Introduction to Transfer Learning
Overview
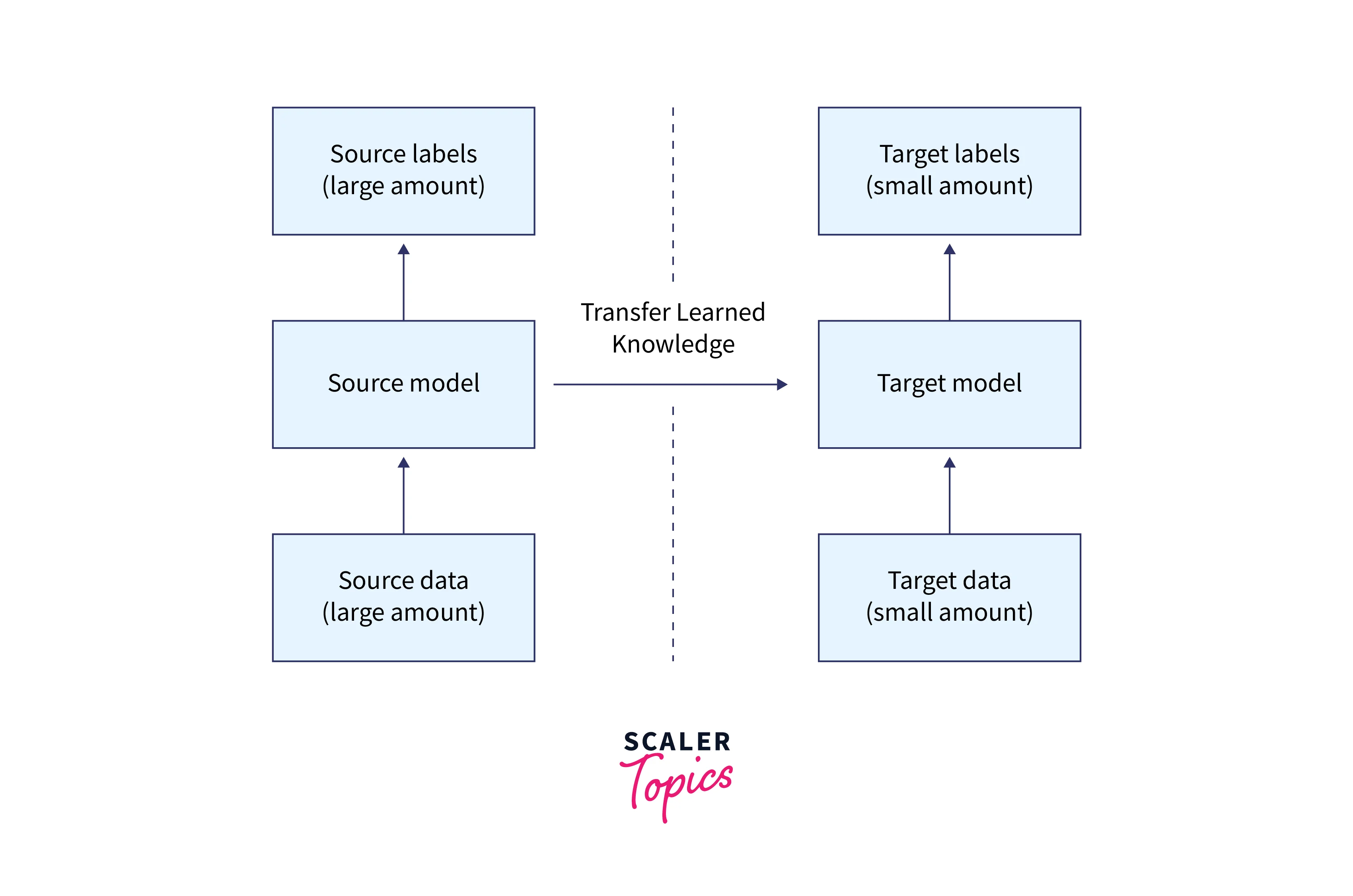
The machine learning transfer learning method uses a model developed for one job as the foundation for another. Because they are faster and less expensive than building neural network models from scratch, pre-trained models are widely used as the basis for deep learning tasks in computer vision and natural language processing. They also perform significantly better on similar tasks.
What is Transfer Learning
A pretrained deep learning model in a new task is known as transfer learning. Utilizing pretrained models' knowledge (features, weights, etc.) to train fresh models allows you to overcome issues like using fewer data for the new task.
Using this method, a model could achieve a high model performance rate and a lot of a chance to utilize minimal computation. The concept of transfer learning machine learning was highly used in Natural Language Processing (NLP) and Image Processing tasks that utilize more computation when building from scratch.
The primary idea behind transfer learning machine learning is to use what has been learned in one task to enhance generalization in another. Transfer Learning example, if you initially trained a model to classify cat images, you would use the knowledge from the model to recognize other images like a dog. To a new "task B," we apply the weights that a network has learned at "task A."
