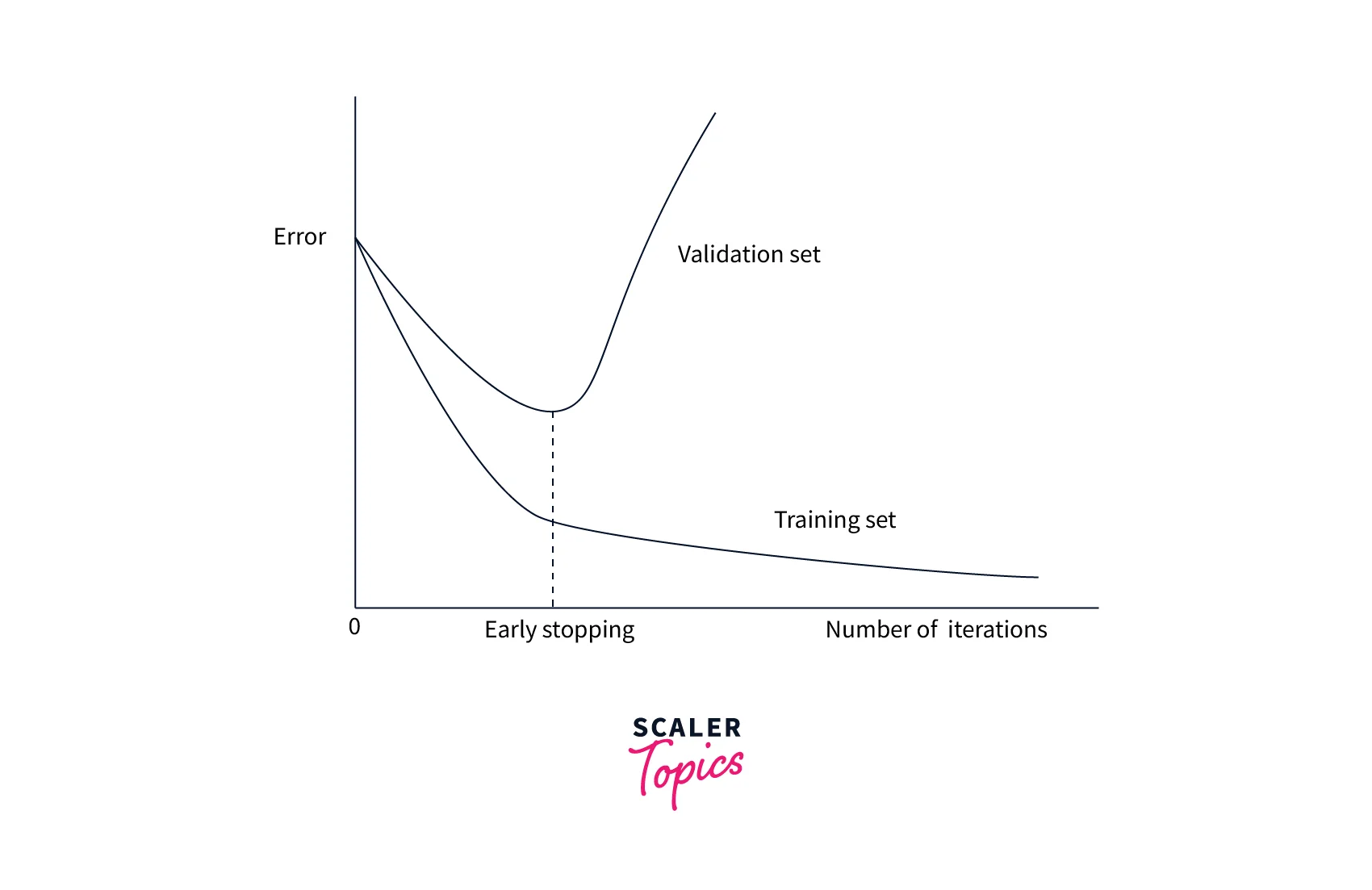
Early Stopping is a regularization technique that improves image classification accuracy by intentionally stopping the training when validation loss increases. Training is stopped as training a model for too many epochs sometimes causes Overfitting. In Early Stopping, the number of epochs becomes a tunable hyperparameter. We continuously store the best parameters during training, and when these parameters no longer change for several epochs, we stop training.
The idea of Early Stopping can be seen in this diagram.
