Disk Scheduling Algorithms
Overview
'Disk Scheduling Algorithm' is an algorithm that keeps and manages input and output requests arriving for the disk in a system. As we know, for executing any process memory is required.
When it comes to accessing things from a hard disk, the process becomes very slow as a hard disk is the slowest part of our computer. There are various methods by which the process can be scheduled and can be done efficiently.
What are Disk Scheduling Algorithms in OS?
"Disk Scheduling Algorithms" in an operating system can be referred to as a manager of a grocery store that manages all the incoming and outgoing requests for goods of that store. He keeps a record of what is available in-store, what we need further, and manages the timetable of transaction of goods.
The 'Disk Structure in OS' is made in such a way that there are many layers of storage blocks on the disk. When we need to access these data from disk, we initialize a 'request' to the system to give us the required data. These requests are done on a large scale. So, there is a large number of input and output requests coming to the disk.
The operating system manages the timetable of all these requests in a proper algorithm. This is called a "Disk Scheduling Algorithm in OS". This algorithm helps OS to maintain an efficient manner in which input-output requests can be managed to execute a process. It manages a proper order to deal with sequential requests to the disk and provide the required data.
Since multiple requests are approaching the disk, this algorithm also manages the upcoming requests of the future and does a lining up of requests.
Importance of Disk Scheduling in Operating System
In our system, multiple requests are coming to the disk simultaneously which will make a queue of requests. This queue of requests will result in an increased waiting time of requests. The requests wait until the underprocessing request executes. To overcome this queuing and manage the timing of these requests, 'Disk Scheduling' is important in our Operating System.
Also, it may be possible that the two different requests are far from each other. For one request is at a spot from where the disk arm is near and the other request is on a different spot of the drive from where the disk arm is farther, Disk scheduling algorithms help reduce the disk arm moment.
The requests that are close to the disk arm will be serviced quickly and for the farther request, the disk arm needs to move from its location. "Disk Arm" is the part of the hard disk that moves through a different part of the hard disk, approaches requests, and serves them. Using 'Disk Scheduling', data can be accessed easily without wasting much time.
Key Terms Associated with Disk Scheduling
There are many terms that we need to know for a better understanding of Disk Scheduling. We are going to have a brief look at each of them one by one:
-
Seek Time: As we know, the data may be stored on various blocks of disk. To access these data according to the request, the disk arm moves and finds the required block. The time taken by the arm in doing this search is known as "Seek Time".
-
Rotational Latency: The required data block needs to move at a particular position from where the read/write head can fetch the data. So, the time taken in this movement is known as "Rotational Latency". This rotational time should be as less as possible so, the algorithm that will take less time to rotate will be considered a better algorithm.
-
Transfer Time: When a request is made from the user side, it takes some time to fetch these data and provide them as output. This taken time is known as "Transfer Time".
-
Disk Access Time: It is defined as the total time taken by all the above processes. Disk access time = (seek time + rotational latency time + transfer time)
-
Disk Response Time: The disk processes one request at a single time. So, the other requests wait in a queue to finish the ongoing process of request. The average of this waiting time is called "Disk Response Time".
-
Starvation: Starvation is defined as the situation in which a low-priority job keeps waiting for a long time to be executed. The system keeps sending high-priority jobs to the disk scheduler to execute first.
Types of Disk Scheduling Algorithm in OS
We have various types of Disk Scheduling Algorithms available in our system. Each one has its own capabilities and weak points.

Let us discuss them.
1. FCFS disk scheduling algorithm-
It stands for 'first-come-first-serve'. As the name suggests, the request that comes first will be processed first and so on. The requests coming to the disk are arranged in a proper sequence as they arrive. Since every request is processed in this algorithm, so there is no chance of 'starvation'.
Example: Suppose a disk having 200 tracks (0-199). The request sequence(82,170,43,140,24,16,190) of the disk is shown as in the given figure and the head start is at request 50.
