Problem Statement
Given an array A of size N + 1. Each element in array A is between 1 and N. Write a program to find one of the duplicates in array A. If there are multiple answers, then print any.
Example 1
Input:
N = 5
A = [1, 2, 5, 3, 4, 3]
Output
3
Explanation
In this example, element 3 is repeated at position 4 and position 6 in array A.
Example 2
Input
N = 5
A = [1, 2, 4, 2, 4, 4]
Output
2
Explanation
In this example, element 2 is repeated as well as element 4 is repeated. Hence we can output any of them.
Constraints
Problem Discussion
Before moving on to the solution, let us first analyze the constraints.
In this problem, we are given that
This is because we are given that array
For example:
Then, the maximum number of unique values in
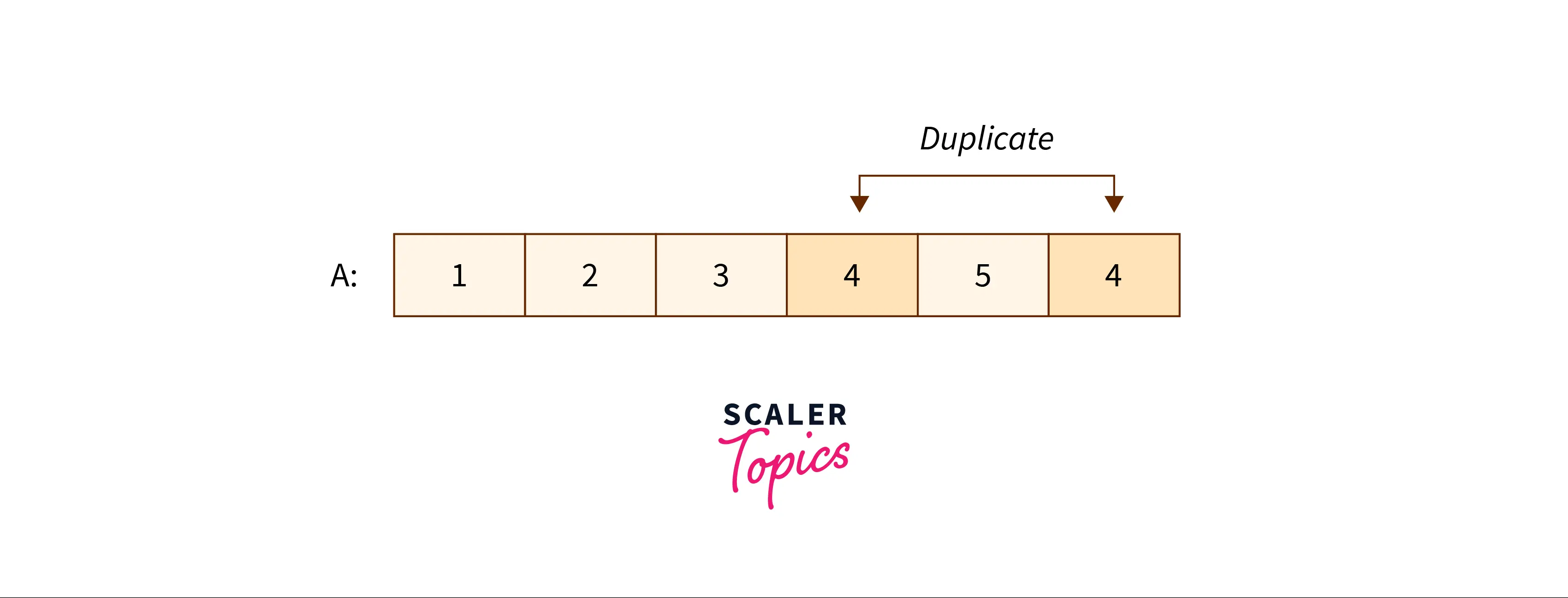
Approach 1: Brute Force
We can solve this problem using a simple brute force over the array
- For each element
- If such an element
In this way, we can find duplicate in array.
C++ Implementation
#include <bits/stdc++.h>
using namespace std;
int findDuplicate(vector<int> &arr, int length){
int duplicate = -1;
for(int i = 0; i < length; i ++) {
// Iterate over all arr[i].
for(int j = i + 1; j < length; j ++) {
// For each arr[i], consider all elements arr[j].
// We iterate from j = i + 1, so this guarantees that i != j.
if(arr[i] == arr[j]) {
duplicate = arr[i];
break;
}
}
if(duplicate != -1) break;
}
return duplicate;
}Java Implementation
import java.util.* ;
public class FindDuplicate{
public static int findDuplicate(ArrayList<Integer> arr, int length){
int duplicate = -1;
for(int i = 0; i < length; i ++) {
// Iterate for all arr[i].
for(int j = i + 1; j < length; j ++) {
// For each arr[i], consider all elements arr[j].
// We iterate from j = i + 1, so this guarantees that i != j.
if(arr.get(i) == arr.get(j)) {
duplicate = arr.get(i);
break;
}
}
if(duplicate != -1) break;
}
return duplicate;
}
}Python3 Implementation
def findDuplicate(arr:list, length:int):
duplicate = -1
for i in range(0, length):
for j in range(i + 1, length):
# For each arr[i], consider all elements arr[j].
# We iterate from j = i + 1, so this guarantees that i != j.
if arr[i] == arr[j]:
duplicate = arr[i]
break
if duplicate != -1:
break
return duplicateTime Complexity Analysis
In this method, we will do two nested iterations over the array
Time complexity:
Space Complexity Analysis
In this method, we only need a constant amount of variables of iteration. We are also keeping another variable to store the duplicate element. Hence the space complexity is
Space Complexity:
:::
:::section{.main}
Approach 2: Using Sorting
- Firstly, we will sort the given array A in increasing or decreasing order. This will guarantee that all equal elements are placed side by side in the sorted array.
