Architecture of Data Warehouse - Five Pillars and Characteristics

Datawarehouse consists of five pillars or components which play an important role while architecting the data warehouse. With that being said, it becomes important to not only understand each of the five pillars of data warehouse architecture but also understand the characteristics of the data warehouse to utilize its elements to its best and help architect structure which helps the analyst derive insights.
The Five Pillars of Data Warehouse Architecture
With the data processing frameworks, a vast amount of data can be obtained from multiple data streams incredibly and this is powering the development of Big Data.
And with that being said, we need a data warehouse to solve our problem of analysis, management, and querying that needs to be done on all the data. The Data Warehouse is mostly based on the RDBMS server which can be defined as the central information repository which is surrounded by some major key Data Warehousing components to make the entire environment functional, manageable, and accessible.
Let us explore more about what data warehouses consist of by exploring below:
While building up the architecture of the data warehouse, we need to have the below structure of these four components in mind, to begin with. The major components that make up the Datawarehouse Architecture are :
- The Data Warehouse Database
- The Extraction, Transformation, and Loading Tools (ETL)
- The Data warehouse Bus Architecture
- The Metadata
- The Data Warehouse Access Tools
Below is the pictorial representation of the Components of Data Warehouse Architecture:
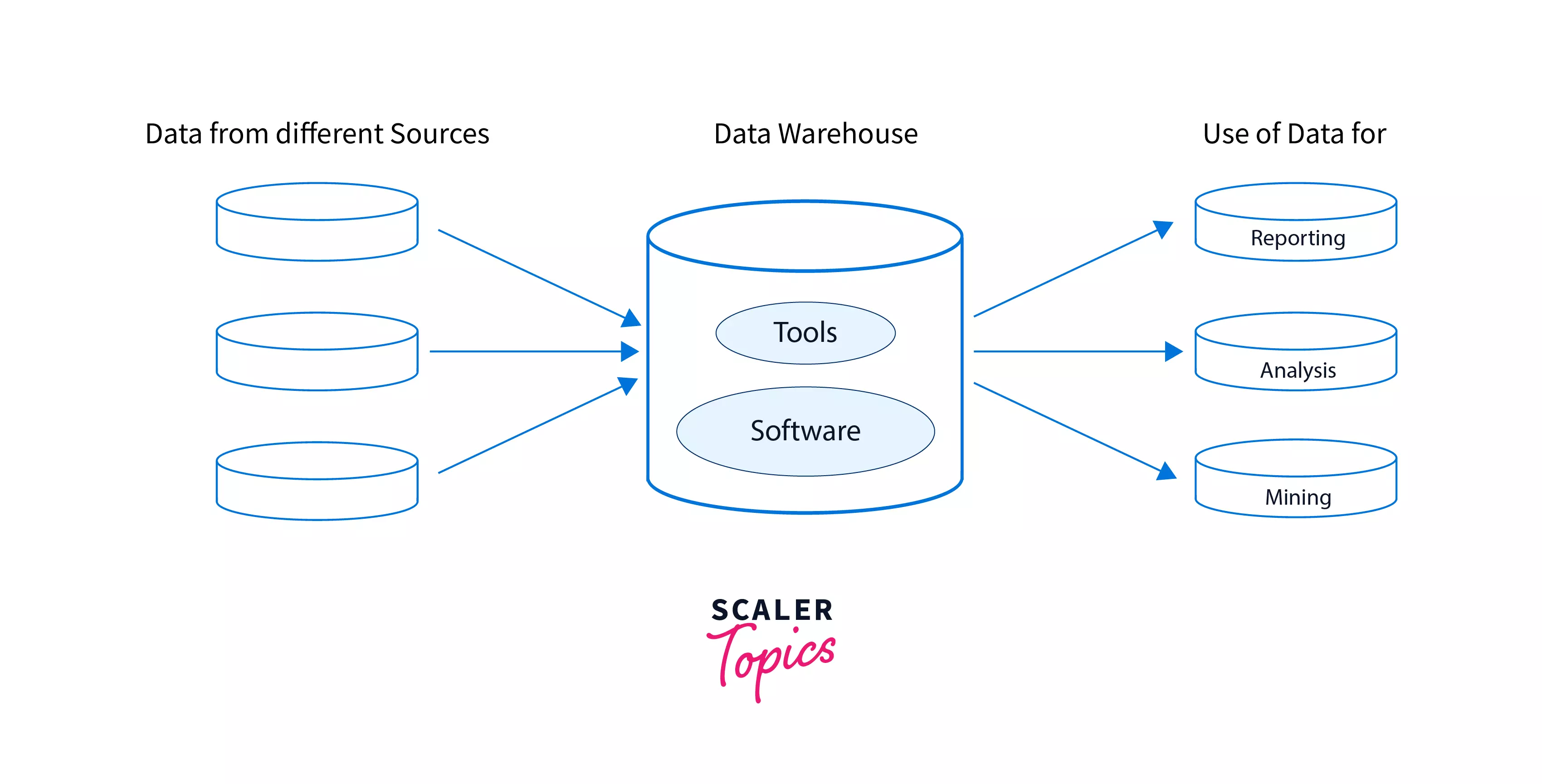
1. The Data Warehouse Database
The first crucial component in the architecture of the data warehouse is the database. This is where the data is stored and can be accessed when needed. It is also called the heart of the data warehousing environment.
While defining the data warehousing environment, we first need to know what kind of data needs to be collected. Below are the different types of databases that serve many purposes:
The Relational databases: This kind of database is a row-centered database.
The Analytics databases: This kind of database is needed when we are required to sustain the data and manage analytics.
The Data warehouse applications: This kind of database is used when we need the software for data management and the hardware is mostly used for storing data which is offered by third-party dealers.
