Difference Between Regression and Classification in Machine Learning

In the realm of machine learning, understanding the difference between regression and classification is fundamental. While both techniques are used for predictive modeling, they serve distinct purposes. This article delves into the nuances of regression and classification algorithms, highlighting their differences and when to employ each.
Classification Algorithms in Machine Learning

Classification algorithms in machine learning are methodologies designed to assign predefined categories or labels to instances based on their features. These algorithms learn patterns from labeled training data and then use this knowledge to classify new, unseen data points. They encompass a diverse range of techniques, including but not limited to decision trees, support vector machines, logistic regression, k-nearest neighbors, and neural networks. Each algorithm has its strengths and weaknesses, making it crucial to select the appropriate one based on the characteristics of the dataset and the specific requirements of the problem at hand.
Classification algorithms are widely used across various domains for solving different types of problems. Here are a few examples of their applications
-
Email Spam Detection:
Classification algorithms are frequently employed to classify emails as either spam or non-spam (ham). Features such as email content, sender information, and subject lines can be used to train models to accurately classify incoming emails, thereby filtering out unwanted spam messages. -
Medical Diagnosis:
In healthcare, classification algorithms are utilized for tasks such as disease diagnosis based on patient symptoms, medical imaging analysis for identifying anomalies or diseases like cancer in X-rays or MRI scans, and predicting patient outcomes or risks based on clinical data. -
Credit Scoring:
Banks and financial institutions use classification algorithms to assess the creditworthiness of loan applicants. These algorithms can classify applicants into different risk categories by analyzing various features such as credit history, income, and debt-to-income ratio, helping lenders make informed decisions about loan approvals and interest rates. -
Sentiment Analysis:
Classification algorithms play a crucial role in sentiment analysis, where they are employed to classify text data (such as social media posts, product reviews, or customer feedback) into positive, negative, or neutral sentiment categories.
Types of Classification Algorithms