- After sorting, equal elements will be placed one after the other so we can do a simple iteration on the sorted array A and check adjacent elements.
- When iterating over the array, if we find a position where adjacent elements are equal, then we have found our duplicate element.
For example
Now if we iterate over the sorted array
This means that the duplicate element is
C++ Implementation
#include <bits/stdc++.h>
using namespace std;
int findDuplicate(vector<int> &arr, int length){
// Sort the array A in increasing order.
sort(arr.begin(), arr.end());
int duplicate = -1;
for(int i = 0; i + 1 < length; i ++) {
// Compare adjacent elements.
if(arr[i] == arr[i + 1]) {
/* If adjancent elements are equal,
then we have found the duplicate element. */
duplicate = arr[i];
break;
}
}
return duplicate;
}Java Implementation
import java.util.* ;
class FindDuplicate {
public static int findDuplicate(ArrayList<Integer> arr, int length){
// Use Collections.sort as it works in O(N log(N)) time.
Collections.sort(arr);
int duplicate = -1;
for(int i = 0; i + 1 < length; i ++) {
// Compare adjacent elements.
if(arr.get(i) == arr.get(i + 1)) {
/* If adjancent elements are equal,
then we have found the duplicate element. */
duplicate = arr.get(i);
break;
}
}
return duplicate;
}
}Python3 Implementation
def findDuplicate(arr:list, length:int):
duplicate = -1
# Sort list in ascending order to group equal elements.
arr.sort()
for i in range(0, length - 1):
# Iterate over list arr and compare adjancet elements.
if arr[i] == arr[i + 1]:
# If adjancent elements are equal,
# then we have found the duplicate.
duplicate = arr[i]
break
return duplicateTime Complexity Analysis
We can sort the array using a comparison-based sorting algorithm. This will take
Time complexity:
We can also use a linear time sorting algorithm like Counting sort. In this case, the time complexity will be
Space Complexity Analysis
We are not using any extra space in our algorithm. We only need a constant number of variables for iteration and searching for the answer. Hence the space complexity is
Space Complexity:
If we use a linear time sorting algorithm like counting sort, then the space complexity will be
Approach 3: Using Frequency Array
To find a duplicate element in the array, we can make use of the observation that any duplicate number A[i] will occur more than once in array A. This means that suppose, if we know the number of times each element occurs in array A, then the duplicate element will be one of the elements whose frequency or the number of times it occurs in A is more than one.
Now how to find the frequency of each element ?
To do this, we can create a frequency table over the array A.
A frequency table is a map that represents the number of times each element occurs in array A. It represents the count or frequency of each element in array A.
- A frequency table can be implemented using arrays or a hash map. Generally, if the range of elements in the given array A is small, then it is preferred that we use arrays as a frequency table. This is because a hash map can have some overhead costs associated with it.
- Let’s say we have a variable
- Now, we iterate over array A and increment
- Now, we can simply check the frequency table. If at any point
For example,
Let us take
Now we build a frequency table
It means
As we can see the
C++ Implementation
#include <bits/stdc++.h>
using namespace std;
int findDuplicate(vector<int> &arr, int length){
int duplicate = -1;
// Range of arr[i] = [1, length - 1]
// Create a frequency array of size length.
// frequency[i] = Number of times i occurs in A.
vector<int> frequency(length, 0);
for(int x : arr) {
// For each element x, increment frequency[x] by 1.
frequency[x] += 1;
}
for(int x : arr) {
// Iterate over frequency array where frequency[x] > 0.
if(frequency[x] > 1) {
// Now if frequency[x] > 1, then x is a duplicate.
duplicate = x;
break;
}
}
return duplicate;
}Java Implementation
import java.util.* ;
public class FindDuplicate{
public static int findDuplicate(ArrayList<Integer> arr, int length){
int duplicate = -1;
// Range of arr[i] = [1, length - 1]
// Create a frequency array of size length.
// frequency[i] = Number of times i occurs in A.
int frequency[] = new int[length];
for(int x : arr) {
// For each element x, increment frequency[x] by 1.
frequency[x] += 1;
}
for(int x : arr) {
// Iterate over frequency array where frequency[x] > 0.
if(frequency[x] > 1) {
// Now if frequency[x] > 1, then x is a duplicate.
duplicate = x;
break;
}
}
return duplicate;
}
}Python3 Implementation
def findDuplicate(arr:list, length:int):
duplicate = -1
# Range of arr[i] = [1, length - 1]
# Create a frequency list of size length.
# frequency[i] = Number of times i occurs in A.
frequency = [0] * length
for i in arr:
# For each element x, increment frequency[x] by 1.
frequency[i] += 1
for i in arr:
# Iterate over frequency array where frequency[x] > 0.
if frequency[i] > 1:
# Now if frequency[x] > 1, then x is a duplicate.
duplicate = i
break
return duplicateTime Complexity Analysis
To create the frequency table, we need to do an iteration over the array
Time complexity:
Space Complexity Analysis
In this method, we need to create a frequency array of size
Space complexity:
Approach 4: Linked List Cycle Method
This method considers the array as a linked list. Suppose we consider the given elements of the array as nodes of a linked list. Here the
In this case, we have 4 linked lists, each of size 1.

