Distributed Storage and Computing in Big Data
Overview
Traditional centralized storage and processing systems need to improve performance and scalability in the era of Big Data. Distributed storage and computing technologies come into play here. Data in a distributed system is distributed among numerous nodes, allowing faster processing and improved fault tolerance. In addition, high scalability and data redundancy are provided by distributed storage solutions such as Hadoop Distributed File System (HDFS) and Apache Cassandra. On the computer front, platforms such as Apache Spark and Hadoop MapReduce enable big datasets to be processed in parallel. These distributed technologies have changed how Big Data is managed and analyzed, allowing significant insights to be extracted from huge datasets in a timely and cost-effective manner.
Introduction
The amount of data generated in today's digital world is expanding at an unprecedented rate. This has resulted in creation of new technologies capable of storing, managing, and processing massive volumes of data efficiently. Distributed storage and computation with big data is one such technique.
Distributed storage stores data across numerous servers or network nodes rather than on a single workstation. This technology has several advantages over traditional storage solutions, including increased scalability, fault tolerance, and data availability.
Distributed computing, on the other hand, refers to dividing a major workload into smaller sub-tasks and distributing them among several devices in a network. This method provides faster processing of massive amounts of data and improved resource use.
Distributed storage and computation are critical in big data since traditional approaches cannot handle the sheer volume of generated data. As a result, technologies such as Hadoop Distributed File System (HDFS) and Apache Spark are commonly employed in distributed storage and computation.
What is Distributed Storage and Computing in Big Data?
Big Data has become essential to business operations in today's digital age. Businesses generate and gather massive volumes of data from many sources, and it is critical to efficiently store, handle, and analyze this data. Conventional centralized storage and processing methods can no longer handle Big Data's volume and complexity. Distributed storage and computation come into play here.
The process of storing data across numerous nodes or servers rather than a single centralized location is called distributed storage. Each node can store a piece of the data, and the distributed system guarantees that the data is duplicated between nodes to provide fault tolerance. While fault tolerance is a desirable property of many distributed systems, it is not a requirement for all of them. This method has various advantages, including scalability, flexibility, and high availability.
In computing, distributed computing is processing data across several devices or network nodes. This method allows for concurrently analyzing big datasets, considerably improving processing speed and efficiency. As a result, distributed computing systems such as Apache Spark and Hadoop MapReduce have become popular Big Data processing and analysis solutions.
The use of distributed storage and computation has transformed how Big Data is managed and analyzed. These methods have enabled the handling of huge datasets in a timely and cost-effective manner. The importance of distributed storage and processing solutions will only grow as the volume and complexity of data grow.
How Distributed Storage Works?
Instead of storing data on a single machine, distributed storage distributes it over numerous physical nodes. This method has various advantages, including greater dependability, fault tolerance, and scalability.
Data is divided into smaller bits known as "chunks" in a distributed storage system, and each chunk is stored on a different node. Because many copies of each chunk are scattered throughout the system, this replication helps ensure that data is not lost in the event of hardware failure.
The Hadoop Distributed File System is one of the most popular distributed storage options (HDFS). Many organizations use HDFS to store and handle enormous volumes of data, and it is designed to run on commodity hardware.
Data in HDFS is divided into smaller blocks, typically 64 or 128 megabytes and each block is replicated across numerous nodes in the cluster. The number of copies can be changed, with three being the default configuration. If one of the nodes fails, the data can be retrieved from another duplicate.
HDFS and other distributed storage systems have significant advantages over traditional storage solutions. They are well-suited for storing and managing huge volumes of data due to their higher dependability, fault tolerance, and scalability. In addition, distributed storage systems can further increase data access speeds by distributing data across numerous nodes, as nodes can work together to read and write data in parallel.