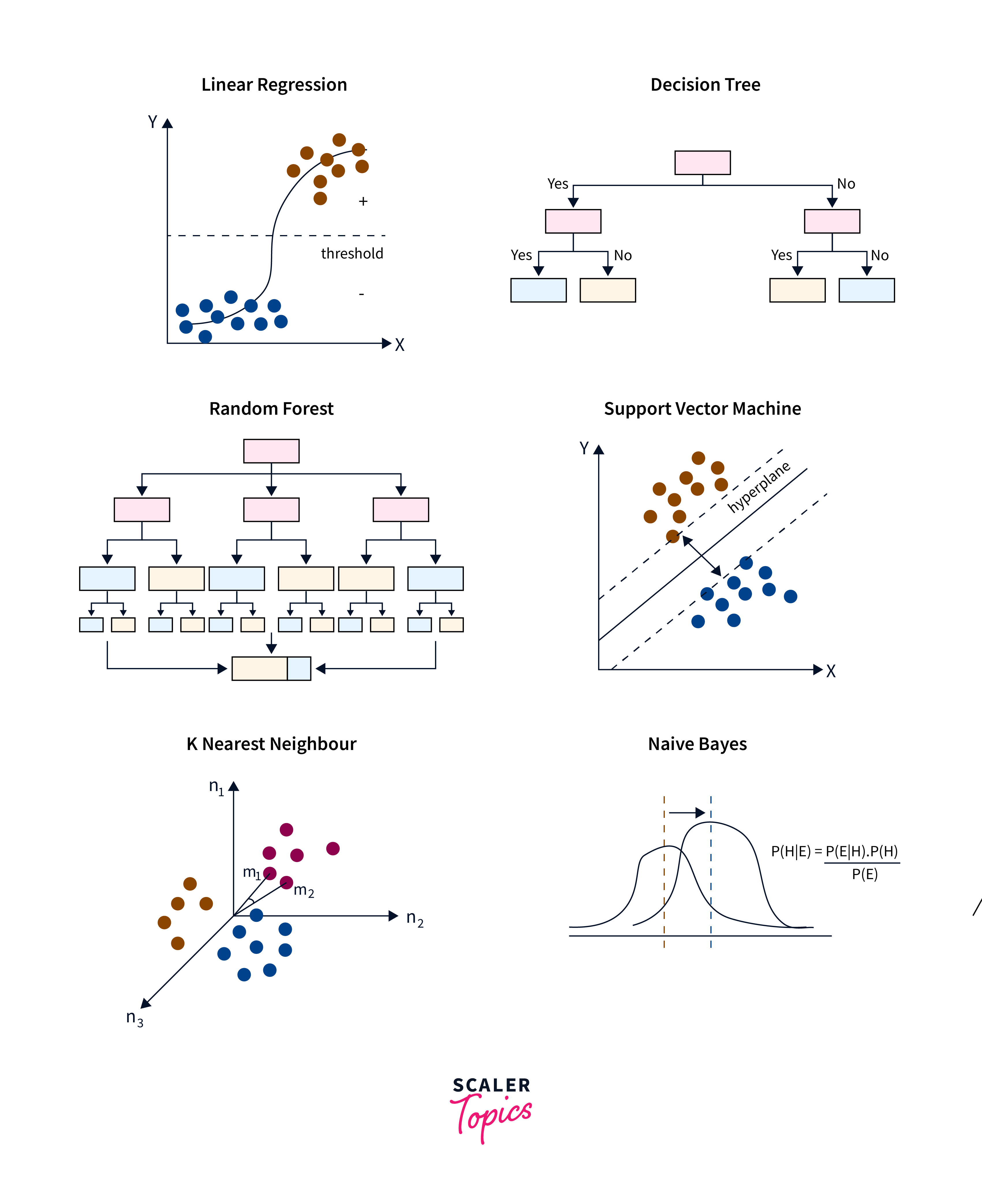
-
Logistic Regression:
- Despite its name, logistic regression is a classification algorithm commonly used for binary classification tasks.
- It models the probability of a binary outcome by applying the logistic function to a linear combination of the features.
- Logistic regression outputs probabilities that can be thresholded to make class predictions.
-
Decision Trees:
- Decision trees are versatile classification algorithms that recursively partition the feature space into subsets based on the values of the features.
- They are intuitive to understand and interpret, making them valuable for both predictive modeling and gaining insights into the decision-making process.
- However, decision trees can suffer from overfitting, which can be mitigated through techniques like pruning.
-
Random Forest:
- Random Forest is an ensemble learning method that constructs a multitude of decision trees during training and outputs the mode of the classes (classification) or the mean prediction (regression) of the individual trees.
- By aggregating predictions from multiple trees, random forests improve robustness and reduce overfitting compared to individual decision trees.
- They are highly scalable and can handle large datasets with high dimensionality.
-
Support Vector Machines (SVM):
- SVM is a powerful classification algorithm that finds the optimal hyperplane to separate data points into different classes.
- It works by maximizing the margin between the classes, which leads to better generalization performance.
- SVMs can manage datasets that are either linearly separable or non-linearly separable by employing various kernel functions.
-
K-Nearest Neighbors (KNN):
- KNN is a simple yet effective classification algorithm that classifies data points based on the majority class among their k nearest neighbors in the feature space.
- It is a non-parametric method, indicating it doesn't rely on assumptions about the underlying data distribution.
- However, KNN's performance may degrade with high-dimensional data and large datasets due to computational overhead.
-
Naive Bayes:
- Naive Bayes is a probabilistic classification algorithm based on Bayes' theorem with the "naive" assumption of independence between features.
- Despite its simplicity, Naive Bayes can perform well in many real-world applications, especially when the independence assumption holds approximately.
- It demonstrates computational efficiency and performs effectively with high-dimensional datasets.
