Google Cloud Big Data
Overview
Google Cloud Big Data is a collection of Google Cloud-based services for managing and analysing large-scale datasets. It offers a scalable, adaptable, and cost-effective solution for data storage, processing, and analysis. Google Cloud Big Data's primary components include BigQuery, Dataproc, Dataflow, and Pub/Sub. BigQuery is a serverless data warehouse that allows users to run SQL-like queries to store and analyse large-scale datasets. Dataproc is a managed Spark and Hadoop service that uses open-source technology to process large-scale datasets. Dataflow is a fully managed service that allows customers to extract, manipulate, and load data at scale.
What is Google Cloud Big Data?
Google Cloud Big Data is a set of Google Cloud Platform (GCP) services for processing, analysing, and storing massive and complex data sets.Google Big Data contains a set of tools and services that allow users to manage and handle large amounts of data in a scalable, dependable, and cost-effective manner.
Google Cloud Big Data includes the following main components:
- Google BigQuery: A fully managed, cloud-based data warehouse that allows customers to utilise SQL to store, query, and analyse massive datasets.
- Google Cloud Dataflow is a managed service that uses Apache Beam to handle and analyse streaming and batch data.
- Google Cloud Dataproc is a fully managed solution that allows you to run Apache Hadoop and Apache Spark clusters on GCP.
- Google Cloud Pub/Sub: A messaging service that allows apps to exchange data in real time.
- Google Cloud Storage is a scalable, long-lasting, and secure object storage service that lets users store and retrieve massive volumes of unstructured data.
These services are intended to function together to provide a comprehensive end-to-end solution for Google Big Data processing and analysis in the cloud.