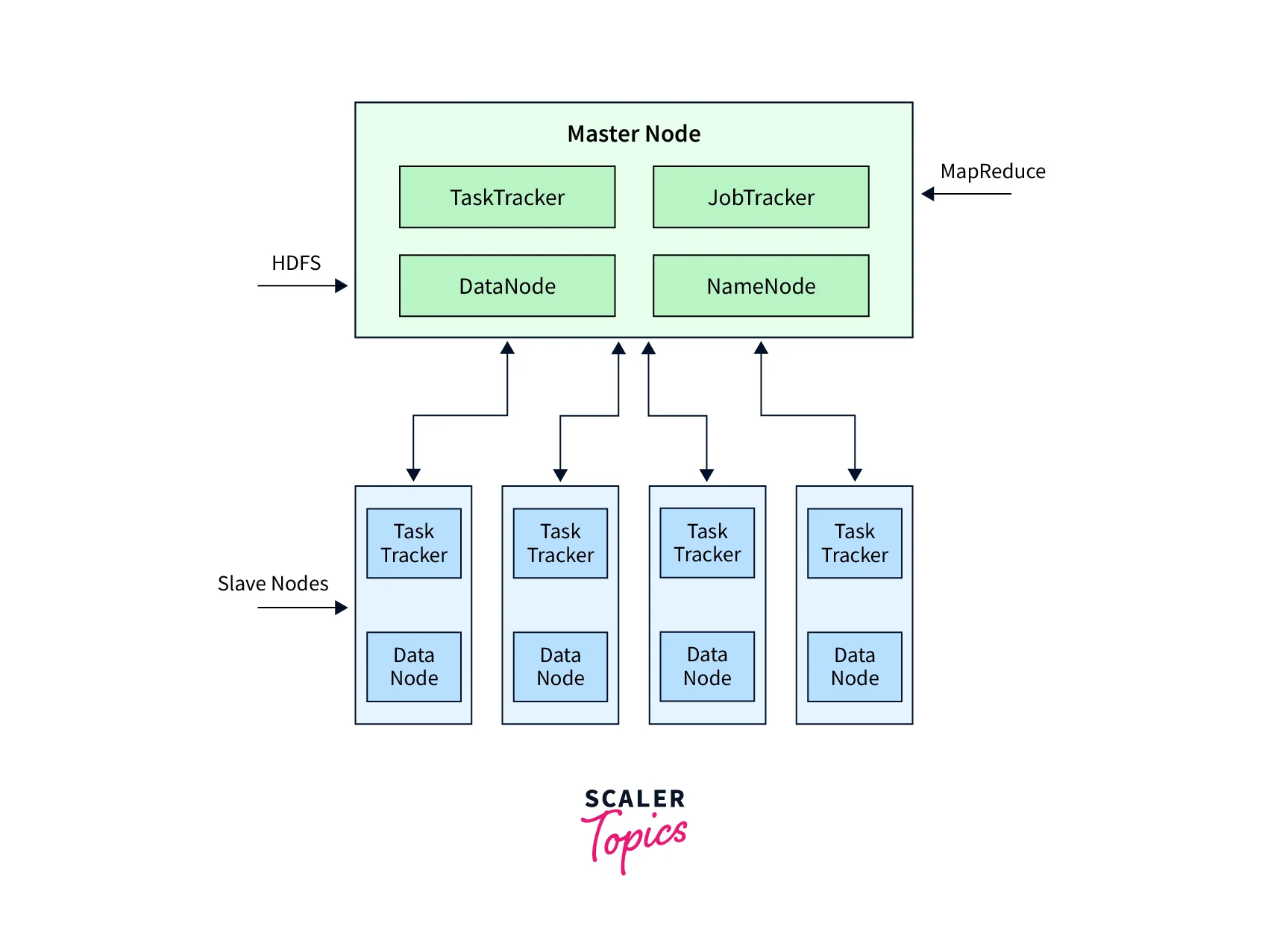
The Hadoop Distributed File System (HDFS) is a core component of the Hadoop ecosystem, and it is based on the master-slave architecture. The master node is called the NameNode, and it manages the file system namespace, which includes the directory tree and metadata for all files and directories in the system. The slave nodes are called DataNodes, and they store the actual data in the system.