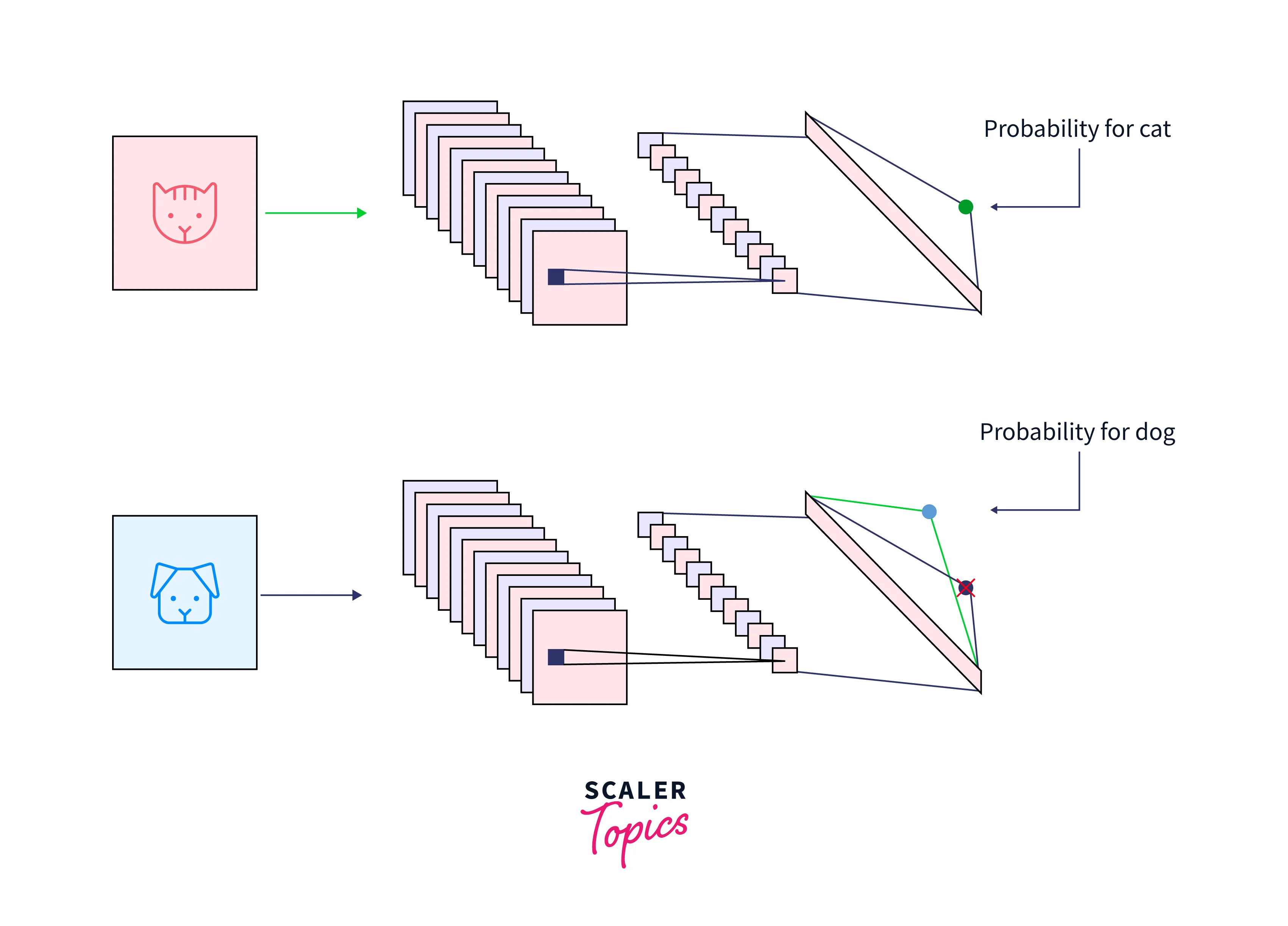
Why Transfer Learning?
Access to data for training was a big problem. In contrast, when we use the transfer learning machine learning method to train on a new task, the data needed to retrain is lesser than training the model from scratch since the model was already pretrained on a similar task as the new one.
Deep Learning algorithms take a long time to train from scratch for complex tasks, leading to inefficiency. For example, a model's training could take days and weeks when considering an NLP task. However, we could only use transfer learning to effectively avoid the model training time.
The model has a greater learning rate because you previously trained it on a similar task. As a result, the model operates at higher performance and produces outputs with more accuracy when it has a better base and a higher learning rate.
When to Use Transfer Learning
The transfer learning technique should be avoided when the weights learned for your pretrained model's actual task and the new task are different. The weights transferred from your pretrained model to the new task will not be able to provide you with the best results, for instance, if your new network is trying to recognize shoes and socks and you trained your prior network to classify cats and dogs. As a result, it is preferable to start the network using pre-trained weights that correspond with expected outputs that are comparable to the actual outputs rather than utilizing uncorrelated weights.
An architecture issue will arise if layers are removed from a pre-trained model. Overfitting may occur by reducing the number of parameters that can be trained and removing layers. Utilizing the proper number of layers is essential for preventing overfitting.
![]()
There are a few well-liked pre-trained machine learning models available. The Inception-v3 model is one of them; it was developed for the ImageNet "Large Visual Recognition Challenge." Participants in this challenge had to group photographs into 1,000 categories, such as "zebra," "Dalmatian," and "dishwasher." The models ResNet and AlexNet are also highly well-liked.
Feature Extraction
Fortunately, deep learning can do feature extraction automatically. However, you must still decide which features to include in your network. Therefore this does not eliminate the value of feature engineering and domain knowledge.
You can use the representation acquired from the pretrained model to tackle different problems. To determine the proper feature representation, use the first few layers; use the network's output sparingly because it is too task-specific. Instead, output data through one of the intermediate levels and transmit it into your network.
This technique is frequently used in computer vision since it can reduce the size of your dataset, speed up computing, and make it better suitable for conventional methods.