The Cloud-based databases: This kind of database is hosted on the cloud and gives the ability to scale for the millions amount of data received.
Most databases are implemented by the RDBMS technology as the RDBMS technology system is optimized for transactional database processing but not for data warehousing which can include multi-table joins, aggregates, and other resource-intensive constraints bringing performance down.
Hence, these are mostly deployed in parallel to allow for scalability which also allows the shared memory or shared-nothing model on multiple multiprocessor configurations.
We also see the use of multidimensional databases (MDDBs) over the relational Data Warehouse Models as it overcomes the limitations that are placed by the RDBMS technology. Sometimes, the new index structures are also used to improve speed and bypass relational table scans.
Summing up, the database must be specifically chosen for the kind of data warehousing that is required by the organization.
2. The Extraction, Transformation, and Loading (ETL) Tools
Expanding the term ETL – this forms the second component in the Architecture of Data Warehouse. The ETL stands for the Extraction of data, the transformation of data, and the loading of data in the Data Warehouse.
ETL stands for Extract, Transform, and Load. The staging layer of the two-tier architecture of the data warehouse uses the ETL tools to extract the required data from various formats and then checks for the quality of the data before loading it into the data warehouse.
The data sourcing, Acquisition, Clean-up and transformation, and migration tools are widely used for performing all the changes that are needed to transform data (that can be conversions, summarizations, and all) into a unified format in the data warehouse.
The Extract-Transform-Loading tools of the data warehouse help in maintaining the Metadata while dealing with the challenges of Data heterogeneity and can also be used to generate cron jobs, background jobs, shell scripts, etc. that keep a check on regularly updating the data in the data warehouse.
The main functionality of the ETL tools includes:
- Eliminating unwanted data in operational databases from loading into the Data warehouse.
- Searching and replacing the common names and definitions for data arriving from multiple sources.
- Calculate the summaries and derived data
- Whenever there is a data miss, these can help in populating the data with defaults.
- The De-duplication of repeated data collected from different data sources.