Consider another example
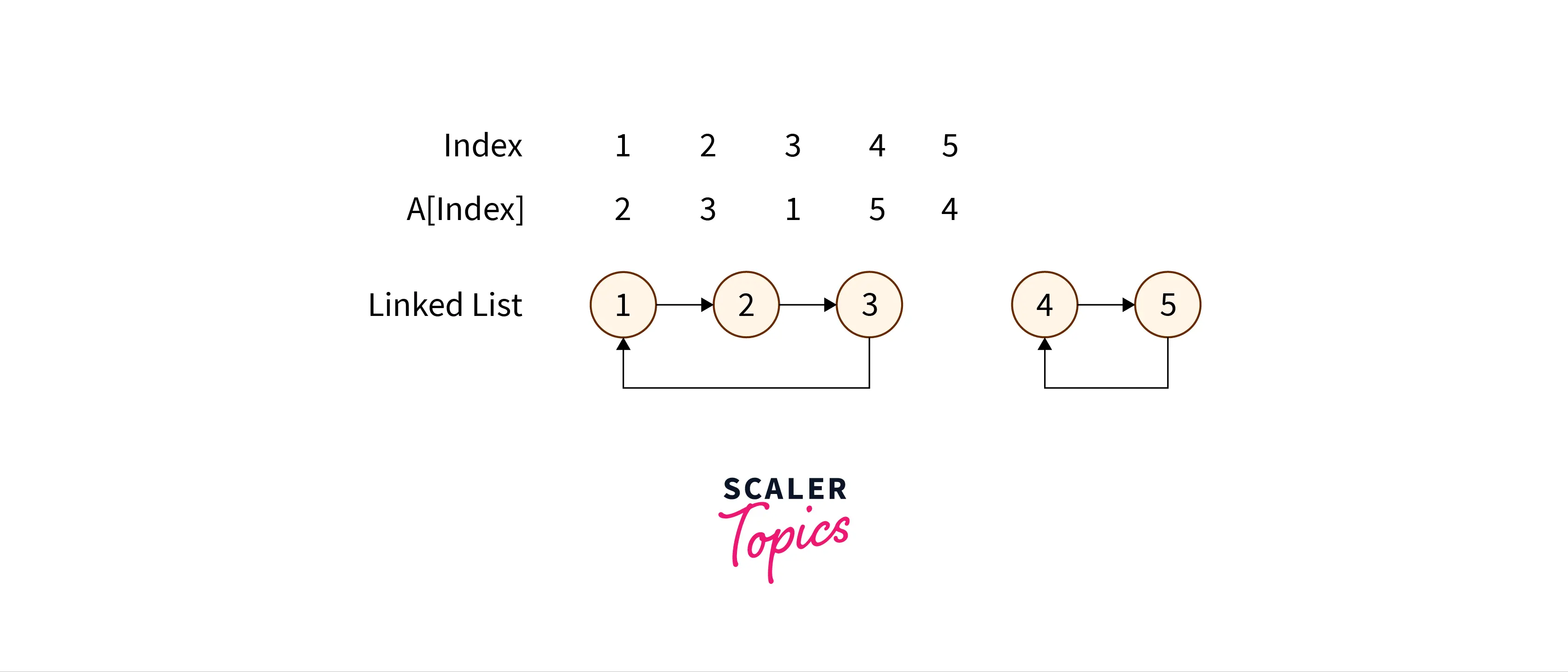
In this way, we represent each list A in the form of a linked list.
In the examples shown above, there are no duplicate elements in array A. Observe that, this means that each element occurs only once so there can be at most one incoming connection for each node. Try out some more examples to understand this clearly.
Now suppose, we add a duplicate element in array A. The main observation is that there will be at least one node in the linked list that will have multiple incoming connections. This is because there are at least two distinct positions i and j such that