Google Big Data Services
Users may manage, process, and analyse huge and complicated data sets with the help of Google Big Data Services, a collection of tools and services made available by Google Cloud Platform. These services are made to manage Big Data workloads in a scalable, reliable, and economical manner.
With Google Big Data Services, users can concentrate on insights rather than infrastructure since they receive a complete end-to-end solution for Big Data processing and analysis in the cloud.
Google Cloud BigQuery

Being a component of Google Cloud Platform (GCP), Google BigQuery is a Cloud Data Warehouse that is simple to link with other Google products and services.
A collection of several Google services, including Google Cloud Storage, Google Bigtable, Google Drive, databases, and other data processing tools, make up Google Cloud Platform. All of the data kept in these Google products can be processed by Google BigQuery.
To construct and run Machine Learning models, Google BigQuery employs ordinary SQL queries. It also integrates with other business intelligence tools like Looker and Tableau.
In Google Big Data, Google BigQuery architecture enables SQL queries and is ANSI SQL 2011 compatible. As part of the data model, BigQuery SQL support has been enhanced to provide nested and repeated field types.
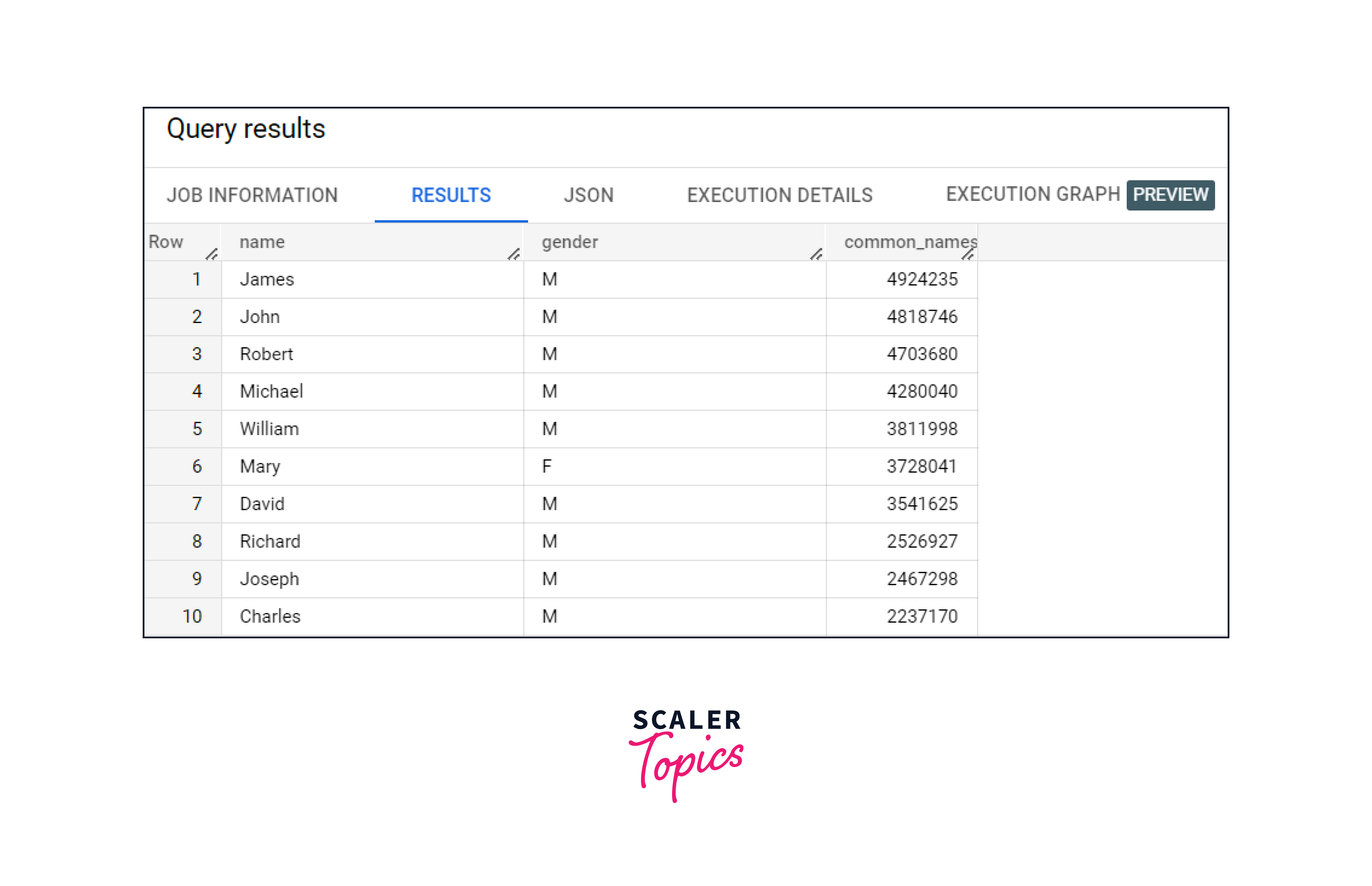
For example, we can query the USA Names public dataset to determine the most common names in the United States between 1910 and 2013 in the editor:
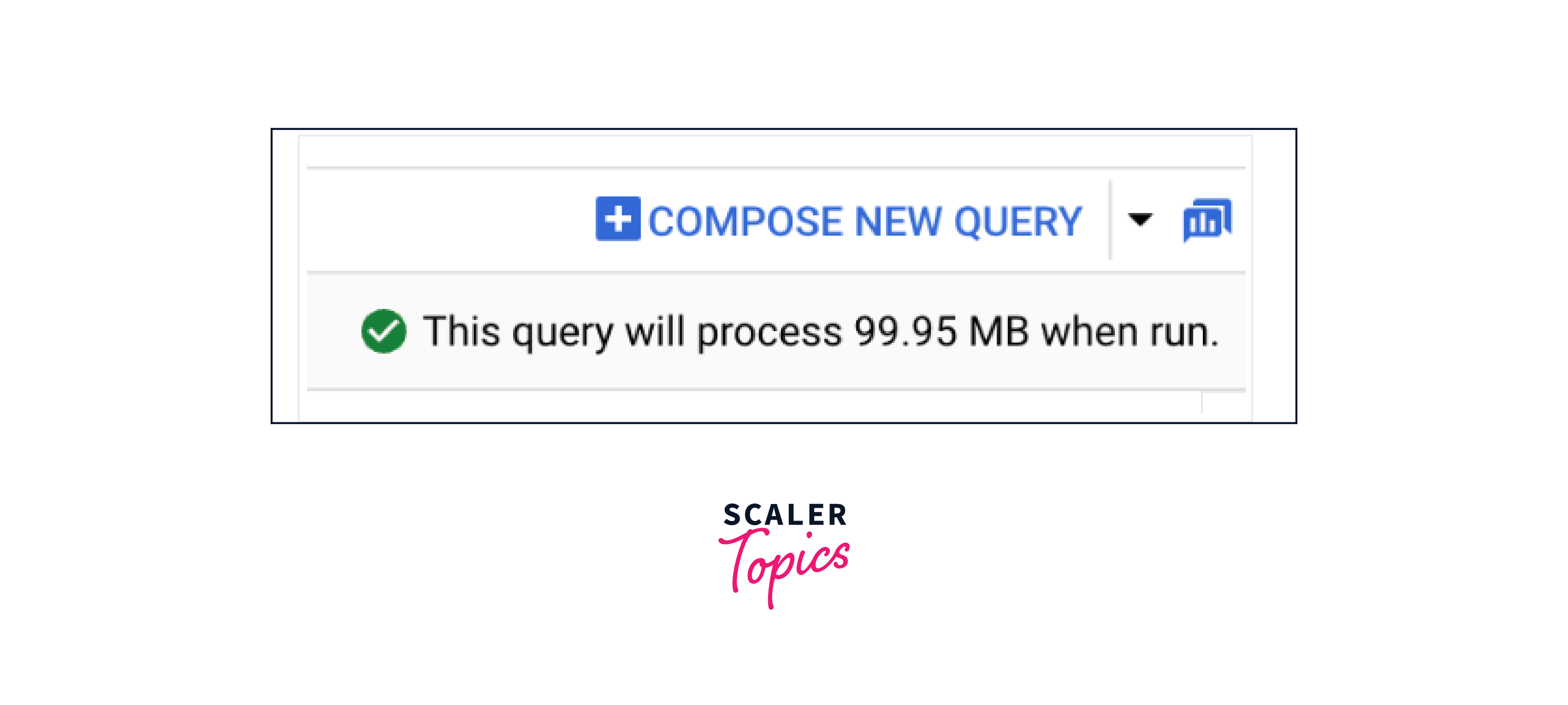
If the query is correct, a green check mark displays alongside the amount of data processed by the query. If the query is incorrect, a red exclamation mark and an error message appears.