3. The Data Warehouse Bus Architecture
The Data warehouse Bus Architecture helps to determine the flow of data in the warehouse information system. While designing a data bus in the data warehouse architecture, one must consider the shared dimensions and facts across data marts in the storage repository i.e. (data warehouse). The flow divergence of data in a data warehouse can be categorized as Inflow, Upflow, Downflow, Outflow, and Meta flow.
4. The Metadata Component
The first step toward data exploration is to ask a few questions such as
What tables, attributes, and keys does the Data Warehouse contain? Where did the data in the data warehouse come from? Do we reload data frequently or does it happen only once? What transformations are the majority applied with the cleansing of the data? .. and so on.
To answer all the above we make use of what is called the Metadata component or simply Metadata.
Once the information system cleans and organizes the data in the data warehouse, the data is then stored in the data warehouse. The architecture of the data warehouse represents the central repository of information that stores metadata, summary data, and raw data coming from various rich sources.
Let's consider an example as shown below which is from a sales database that says: 8830 TTu32 457.77
This data seems too vague until we consult the Meta that makes us understand that it was -
Model number: 8830 Unique Identifier: KJ732 Total sales amount of $457.77
Now it seems to make much more sense, isn’t it?
Therefore, Meta Data can be defined as data about data that defines the data warehouse which is used for building, maintaining, and managing the data warehouse and hence acts essential ingredient in the transformation of data into knowledge.
It is also said that metadata is equal to the data dictionary or the data catalog in a database management system like the logical data structures, the data about the records and addresses, the information about the indexes, and so on.
It directs about the sources, usage, values, and features of the data in the data warehouse. It also interprets how data can be changed and processed and hence holds the data closely connected to the data warehouse.
Mostly Metadata can be diversified into two broad categories as can be seen below:
The Business MetaData: This kind of Metadata contains information that tells the end-users an easy method to understand the information stored in the data warehouse.
The Technical MetaData: This kind of Metadata contains information mostly about the warehouse which is used by Data warehouse administrators and designers.
Summary data can be defined as the data which gets updated when the new data is loaded into the data warehouse which is mostly generated by the warehouse manager. This component in the architecture of the data warehouse can include lightly or highly summarized data whose major role is to speed up query performance and generate the output quickly.
Raw data on the other hand can be defined as the actual data which is loaded into the storage repository, in its raw format which can be structured, semi-structured, or unstructured. This raw data is simply the data that has not been processed yet. Having the data in its raw form makes it more accessible for generating insights after further processing and analysis.
Summing up, Metadata can be considered as the information that defines the data whose primary role is to simplify working with the data instances and allow the data analysts to classify, locate, and direct queries on the needed data.
The Data Marts
The data mart in the data warehouse can be considered as the same database or a physically separate Database as the Datawarehouse. It can also be defined as an access layer that is used to get data out to the users.
Most of the time when within the company different categories of information need to be done by departments then we can use the data mart for the partition of data that can be created for the specific group of users.
In simple words, a Datamart can be considered a subsidiary of a data warehouse and is one of the important components in the architecture of a database.
The Data marts allow us to have different groups within the system by segmenting the data from the data warehouse into categories. The Data marts are the shorter form of the data warehouses contained in the enterprises.
Seeing the current trends in data warehousing, it's well evident that the development of data marts within the data warehouse can be considered for performing particular kinds of queries and reports. To date, it is presented as an option for the large-size data warehouse as it usually takes less time and money to build a data mart.
Many times the data mart can also be defined as a subset of enterprise-wide data that is of value to a specific group of users whose scope is confined to selected subjects and hence, there is no standard definition of a data mart is differing from a person to person.
Recently, we have seen that development in the data warehouse industry has made incremental and standard data dumps more achievable.
5. The Query Tools
We have so far known about the four major components of the data warehouse architecture without which the database would have no meaning altogether.