- To find the duplicate element, we will represent array A in the form of a linked list.
- Now, to find the duplicate element, we need to find the start of the cycle. This can be done using Floyd’s cycle finding algorithm (discussed below).
Let us understand this using an example.
Consider
Let us say, we are index
At index
At index
At index
At index
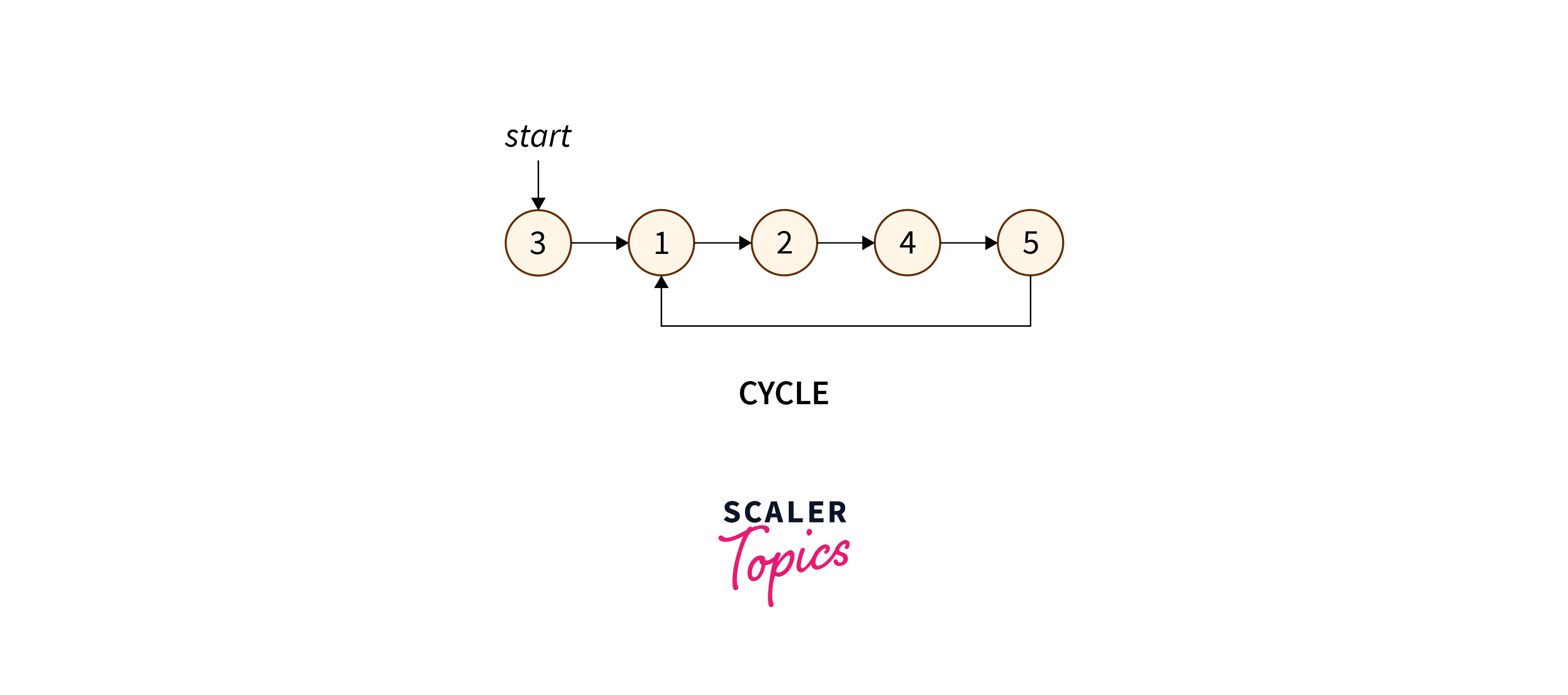
Now as we can see this represents a linked list structure with a cycle. So when the elements range between