If there is an error in the SQL syntax, BigQuery will pop a red exclamation mark ! on the query stating where the error is.

Google Cloud Dataflow
In Google Big Data, Google Cloud Dataflow is a fully managed service that uses Apache Beam, a unified programming model for data processing pipelines, to process and analyse both batch and streaming data. It offers a serverless framework for developing data processing pipelines that can handle enormous amounts of data.

Users of Google Cloud Dataflow may create and execute data processing pipelines in Java or Python, then deploy them to the cloud platform. The service manages and scales resources automatically, ensuring that users only pay for what they need.

It is an easier substitute for batch ETL (Execute-Transform-Load) by targeting stream analytics solutions to maximize the value from user-interaction events, app events, and machine logs. It can consume millions of streaming events from all around the world every second. GCP's stream analytics simplifies ETL procedures without sacrificing reliability, accuracy, or functionality.
Google Cloud Dataproc
Google Big Data's take on the Hadoop environment is called Google Cloud Dataproc. It comprises the MapReduce processing architecture and Hadoop Distributed File System (HDFS). Numerous Hadoop-based apps including Hive, Mahout, Pig, Spark, and Hue are also part of the Google Cloud Dataproc system.

- Dataproc separates storage and computation. Imagine you receive logs from an external app that you wish to analyze, so you store them in a data source.
- The data is taken from Cloud Storage (GCS) and processed by Dataproc before being returned to GCS, BigQuery, or Bigtable. Additionally, you may submit logs to Cloud Monitoring and Logging and use the data for analysis in a notebook.
- A long-lived cluster may have one cluster for each job because storage is different, but to reduce costs, you could utilise ephemeral clusters that are aggregated and picked by labels. Finally, you may utilise the appropriate combination of RAM, CPU, and disk space depending on the demands of your application.
Google Cloud Pub/Sub
In Google Big Data, asynchronous and scalable messaging service Pub/Sub separates services that produce messages from those that process them. Services can interact asynchronously via Pub/Sub, with latencies of about 100 milliseconds.
Data integration pipelines and streaming analytics employ Pub/Sub to ingest and deliver data. It works as a queue to parallelize jobs as well as a messaging-oriented middleware for service interaction.

Some terminologies in Pub/Sub include the following :
- Pub/Sub is a publish/subscribe service and a messaging platform that separates message senders and recipients.
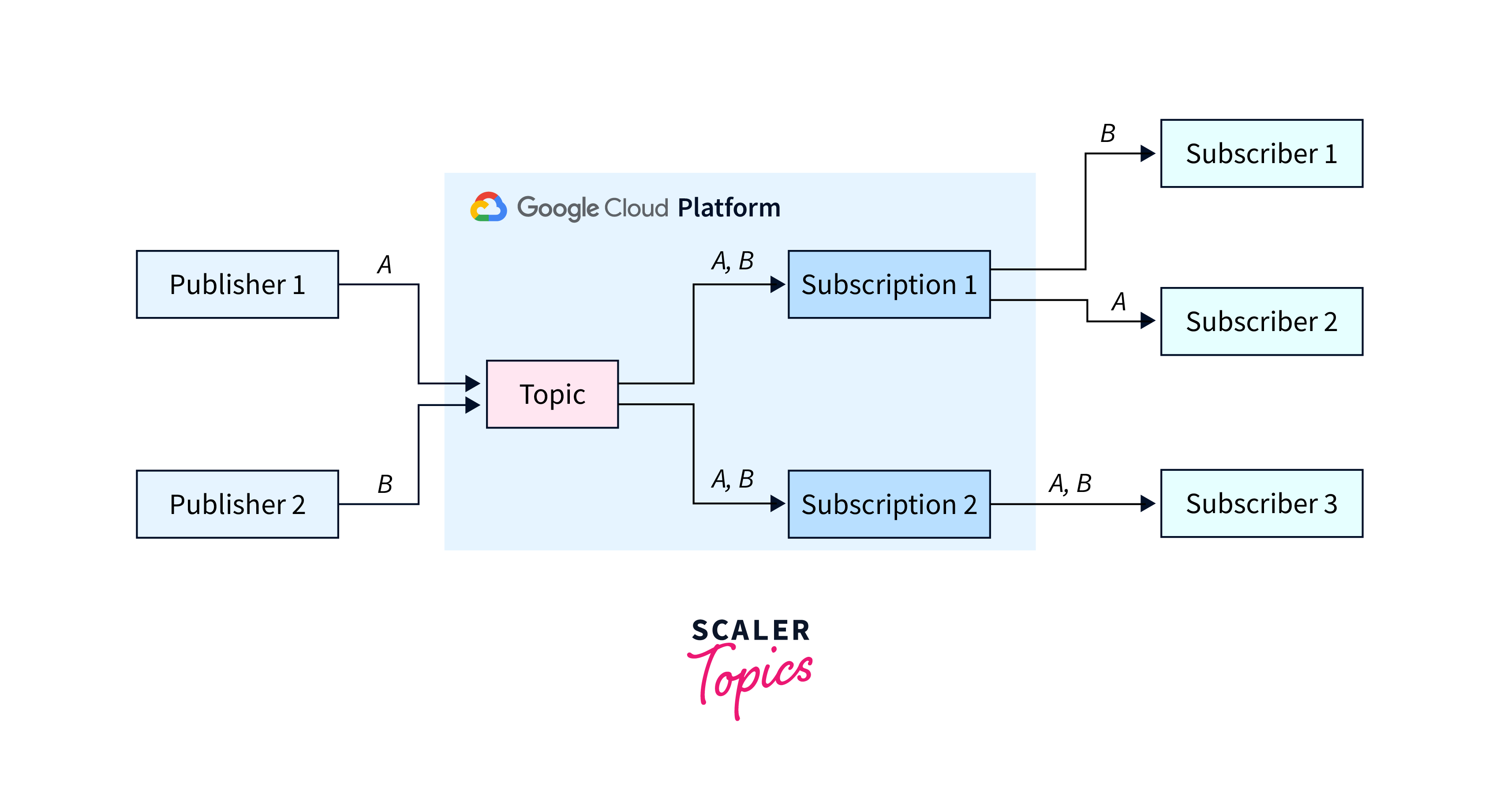
- Data passing through the service is the message.