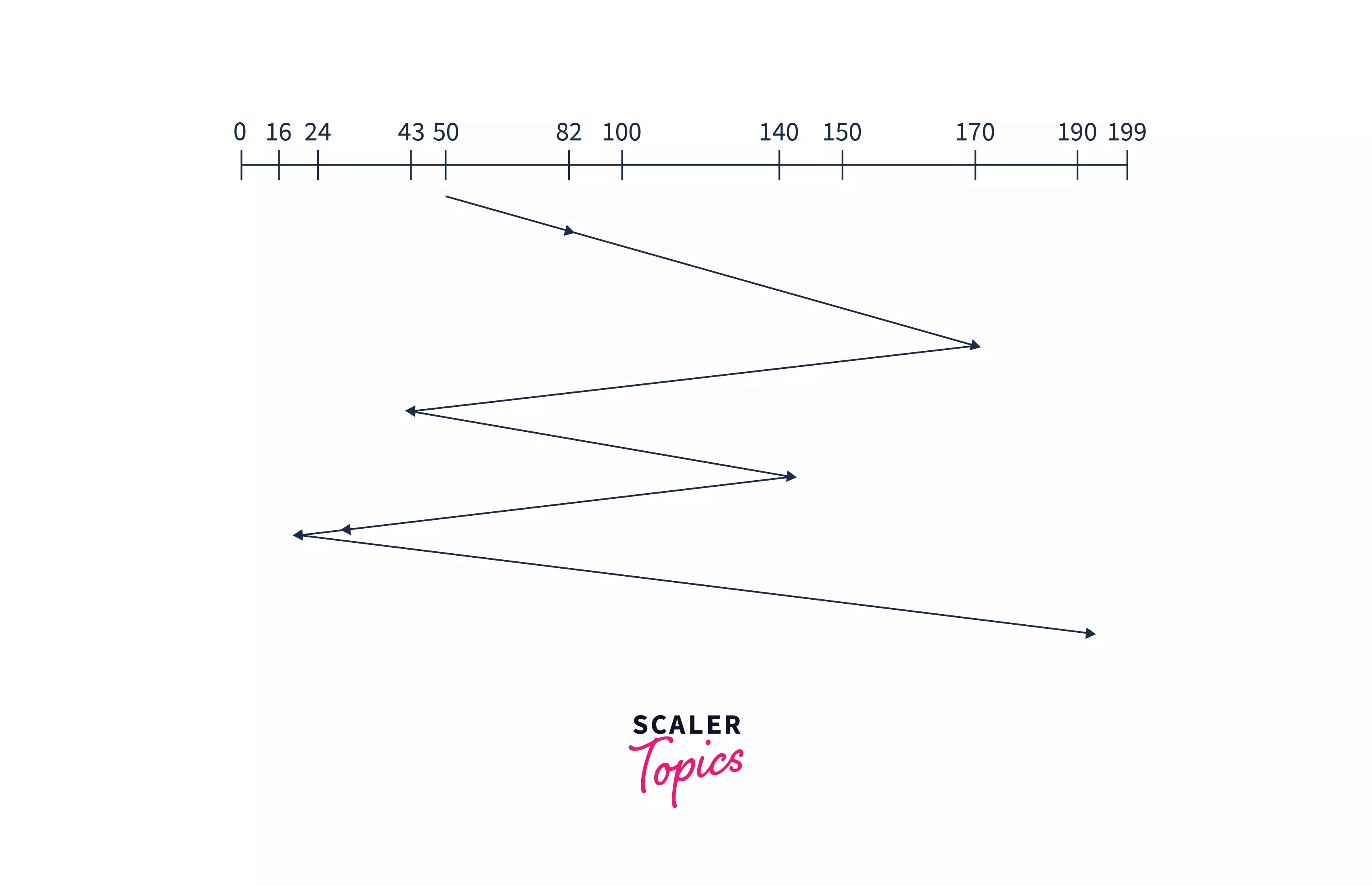
Explanation: In the above image, we can see the head starts at position 50 and moves to request 82. After serving them the disk arm moves towards the second request which is 170 and then to the request 43 and so on. In this algorithm,, the disk arm will serve the requests in arriving order. In this way, all the requests are served in arriving order until the process executes.
"Seek time" will be calculated by adding the head movement differences of all the requests:
Seek time= "(82-50) + (170-82) + (170-43) + (140-43) + (140-24) + (24-16) + (190-16) = 642
- Advantages:
- Implementation is easy.
- No chance of starvation.
- Disadvantages:
- 'Seek time' increases.
- Not so efficient.
