Dropout Layers in TensorFlow
Overview
In deep learning, where neural networks are becoming increasingly complex, preventing overfitting is a significant challenge. The dropout layer has emerged as a powerful technique to address this issue. This article delves into the dropout tensorflow layer, its impact on training and inference, optimization strategies, and its benefits and limitations.
As deep learning models grow in size and complexity, they become more prone to overfitting – a situation where a model learns the training data too well and fails to generalize to new, unseen data. Traditional methods like weight decay and early stopping have limitations in handling this problem. Dropout, a regularization technique introduced by Geoffrey Hinton and his colleagues in 2012, has since become a cornerstone in the toolbox of deep learning practitioners.

What is the Dropout Layer in Deep Learning?
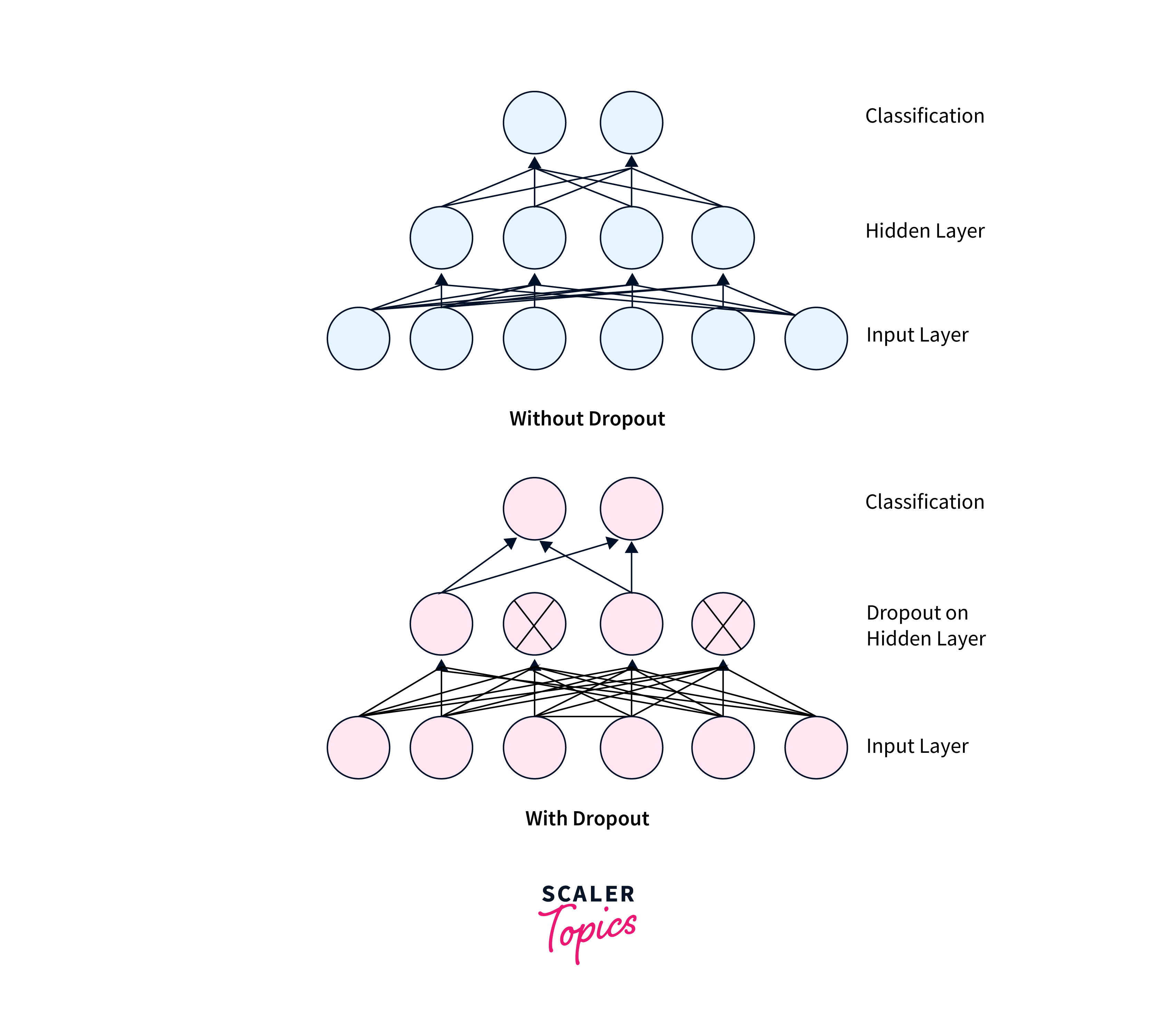
The dropout layer is a unique innovation that addresses overfitting by selectively dropping out a fraction of neurons during each training iteration. In a dropout tensorflow layer, a user-defined dropout rate determines the probability of any given neuron being excluded from the network temporarily. This dynamic exclusion ensures that the network doesn't rely too heavily on any single neuron, making it more robust and adaptable.