- Topic is a named object that denotes a message stream.
- A named object known as a subscription denotes a desire to receive messages on a specific topic.
- A publisher (also known as a producer) is an entity which writes messages and publishes them to a messaging service on a particular subject.
- The entity which receives messages on a certain topic is a subscriber (also known as a consumer).
Google Cloud Composer
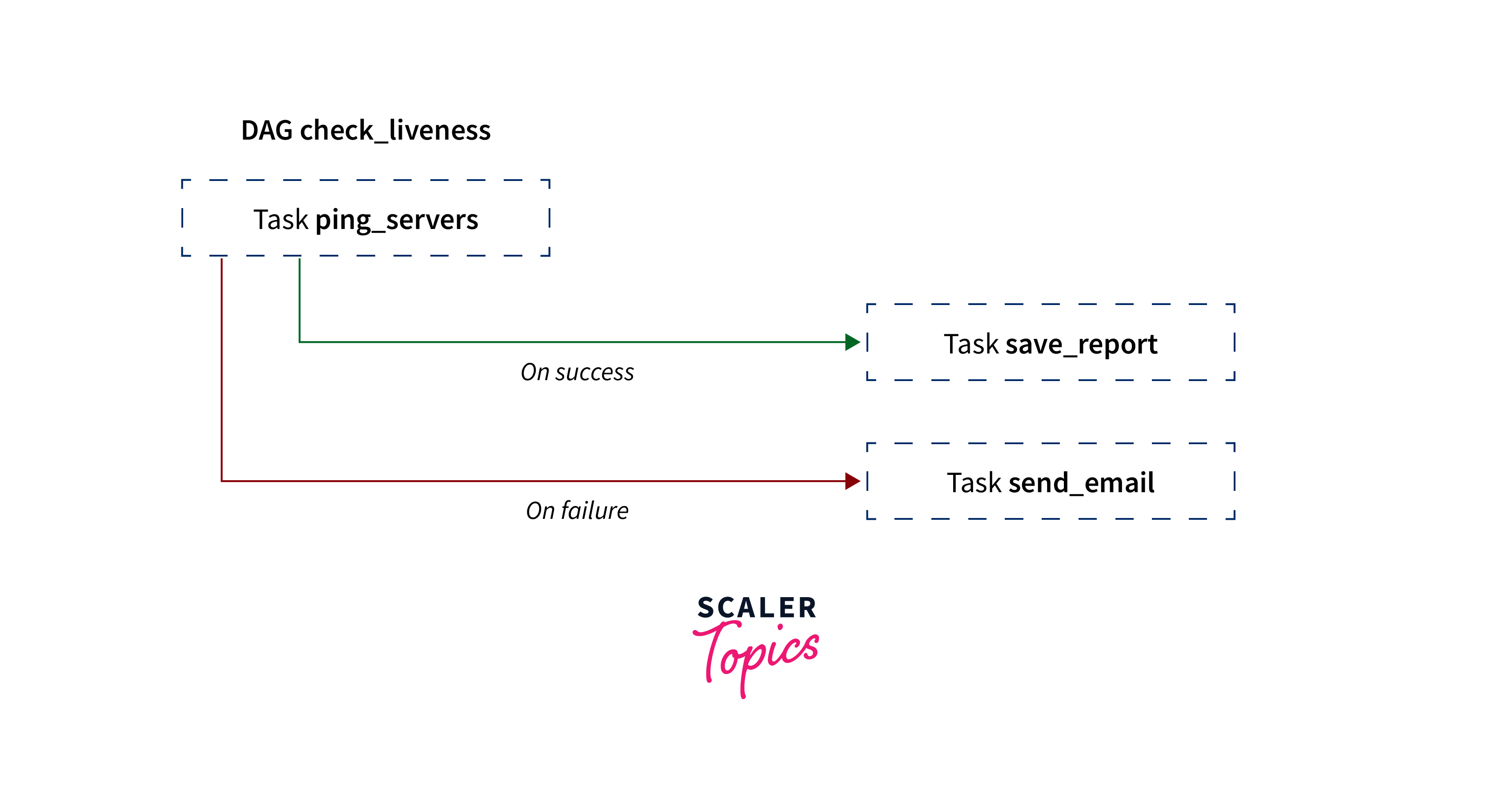
A fully managed workflow orchestration service, Google Cloud Composer is based on Apache Airflow, an open-source workflow creation, scheduling, and monitoring tool. Using a straightforward, user-friendly interface, users can easily construct, manage, and plan complicated data pipelines with the help of Directed Acyclic Graphs or DAGs.