The duplicate element will be the start of this cycle. This is because the duplicate element will point to an element that has already been visited. So, if we find the start of this cycle, then we can find the duplicate in array
Now to find the start of the cycle, we can use Floyd’s cycle finding algorithm.
The idea is to use two pointers – slow and fast pointer. We will start from index
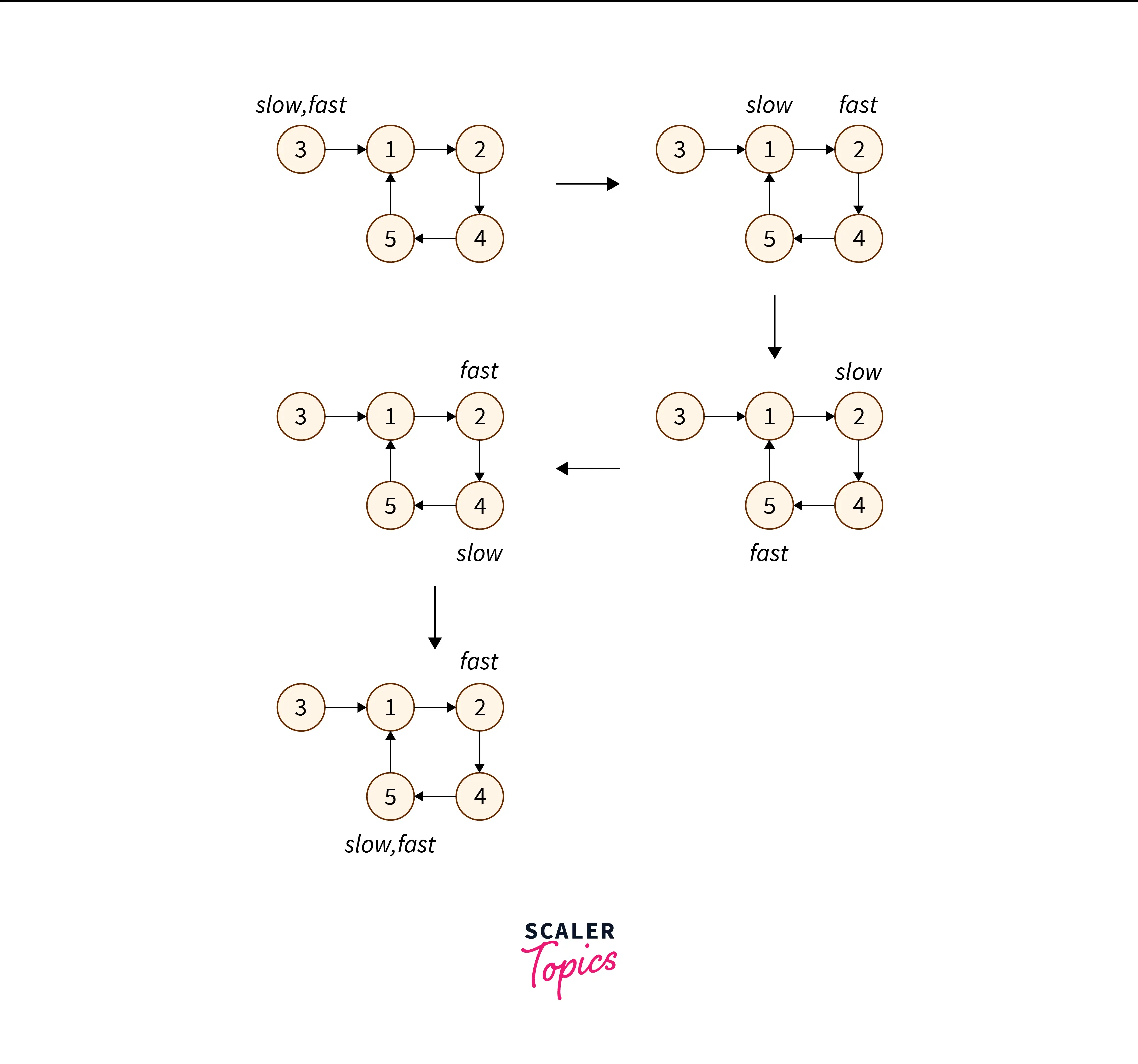
To find the start of the cycle, we will re-initialize the slow pointer to
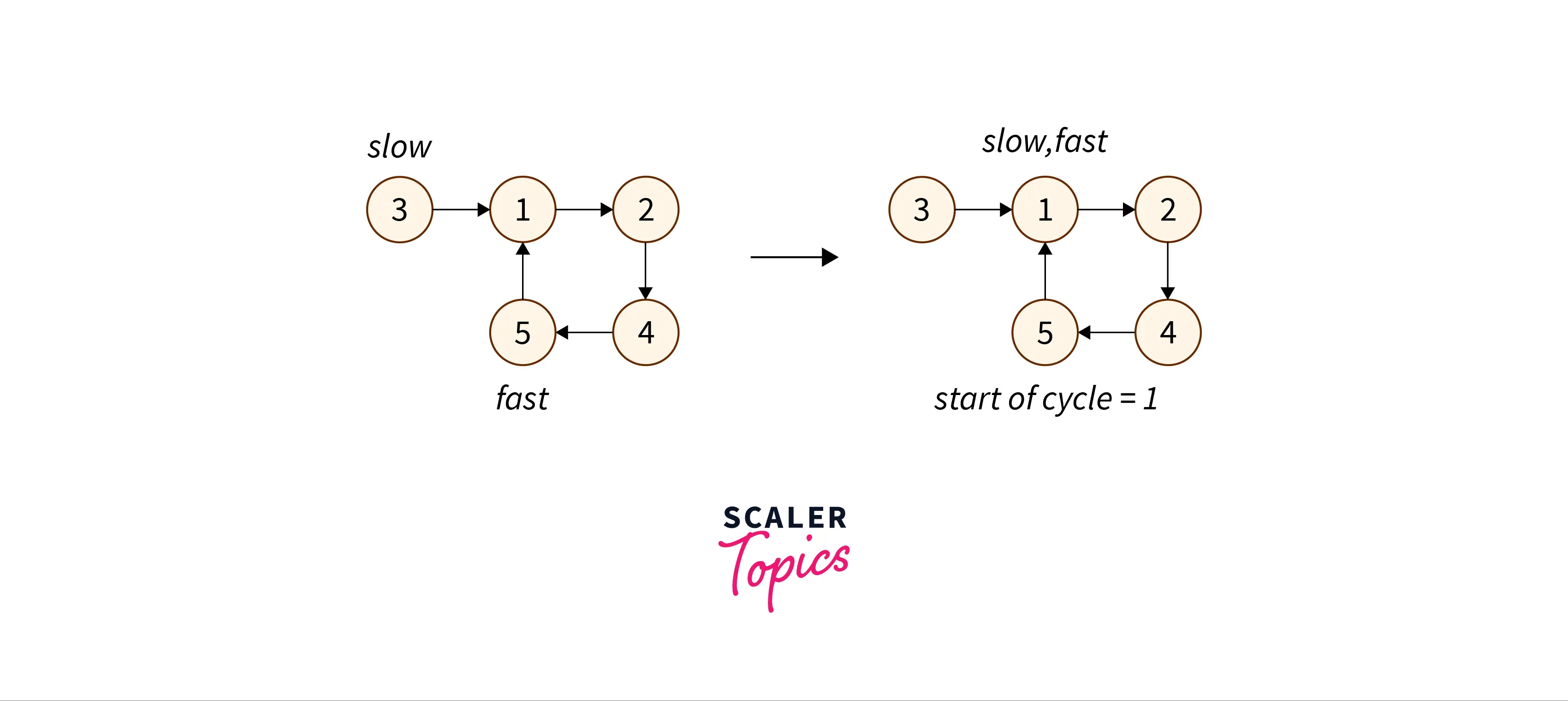
Now, the question is why should slow and fast pointers meet at the start of the cycle using this method. To understand this consider the image below.