Here's how the master-slave architecture of Hadoop works:
- When a user wants to store a file in HDFS, the client application first connects to the NameNode and sends a request to create the file. The NameNode creates a new entry in its namespace and assigns one or more DataNodes to store the data.
- The client then sends the file data to the assigned DataNodes. The DataNodes store the data in blocks and acknowledge the client when the write operation is complete.
- The NameNode keeps track of the locations of all the blocks that make up a file, and it provides this information to the client when the client wants to read the file.
- When a client wants to read a file, it first connects to the NameNode and requests the locations of the blocks that make up the file. The NameNode responds with the locations of the DataNodes that store the blocks.
- The client then reads the data directly from the DataNodes, without going through the NameNode. This allows for parallel processing and high throughput.
- If a DataNode fails or becomes unavailable, the NameNode detects the failure and replicates the data on another DataNode to ensure fault tolerance.
Refer to the image provided below for more clarity.
Need for Distributed Storage and Computing in Big Data
Today's data generation is expanding at an exponential rate. As a result, new technologies that can efficiently store, handle, and interpret huge amounts of data are required. Distributed storage and computing have emerged as the go-to big data solutions.
Using distributed storage, data can be stored across numerous nodes or servers rather than a single system. This method provides better scalability, fault tolerance, and data availability. It also makes it easier to expand storage capacity as the data volume grows.
Distributed computing, on the other hand, divides huge workloads into smaller sub-tasks and distributes them across a network of machines. This results in faster processing of massive amounts of data and improved resource utilization.
Traditional storage and computation technologies need to be improved in big data due to the sheer volume of data. Therefore, distributed storage and computation technologies such as Hadoop Distributed File System (HDFS) and Apache Spark are critical for effective large data management and processing.
Example:
One example of a banking or fintech application that requires distributed storage and computing is fraud detection. Fraudulent activities can involve large amounts of data, such as transactions, customer profiles, and external data sources, which need to be processed and analyzed in real-time to detect and prevent fraud.
In a traditional setup, a single machine may not be able to handle the volume and complexity of data involved in fraud detection. With distributed storage and computing, data can be stored across multiple machines and processed in parallel, enabling faster and more efficient fraud detection.
For example, a bank may use Hadoop, a popular distributed computing framework, to store and process data for fraud detection. The bank may store transaction data in Hadoop Distributed File System (HDFS) and use Hadoop MapReduce or Apache Spark for processing and analyzing the data. The bank can also use machine learning algorithms, such as decision trees or random forests, to detect patterns and anomalies in the data.
By using distributed storage and computing, the bank can handle large amounts of data, provide real-time fraud detection, and ensure fault tolerance by replicating data across multiple machines. This improves the accuracy and efficiency of fraud detection, reduces false positives, and enhances the bank's ability to protect its customers from financial losses due to fraud.
Features and Limitations
Let us review the many benefits and drawbacks of distributed storage and computation.
Partitioning
Partitioning is a critical component of big data distributed storage and computation. It entails partitioning data into smaller chunks and distributing them over multiple nodes or servers. This method provides for speedier processing and more efficient resource utilization.
Partitioning, however, has restrictions. For example, if data is not spread uniformly across partitions, some partitions may have greater processing demands, resulting in slower processing times. Partitioning can also increase network traffic and communication overhead, which can harm system performance.
Partitioning is a fundamental aspect of big data distributed storage and computation. Effective partitioning can result in significant performance gains, but it must be carefully designed and implemented to achieve the best benefits.
Replication
Partitioning and replication are two critical components of big data distributed storage and computation. Partitioning is splitting data into smaller divisions and distributing it over numerous nodes or servers. In contrast, replication is the process of producing duplicate copies of data across multiple nodes.
Partitioning and replication provide various advantages, including increased data availability, fault tolerance, and scalability. However, these functionalities have limits, such as higher storage and network cost and the requirement for careful data consistency and synchronization control.
Fault Tolerance
Fault tolerance is a critical component of big data distributed storage and computation. It refers to the system's capacity to continue operating even if hardware or software fails. This is accomplished by data replication, backup and recovery, and automatic failover.