Regression Algorithms in Machine Learning
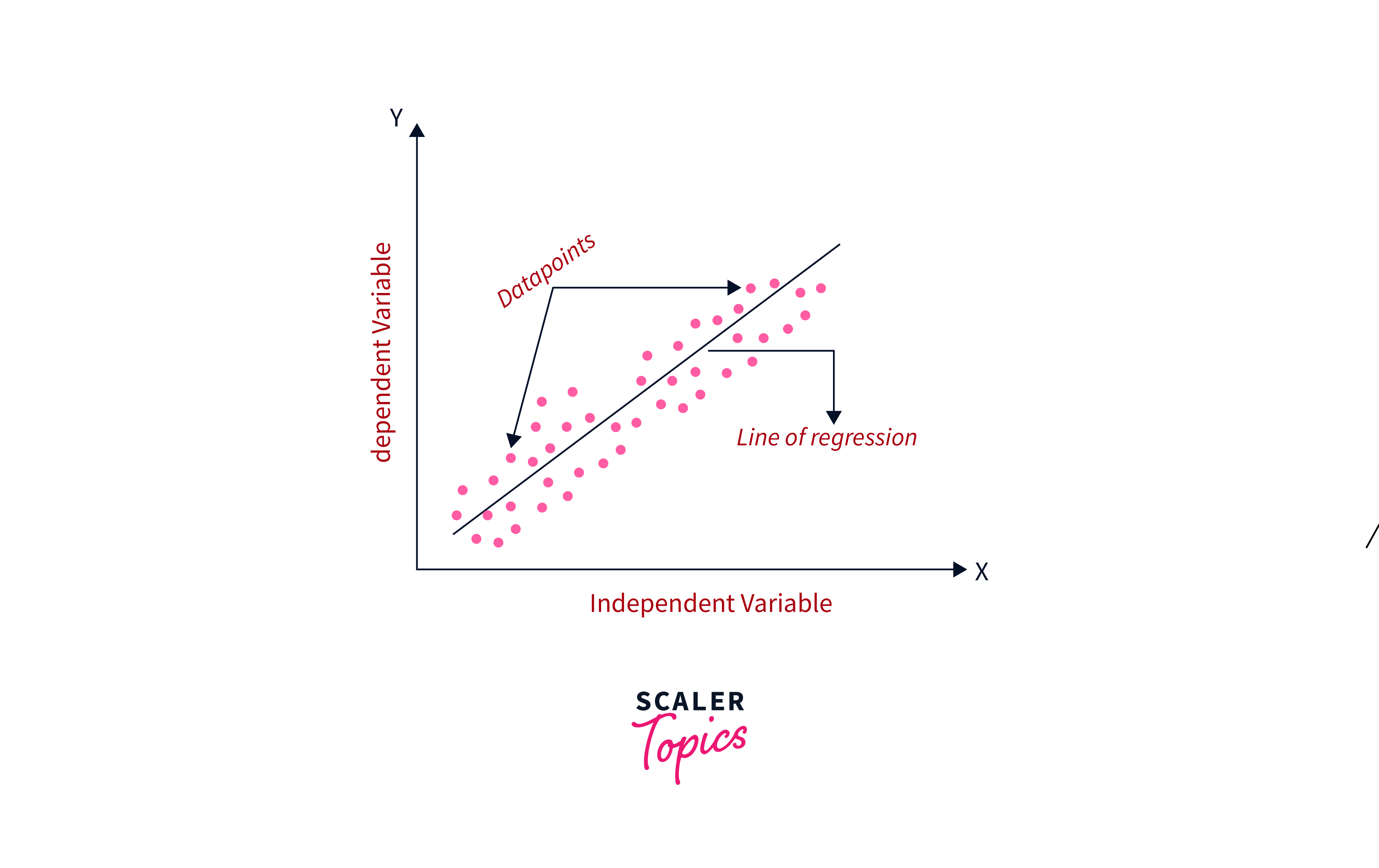
Regression algorithms in machine learning are techniques used to predict continuous numerical values based on input features. These algorithms analyze the relationship between independent variables and a dependent variable to make predictions. Examples include linear regression, polynomial regression, decision tree regression, random forest regression, support vector regression, and neural network regression. Each algorithm has its characteristics and is suited for different types of data and prediction tasks. Choosing the most appropriate regression algorithm depends on factors such as the nature of the data, the complexity of the relationship between variables, and the desired accuracy of the predictions.
-
House Price Prediction:
Regression algorithms can be used to predict the prices of houses based on various features such as square footage, number of bedrooms and bathrooms, location, and amenities. -
Demand Forecasting:
In retail and supply chain management, regression algorithms are utilized for demand forecasting. By analyzing historical sales data along with factors like seasonality, promotions, and economic indicators, regression models can predict future demand for products. -
Stock Price Prediction:
Financial analysts and investors use regression algorithms to predict stock prices and identify potential trends in financial markets. -
Healthcare Outcome Prediction:
Regression algorithms play a crucial role in healthcare for predicting patient outcomes and risks associated with diseases or medical treatments. -
Crop Yield Prediction:
In agriculture, regression algorithms are used for crop yield prediction, helping farmers optimize agricultural practices and maximize harvests.
