Machine Learning Diabetes Prediction Project in Django
Overview
Our Diabetes Prediction using Machine Learning project in Django focuses on harnessing the power of artificial intelligence to enhance healthcare. Diabetes, a pervasive health issue, demands early detection for effective management. Leveraging advanced machine learning techniques, this project aims to predict diabetes risk in individuals. Through a user-friendly Django web application, we provide a seamless experience for users to assess their diabetes susceptibility. Join us on this journey as we blend the worlds of technology and healthcare to create a valuable predictive tool for improved well-being.
What are we building?
In this section, we'll dive deeper into what our diabetes prediction using machine learning project in Django entails. Before we embark on this journey, it's essential to understand the prerequisites and the key features that make this project both informative and practical.
Pre-requisites
Before delving into the specifics of our project, let's ensure we have a strong foundation in the following topics, as they are fundamental to understanding and contributing to the diabetes prediction using machine learning project:
- Python Programming: Familiarity with Python is crucial, as Django, our web framework of choice, is Python-based. If you're new to Python, consider checking out articles on Python basics.
- Django Framework: Understanding Django is vital for building our web application. You can get started with Django by exploring introductory materials on Django development.
- Machine Learning Concepts: A grasp of machine learning principles will help you understand the heart of our project. Start with Machine Learning basics.
- Data Handling in Python: We'll be working with data extensively, so it's crucial to know how to handle data efficiently in Python. You can learn about this in articles about data manipulation in Python.
- Basic Conditionals and Control Structures: These are essential for programming logic.
Explore this article on Python conditionals and control structures
Key Features of Diabetes Prediction Project
Our diabetes prediction using machine learning project is designed to be a robust and user-friendly tool. Here are the key features that make it stand out:
- User-Friendly Interface: We've created an intuitive user interface that allows users, regardless of their technical background, to input their health data and receive predictions with ease.
- Accurate Predictions: Leveraging advanced machine learning algorithms, our project provides highly accurate diabetes risk predictions based on the user's input data.
- Data Privacy: We prioritize user data privacy and ensure that all personal health information remains confidential and secure.
- Educational Resources: Alongside predictions, we offer educational resources to help users understand the factors influencing diabetes risk and the importance of preventive measures.
- Scalability: Our Django-based web application is designed for scalability, making it adaptable for future enhancements and updates.
- Community Engagement: We encourage user feedback and community contributions to continually improve and refine our diabetes prediction model and web application.
How are we going to build the Diabetes Prediction Project in Django?
Our diabetes prediction using machine learning project in Django is an exciting venture that combines healthcare, machine learning, and web development. In this section, we'll outline the approach we've taken to build this project and the steps involved.
Objective
Our primary goal is to create a web-based tool capable of predicting whether an individual has diabetes based on diagnostic measurements. To achieve this, we employ machine learning techniques on a dataset originally sourced from the National Institute of Diabetes and Digestive and Kidney Diseases.
Dataset
The dataset we use for this project is available at two locations: the original dataset and a version on Kaggle. It contains diagnostic measurements and serves as the foundation for our predictive model.