While fault tolerance is essential for assuring data dependability and availability in distributed systems, it is not without restrictions. For example, replication and backup schemes can add storage and network overhead, making managing data consistency and synchronization difficult.
Elastic Scalability
Elastic scalability is an important aspect of large data distributed storage and computing. It refers to the system's capacity to scale up or down easily and seamlessly in response to changing data volume or processing requirements. This is accomplished using distributed architectures, parallel computing, and load balancing.
The elastic scalability does not guarantee linear scalability. Adding more resources may not always result in a proportional increase in performance or throughput. This can be due to a variety of factors, such as network latency, data skew, or contention for shared resources. While elastic scalability can help ensure that big data systems have enough resources to handle variable workloads, it can also result in underutilization of resources during periods of low demand. This can be costly in terms of hardware, power, and cooling expenses.
Cloud Computing vs Distributed Cloud
Let us discuss the differences between Cloud Computing and Distributed Cloud.
| Cloud Computing | Distributed Cloud |
|---|---|
| Refers to the use of remote servers accessible via the internet for storing, managing, and processing data and applications. | A network of decentralized, geographically dispersed servers collaborating to provide cloud services. |
| Third-party providers like Amazon Web Services or Microsoft Azure typically host and manage cloud services. | Operated by a network of geographically spread nodes, each responsible for a subset of cloud services. |
| Scalability on-demand, pay-as-you-go pricing, and access to resources from anywhere with an internet connection are all available. | Due to the usage of geographically scattered nodes, it provides enhanced fault tolerance, data availability, and reduced network latency. |
| May be less secure owing to the use of shared infrastructure, which increases the risk of data breaches or cyber-attacks. | Provides enhanced security and data privacy due to decentralized infrastructure, making it more difficult for attackers to access or compromise data. |
| Usually appropriate for applications requiring large computational resources, such as big data analytics or high-performance computing. | Appropriate for applications requiring high levels of fault tolerance and data availability, such as mission-critical systems or real-time applications. |
Edge Computing vs Distributed Cloud
Let us discuss the differences between edge computing and distributed cloud.
| Edge Computing | Distributed Cloud |
|---|---|
| Edge computing is the activity of processing and analyzing data at the network's edge, closer to the data source. | Distributed cloud is distributing cloud computing resources over several geographic locations. |
| Edge computing is intended to reduce latency and increase real-time data processing for applications that demand immediate reaction times. | Distributed cloud is intended to improve the scalability and availability of cloud computing resources by distributing them over several locations. |
| Edge computing is commonly used for applications requiring real-time data processing, such as IoT devices and autonomous vehicles. | Distributed cloud is commonly used for applications requiring scalable, reliable, and globally accessible cloud computing resources, such as enterprise applications and web services. |
| Edge computing devices are typically compact in size and power, with minimal storage capacity. | Distributed cloud resources are usually vast and scalable, with lots of processing power and storage space. |
| Edge computing is a decentralized architecture in which processing and storage occur at the network's edge. | Distributed cloud is a centralized architecture in which resources are dispersed across numerous locations yet controlled centrally. |
Example of A Distributed Storage System
A distributed storage system is a group of storage devices or servers that cooperate to deliver a unified storage solution. This technology offers more scalability, fault tolerance, and data availability than typical centralized storage systems.
Apache Hadoop Distributed File System is one example of a distributed storage system (HDFS). HDFS is a distributed file system that is open source and designed to store massive volumes of data across several nodes or servers.
HDFS employs a master-slave architecture, with a single NameNode as the master, managing the file system namespace and controlling file access. DataNodes behave as slaves, storing actual data on local file systems.
To ensure data availability and fault tolerance, HDFS employs replication. Data is replicated over many DataNodes, with replication factors that can be configured. HDFS also supports data partitioning, which allows big files to be partitioned into smaller portions for distributed storage and processing.