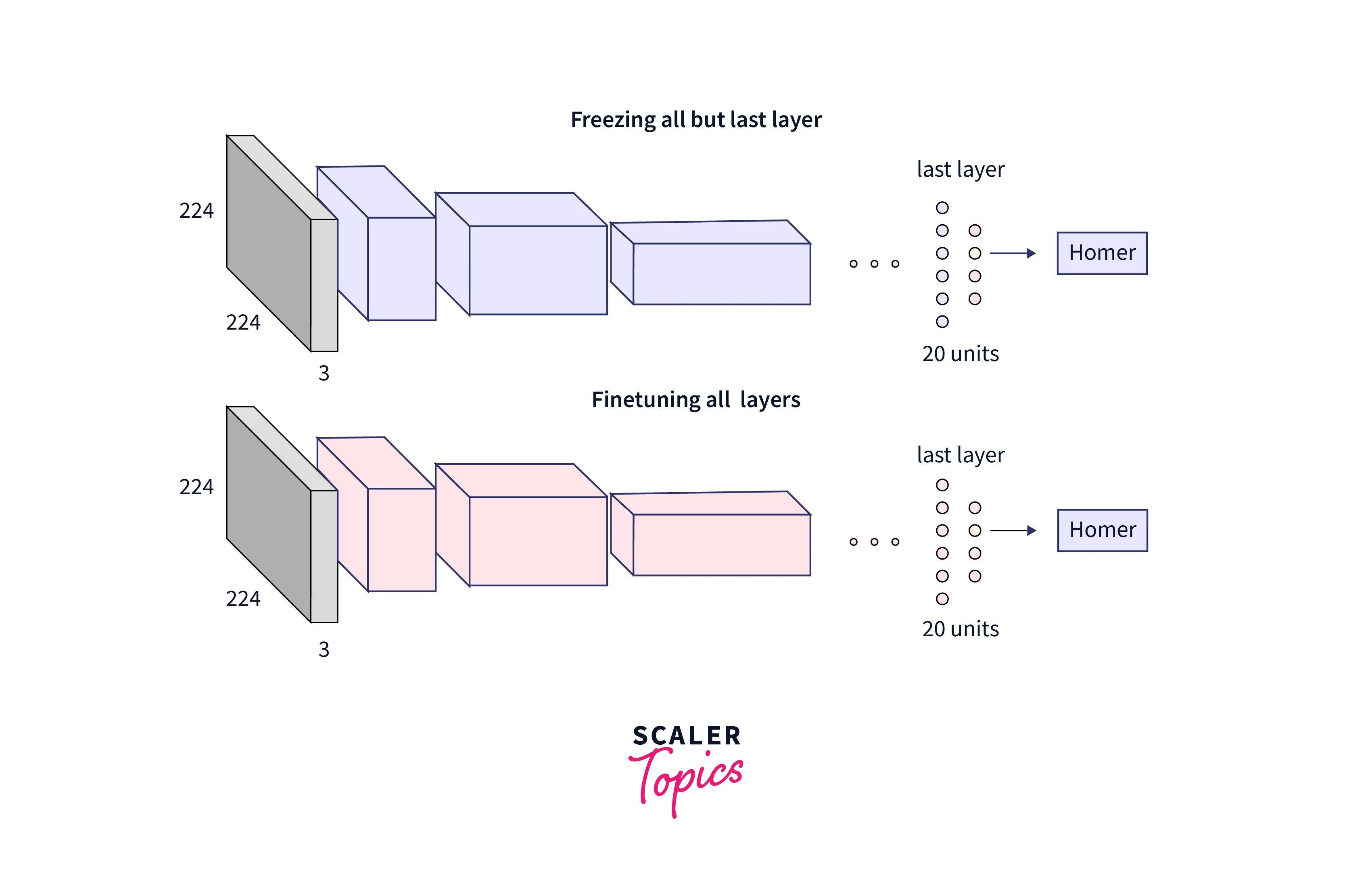
Freezing or Fine-tuning?
Freezing: In this step, we freeze the weights of every layer that is still present, add new, completely connected layers, and train the system using fewer photos. We employ this strategy when data similarity is high and data size is minimal.
On the other hand, Fine-tuning means making a few slight modifications to enhance the model's performance further. For instance, you can unfreeze the pre-trained model during transfer learning for greater task-specific adaptation.
For instance, we can simplify a new function g() by g(f(x)) if we already have a pre-trained model function f() and want to learn it. In this manner, g() views all data via f(). This can entail adjusting the previously learned model. We can also adjust f() during the learning phase.
Because the update process moves incrementally in the gradient's opposite direction, the learning process can be considered merely fine-tuning. However, fine-tuning is typically saved for the end and entails lowering the learning rate to modify the weights accurately. Typically, the learning process begins with a very bad beginning condition and a large learning rate, which may subsequently include a fine-tuning phase and a lower learning rate. The learning phase can be divided into several fine-tuning phases, each with a lower learning rate than the previous one.
Types of Deep Transfer Learning
Transfer learning is often seen as a basic idea or principle in which we attempt to complete a target task utilizing the knowledge of the source task's domain. Unfortunately, the terminology connected to transfer learning has been used indiscriminately and frequently. Therefore, differentiating between transfer learning, domain adaptation, and multi-task learning can sometimes be difficult. However, you can ensure that all are connected and aim to address similar issues.