Dataset Overview
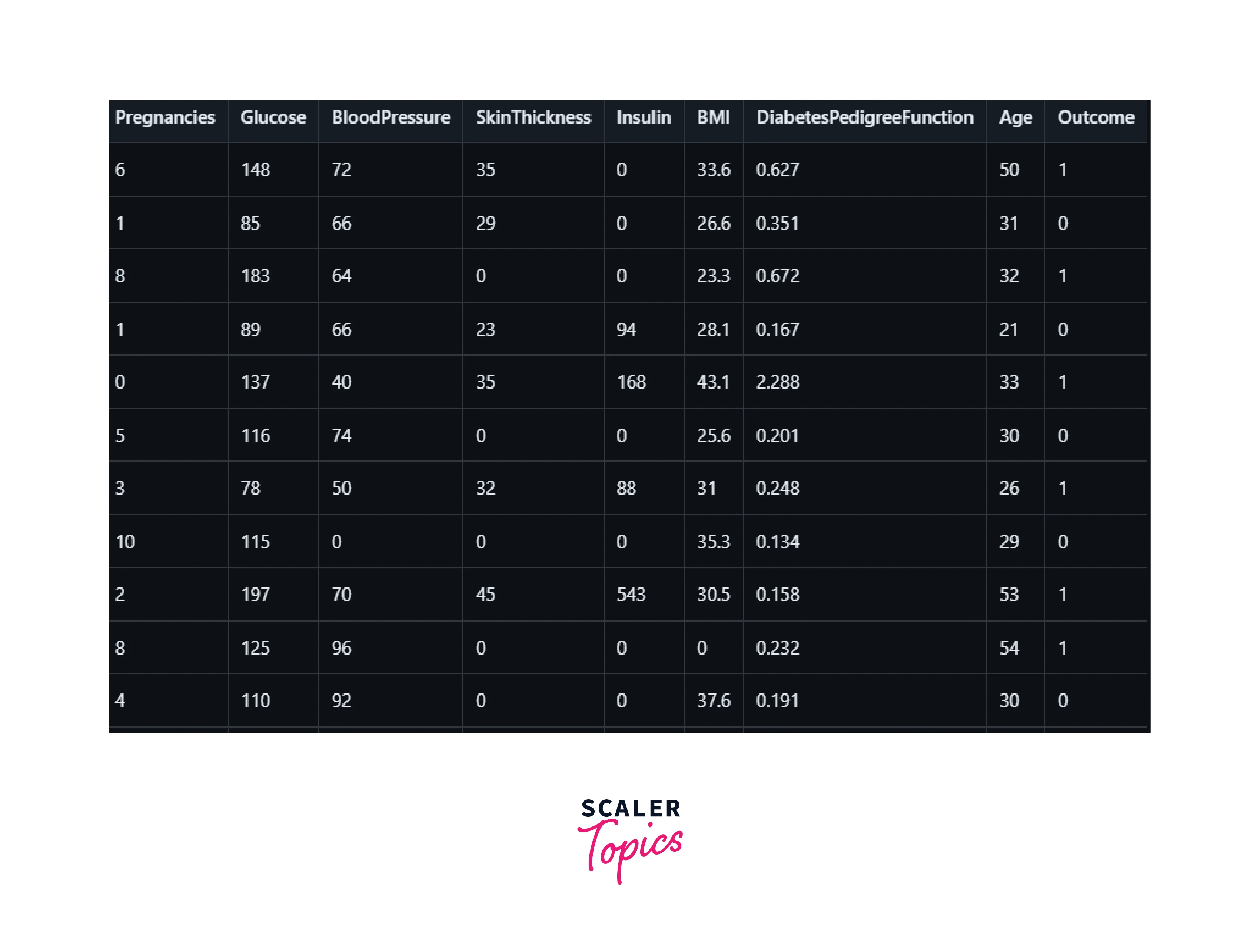
The dataset used in our Diabetes Prediction Project comprises several key features: Pregnancies, Glucose, BloodPressure, SkinThickness, Insulin, BMI, DiabetesPedigreeFunction, Age, and the Outcome variable. These features represent diagnostic measurements and health-related information. The objective is to predict the presence or absence of diabetes in individuals based on these parameters. The dataset includes information primarily about females of Pima Indian heritage, aged at least 21 years. Through data preprocessing and machine learning, we aim to harness the power of these features to create an accurate prediction model for diabetes susceptibility.
Techniques Used
In our Diabetes Prediction Model, we employ various machine learning techniques to create predictive models based on diagnostic measurements.
- Logistic Regression: Logistic Regression is a popular classification algorithm used for binary classification problems like diabetes prediction. We train a logistic regression model using the LogisticRegression class from scikit-learn, and it achieved an accuracy of 77.92% on the test data.
- K-Nearest Neighbors (KNN): K-Nearest Neighbors is a non-parametric classification algorithm. In our case, we used KNeighborsClassifier with k=3 neighbors, and it achieved an accuracy of 74.03% on the test data.
- Support Vector Machine (SVM): Support Vector Machines are versatile classifiers. We experimented with different kernel functions (linear, RBF, polynomial, sigmoid) within the SVM framework. The RBF kernel achieved the highest accuracy at 78.57% on the test data.