Now let us move on to the fifth component which is Query tools. It is the Query tools that allow users to interact with the data warehouse system and which can in return provide information to businesses to make strategic decisions.
These Query tools can be categorized into four parts:
- The OLAP tools
- The Query and Reporting tools
- The Data mining tools
- The Application Development tools
The OLAP Tools
The OLAP tool or the Online analytical processing tools are based on concepts of a multidimensional database which allows its users to analyze the data using elaborate and complex multidimensional views. It helps its users get multiple perspectives at the time of analytical processing of the data.
The OLAP tool reorganizes the data into the multidimensional format by getting the data from numerous relational data sets present which in turn helps the users in fast processing and valuable analysis.
This tool is also leveraged by the users to gather information for analyzing the data, gather insights, and create reports through the use of different tools and technologies.
The Query and reporting tools
The Query and Reporting tools are used in two broad perspectives as can be observed below:
- The Reporting tools
- The Managed query tools
The Reporting tools:
The Reporting tools play a crucial role in understanding how the business is performing and what next needs to be done to gain insights that can be leveraged by the enterprise to upskill its functionality multi-folds.
The reporting tools help us visualize how data changes over time through visualizations methods such as graphs and charts.
We can be further sub-divided The reporting tools into 2 broad categories: Desktop report writer and Production reporting tools as follows:
Desktop Report writers: The desktop Report writers reporting tool are majorly used for analysis by the end-users during the reports generation for gaining insights.
Production reporting tools: The Production reporting tools are majorly used for supporting high volume batch jobs like printing and calculating which allows enterprises in generating regular operational reports for gaining insights.
Some popular examples of this kind of reporting tool are Brio, Business Objects, Oracle, Power-Soft, and SAS Institute.
The Managed query tools:
The Managed query tools play a crucial role to access tools that can help resolve snags in database and SQL by end-users. It can also be used for inserting meta-layer between users and database in the database structure.
The Data mining tools
To understand the data mining tools we need to first understand What data mining is?