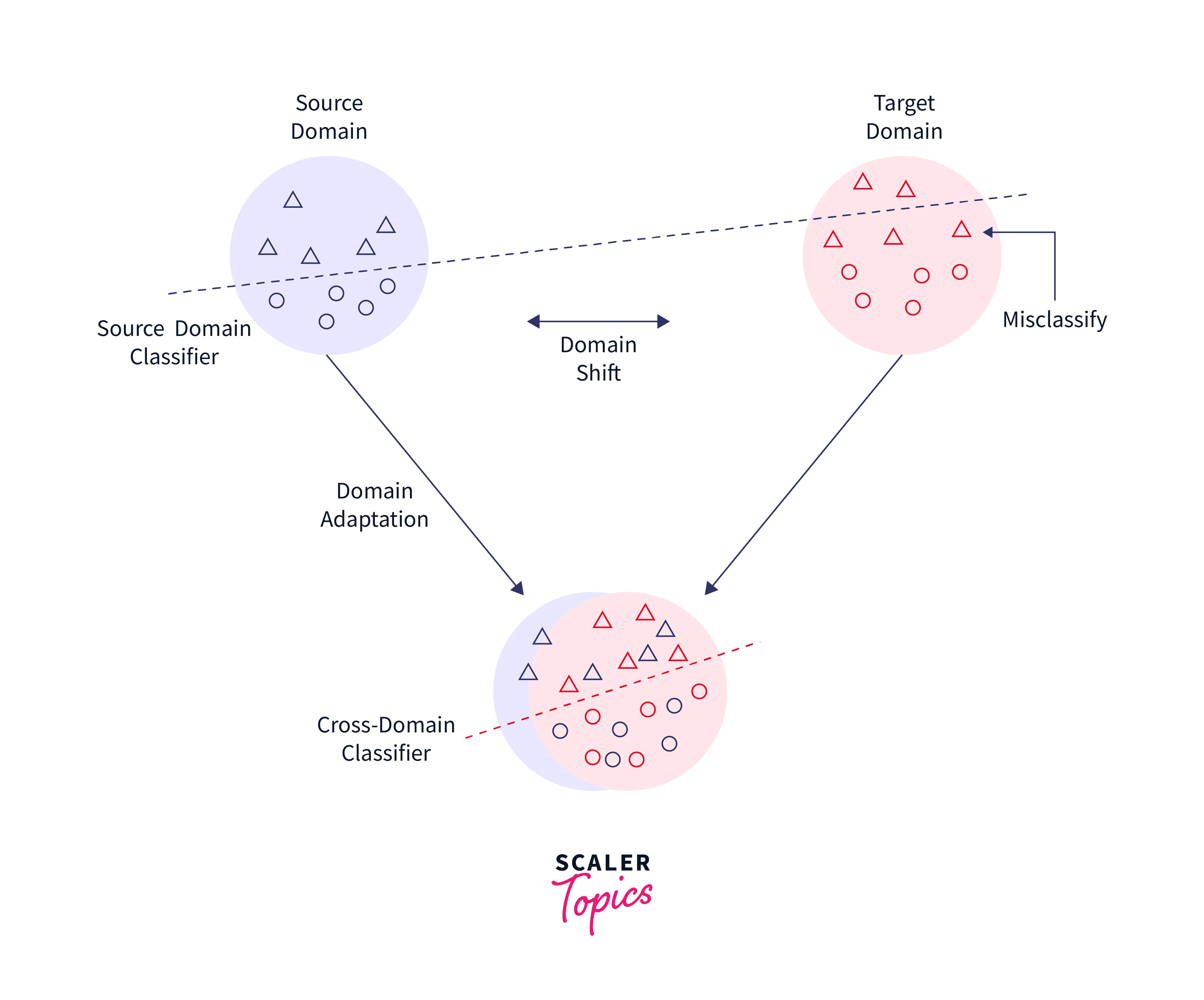
Domain Adoption
When the marginal probabilities between the source and destination domains differ, domain adaptation is typically used. The data distribution of the true and target domains is naturally shifting or drifting, necessitating adjustments to transmit the learning. For instance, a corpus of attitudes from product reviews would differ from a corpus of positive or negative movie reviews. If used to categorize product reviews, a classifier trained on movie-review sentiment might observe a different distribution. Therefore, domain adaption strategies are used in transfer learning in these situations.