Understanding Overfitting
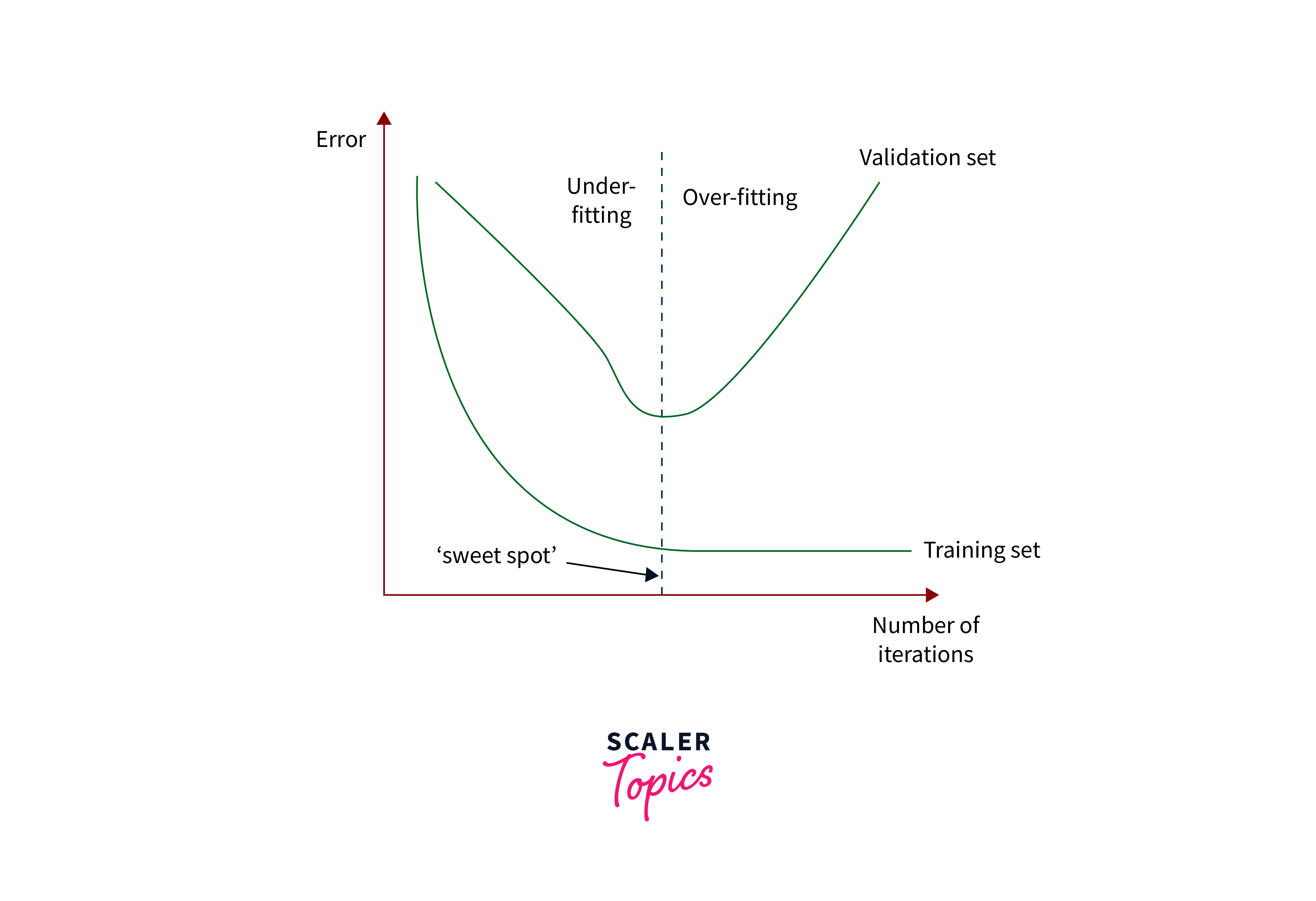
Overfitting occurs when a neural network learns not just the underlying patterns in the data but also the noise present in the training dataset. As a result, the network becomes overly specialized, performing poorly on unseen data. This phenomenon is a major obstacle to achieving high generalization performance.