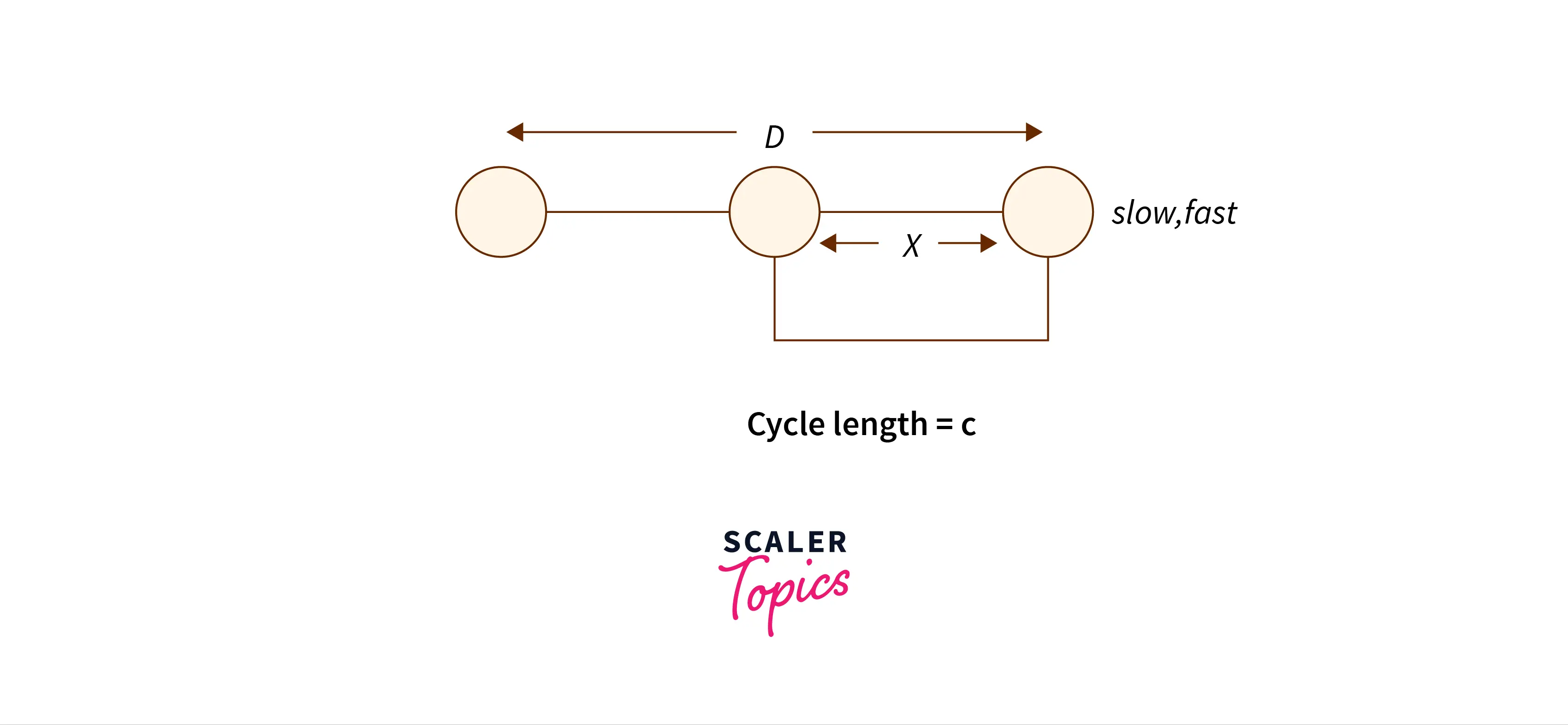
Let us say:
The distance between the first element and the point of collision of the slow and the fast pointer is
Cycle length =
Distance traveled by slow pointer =
If slow and fast pointers meet, then the distance between them is integer multiple of
This means
Now when we reset the slow pointer, the fast pointer has moved a distance of X from starting point of the cycle.
If we now update both the pointers, one at a time, this means that the slow pointer will travel a distance of
In this way, we can find the duplicate element in the array.
C++ Implementation
#include <bits/stdc++.h>
using namespace std;
int findDuplicate(vector<int> &arr, int length){
int slow = arr[0];
int fast = arr[arr[0]];
while (fast != slow) {
// slow increases by 1. fast increases by 2.
slow = arr[slow];
fast = arr[arr[fast]];
}
// Re-initialize slow to 0 and increase both slow and fast by 1.
slow = 0;
while (fast != slow) {
slow = arr[slow];
fast = arr[fast];
}
// Duplicate = Start of cycle = slow
return slow;
}Java Implementation
import java.util.* ;
public class FindDuplicate{
public static int findDuplicate(ArrayList<Integer> arr, int length){
int slow = arr.get(0);
int fast = arr.get(arr.get(0));
while (fast != slow) {
// slow increases by 1. fast increases by 2.
slow = arr.get(slow);
fast = arr.get(arr.get(fast));
}
// Re-initialize slow to 0 and increase both slow and fast by 1.
slow = 0;
while (fast != slow) {
slow = arr.get(slow);
fast = arr.get(fast);
}
// Duplicate = Start of cycle = slow
return slow;
}
}Python3 Implementation
def findDuplicate(arr:list, length:int):
slow, fast = arr[0], arr[arr[0]]
while fast != slow:
# slow increases by 1. fast increases by 2.
slow = arr[slow]
fast = arr[arr[fast]]
# Re-initialize slow to 0 and increase both slow and fast by 1.
slow = 0;
while fast != slow:
slow = arr[slow]
fast = arr[fast]
# Duplicate = Start of cycle = slow
return slow;Time Complexity Analysis
To find the cycle, we will iterate over the cycle once. This is true because when both the pointers – slow and fast are in the cycle, the distance between them will decrease by
Time complexity:
Space Complexity Analysis
If we look at the implementation, we are only using a constant amount of space. Hence the space complexity is
Space complexity:
Approach 5: Binary Search on Array
Suppose, we are given that there is only one duplicate element in array
The idea is to perform a binary search to find the duplicate element in the range
If
Then if
There are three cases.
- If the
- If the
- The case where the
Let us take an example to understand this.
Let us say
To find the number of elements that are less than or equal to a given value of
C++ Implementation
#include <bits/stdc++.h>
using namespace std;
int findDuplicate(vector<int> &arr, int length){
int low = 1, high = length - 1;
while(low < high) {
// Find mid element.
int mid = low + (high - low)/2;
int count = 0;
// Count the number of elements in A smaller than or equal to mid.
for(int x : arr) {
if(x <= mid) count ++;
}
if(count > mid) {
// In this case, at least duplicate lies in the range [1, mid].
high = mid;
}
else {
// In this case, at least one duplicate lies in the range [mid + 1, high].
low = mid + 1;
}
}
return low;
}Java Implementation
import java.util.* ;
public class FindDuplicate{
public static int findDuplicate(ArrayList<Integer> arr, int length){
int low = 1, high = length - 1;
while(low < high) {
// Find mid element.
int mid = low + (high - low)/2;
int count = 0;
for(int x : arr) {
// Count #elements smaller than or equal to mid.