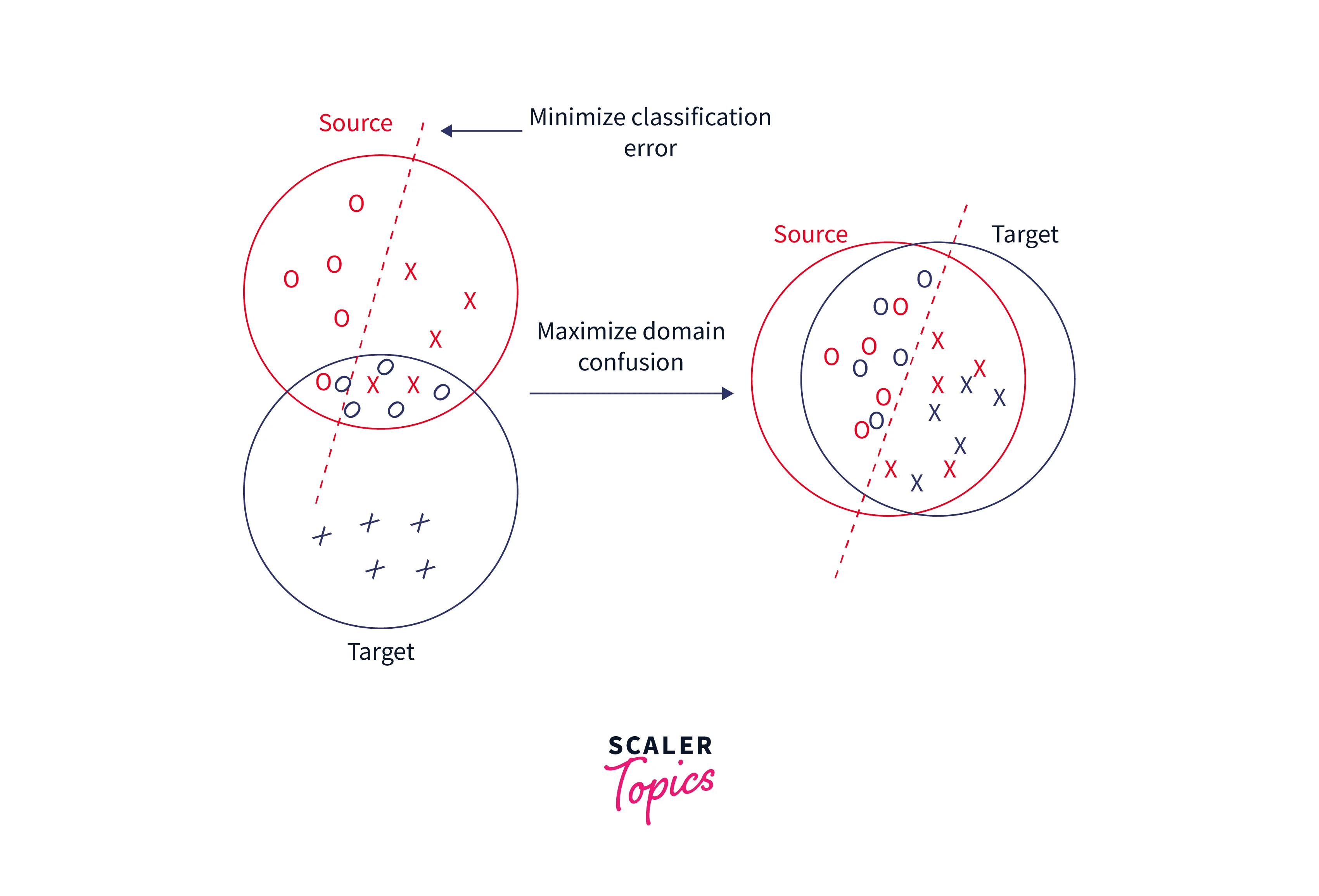
Domain Confusion
We push both domains' representations to be as comparable as feasible rather than letting the model learn any representation. This fact allows us to acquire domain-invariant features and enhance their domain portability. We can do it by directly applying specific pre-processing procedures to the representations.
This technique's core concept is to add a new purpose to the original model to promote similarity by confounding the domain itself, which leads to domain confusion.
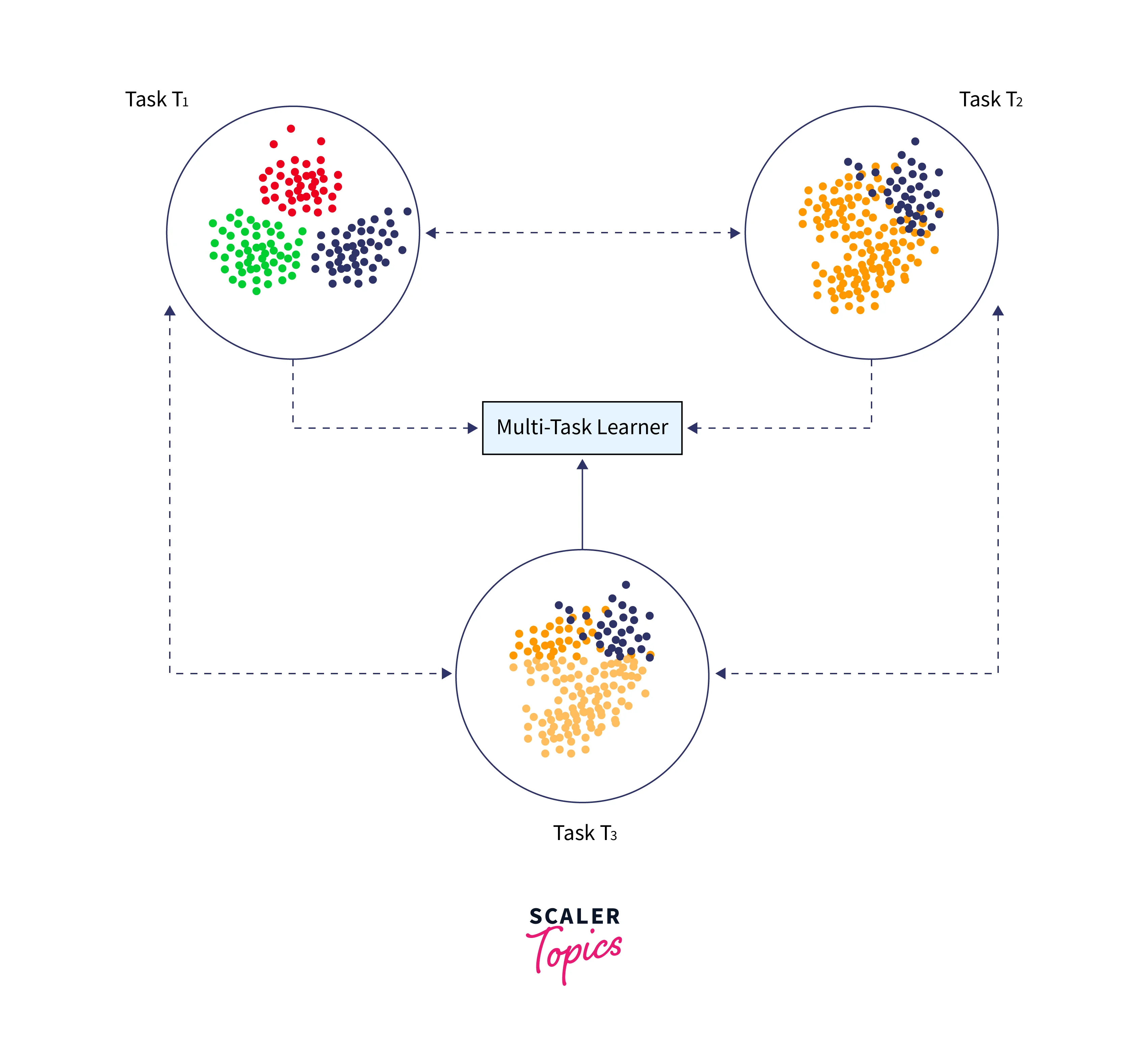
Multitask Learning
Multitask learning is the simultaneous learning of many tasks without distinguishing between sources and targets. Unlike transfer learning, where the learner initially does not know the target task, the learner learns information about numerous tasks simultaneously.