In HDFS, the NameNode is the master node that manages the file system namespace and metadata. It keeps track of the locations of all the blocks that make up a file, as well as the identity of the DataNodes that store the blocks. The NameNode is responsible for maintaining the consistency and integrity of the file system, as well as handling requests from clients for file system operations such as creating, deleting, or modifying files.
The Secondary NameNode is a helper node for the NameNode that periodically merges the edit log and fsimage files of the NameNode. This helps to reduce the amount of time needed for the NameNode to start up in case of a failure, as well as reducing the size of the edit log file, which can grow very large over time.
YARN, which stands for Yet Another Resource Negotiator, is a framework for managing resources in a Hadoop cluster. YARN allows multiple applications to share the same cluster resources, enabling better resource utilization and reducing the need for dedicated clusters for each application. YARN consists of two components: the ResourceManager, which manages cluster resources and schedules applications, and the NodeManager, which runs on each machine in the cluster and manages local resources such as memory and CPU. YARN enables the Hadoop ecosystem to support a wide range of distributed computing applications, including batch processing, interactive processing, stream processing, and machine learning.
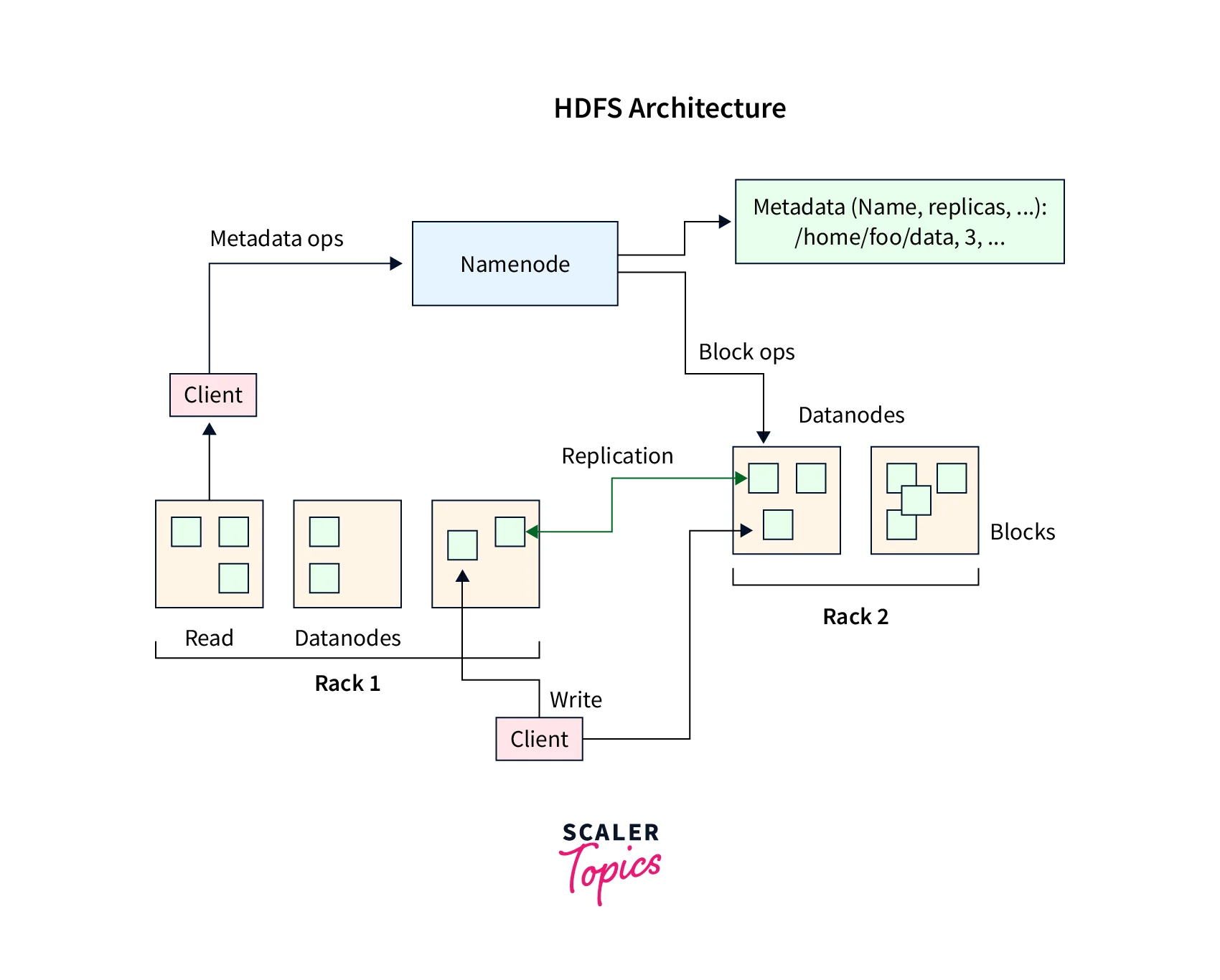
Advantages and Disadvantages of Distributed Storage
Let us discuss the advantages and disadvantages of distributed storage.