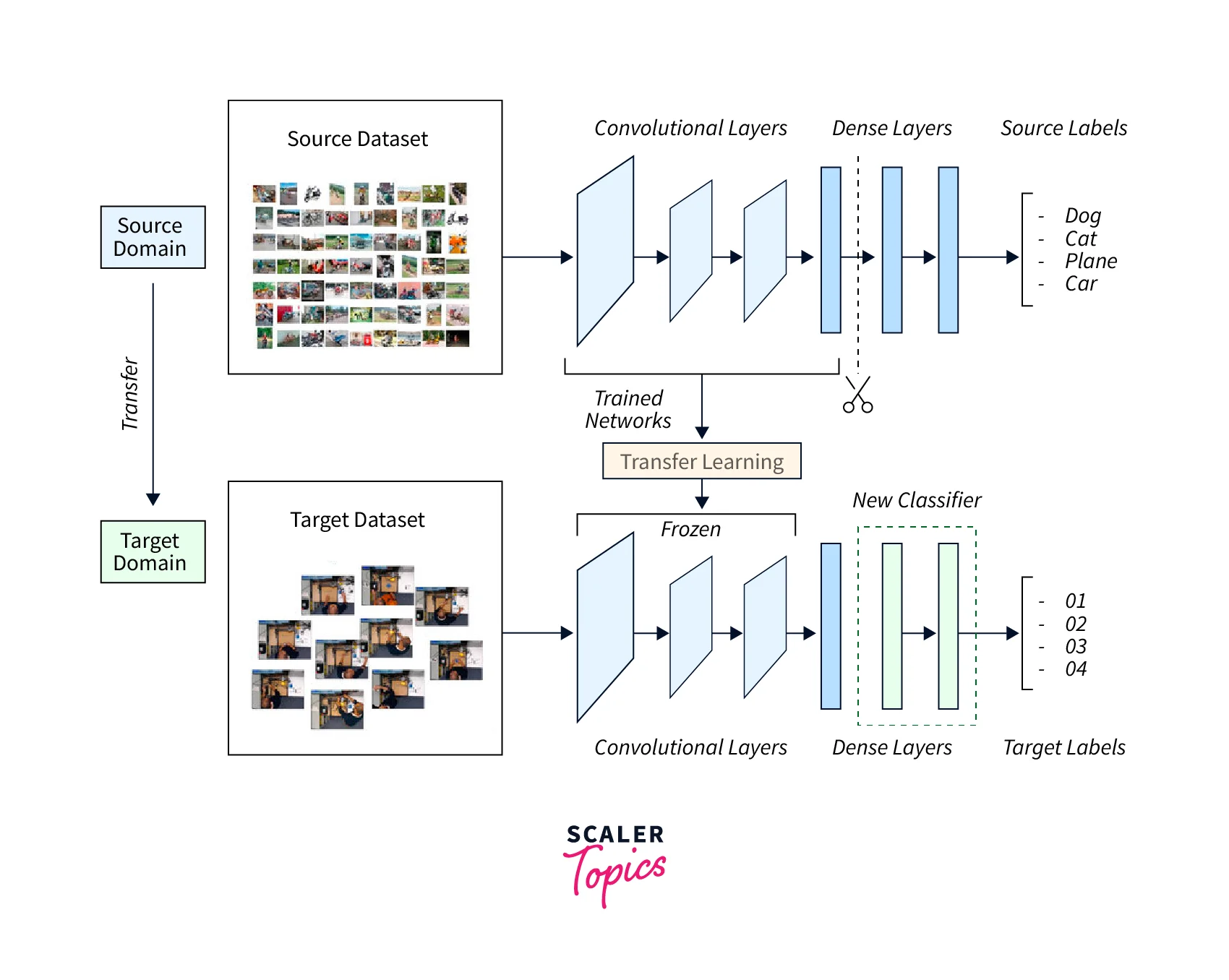
Transfer Learning
Training large-scale image models is time and energy-consuming. Since most vision datasets have some common features, it is possible to take a network trained on a similar dataset and use the trained features to reduce training time on a different dataset. Transfer learning is a procedure that lets a pre-trained model be used either as a feature extractor or as a weight initializer. In most cases, Transfer learning is used for fine-tuning. We can transfer knowledge from a network trained on a complex task to a simpler one or from a network trained on large amounts of data to one with fewer data. Transfer learning is thus a potential key to multi-task learning, an active field of research in deep learning. This technique is also key in quickly improving image classification accuracy with fewer data. The following diagram shows the concept behind using Transfer learning to improve image classification accuracy.