Dropout Regularization
Dropout combats overfitting by introducing a controlled form of randomness into the network's structure. During each training batch, neurons are randomly deactivated based on the dropout tensorflow rate. Consequently, the network must learn redundant representations and rely on something other than specific neurons for accurate predictions. This leads to improved generalization, as the model learns to distribute its learning across a wider range of features.
Effect of Dropout on Training and Inference
Dropout introduces controlled randomness into the network during training, but its behavior changes during inference. Understanding how dropout tensorflow affects training and inference stages is crucial for effectively implementing this technique.
- Effect on Training: The dropout tensorflow rate determines the probability of a neuron being temporarily deactivated (dropped out) during each training iteration. This random deactivation makes the network robust and prevents it from relying too heavily on specific neurons. Here's how dropout affects training:
- Random Deactivation: For each training batch, dropout randomly deactivates neurons based on the dropout rate. This means that different subsets of neurons are active for each batch, leading the network to learn redundant representations.
- Ensemble Effect: Dropout can be thought of as training multiple sub-networks within the main network. Each sub-network corresponds to a unique combination of active and inactive neurons. This ensemble effect helps the network generalize better by learning a broader range of features.
- Regularization: Dropout acts as a form of regularization by preventing the network from memorizing the training data. The network learns to distribute its learning across multiple pathways, reducing overfitting.
- Effect on Inference: During inference (when the trained model makes predictions on new, unseen data), dropout behaves differently than training. The aim is to utilize the full expressive power of the trained network while accounting for the fact that dropout was used during training. Here's how dropout affects inference:
- No Dropout: During inference, there is no dropout applied. All neurons are active, and the entire network participates in making predictions.
- Weight Scaling: The network weights are scaled during inference to ensure that the expected output remains consistent between training and inference. The scaling factor equals the probability of a neuron dropping out during training (dropout rate). This scaling compensates for the fact that fewer neurons were active during training.
- Ensemble Averaging: Since dropout can be seen as training an ensemble of sub-networks, some researchers advocate for performing multiple forward passes through the network with dropout enabled during inference. The predictions from these passes are then averaged to obtain the final prediction. This ensemble averaging can further enhance model robustness.
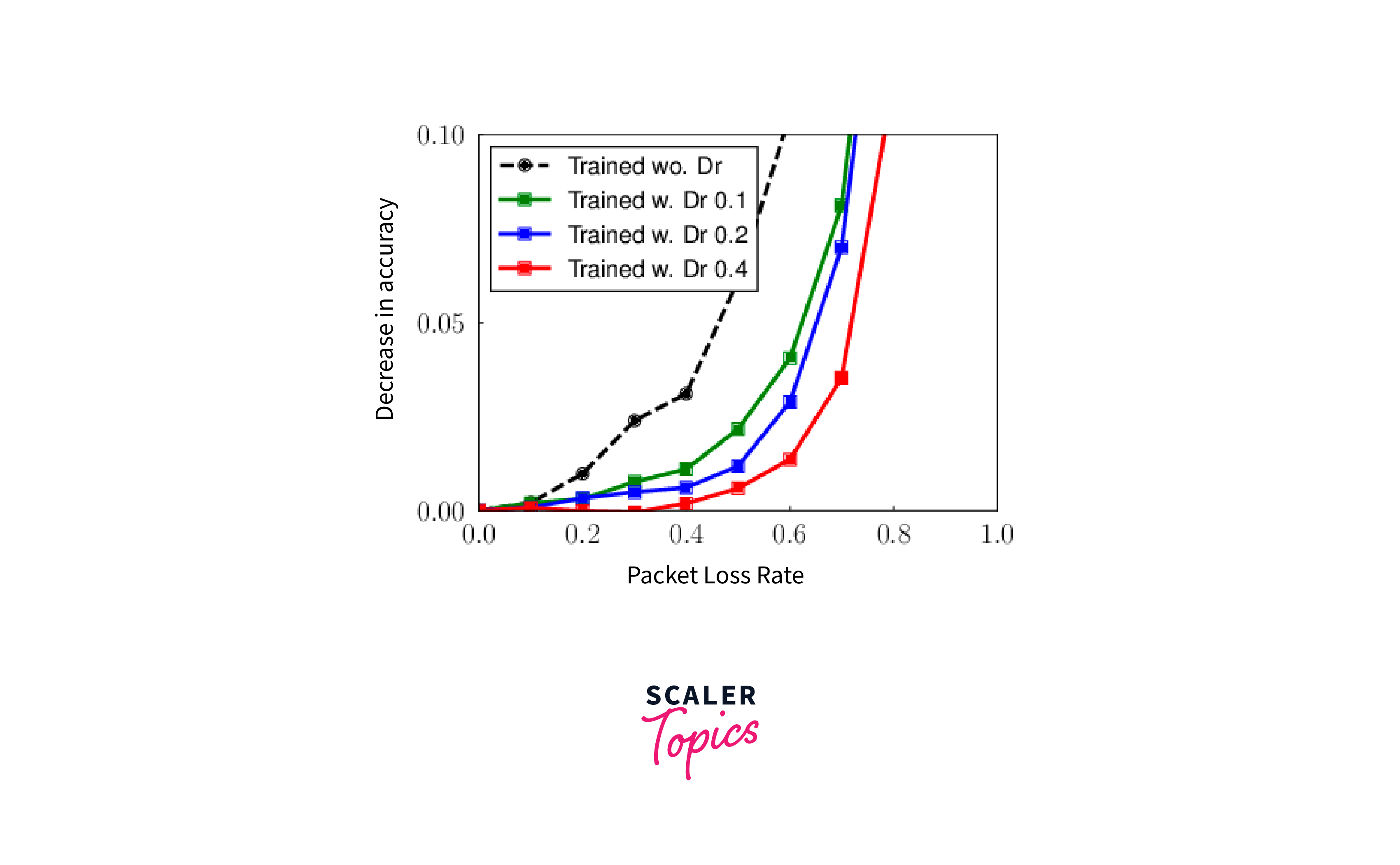
Tuning and Optimizing Dropout
Efficiently tuning the dropout rate within the Dropout tensorflow layer is pivotal to harnessing its potential for neural network regularisation. The dropout rate, which defines the proportion of neurons deactivated during training, necessitates a balanced adjustment to counter overfitting while retaining learning capacity. Here are essential strategies for achieving optimal dropout rates:
-