Advantages of Distributed Storage
- Scalability:
Because distributed storage systems can scale up and down to suit changing storage needs, it is easier to manage to expand data volumes. - Fault Tolerance:
Distributed storage systems are designed to provide fault tolerance and data redundancy, which means that data is still accessible from other nodes if one storage node fails. - Improved Availability:
By distributing data over numerous nodes, distributed storage systems can improve data availability by minimizing the likelihood of data loss due to hardware failure or other issues. - Cost-effective:
Because of the utilization of commodity hardware and open-source software, distributed storage can be less expensive than traditional centralized storage solutions.
Disadvantages of Distributed Storage
- Complexity:
Distributed storage systems can be difficult to set up and administer since they necessitate specific knowledge and abilities. - Data Consistency:
Maintaining data consistency across several nodes can be difficult, particularly during hardware failure or network problems. - Security:
Distributed storage systems can be exposed to security threats such as data breaches and cyber attacks, which must be mitigated with rigorous security measures. - Performance:
Due to increased network traffic and communication overhead, distributed storage systems may face performance difficulties. - Data privacy:
Since data is distributed across multiple nodes, it can be more challenging to ensure that data is kept private and confidential. Unauthorized access to any one node can potentially compromise the entire data set. - Here are some GDPR issues related to distributed storage in HDFS:
- Data Location:
HDFS stores data across multiple machines in a cluster, and the data may be replicated across different locations for fault tolerance. This makes it difficult to know the exact location of personal data, which is a GDPR violation. - Data Retention:
HDFS may store data indefinitely, which can also be a GDPR violation if personal data is stored longer than necessary. - Data Security:
HDFS may have vulnerabilities that can lead to data breaches, which can compromise the privacy and security of personal data. A data breach can also be a GDPR violation if personal data is accessed by unauthorized parties.
- Data Location:
- Authentication and authorization are also critical issues in distributed storage of HDFS. Here's how these issues can affect HDFS:
- Authentication:
HDFS requires authentication to access data stored in the file system. This ensures that only authorized users can access sensitive data. However, if authentication is not implemented properly, it can lead to security breaches and data loss. - Authorization:
HDFS also requires authorization to access data. This ensures that users have the necessary permissions to access specific data. However, improper authorization can lead to data breaches and data loss. - Kerberos:
Kerberos is a widely-used authentication protocol for Hadoop clusters. It enables secure communication between nodes in a cluster and authenticates users and services. However, setting up and managing Kerberos can be complex and time-consuming, and may require specialized knowledge.
- Authentication:
Conclusion
- High scalability and data redundancy are provided by distributed storage technologies such as Hadoop Distributed File System (HDFS) and Apache Cassandra.
- Distributed storage stores data across numerous servers or network nodes rather than on a single workstation.
- Distributed computing is the technique of dividing a major workload into smaller sub-tasks and distributing them among numerous computers in a network.
- The requirement for specific skills and experience to maintain and operate distributed storage and computing systems is one of the fundamental drawbacks of distributed storage and computing.