Find S Algorithm in Machine Learning

In the vast landscape of machine learning algorithms, the "Find S Algorithm" emerges as a foundational method for inducing hypotheses from training data. Concept learning, a fundamental aspect of machine learning, often relies on algorithms like Find S to discern patterns and regularities within data. At its core, the Find S Algorithm operates on a principle of iterative refinement, gradually honing in on a hypothesis that accurately represents the underlying concept being learned. This article provides an in-depth exploration of the Find S Algorithm, elucidating its critical representations, steps, and significance in the realm of machine learning. For example, in a dataset of email messages labeled as spam or not spam, the Find-S algorithm could iteratively refine a hypothesis that identifies common features of spam emails, ultimately providing a rule to classify new emails as spam or not spam based on those features.
Important Representations in Find S Algorithm
Central to understanding the Find S Algorithm are the representations it employs to encode hypotheses and training examples. These representations play a pivotal role in guiding the algorithm's learning process. Here's a closer look at the essential representations utilized within the Find S Algorithm:
- ? (Question Mark):
This symbol denotes a wildcard or placeholder, signifying that any value is acceptable for the corresponding attribute. Within the context of hypothesis representation, the ? allows for flexibility in capturing patterns across diverse data instances. - Specific Value:
In contrast to the wildcard represented by ?, specific attribute values are explicitly defined within a hypothesis. For instance, if a particular attribute is known to have a specific value (e.g., "Cold" for temperature), it is directly incorporated into the hypothesis. - ϕ (Phi):
The symbol ϕ represents a null or empty value, indicating that no value is acceptable for the corresponding attribute. This representation serves to delineate constraints within the hypothesis, narrowing down the range of possible attribute values. - Most General Hypothesis:
Denoted by {?, ?, ?, ?, ?, ?}, the most general hypothesis encompasses all possible attribute values, offering a broad yet inclusive representation of the concept being learned. It serves as the starting point for hypothesis refinement within the Find S Algorithm. - Most Specific Hypothesis:
In stark contrast, the most specific hypothesis is represented by {ϕ, ϕ, ϕ, ϕ, ϕ, ϕ}, where each attribute is constrained to null values. This hypothesis encapsulates the utmost specificity, essentially representing a lack of knowledge about the underlying concept.
Steps Involved in Find S Algorithm
The Find S Algorithm operates through a systematic series of steps aimed at progressively refining hypotheses based on provided training examples. This iterative process facilitates the extraction of underlying patterns and regularities from data. Here's a comprehensive breakdown of the steps involved:
-
Initialization:
The algorithm commences by initializing the hypothesis to the most specific representation, {ϕ, ϕ, ϕ, ϕ, ϕ, ϕ}. This starting hypothesis encapsulates the absence of any prior knowledge about the concept being learned. -
Iteration through Training Examples:
- For each training example encountered: If the example is negative (i.e., does not conform to the concept being learned), no changes occur to the hypothesis. The algorithm maintains its specificity in light of conflicting evidence.
- If the example is positive (i.e., aligns with the concept being learned):
- The algorithm evaluates whether the current hypothesis is too specific to accommodate the positive example.
- If deemed too specific, the hypothesis is generalised to encompass the observed attribute values of the positive example.
- This generalisation process involves replacing null (ϕ) values with specific attribute values from the positive example or introducing wildcard (?) symbols where appropriate.
-
Iterative Refinement:
The algorithm iterates through the training examples, progressively refining the hypothesis with each encounter. By assimilating both positive and negative instances, the algorithm hones in on a hypothesis that accurately captures the underlying concept. -
Convergence:
The iterative process continues until all training examples have been processed. At this juncture, the algorithm yields a final hypothesis that encapsulates the learned concept based on the provided data. -
Final Hypothesis:
The culmination of the algorithm's iterative refinement is the derivation of a final hypothesis. This hypothesis represents a synthesized abstraction of the underlying concept, encapsulating the observed patterns and regularities within the training data.
