Git Sparse Checkout
Overview
The git sparse checkout command is one of the most important commands used in developing a larger code base and helps us manage and retrieve important files faster. This command helps use to populate the current working directory with the necessary content of the project by discarding the unnecessary files so that the modifications can be made faster to the desired files. We must know that although this command helps us to get the desired files from the whole bunch of files but it does not alter or hamper the size of the actual code base.
Pre-requisites
The prerequisites for learning the git sparse checkout command can be a basic understanding of Version Control Systems, Branching, and Git. Before learning about the git sparse checkout command, let us discuss them briefly.
A version control system is a tool in software development that tracks the changes in the code, documents, and other important information regarding a certain code base (or project), etc. Git is a version control system that tracks the changes in the code, documents, and other important information regarding a certain code base (or project), etc. Git is free and one of the most widely used version control systems. GitHub is a cloud-based central repository that can be used to host our code for team collaboration. It is a hosting service that is used to manage the git repository in the central server. GitHub is a free (for certain limits) and easy-to-use platform that enables teammates to work together on projects.
Introduction to Git Sparse Checkout
To understand the git sparse checkout command and its working, let us first take a scenario that will help us to understand the need for this command.
Suppose that you are a maintainer of numerous projects. You are maintaining various projects and for maintaining the projects, you use Git on your local system. Now due to these many projects, your local system has a very large directory which makes it very hard to focus on the primary section of each project where the development is generally made. Every time there is a change, you need to go to a certain directory or file by covering the entire web of directories and paths. So, what will you do in such scenarios? You will save the path of the desired changing location so that you can easily refer to those bunch of files. This is exactly what the git sparse checkout command helps us to achieve in Git world (on our local system) so that we can get the desired set of files faster.
The git sparse checkout command is one of the most important commands that is used in the development of larger code base and helps us to manage and retrieve important files faster. The git sparse checkout helps use to populate the current working directory with the necessary content of the project by discarding the unnecessary files so that the modifications can be made faster to the desired files.
We must know that although this command helps us to get the desired files from the whole bunch of files the git sparse checkout command does not alter or hamper the size of the actual code base. The actual size of the code base remains the same. Hence, there is no impact on the size of the directory before and after applying the git sparse checkout command.
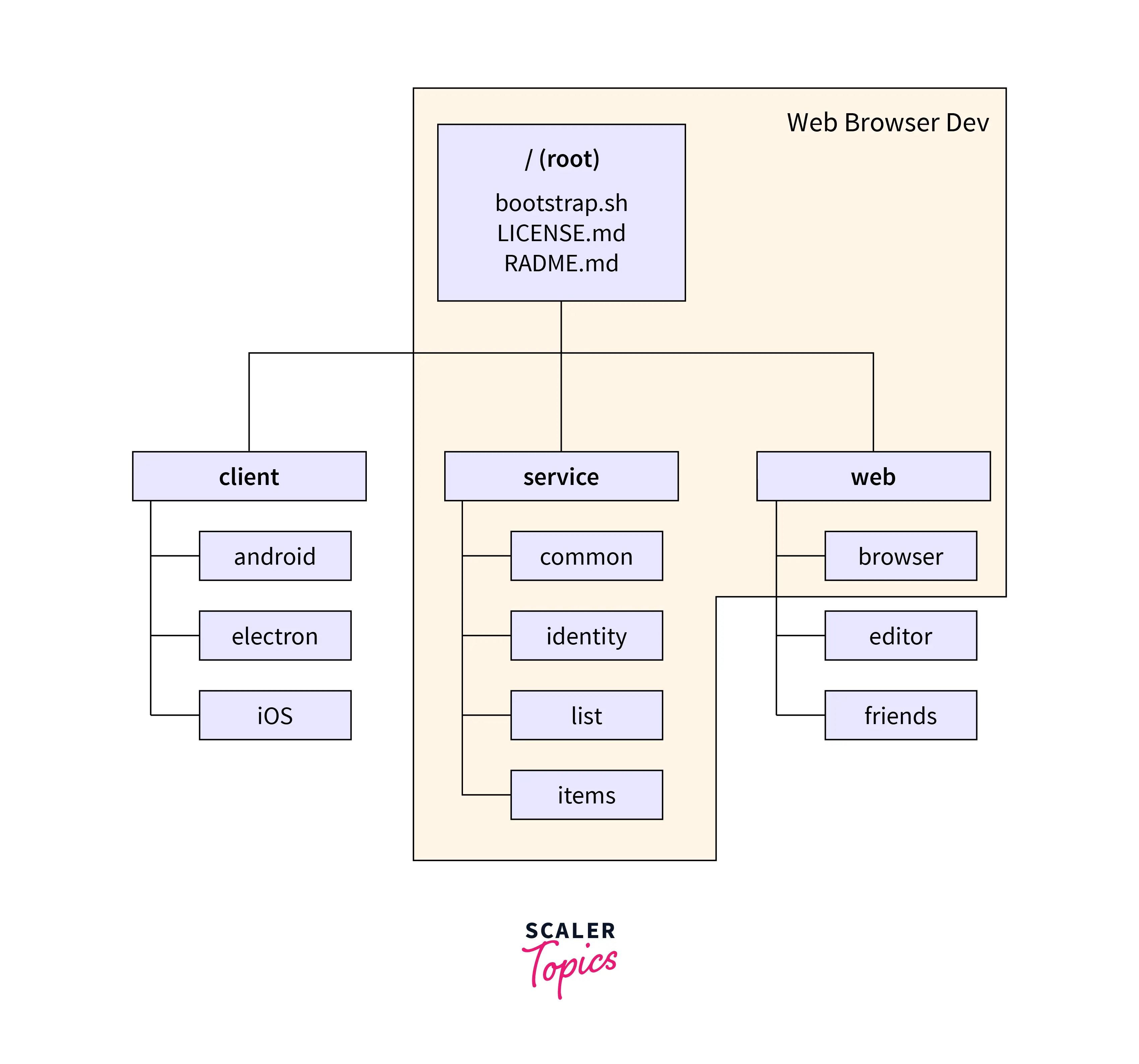
In the above image, we can see that we have only added the desired diretory and files (shown in green color) so that the output can be viewed more rapidly.
The syntax of the git sparse checkout is pretty simple, we just need to provide the git sparse checkout along with the subcommand and the options. We will be learning more about the subcommands and options in the later section. The overall command for the same is:
In the above command, the subcommand and the options help us to strengthen the command and provide some extensive support to the simple command. Some of the various features that are provided by the subcommand and the options are as follows:
- Helps us to initialize the git sparse checkout file.
- Helps us to write some kind of pattern to the git sparse checkout initialization file.
- Helps us to list down all the sparse directories involved, etc.
How does Git Sparse Checkout Work?
So far we have discussed about the git sparse checkout in detail. Let us now learn how the git sparse checkout actually works.
Well, the git sparse checkout command uses a skip-work tree to reference the files and this skip-work tree is defined and stored in a file stored at: $GIT_DIR/info/sparse-checkout. Now a question that comes to our mind is what is this skip-work tree reference and how it is associated with the git sparse checkout command. Well, the skip-work tree is somewhat similar to the git config files and helps us to store the local shared files metadata that will be used by the git sparse checkout command.
There are generally two steps to make the git sparse checkout command work more efficiently.
- Whenever we update the working directory, the skip-work tree bits are also updated in or saved file.
- Once the mapping is made into the $GIT_DIR/info/sparse-checkout file so whenever we make any request to a certain file, the matching file is returned faster and hence other files are not stored.
Commands
Let us now look at the various associated commands of the git sparse checkout.
- list: The list command is used to describe the entire pattern present in the sparse-checkout file.
- init: The init command is used to enable core.sparseCheckout setting. If there is no sparse-checkout file present in our directory then the command populates the pattern with every matching file present in the root directory and no other directories.
- This command is also used to add any pattern to the sparse-checkout file so that it can repopulate the working directory file.
- There may be situations in which the current work tree can interfere with the other working tree then this command helps us to avoid this by enabling the setting extensions.worktreeConfig and setting the core.sparseCheckout setting in the configuration file of the work tree.
- set: The set command is used to write some set of patterns to our sparse-checkout configuration file. The patterns are provided as a list of arguments. The list of arguments is provided after the set command.
- This command is also used to update the working directory and helps to match it with the new pattern.
- If the core.sparseCheckout configuration is not set then the set command also sets this configuration.
- disable: The disable command is used to disable the configuration setting - core.sparseCheckout. It also restores the entire working directory and includes all the files. The disable command also leaves the current sparse-checkout file the same so that if we perform a git sparse-checkout init in the future the command can return the working directory in the same saved state.
Sparse Checkout
The sparse checkout command helps us to populate the working directory in a sparse format. As we have previously discussed that the command uses a skip-working tree to detect whether a certain file is added in the most frequently asked files or not. So, it helps us to detect and fetch the desired file(s) faster.