- Naive Bayes: Naive Bayes is a probabilistic classification algorithm based on the Bayes' theorem. In our model, it achieved an accuracy of 77.27% on the test data.
- Random Forest Classifier: The Random Forest Classifier is an ensemble learning method. We configured it with 1000 decision trees and achieved an accuracy of 80.52% on the test data.
- Decision Tree: Decision Trees are versatile and interpretable classifiers. We set a maximum depth of 4 for our tree and achieved an accuracy of 79.22% on the test data.
- XGBoost: XGBoost is an efficient and scalable gradient boosting library. In our model, it achieved an accuracy of 75.32% on the test data.
Final Output

Complete Guide
Setting up environment
First, create a new folder and open that folder in vs studio and open the terminal and first run the following command for creating a virtual environment. Now we need to install Django which runs the command.
Create a new project in Django by using the following command or running the following command in the terminal.
To download, the dataset click here and save it in the same folder.
Folder Structure:
Templates Folder
After that, we will make a template folder in which we create two files predict.html and home.html for making the frontend part of our Placement prediction system.
home.html:
In this file, we create a simple home page in which we write a simple heading massage welcome to Diabetes prediction System and add one button to redirect to the form page which is the second page of our Diabetes prediction or redirect one page to another page we are using a form action tag which we write the function name home which we create view.py file and we added a render_templates for redirect to predict page.
predict.html:
In this file, we created a simple form in which we need to fill in some input like health details like pregnancy, age, BMI, and many other details which is a form required for predicting diabetes in person and also we added a predict button when we click on button it will show the result as a flash message on same display screen like person have diabetes or not flash massage for perform all operations in our prediction system we created a two function predict and result through which we connected all the files separated and display result.
NOTE: Install all the dependencies by your own with appropriate command.
urls .py
In this file, we must add all paths, import the py file via Django, and call each template one by one using the URLs functionality, as well as connect all files via the path method.
setting .py
In this file, we import os and connect templates to the folder by using the following type of os.path joins code, for connecting the templates folder.

view .py
This is the main file of our project in which we will machine learning logistic regression algorithm to perform the operation of whether a person has Diabetes or not for which first we imported some library, first we imported Django and pandas and used sklearn library to train our data and for use logistic regression we also imported logistic regression and also the accuracy_score
We create three functions first for the home page, second for the display input form page, and third for the display result in which first we read our dataset by using pd.read, and then we train our dataset using train_ and train_Y and then we model our dataset and after that, we created 13 input using float and for fill person health details and after that, we use if and else condition like if our target is one its means Person have Diabetes prediction else Person doesn’t have Diabetes prediction which depends on the input values which is filled by according person report.
Run the following command in the terminal to start the project:
What's Next
As we wrap up our exploration of the Diabetes Prediction Project in Django, it's important to consider what's next. While we've covered the essentials, there are additional features and enhancements that readers can implement to take this project even further:
Extensive Error Testing
One valuable addition to the project is implementing extensive error testing. This ensures that users are provided with clear feedback when they make invalid selections. For instance, if a user selects a cell that is already filled or a cell that is outside the permissible range, the application should promptly notify them of the error. This enhancement not only improves user experience but also demonstrates a commitment to robust software development practices. Readers can explore Django's validation mechanisms and customize error messages to make the application more user-friendly and informative.
Conclusion
- This project exemplifies the powerful synergy between healthcare and technology. We've leveraged machine learning to develop a tool that aids in the early prediction of diabetes, potentially improving the lives of individuals at risk.
- The quality of the dataset is crucial for the success of any machine learning project. We've learned the importance of thorough data cleaning and preprocessing to ensure accurate model predictions.
- Experimenting with various machine learning algorithms has highlighted that the choice of the right model significantly impacts prediction accuracy. In our case, the Random Forest Classifier proved to be the most accurate.
- Building a user-friendly interface and considering the user experience is essential, especially when dealing with healthcare applications. Providing clear and informative feedback to users enhances trust and usability.
- Our project is not static. We've set the stage for ongoing improvements, whether through refining the machine learning model, enhancing the user interface, or addressing user feedback. Machine learning models, in particular, can benefit from periodic retraining with fresh data to maintain accuracy.