if(x <= mid) count ++;
}
if(count > mid) {
// This means duplicate lies towards left range.
high = mid;
}
else {
// This means duplicate lies towards right range.
low = mid + 1;
}
}
return low;
}
}Python3 Implementation
def findDuplicate(arr:list, length:int):
low, high = 0, length - 1
while low < high:
# Find mid element.
mid = low + (high - low) // 2
count = 0
# Count #elements smaller than or equal to mid.
for x in arr:
if x <= mid:
count += 1
if count > mid:
# This means duplicate lies towards left range.
high = mid
else:
# This means duplicate lies towards right range.
low = mid + 1
return lowTime Complexity Analysis
In this method, we perform a binary search over array
Time Complexity:
Space Complexity Analysis
Binary search does not require any extra space. We use only a constant amount of space. Hence space complexity:
Approach 6: Count Iterations
In this method, the idea is to count the number of times, each element occurs while iterating over the array
- We will maintain a frequency table count with all entries as
- Now iterate over the array A and for each element
Example:
Iteration 1:
Iteration 2:
Iteration 3:
Iteration 4:
Iteration 5:
C++ Implementation
#include <bits/stdc++.h>
using namespace std;
int findDuplicate(vector<int> &arr, int length){
int duplicate = -1;
// Create a frequency table count of size length.
// count[i] = Frequency of i in arr.
vector<int> count(length, 0);
for (int i = 0; i < length; i++) {
// For each element arr[i], increment count[arr[i]] by 1.
int x = arr[i];
count[x] ++;
if (count[x] > 1) {
// If count[arr[i]] > 1, then we have found the duplicate element.
duplicate = x;
break;
}
}
return duplicate;
}Java Implementation
import java.util.*;
public class FindDuplicate{
public static int findDuplicate(ArrayList<Integer> arr, int length){
int duplicate = -1;
// Create a frequency table count of size length.
// count[i] = Frequency of i in arr.
int[] count = new int[length];
for (int i = 0; i < length; i++) {
// For each element arr[i], increment count[arr[i]] by 1.
int x = arr.get(i);
count[x]++;
if (count[x] > 1) {
// If count[arr[i]] > 1, then we have found the duplicate element.
duplicate = arr.get(i);
break;
}
}
return duplicate;
}
}Python3 Implementation
def findDuplicate(arr:list, length:int):
duplicate = -1
# Create a frequency table count of size length.
# count[i] = Frequency of i in arr.
count = [0] * length
for i in range(0, length):
# For each element arr[i], increment count[arr[i]] by 1.
count[arr[i]] += 1
if count[arr[i]] > 1:
# If count[arr[i]] > 1, then we have found the duplicate element.
duplicate = arr[i]
break
return duplicateTime Complexity Analysis
In this method, we are doing a single iteration over array A and updating the count in the frequency table. Hence the complexity of this solution is
Time complexity:
Space Complexity Analysis
This method requires a frequency table for calculating the answer. The frequency table is implemented using an array of size N+1. So, the space complexity is O(N).
Space complexity:
Approach 7: Sum of Elements
This method is useful if it is known that there is only one duplicate element. If the problem specifies a new constraint, that there can be only one duplicate element, then we can use the following math trick to find that duplicate element efficiently.
We know that array
Now we can write,
(Sum of elements from
From this, we can derive
We also know that the sum of elements from
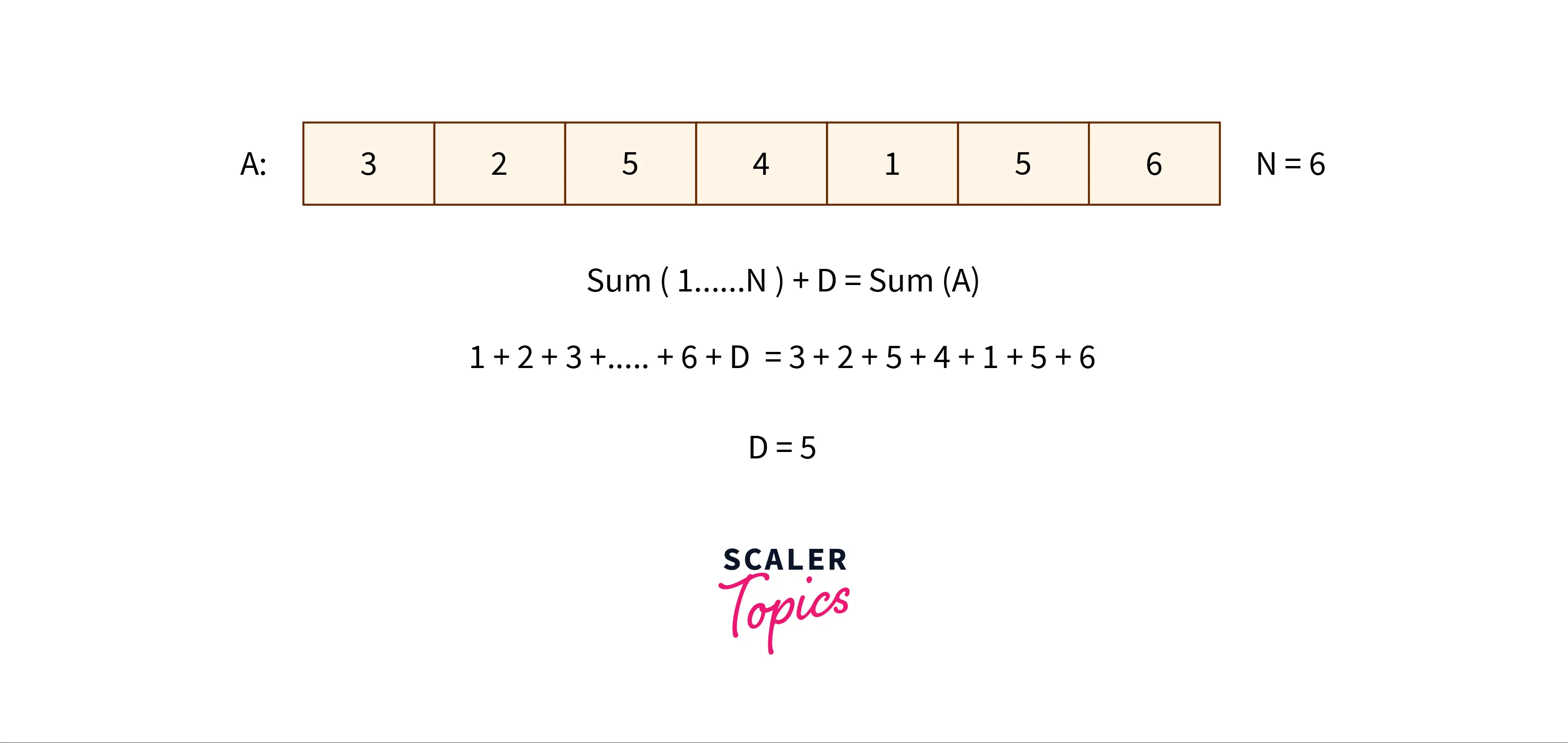
The only thing we need is the sum of elements in array
In this way, we can find the required duplicate element in array
Note that, this method is only useful when it is given that there is only one duplicate element. If this is not the case, then this method will fail as the equation defined above does not holds good.