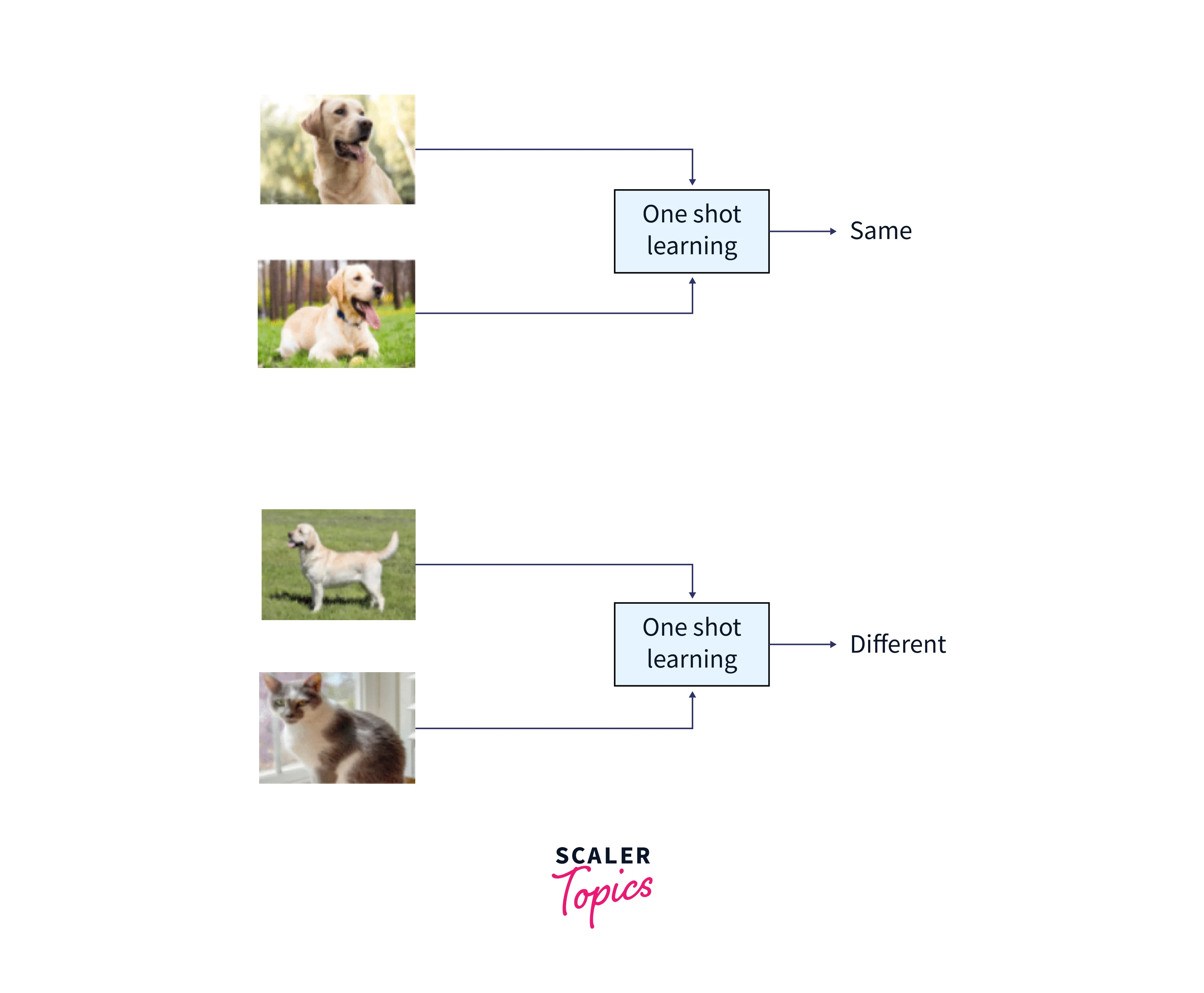
One Shot Learning
Deep learning systems require a lot of training examples to learn the weights b by nature. This is one of the limitations of deep neural networks, but human learning is unaffected. For instance, once a youngster is taught what an orange looks like, they can quickly recognize several orange varieties; this is not true with ML and deep learning methods. One-shot learning is a subset of transfer learning in which we attempt to predict the desired result using just one or a small number of training samples. It effectively helps when it is impossible to have labeled data for every potential class and in cases where new classes are often added.