Data mining as a process can be understood as the process of mining a large amount of data which leads to discovering meaningful new correlations, patterns, and trends.
With that being said, the Data mining tools play an important role by making the data mining process automatic which will help in examining the data sets to find out patterns that can help us in knowing the correlation within the warehouse.
The major task that the data mining tools solve for us is helping out with establishing the relationships when analyzing multidimensional data.
The Application development tools
The application development tools can be considered as the tools which solve the limitation which is often observed by the built-in graphical and analytical tools which a lot of times do not satisfy the analytical needs of an organization and to overcome, such cases, we make use of custom reports which are developed using Application development tools.
The Characteristics of Data warehouse Architecture
When we design the architecture of a data warehouse there needs to be certain characteristics that need to be kept in mind which can help design in a way that can be more flexible towards sustaining the changes as it comes along the way:
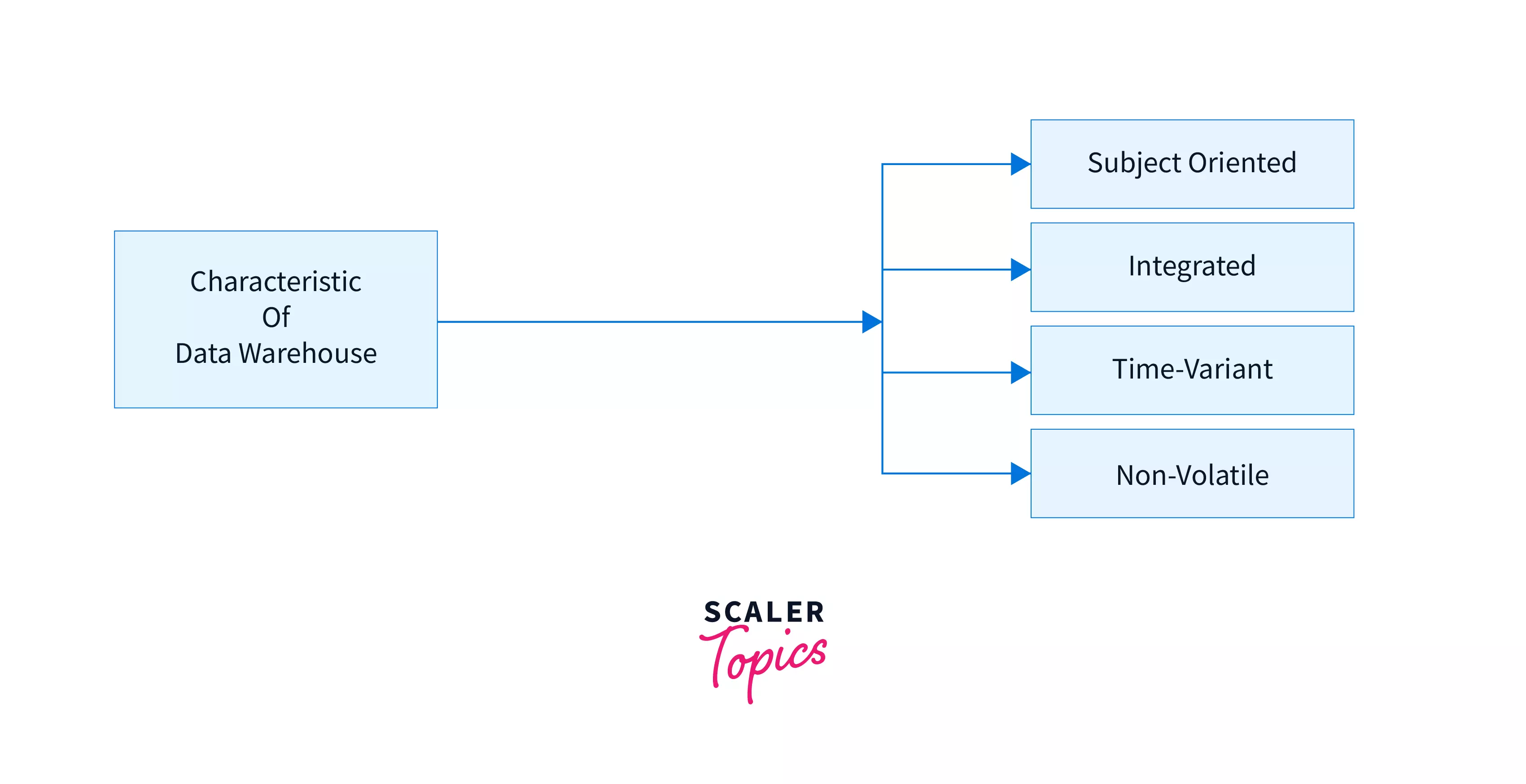
The following characteristics of the Data Warehouse Concepts can be seen below:
- Time-variant
- Integrated
- Non-volatile
- Subject-Oriented
1. Time-Variant:
The characteristics which need to be analyzed while designing the architecture of the data warehouse are time-variant. When we talk about time-variant it means here the data is maintained through different intervals of time such as weekly, monthly, or annually, etc.
The time horizon for a data warehouse can be quite extensive compared with the traditional operational systems therefore, The data collected in a storage repository can be recognized within a particular period and offers information from the historical point of view if calculated.
The time-variant founds various time limits which need to be structured between the large datasets and is mostly held in the online transaction process (OLTP).
We can know that the time limits for a data warehouse are wider-ranged than that of the operational systems And this leads to the data which resides in the data warehouse being quite predictable with a specific interval of time. It comprises elements of time explicitly or implicitly.
For example, Every primary key contained with the DW should have either implicitly or explicitly an element of time. Like the day, week month, etc which is mostly seen in Datawarehouse where data display the time variance is in in the structure of the record key.