By systematically navigating through these steps, the Find S Algorithm adeptly traverses the space of hypotheses, culminating in the extraction of actionable knowledge from data.
Algorithm
The Find S Algorithm can be described with the following pseudocode:
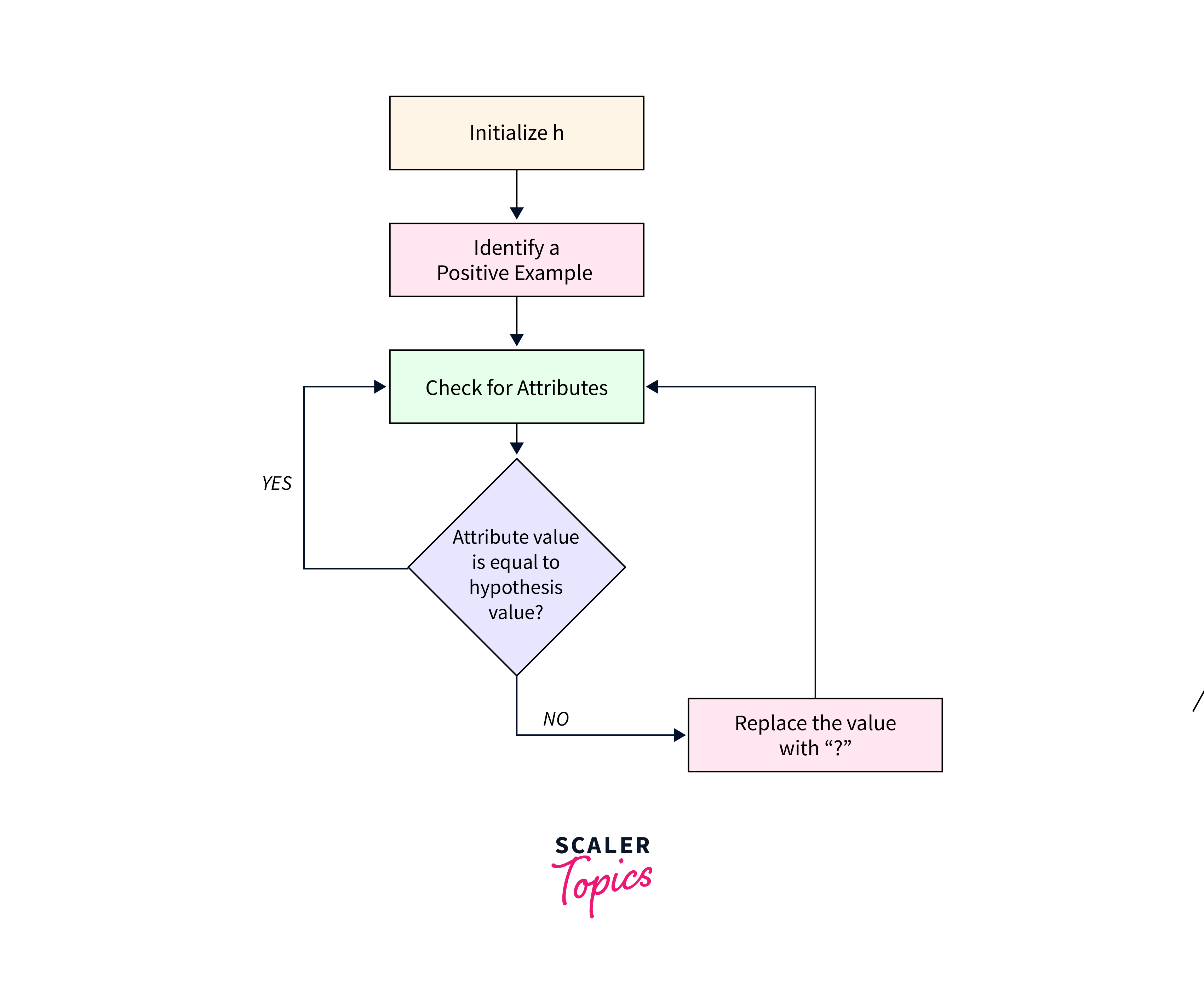
This algorithm embodies the iterative process of refining hypotheses based on positive training instances.