A DAG is a group of actions that you wish to plan and carry out, arranged to indicate their connections and dependencies. Python scripts are used to generate DAGs, and these scripts use code to specify the DAG structure (tasks and their dependencies).
Almost anything may be represented by a task in a DAG; for instance, a task could carry out any of the following tasks:
- Getting data ready for consumption
- Tracking an API
- Composing an email
- Developing a pipeline
The service makes it simple to combine data from many sources by offering a variety of pre-built connections to well-known data sources and sinks, including BigQuery, Cloud Storage, and Cloud SQL.
Google Cloud Data Fusion
A completely managed cloud solution for creating and overseeing data integration pipelines is Google Cloud Data Fusion. Users with a variety of technical backgrounds may easily develop and manage data pipelines, thanks to the tool's visual interface for designing, deploying, and monitoring pipelines.
A drag-and-drop interface for creating pipelines, integrated monitoring and alerting, and connectivity with other Google Cloud services like Cloud Logging and Cloud Monitoring are just a few of the features that Cloud Data Fusion provides to make the design and maintenance of pipelines easier.

A tenancy unit is where a Cloud Data Fusion instance is deployed. It offers the ability to create and manage data pipelines as well as centralised metadata management. It utilises Cloud Storage, Cloud SQL, Persistent Disk, Elasticsearch, and Cloud KMS for storing business, technical, and operational metadata and operates on a Google Kubernetes Engine (GKE) cluster inside of a tenant project.
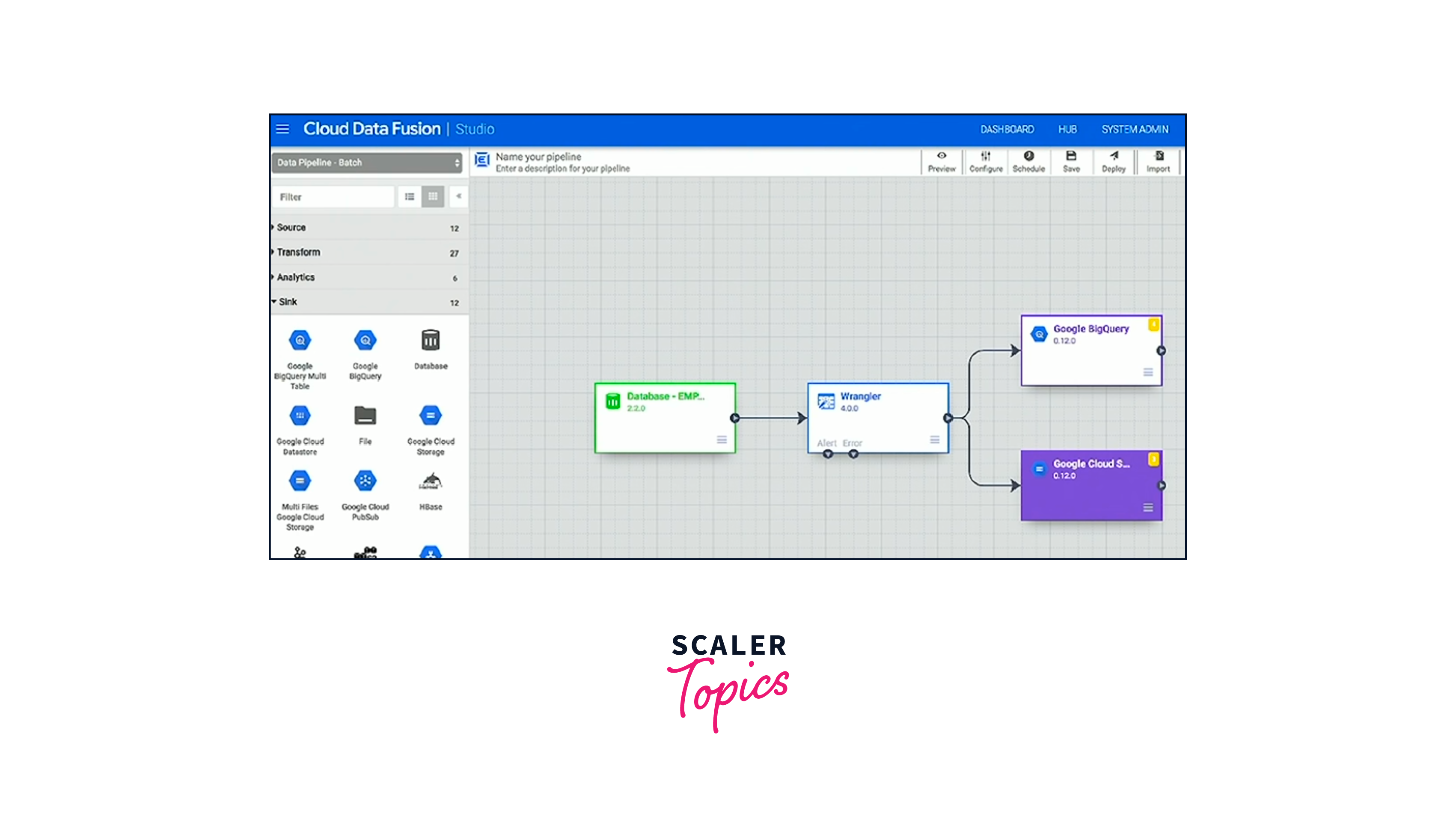
Some of the important components of Cloud Data Fusion are as follows:
- Tenant Project
- System services
- User interface
- Hub
- Metadata storage
- Namespaces
- Domain
- Pipeline execution
Google Cloud Bigtable
Bigtable is an HBase-compatible NoSQL database made for low latency data access, an environment in which scalability and reliability are crucial. The bulk of Google's products, including Gmail, Maps, and YouTube, which each have billions of users, is powered by the same technology.