2. SSTF disk scheduling algorithm-
It stands for 'Shortest seek time first'. As the name suggests, it searches for the request having the least 'seek time' and executes them first. This algorithm has less 'seek time' as compared to the FCFS Algorithm.
Example: Suppose a disk has 200 tracks (0-199). The request sequence(82,170,43,140,24,16,190) are shown in the given figure and the head position is at 50.
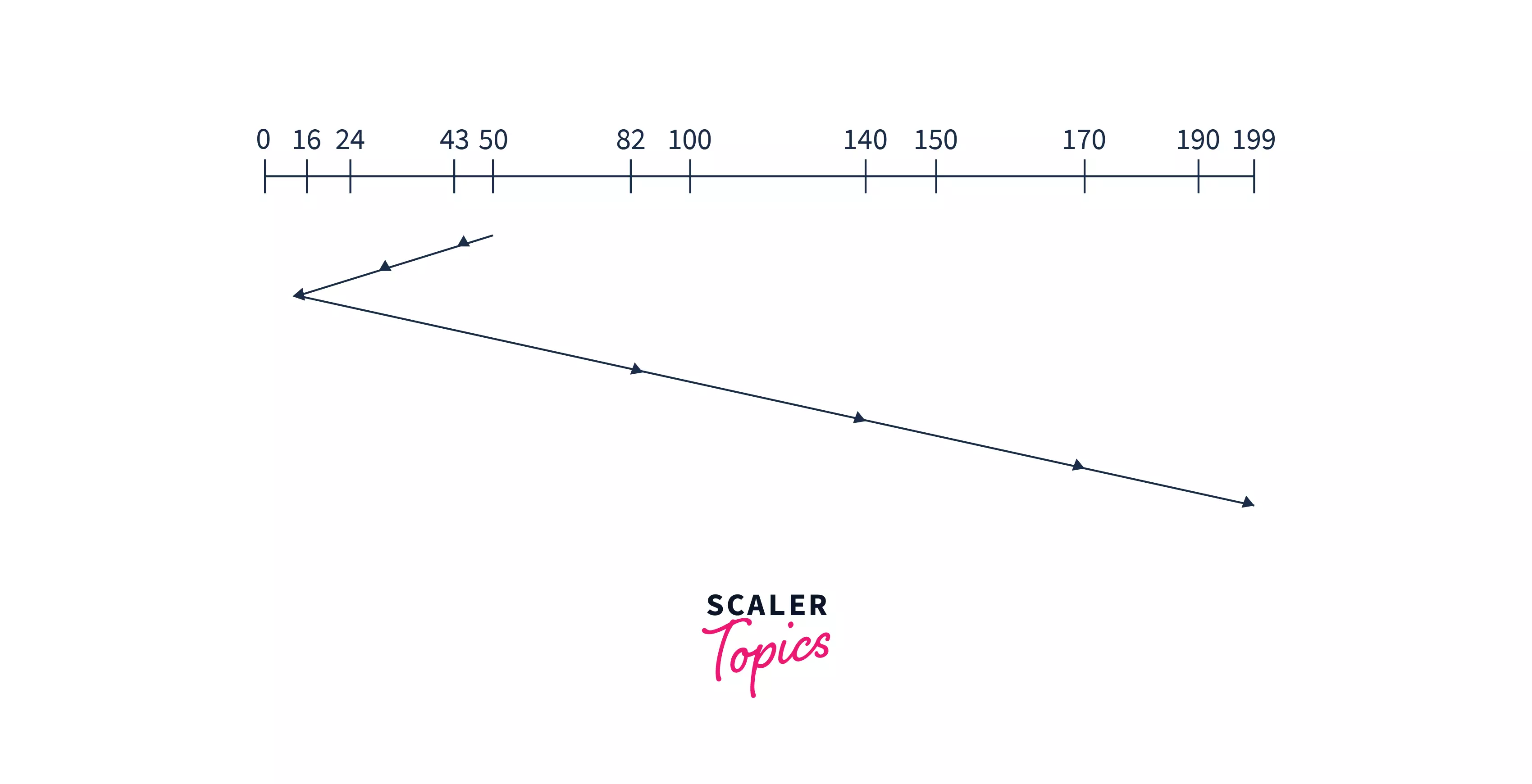
Explanation: The disk arm searches for the request which will have the least difference in head movement. So, the least difference is (50-43). Here the difference is not about the shortest value but it is about the shortest time the head will take to reach the nearest next request. So, after 43, the head will be nearest to 24, and from here the head will be nearest to request 16, After 16, the nearest request is 82, so the disk arm will move to serve to request 82 and so on.