Once the skip-work tree bit is set then the rest of the files are ignored so that the retrieval is faster for the desired files. This feature is very helpful if we are working on a very large project having only a few important files. One such example can be a project involving numerous node modules, as we know that node modules can be very very large so the directory of the entire project also becomes large, hence using the git sparse checkout command helps us to focus on the desired files only.
The git sparse checkout command uses a skip-work tree to reference the files and this skip-work tree is defined and stored in a file stored at: $GIT_DIR/info/sparse-checkout. The sparse feature is not initialized by default, so to initialize this feature, we need to run the command: git sparse-checkout init. This command will internally enable the configuration setting - core.sparseCheckout. After running this command, we can then set the patterns using the command: git sparse-checkout set. Finally, if we want to repopulate the entire working directory with all the files of the directory (as it was before running the git sparse checkout command) then we can use the command: git sparse-checkout disable.
Full Pattern Set
The patterns are set in the sparse-checkout file and this configuration is the same as the .gitignore file. By pattern, we mean the name of the files that need to be searched when the git sparse checkout command is executed. Now we can name also name the files that should not be included in the search. For example, we can remove all the unwanted files as:
Cone Pattern Set
The searching for an arbitrary pattern may be complicated and may need O(N*M) pattern matches for updating the index. Here N refers to the total number of patterns and M refers to the total number of paths in the index. Now, this complex performance issue can be solved by setting a more restricted pattern set enabling core.spareCheckoutCone in the config file.
We have two types of cone pattern sets namely recursive and parent. The recursive pattern set contains all the paths inside a directory that has to be included. The pattern contains all the files that are immediately inside the working included directory.
When we include the recursive pattern then the following pattern is added as a parent pattern:
Submodules
The git submodule command is used to initialize the submodules. If there are one or more than one submodules present in our repository then the submodules appear based on how we initialized them with the git submodule command. As we know that all the submodules and patterns are stored in the sparse-checkout configuration file so if we exclude any initialized submodule from the set of patterns then that submodule would still appear in our working directory.
Using git sparse checkout
Let us run and understand the git sparse checkout command with the help of an example. Suppose we have a directory named test and we want to include some files of the directory. Let us see the stepwise approach for the same.
Step 1: Initialize the git repository by using the command:
Step 2: Enable the sparse checkout configuration settings using the command:
Step 3: Include the directories that we want Git to include in the pattern. For example:
Step 4: Add the remote server (i.e. origin as the GitHub repository).
Step 5: Fetch the files from the remote server and start working on the project.
How to disable git sparse checkout?
As we have previously discussed that the disable command is used to disable the effect of the git sparse checkout command. The disable command is used to disable the configuration setting - core.sparseCheckout. It also restores the entire working directory and includes all the files. The disable command also leaves the current sparse-checkout file the same so that if we perform a git sparse-checkout init in the future the command can return the working directory in the same saved state. The overall command for the same is:
Conclusion
- Git is a version control system that tracks the changes in the code, documents, and other important information regarding a certain code base (or project), etc.
- The git sparse checkout command is one of the most important commands that is used in the development of a larger code base and helps us to manage and retrieve important files faster.
- We must know that although this command helps us to get the desired files from the whole bunch of files the git sparse checkout command does not alter or hamper the size of the actual code base.
- The git sparse checkout helps us to populate the current working directory with the necessary content of the project by discarding the unnecessary files so that the modifications can be made faster to the desired files.
- The actual size of the code base remains the same. Hence, there is no impact on the size of the directory before and after applying the git sparse checkout command.
- The subcommand and the options help us to strengthen the command and provide some extensive support to the simple command.
- The git sparse checkout command uses a skip-work tree to reference the files and this skip-work tree is defined and stored in a file stored at: $GIT_DIR/info/sparse-checkout.
- The skip-work tree is somewhat similar to the git config files and helps us to store the local shared files metadata that will be used by the git sparse checkout command.
- The list command is used to describe the entire pattern present in the sparse-checkout file.
- The init command is used to enable core.sparseCheckout setting. If there is no sparse-checkout file present in our directory then the command populates the pattern with every matching file present in the root directory and no other directories.
- The set command is used to write some set of patterns to our sparse-checkout configuration file. The patterns are provided as a list of arguments.
- If we want to repopulate the entire working directory with all the files of the directory (as it was before running the git sparse checkout command) then we can use the command: git sparse-checkout disable.