C++ Implementation
#include <bits/stdc++.h>
using namespace std;
int findDuplicate(vector<int> &arr, int length){
// Works only when there is exactly one duplicate element.
int N = length - 1;
int sum = accumulate(arr.begin(), arr.end(), 0);
int duplicate = sum - ((N * (N + 1))/2);
return duplicate;
}Java Implementation
import java.util.*;
public class Solution{
public static int findDuplicate(ArrayList<Integer> arr, int length){
// Works only when there is exactly one duplicate element.
int duplicate = -1, sum = 0, N = length - 1;
for(int x : arr) sum += x;
duplicate = sum - (N * (N + 1))/2;
return duplicate;
}
}Python3 Implementation
def findDuplicate(arr:list, length:int):
# This works only when there is exactly one duplicate element.
N = length - 1
sum_of_list = sum(arr)
duplicate = sum_of_list - ((N * (N + 1))//2)
return duplicateTime Complexity Analysis
To find the duplicate in array
Time Complexity:
Space Complexity Analysis
We do not need any extra space to find the answer. We only need a variable to calculate the sum.
Space complexity:
Approach 8: Marker
In this approach, we will make use of the information given to us, that each element
Suppose we take a boolean
This is because if the value of
Space Optimization:
In this approach, we can optimize space as well. We are given positive elements in array
Example
Consider array
Iteration 1:
Make
Iteration 2:
Make
Iteration 3:
Make
Iteration 4:
Make
Iteration 5:
Make
Iteration 6:
Now, we see that
C++ Implementation
#include <bits/stdc++.h>
using namespace std;
int findDuplicate(vector<int> &arr, int length){
int duplicate = -1;
for (int i = 0; i < length; i++) {
int curr = arr[i];
// For each element arr[i], check if arr[abs(arr[i])] > 0.
if (arr[abs(curr)] > 0) {
// In this case, we mark arr[abs(arr[i])] as negative.
arr[abs(curr)] = -1 * arr[abs(curr)];
}
else {
/* In thie case, arr[i] was already visited,
so we have the duplicate element. */
duplicate = abs(curr);
break;
}
}
return duplicate;
}Java Implementation
import java.util.ArrayList;
public class Solution{
public static int findDuplicate(ArrayList<Integer> arr, int length){
int duplicate = -1;
for (int i = 0; i < length; i++) {
// For each element arr[i], check if arr[abs(arr[i])] > 0.
int curr = arr.get(i);
if (arr.get(Math.abs(curr)) > 0) {
// In this case, we mark arr[abs(arr[i])] as negative.
arr.set(Math.abs(curr), -1 * arr.get(Math.abs(curr)));
}
else {
/* In thie case, arr[i] was already visited,
so we have the duplicate element. */
duplicate = Math.abs(curr);
break;
}
}
return duplicate;
}
}Python3 Implementation
def findDuplicate(arr:list, length:int):
duplicate = -1;
for i in range(length):
# For each element arr[i], check if arr[abs(arr[i])] > 0.
curr = arr[i];
if arr[abs(curr)] > 0:
# In this case, we mark arr[abs(arr[i])] as negative.
arr[abs(curr)] = -1 * arr[abs(curr)]
else:
# In thie case, arr[i] was already visited,
# so we have the duplicate element.
duplicate = abs(curr)
break
return duplicate;Time Complexity Analysis
In this method, we are iterating over the array A once, hence the time complexity is
Time complexity:
Space Complexity Analysis
If you use a secondary array flag for marking each element, then the space complexity will be
If you re-use the same input array for marking each element, then the space complexity of our algorithm is
Conclusion
- There are many methods, discussed in this article, to find duplicates in an array.
- Some techniques like Binary search over an array or method using the sum of elements are only applicable only if there is a single duplicate element.
- Other techniques like using a frequency table or hash tables can be applied to a more general problem.
- The linked list cycle technique can be applied only when elements range from 1 to N.
- From this problem, you can learn how to apply different types of techniques to the same problem. It is essential to understand each algorithm and the complexity analysis.