Hence, Calculation of Seek Time = (50-43) + (43-24) + (24-16) + (82-16) + (140-82) + (170-140) + (190-170) = 208
-
Advantages:
- In this algorithm, disk response time is less.
- More efficient than FCFS.
-
Disadvantages:
- Less speed of algorithm execution.
- Starvation can be seen.
3. SCAN disk scheduling algorithm:
In this algorithm, the head starts to scan all the requests in a direction and reaches the end of the disk. After that, it reverses its direction and starts to scan again the requests in its path and serves them. Due to this feature, this algorithm is also known as the "Elevator Algorithm".
Example: Suppose a disk has 200 tracks (0-199). The request sequence(82,170,43,140,24,16,190) is shown in the given figure and the head position is at 50. The 'disk arm' will first move to the larger values.
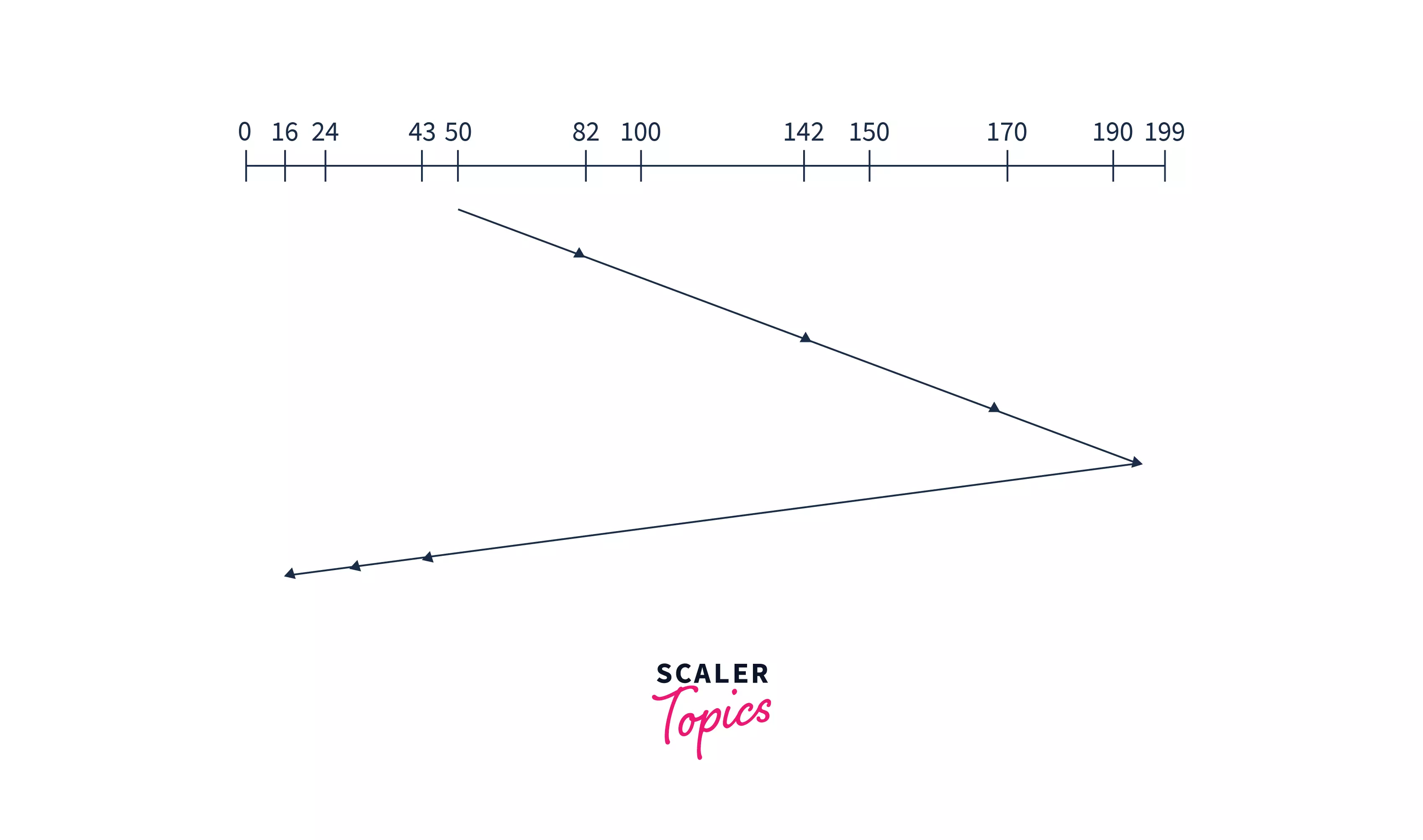
Explanation: In the above image, we can see that the disk arm starts from position 50 and goes in a single direction until it reaches the end of the disk i.e.- request position 199. After that, it reverses and starts servicing in the opposite direction until reaches the other end of the disk. This process keeps going on until the process is executed. Hence, the Calculation of 'Seek Time' will be like: (199-50) + (199-16) =332
-
Advantages:
- Implementation is easy.