NoSQL databases store data in a non-tabular format rather than using the conventional relational database approach.
Four Kinds of NoSQL Databases are:
- Document-oriented databases store data in flexible, semi-structured formats like JSON or XML.
- Key-value stores enable quick access and storage of unstructured data by storing them in a key-value format.
- Column-family stores are the best for managing vast volumes of data with many data types because they organise data into columns rather than rows.
- Graph databases store information as nodes and edges, and are the best tool for dealing with densely linked data, such as that found in social networks or recommendation engines.
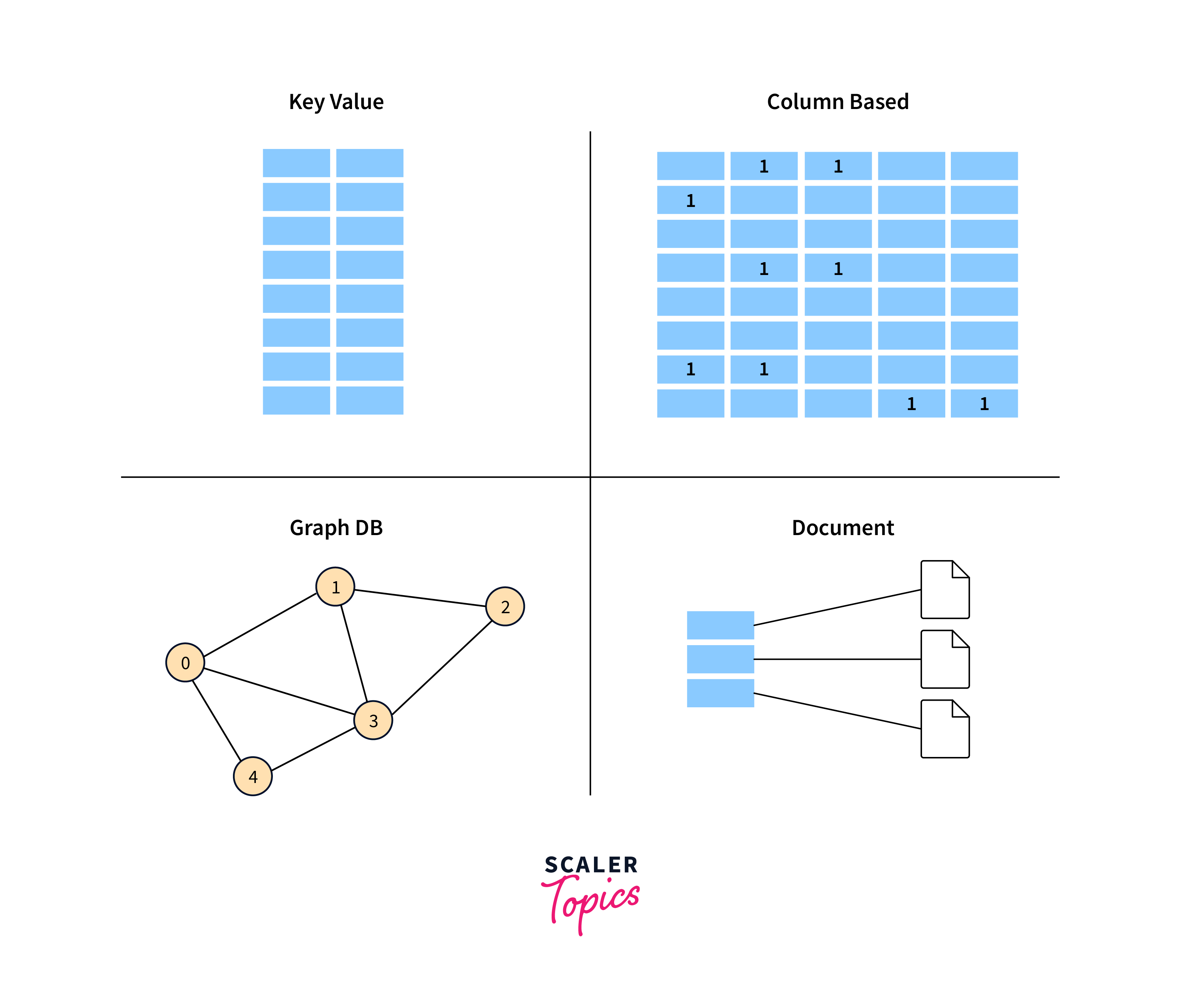
Bigtable falls into the Wide-Column based family along with other databases like Cassandra, and HBase.
