ML Deployment on Cloud Using TF Serve
Overview
Machine learning (ML) models have become a powerful tool for businesses across industries to improve their products, and services and make better decisions. However, deploying ML models to production is a significant challenge. Many companies face difficulties deploying models that have been trained in development environments to production environments. The process of deploying ML models involves several steps, including model versioning, performance optimization, and monitoring.
Introduction
TensorFlow Serving is a flexible, high-performance serving system for machine learning models that were designed for production environments. It provides an easy way to deploy new algorithms and experiments while keeping the same server architecture and APIs. TensorFlow Serving allows multiple models or multiple versions of the same model to be served simultaneously, which is useful for A/B testing or rolling out new models in a controlled manner. It also provides monitoring and management features, such as metrics and logging, that help with the overall management of the deployed models.
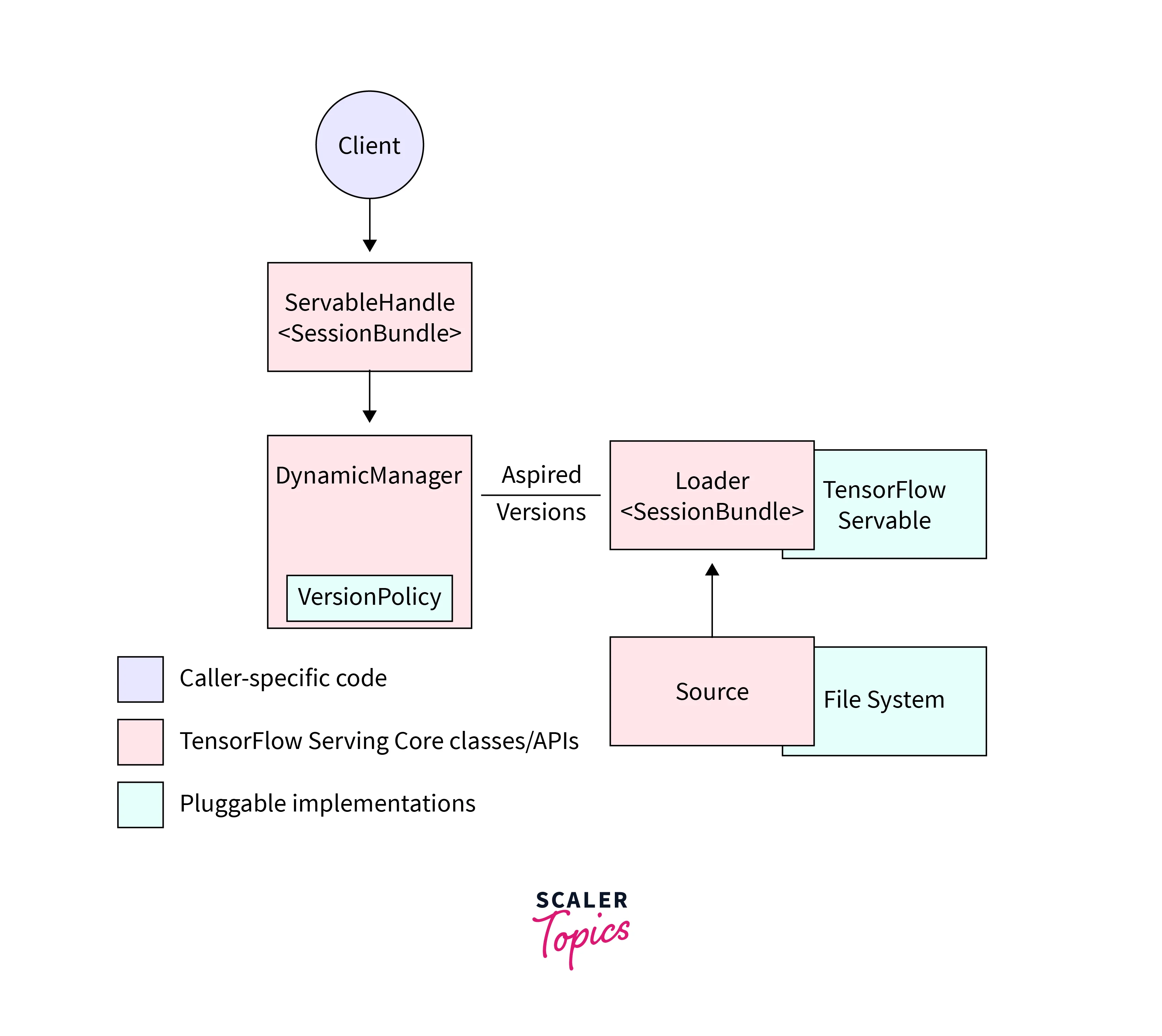
TensorFlow Serving Libraries : An Overview
TensorFlow Serving Libraries play a critical role in the TensorFlow deployment process, as they provide the necessary abstractions and APIs to manage the entire lifecycle of serving machine learning models.
TensorFlow Serving is composed of a few key abstractions that implement APIs for different tasks. The most important ones are Servable, Loader, Source, and Manager.
-
The Servable abstraction represents the model or other machine learning assets that can be served. It includes metadata such as version and signature, as well as the actual data used to perform the computation.
-
The Loader abstraction is responsible for loading and unloading a Servable from memory. It handles the low-level details of loading the data and creating the TensorFlow session.