Gradual Initialization: Initiate model training with a conservative dropout rate, typically around 0.2 or 0.3. This initial restraint prevents excessive information loss during early training stages, enabling the model to adapt progressively.
-
Progressive Rate Adjustment: As the model trains, incrementally increase the dropout rate. This adaptive strategy allows the network to acclimate to the dropout's regularization impact over time. Vigilantly monitor validation performance during rate adjustments.
-
Hyperparameter Tuning: Leverage hyperparameter tuning techniques like grid or random search to identify the dropout rate that maximizes model performance. Systematically test a range of rates to discover the optimal setting.
Benefits and Limitations of Dropout
The Dropout layer in deep learning brings forth a range of benefits in enhancing model robustness and generalization, yet it also bears limitations that require consideration.
- Benefits:
- Robustness Enhancement: Dropout bolsters model resilience by discouraging over-reliance on specific neurons. This prevents the network from being overly sensitive to noisy or irrelevant features in the data.
- Overfitting Mitigation: One of Dropout's primary advantages is its efficiancy in mitigating overfitting. Randomly deactivating neurons during training disrupts co-adaptation, leading to excessive fitting to the training data.
- Ensemble Effect: Dropout effectively emulates an ensemble of thinned networks during training. This ensemble effect improves generalization by capturing diverse patterns and reducing model variance.
- Limitations:
- Extended Training Time: Applying Dropout often leads to increased training time. The repeated deactivation and reactivation of neurons demand more iterations for the network to converge effectively.
- Architecture Suitability: While Dropout benefits many deep learning tasks, it might only be universally suitable for some network architectures. Some models or tasks might not respond well to the dropout-induced noise.
- Tuning Complexity: Finding the optimal dropout rate can be intricate. An inappropriate rate might lead to underfitting or minimal regularization effect, rendering thorough hyperparameter tuning essential.
Best Practices of Dropout Layer
Utilizing the Dropout tensorflow layer effectively involves adhering to certain best practices to enhance model performance and prevent overfitting. Here's a practical implementation using Python and TensorFlow:
Step 1: Import necessary libraries,load the FashionMNIST data and Normalize it(_images / 255.0).
Output:
Step 2: Define the model and use tf.keras.layers.Dropout() in order to apply dropout in the model.
Step 3: Compile the model that has been defined with dropout tensorflow layers and set up a early stopping for the model. Now you can use model.fit to train the model.
Output:
Step 4: Evaluate the model using *model.evaluate* in the test dataset.
Output:
By changing the dropout tensorflow values we can fine-tune our model and also avoid overfitting.
Conclusion
- Dropout is an instrumental tool in deep learning, counteracting overfitting and enriching model generalization.
- A deep understanding of overfitting underscores the necessity of employing techniques like Dropout.
- Dropout tensorflow dynamically deactivates neurons, fostering model diversification and preventing overfitting.
- Gradual rate escalation, combined with systematic hyperparameter tuning, yields the optimal dropout rate.