Implementation of Find S Algorithm
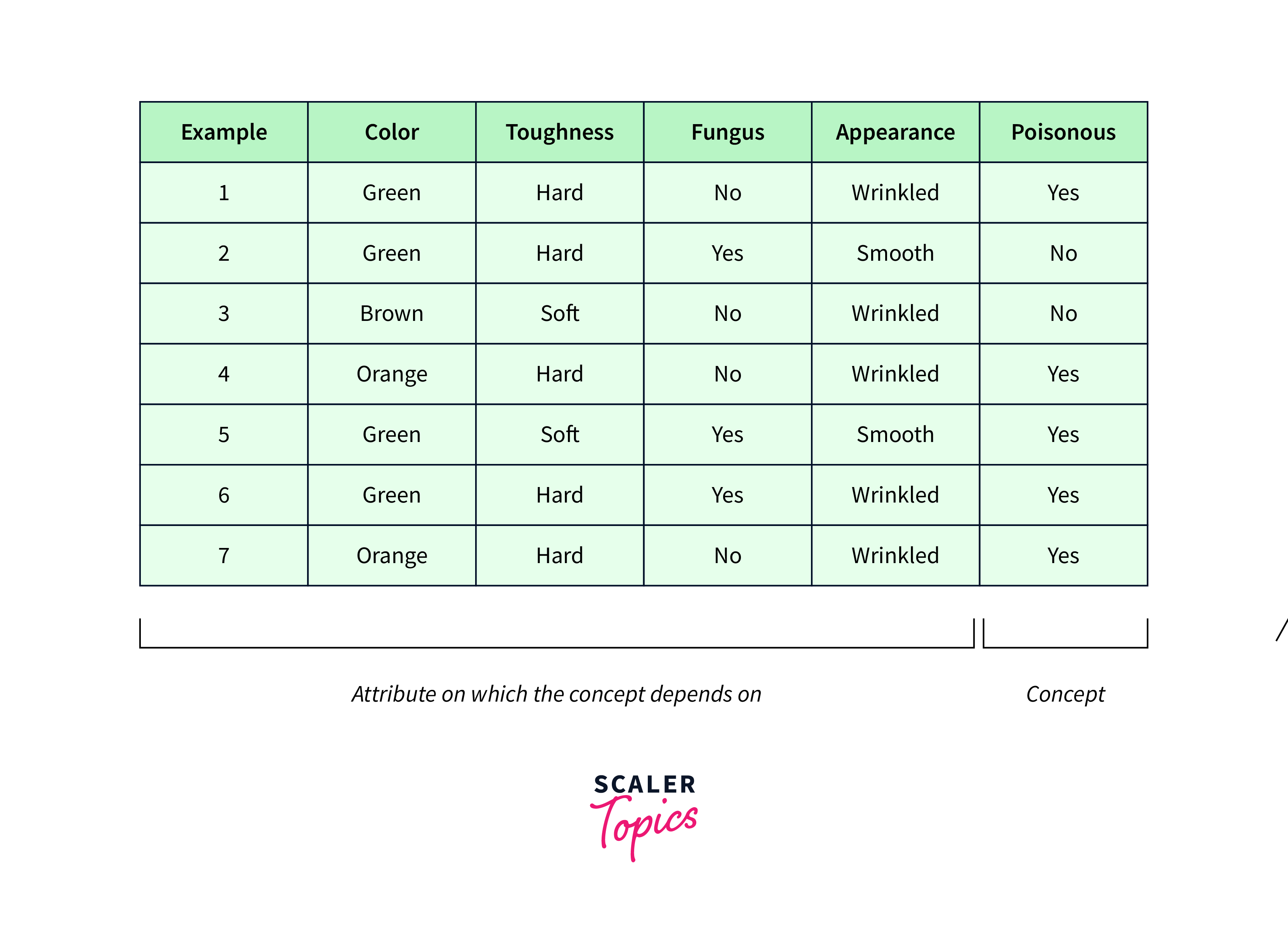
In the above implementation, the data variable represents a training dataset for a simple classification problem. Each row in the dataset represents an example, and the last column represents the class label indicating whether the example belongs to the class 'Yes' or 'No'.