- Requests do not have to wait in a queue.
-
Disadvantage:
- The head keeps going on to the end even if there are no requests in that direction.
4. C-SCAN disk scheduling algorithm:
It stands for "Circular-Scan". This algorithm is almost the same as the Scan disk algorithm but one thing that makes it different is that 'after reaching the one end and reversing the head direction, it starts to come back. The disk arm moves toward the end of the disk and serves the requests coming into its path.
After reaching the end of the disk it reverses its direction and again starts to move to the other end of the disk but while going back it does not serve any requests.
Example: Suppose a disk having 200 tracks (0-199). The request sequence(82,170,43,140,24,16,190) are shown in the given figure and the head position is at 50.

Explanation: In the above figure, the disk arm starts from position 50 and reached the end(199), and serves all the requests in the path. Then it reverses the direction and moves to the other end of the disk i.e.- 0 without serving any task in the path.
After reaching 0, it will again go move towards the largest remaining value which is 43. So, the head will start from 0 and moves to request 43 serving all the requests coming in the path. And this process keeps going.
Hence, Seek Time will be
- Advantages:
- The waiting time is uniformly distributed among the requests.
- Response time is good in it.
- Disadvantages:
- The time taken by the disk arm to locate a spot is increased here.
- The head keeps going to the end of the disk.
5. LOOK the disk scheduling algorithm:
In this algorithm, the disk arm moves to the 'last request' present and services them. After reaching the last requests, it reverses its direction and again comes back to the starting point. It does not go to the end of the disk, in spite, it goes to the end of requests.
Example
Explanation: The disk arm is starting from 50 and starts to serve requests in one direction only but in spite of going to the end of the disk, it goes to the end of requests i.e.-190. Then comes back to the last request of other ends of the disk and serves them. And again starts from here and serves till the last request of the first side. Hence, Seek time =(190-50) + (190-16) =314
-
Advantages:
- Starvation does not occur.
- Since the head does not go to the end of the disk, the time is not wasted here.
-
Disadvantage:
- The arm has to be conscious to find the last request.
6. C-LOOK disk scheduling algorithm:
The C-Look algorithm is almost the same as the Look algorithm. The only difference is that after reaching the end requests, it reverses the direction of the head and starts moving to the initial position. But in moving back, it does not serve any requests.
Example: Suppose a disk having 200 tracks (0-199). The request sequence(82,170,43,140,24,16,190) are shown in the given figure and the head position is at 50.