Types of Regression Algorithms

-
Linear Regression:
- Linear regression stands as one of the simplest and most commonly employed regression techniques.
- It establishes the connection between independent variables and a dependent variable by fitting a linear equation to the provided data.
- The equation takes the form: , where is the dependent variable, are the independent variables, and are the coefficients.
-
Polynomial Regression:
- Polynomial regression expands upon linear regression by fitting a polynomial equation to the dataset.
- It can capture non-linear relationships between the independent and dependent variables.
- The polynomial equation takes the form: , where y is the dependent variable, is the independent variable, and is the degree of the polynomial.
-
Ridge Regression:
-
Ridge regression is a regularized version of linear regression that adds a penalty term to the loss function.
-
In Ridge regression, the penalty term added to the loss function is the sum of the squared magnitudes of the coefficients (also known as L2 regularization). This penalty term is proportional to the square of the magnitude of the coefficients vector β. Mathematically, the penalty term can be represented as:
-
Where:
-
is the regularization parameter that controls the strength of the penalty.
-
is the number of features or predictors.
-
represents the coefficients of the features.
- This penalty term, controlled by a hyperparameter penalizes large coefficients, thus reducing model complexity and mitigating overfitting.
- Ridge regression is particularly useful when dealing with multicollinearity (high correlation among independent variables).
-
Lasso Regression:
- Lasso (Least Absolute Shrinkage and Selection Operator) regression is another regularized linear regression method.
- It includes a penalty term, equivalent to the absolute value of the coefficients, within the loss function. This encourages sparsity and facilitates feature selection.
- Lasso regression is effective in situations where feature selection is crucial.
-
ElasticNet Regression:
- ElasticNet regression combines the penalties of ridge and lasso regression, providing a balance between the benefits of both methods.
- It can handle situations where there are many correlated independent variables.
- ElasticNet regression is particularly useful when dealing with high-dimensional datasets.
-
Support Vector Regression (SVR):
- SVR extends the principles of support vector machines (SVM) to regression problems.
- It aims to find the optimal hyperplane that best fits the data while minimizing errors within a specified margin.
- SVR is effective in capturing complex relationships between variables and handling non-linear regression tasks.
Difference between Classification and Regression Algorithms

| Aspect | Classification | Regression |
|---|---|---|
| Target Variable | Categorical | Continuous |
| Output | Class Labels | Real Numbers |
| Nature of Prediction | Class Membership | Quantity |
| Evaluation Metrics | Accuracy, Precision, Recall, F1-score, ROC-AUC | Mean Squared Error, R-squared, Mean Absolute Error |
| Examples | Spam Detection, Image Recognition, Sentiment Analysis | House Price Prediction, Stock Price Forecasting, Demand Prediction |
When to Use Classification/Regression?
When to Use Classification?
-
Categorical Outcome:
- Use classification when the target variable or outcome is categorical, meaning it falls into distinct classes or categories.
-
Discrete Predictions:
- Classification is suitable for making discrete predictions, where the output is confined to a finite set of classes or categories.
When to Use Regression?
-
Continuous Outcome:
- Regression is suitable when the target variable is continuous, meaning it can take on an infinite number of values within a specific range.
-
Quantity Prediction:
- Regression algorithms are ideal for predicting quantities or numerical values.
-
Relationship Analysis:
- Regression allows for the analysis of relationships between variables, uncovering how changes in one or more predictors affect the outcome.
FAQs
Q. When should I use classification over regression?
A. Use classification when dealing with categorical data or when you need to assign data points to predefined categories or classes.
Q. Can regression algorithms be used for classification tasks?
A. While regression algorithms are designed for continuous data, they can sometimes be adapted for classification by setting thresholds on the predicted values.
Q. What evaluation metrics are commonly used for regression?
A. Common evaluation metrics for regression include Mean Squared Error (MSE), R-squared, and Mean Absolute Error (MAE).
Conclusion
- Classification algorithms are used for predicting categorical outcomes, while regression algorithms are employed for continuous variables.
- Classification algorithms classify data into predefined categories, such as spam detection in emails or sentiment analysis in text data.
- Regression algorithms predict continuous values, like forecasting weather or predicting house prices.
- Key classification algorithms include logistic regression, decision trees, random forest, SVM, KNN, and Naive Bayes.
- Major regression algorithms include linear regression, polynomial regression, ridge regression, lasso regression, elastic net regression, and SVR.