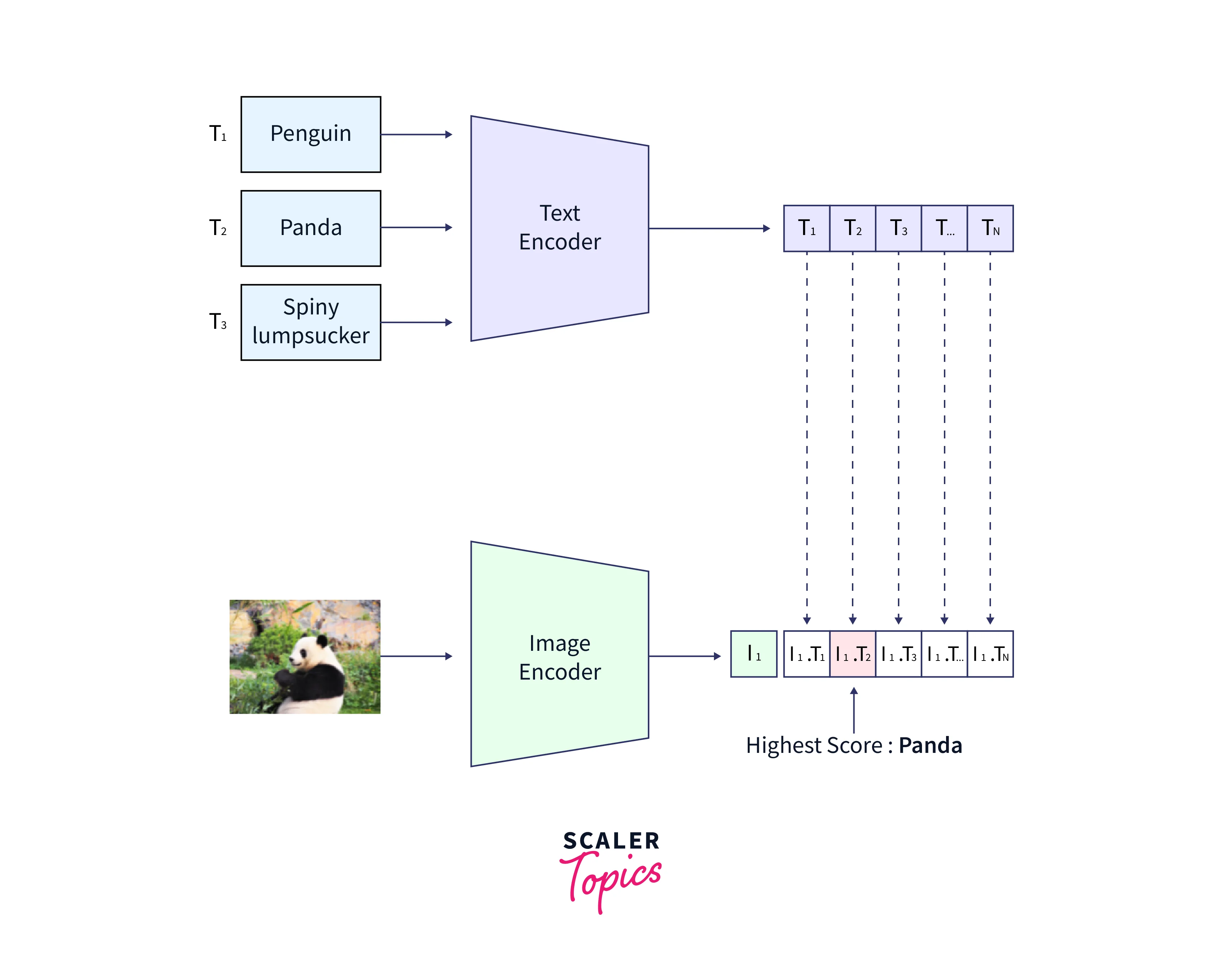
Zero-Shot Learning
Another extreme form of transfer learning is "zero-shot learning," which requires no labeled samples to learn a task. This may seem silly, especially since most supervised learning algorithms focus on learning from instances. However, zero-data learning techniques, also known as zero-short learning techniques, make ingenious alterations during training to utilize extra knowledge to understand data that has not yet been seen. Zero-shot learning is a case where three parameters are learned, such as the input variable (x), the output variable (y), and the additional variable that specifies the job (T). Thus, the conditional probability distribution of P(y | x, T) is taught to the model.
How to Use Transfer Learning?
Develop a Model Approach
Think of a problem where you want to complete Task A but lack data to train a neural network. One way around this is to locate task B, which is related and has a lot of data.
Utilize task B as training data for the neural network, then use the model to resolve task A. Whether you need to use the complete model or just a few levels will depend on the issue you're trying to solve.
It is possible to reapply the model and produce predictions for your fresh input if the input for both jobs is the same. On the other hand, one method to look at is changing and retraining various task-specific and output layers.