Here's a breakdown of what each column represents:
- Outlook:
Weather condition (e.g., Sunny, Rainy) - Temperature:
Temperature (e.g., Warm, Cold) - Humidity:
Humidity level (e.g., High, Normal) - Wind:
Wind condition (e.g., Strong, Weak) - PlayTennis:
Class label indicating whether to play tennis or not (e.g., Yes, No)
For example, the first row [Sunny, Warm, Normal, Strong, Warm, Same, Yes] means:
- Outlook is Sunny
- Temperature is Warm
- Humidity is Normal
- Wind is Strong
- The wind is Warm
- The condition of the weather doesn't change
- The decision is to play tennis (Yes)
Similarly, each subsequent row represents another example with the same attributes and a corresponding class label indicating whether to play tennis or not.
Step-by-step explanation -
Step 1:
Initialize hypothesis to the most specific hypothesis:
hypothesis = ['0', '0', '0', '0', '0', '0']
Step 2:
Iterate over positive examples and update the hypothesis:
Example 1:
['Sunny', 'Warm', 'Normal', 'Strong', 'Warm', 'Same', 'Yes']
Update hypothesis: ['Sunny', 'Warm', 'Normal', 'Strong', 'Warm', 'Same']
Example 2:
['Sunny', 'Warm', 'High', 'Strong', 'Warm', 'Same', 'Yes']
Update hypothesis: ['Sunny', 'Warm', '?', 'Strong', 'Warm', 'Same']
Example 3:
['Sunny', 'Warm', 'High', 'Strong', 'Cool', 'Change', 'Yes']
Update hypothesis: ['Sunny', 'Warm', '?', 'Strong', '?', '?']
Final hypothesis:
['Sunny', 'Warm', '?', 'Strong', '?', '?']
So, the final hypothesis derived by the Find-S algorithm for the given data would be ['Sunny', 'Warm', '?', 'Strong', '?', '?'], indicating that when the weather outlook is 'Sunny', and the temperature is 'Warm', with 'Strong' wind, the decision about playing tennis is uncertain ('?') for the remaining attributes.
FAQs
Q. What is the primary objective of the Find S Algorithm?
A. The Find S Algorithm aims to induce hypotheses from training data, particularly in the context of concept learning.
Q. How does the Find S Algorithm handle negative training examples?
A. Negative training examples do not affect the hypothesis in the Find S Algorithm.
Q. What representations are crucial within the Find S Algorithm?
A. Important representations include ?, specific attribute values, and ϕ (indicating no value).
Conclusion
- The Find S Algorithm is a foundational tool in machine learning, specifically designed for concept learning tasks.
- It operates by iteratively refining hypotheses based on provided training examples, facilitating the induction of accurate classifiers from data.
- Understanding the crucial representations, steps, and implementation of the Find S Algorithm is essential for mastering its usage in practical scenarios.
- Despite advancements in machine learning, the Find S Algorithm remains a timeless technique for hypothesis generation and concept learning.
- Practitioners can leverage the principles and methodologies outlined in this article to effectively tackle a wide array of machine learning problems.
- Whether it involves predicting outcomes based on weather conditions or classifying data in diverse domains, the Find S Algorithm stands as a reliable ally in knowledge extraction and pattern recognition.