Bigtable maintains information about columns. Columns are grouped into what are known as column families, in order to assist organise the data. To promote more effective access, these column families aggregate the fields that are most commonly asked for by the users.
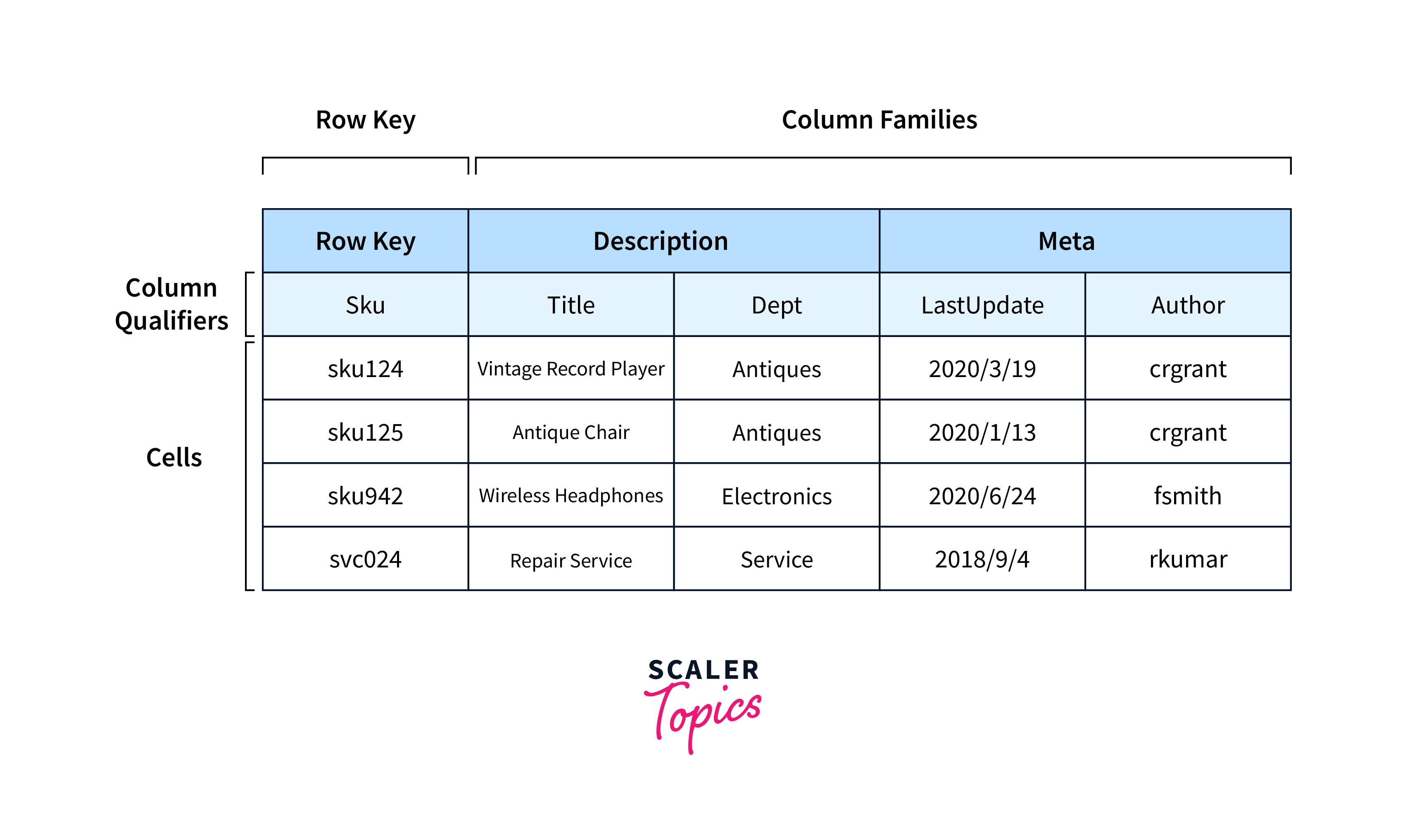
Google Cloud Data Catalog
A fully managed and scalable metadata management service, Google Cloud Data Catalog enables businesses to quickly find, comprehend, and manage their data assets throughout their entire data ecosystem.

Users can quickly search and browse through the information related to any data asset, as Data Catalog offers a single view of all data assets, whether they are on-premises or in the cloud. Information like data lineage, data quality, and access regulations may be included in this metadata.
Additional capabilities offered by Cloud Data Catalog include data discovery and classification, automatic schema recognition, and interaction with other Google Cloud services like BigQuery and Dataflow. These tools assist organisations in automating the administration of their data assets.
Architecture for Large Scale Big Data Processing on Google Cloud
Massive numbers of incoming log and analytics events may be gathered using Google Cloud's elastic and scalable managed services, which can then be used for analysis before storing them in a data warehouse like BigQuery.