Hyperparameter Tuning
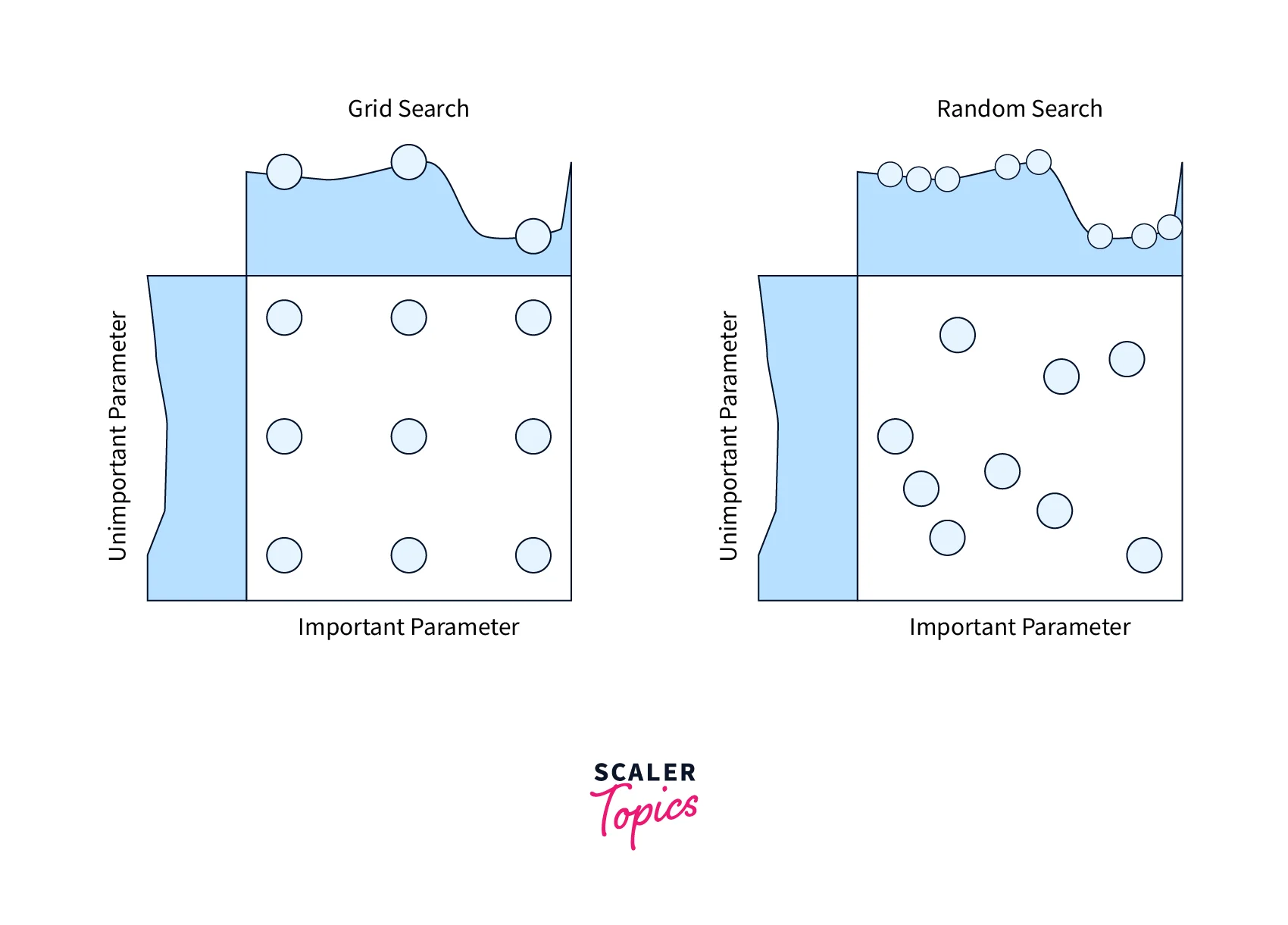
Every DL model and training pipeline has parameters we can tune to optimize performance. Parameters can include - how many epochs to train the network, weight decay, optimizers, learning rate, and more. Each hyperparameter can have multiple values, and these quickly add up to hundreds or more different cases to try. Hyperparameter tuning is the art of tweaking these parameters to create an optimal model quickly. We can test only some parameters, but a tuning service can estimate which hyperparameter to keep and which to discard. Many algorithms enable such a service, including a grid search over the hyperparameter space. If the hyperparameter in question reduces model performance, it is dropped, and sometimes similar hyperparameters are also dropped. Hyperparameter tuning is a challenging problem as every task requires different requirements. Tuning hundreds of parameters is a balancing act between the choices. This technique is one of the final bits of the pipeline that leads to improving image classification accuracy.
Conclusion
- In this article, we learned the importance of other algorithms in improving image classification accuracy.
- We looked at the concepts of Overfitting and Underfitting and understood how they affect model training.
- We also looked at many algorithms that improve performance by modifying the architecture or changing how we train the network.
- We understood what techniques to use when we lacked data.
- We also tackled improving the existing model's performance by tuning its hyperparameters.