Pre-trained Model Approach
Utilizing an existing trained model is the second choice. Research these models in advance because there are many of them available. The task determines how many layers to reuse and retrain.
Nine pre-trained models make up Keras for transfer learning, prediction, and fine-tuning. You can find these models here, along with a few basic tutorials on how to use them. Access to trained models is also widely available from research institutions.
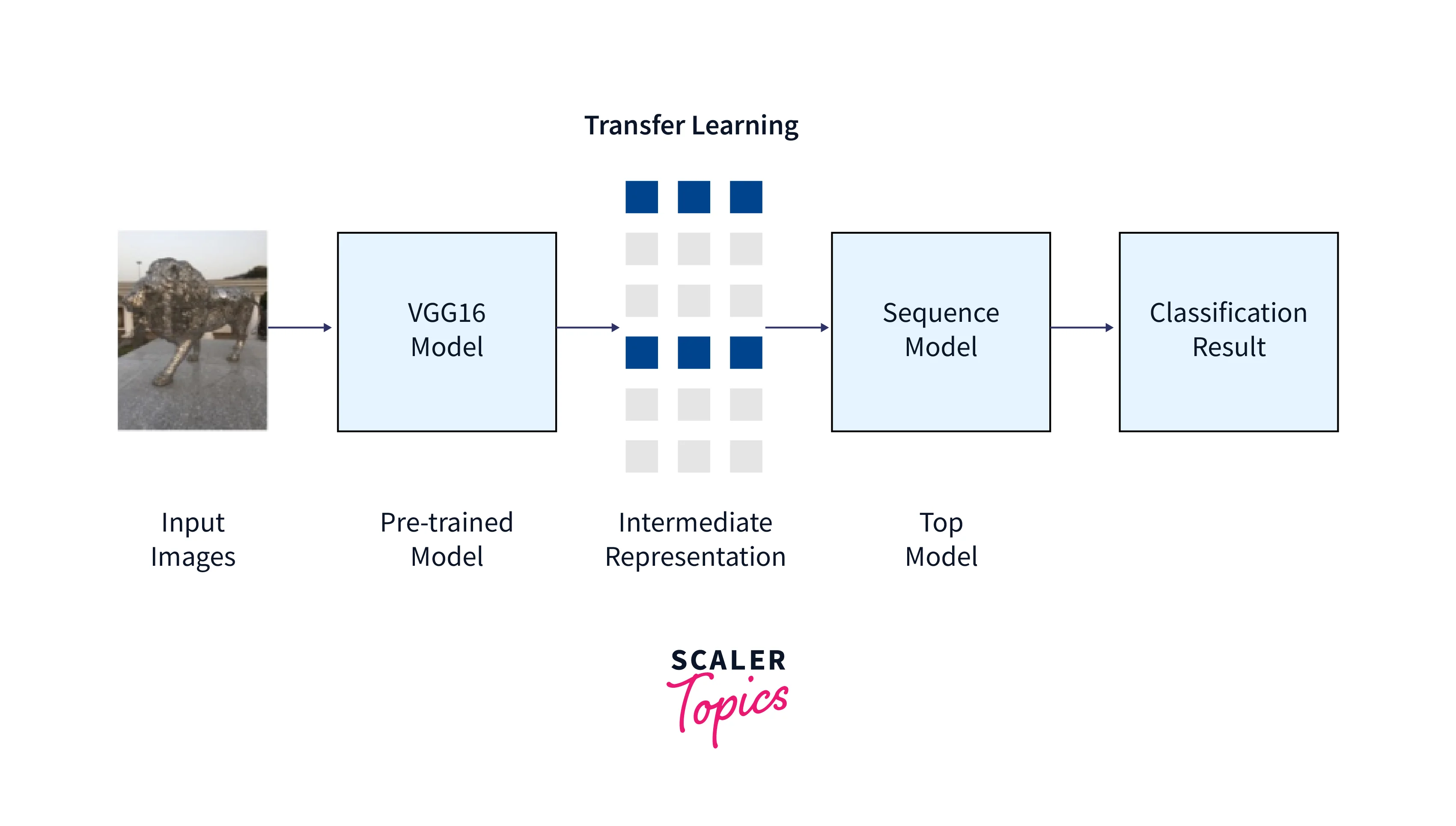
Transfer Learning with Images
Let's learn how to implement transfer learning examples with image data and fine-tune the same in a colab environment.
Below is an image classification code that classifies an image of a cat and dog.
Import the Dataset
Data Augmentation
Data augmentation is creating additional data points from current data to artificially increase the amount of data. Amplifying the dataset may involve making small adjustments to the data or utilizing machine learning models to produce new data points in the latent space of the original data.
Output

Import Pretrained Model
Build Model
Output
Fine Tune Model
Output
Transfer Learning with Language Data
We will implement transfer learning examples with pretrained Glove embeddings on a sentiment analysis dataset.
Import Data
Output
Data Preprocess
Load Embeddings
Output
Build Model
Output
Conclusion
- Deep learning networks' dynamic properties made it possible to change models that have already been pretrained for various applications and datasets. As a result, the number of worthwhile studies in this field is growing rapidly.
- In this article, we used a pretrained Xception model for image processing and used Glove; an unsupervised learning approach called GloVe is used to build vector representations in NLP tasks.
- Model development and implementation are facilitated by transfer learning. We anticipate seeing more features of transfer learning as deep learning becomes essential to addressing various issues in fields like natural language processing (NLP) and video processing.