The point which needs to note here is once data is inserted in the warehouse, it can’t be updated, changed, modified, or altered which makes the time variance a unique characteristic
2. Integrated
To understand the next character in the architecture of the data warehouse let us consider an example:
There are three different applications labeled S, T, B, and A. Now let's suppose the information stored in these applications is Fruits, Vegetables, ID, and Month. We know that the data stored in each application is different as can be seen below:
In Application S, the Fruits field stores character values like Orange, Apple, Watermelon.
In Application T, the vegetable field stores logical values like C for carrot, P for potato, O for onion.
In Application B, the application-ID field is stored in the form of a numerical value like 1, 8, 9, and so on.
In Application A, the Month field is stored in the form of a logical value like J, F, M, A, M, and so on.
As can be seen from the above figure and example we see that all the applications have data in different formats like logical, character, and numerical but after this, the data goes into transformation and cleaning process all this data is stored in a common format in the Data Warehouse.
The integration as a character can also be defined as the establishment of a common unit of the measure for all similar data from the dissimilar database that is the data must keep consistent naming conventions, format, and coding.
When the data is stored in the Datawarehouse it needs to be in a common and universally acceptable manner. It is observed that by integrating data from varied sources like a mainframe, relational databases, flat files, etc. when it is transformed and cleansed then only it needs to be loaded in the data warehouse which makes it easier for the analytics team to understand the data better.
The benefits integration of data warehouse has are effective analysis of data, reliable naming conventions, format, and codes., shared entity to scale the all similar data from the different databases, Reliability in naming conventions, column scaling, encoding structure, etc.
3. Non-volatile
The characteristics which need to be analyzed while designing the architecture of the data warehouse are Non-volatility. The property of non-volatility means that the data which is stored in the data warehouse cannot be erased when new data is entered into it.
The data remains read-only and periodically refreshed which helps to analyze historical data and understand what & when happened. This characteristic of the data warehouse does not require transaction process, recapture, and concurrency control mechanisms which makes it more beneficial in analyzing historical data and incomprehension of the functionality.
It is often observed that functionalities linked to data such as delete, update, and insert which are performed in an operational application are lost in a data warehouse environment. But with the data that resides in a data warehouse, remains permanent.
That means that data is not erased or deleted when new data is inserted which includes the mammoth quantity of data that is inserted into modification between the selected quantity on logical business advice. This helps in the evaluation of the analysis within the technologies of the warehouse.
There are two types of data operations done in the data warehouse are:
Data Loading: data is loaded after cleaning and transforming.
Data Access: the transformed data can be accessed by the analyst to gain insights.
4. Subject-Oriented
The characteristic which needs to be analyzed while designing the architecture of the data warehouse is Subject-orientation. By Subject orientation, we mean that a data warehouse can deliver information about a theme instead of the organization’s current operations that is it can be achieved on specific themes like sales, distributions, marketing, etc.
Subject Orientation can also be defined as the process in data warehousing which is capable of handling a specific theme that is more defined and not focused on any ongoing operations. Instead, it can emphasize the modeling/demonstrating and the analysis which is performed on the data for decision making. This also provides a simple and concise view of the specific subject by excluding data that does not help to support the decision-making process.
Below is the pictorial representation of The Characteristics of the Data Warehouse that must be followed to design the architecture of data warehouse:
Conclusion
-
While designing the architecture of the data warehouse, one needs to know the basics of the data warehouse and its components.
-
The architecture of data warehouse has 5 components: Data Warehouse Database, Extraction, Transformation, and Loading Tools (ETL), Data warehouse Bus Architecture, Metadata, Data Warehouse Access Tools
-
The characteristics of Data Warehouse Architectures that need to be catered to while designing the architecture of the data warehouse are Time-variant, Integrated, Non-volatile, and Subject-Oriented.
-
It's important to always be aware of the Property and the Characteristics that need to be recollected while designing the architecture of the data warehouse.