-
The Source abstraction is responsible for managing the versions of a Servable. It defines the location of the Servable and the way the Servable is loaded.
-
The Manager abstraction is responsible for managing the Servable. It keeps track of the available Servables and the corresponding Sources and Loaders.
Each of these abstractions plays a crucial role in the serving process and working together, allows TensorFlow Serving to handle the full life-cycle of serving ML models, from loading and unloading to versioning and management, providing a reliable and robust way to serve machine learning models in production environments.
Additionally, TensorFlow Serving provides a convenient gRPC API for making predictions over the network, making it easy to use models from other languages and platforms. TensorFlow Serving also supports more fine-grained configuration options for performance and capacity, which can be adjusted depending on the specific requirements of the production environment.
Exporting a Model for Serving
Exporting a model for converting a trained machine learning model into a format that TensorFlow Serving can use to perform inference. The recommended format for this is the SavedModel format, which is a standard format for saving TensorFlow models.
To export a TensorFlow model to the SavedModel format, you can use the tf.saved_model.save() method. This method takes the following arguments:
- model:
the TensorFlow session used to train the model. - export_dir:
the directory where the SavedModel will be saved. - inputs:
a dictionary that maps input tensors to their names. - outputs:
a dictionary that maps output tensors to their names.
For example, if you have a trained TensorFlow model in a model variable, and you want to export it to the directory /path/to/model, with input tensor x and output tensor y, you can use the following code:
Once you have exported the model, it can be loaded and served by TensorFlow Serving. TensorFlow Serving supports a range of configuration options, such as the number of worker threads and the GPU device to use, that can be adjusted depending on the specific requirements of the production environment.
For non-TensorFlow-based models, you can use the tensorflow-serving-api package to load and serve the models in other formats, this package allows you to define the input and output tensors, as well as the model's metadata, using programmatic APIs.
Exporting a model correctly is important to achieve a correct serving, if the model's inputs, outputs, and versioning are not correctly defined, TensorFlow serving will not be able to use the model.
Setting Up the Environment
We will use the Keras and Transformers libraries to implement the MLM model in Python. Before we start, we need to set up these libraries and import some other useful packages.
Installation
-
Add TensorFlow Serving distribution URI as a package source (one-time setup):
-
Update the apt repository and Install TensorFlow ModelServer:
How to Use Saved Models?
Once the model has been converted to the SavedModel format, it's easy to set up TensorFlow Serving for the model. To start the TensorFlow Serving server, you can use the tensorflow_model_server command along with the necessary arguments, such as the model name, path, and ports. This command starts the TensorFlow serving server and listens on the gRPC API port and the REST API port. The model name flag specifies the name of the model to serve which will be exposed at the endpoint. The model base path flag specifies the path to the directory where the model is located.
This command is easy to use and self-explanatory, but it's good to know more about the flags that are used:
- The port flag specifies the gRPC API port to listen on, the default is 8500, but it's common practice to explicitly specify the port value.
- The rest_api_port flag specifies the REST API port, the default value is zero which means REST API will not be deployed unless specified.
- The model_name flag specifies the name of the model to serve.
- The model_base_path flag specifies the absolute path to the directory where the model is located in the file system.
It is worth noting that, TensorFlow Serving requires additional libraries such as gRPC, which should be installed and configured correctly before starting the server.
Generating Client Requests
Once the TensorFlow Serving server is up and running, the next step is to generate client requests to make predictions using the deployed model. TensorFlow Serving exposes a gRPC API and REST API to handle client requests. The gRPC API is the recommended way to interact with TensorFlow Serving, as it provides a high-performance and efficient way to communicate with the server. However, the REST API is an alternative option that can be used to make requests using standard HTTP protocols.
To make requests to the TensorFlow Serving server using gRPC, you can use one of the gRPC client libraries, such as the one provided by TensorFlow or a third-party library. These libraries provide a convenient API for making gRPC requests and handling responses.
Here's an example of requesting the TensorFlow Serving server using the TensorFlow gRPC client:
To make requests to the TensorFlow Serving server using the REST API, you can use any standard HTTP client library to send an HTTP request to the server. The request payload should be in JSON format and should contain the input data and metadata, such as the model name and version. The server will respond with a JSON object containing the prediction results.
The endpoint is available at http://localhost:8501/v1/models/model_name, where model_name is the name of the model that is being served.
That should output something similar to the following JSON response if everything succeeded:
It's important to note that the client should be aware of the input and output tensors' names and use the correct format when sending the request to the server, otherwise the server will not be able to understand the request and return an error.
Also, it's good to test the requests locally before deploying them to the production environment.
Conclusion
This article showed us how to deploy a model using TensorFlow Serve. We learned the following about TensorFlow Deployment:
- TensorFlow Serving is a powerful solution for serving machine learning models in production environments.
- It supports versioning and provides out-of-the-box integration with TensorFlow models, but can be easily extended to other types of models.
- TensorFlow Serving can be run on both CPU and GPU, it exposes both gRPC and REST APIs to make it easy to integrate with different applications.
- The Model Status API is useful for monitoring and managing the served models during TensorFlow deployment.
- TensorFlow Serving is a flexible and efficient solution that can handle a wide range of use cases, making it ideal for serving models at scale.