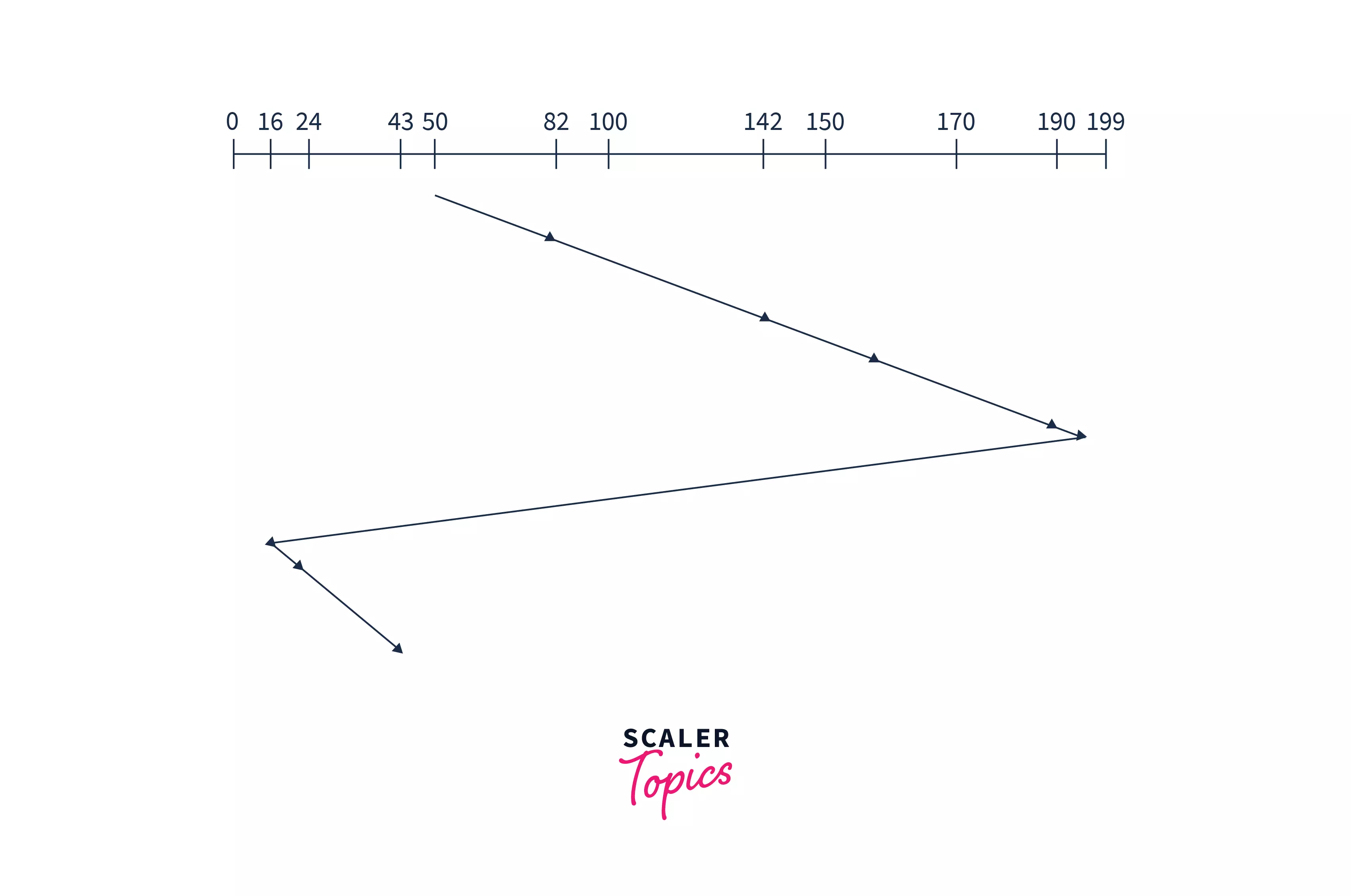
Explanation: The disk arm starts from 50 and starts to serve requests in one direction only but in spite of going to the end of the disk, it goes to the end of requests i.e.-190. Then comes back to the last request of other ends of a disk without serving them. And again starts from the other end of the disk and serves requests of its path. Hence, Seek Time
-
Advantages:
- The waiting time is decreased.
- If there are no requests till the end, it reverses the head direction immediately.
- Starvation does not occur.
- The time taken by the disk arm to find the desired spot is less.
-
Disadvantage:
- The arm has to be conscious about finding the last request.
Conclusion
- The Disk Scheduling Algorithm in OS is used to manage input and output requests to the disk.
- Disk Scheduling is important as multiple requests are coming to disk simultaneously and it is also known as the "Request Scheduling Algorithm"
- Various types of scheduling algorithms are:
- FCFS (First come first serve) algorithm
- SSTF (Shortest seek time first) algorithm
- Scan Disk Algorithm
- C-Scan (Circular scan) algorithm
- Look algorithm
- C-Look (Circular look) algorithm
- An algorithm in which starvation is minimum is considered an efficient algorithm.