Any design for ingesting substantial amounts of analytics data should consider which data you need to access in near real-time and which data you can manage after a little delay, and separate them properly.
The advantages of a segmented strategy include:
- Log Consistency: No logs are lost as a result of sampling or streaming quota restrictions.
- Lower Costs: Events and log entries made via streaming incur a higher fee than those made via batch tasks from cloud storage.
- Allocated Resources for Querying: Batch loading the lower priority logs prevents them from using reserved query resources.
The term hot pathway describes the method of processing and storing data as it is generated in real time. Real-time analytics and monitoring systems are common examples of applications that use this method since they must analyze data as soon as it is generated.
The term cold pathway describes how data is processed and stored in batch mode, usually after some lag time. This method is frequently applied in applications like batch processing and data warehousing that don't require rapid analysis of the data and can handle some processing latency.
The following architectural diagram introduces the idea of hot and cold pathways for ingestion:
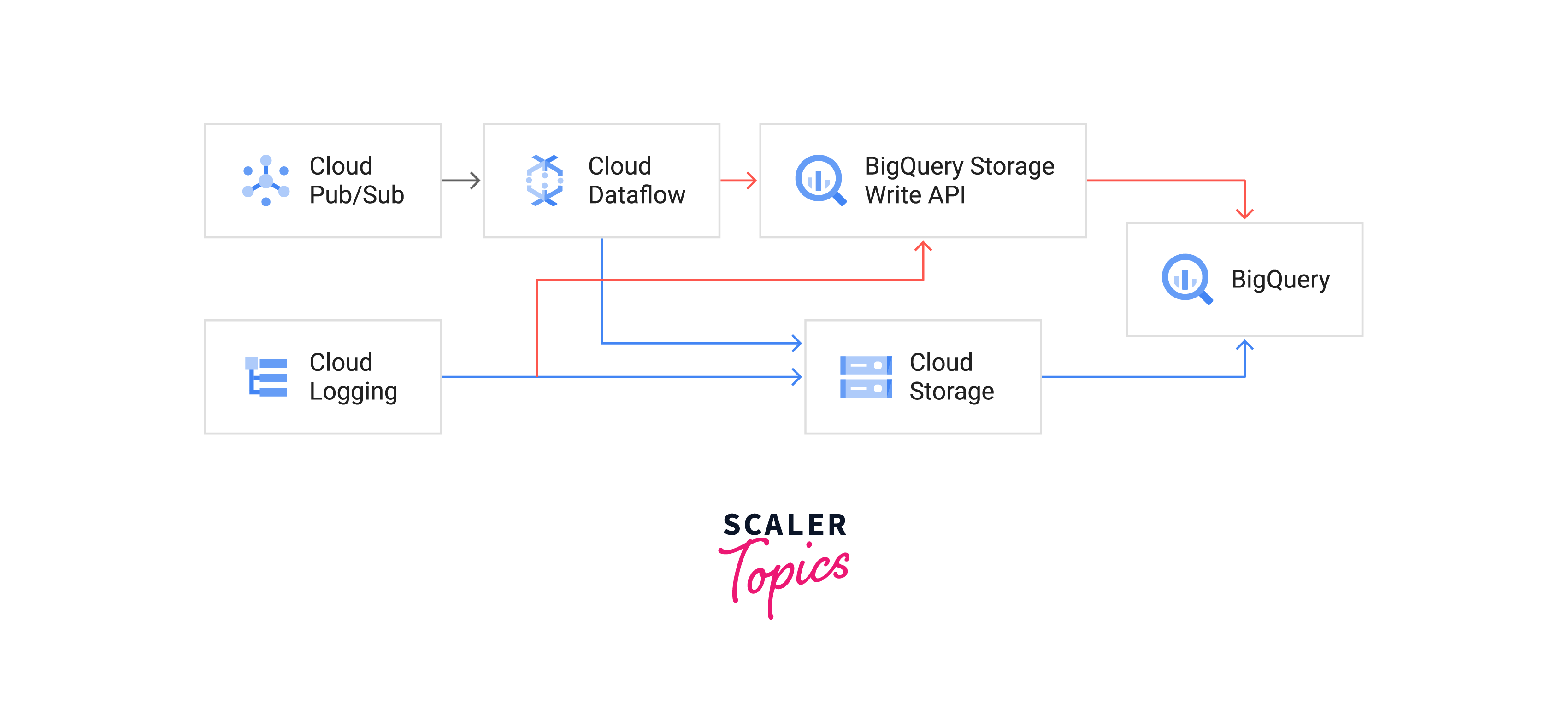
The two alternative sources of data in this architecture are as follows:
- By use of cloud logging, logs are gathered.
- Events related to analytics are posted to a Pub/Sub topic.
Data is placed into either the hot path or the cold path after ingestion from either source, depending on the message's latency needs. The cold path is a batch procedure that loads the data according to a schedule you decide, whereas the hot path employs streaming input and can manage a continuous data flow.
Logging Events
To ingest logging events produced by default operating system logging features, utilise Cloud Logging. The Cloud Logging Agent may be used to install Cloud Logging on a variety of operating systems, and it is accessible by default in a number of Compute Engine settings, including the standard images.
Hot Path:
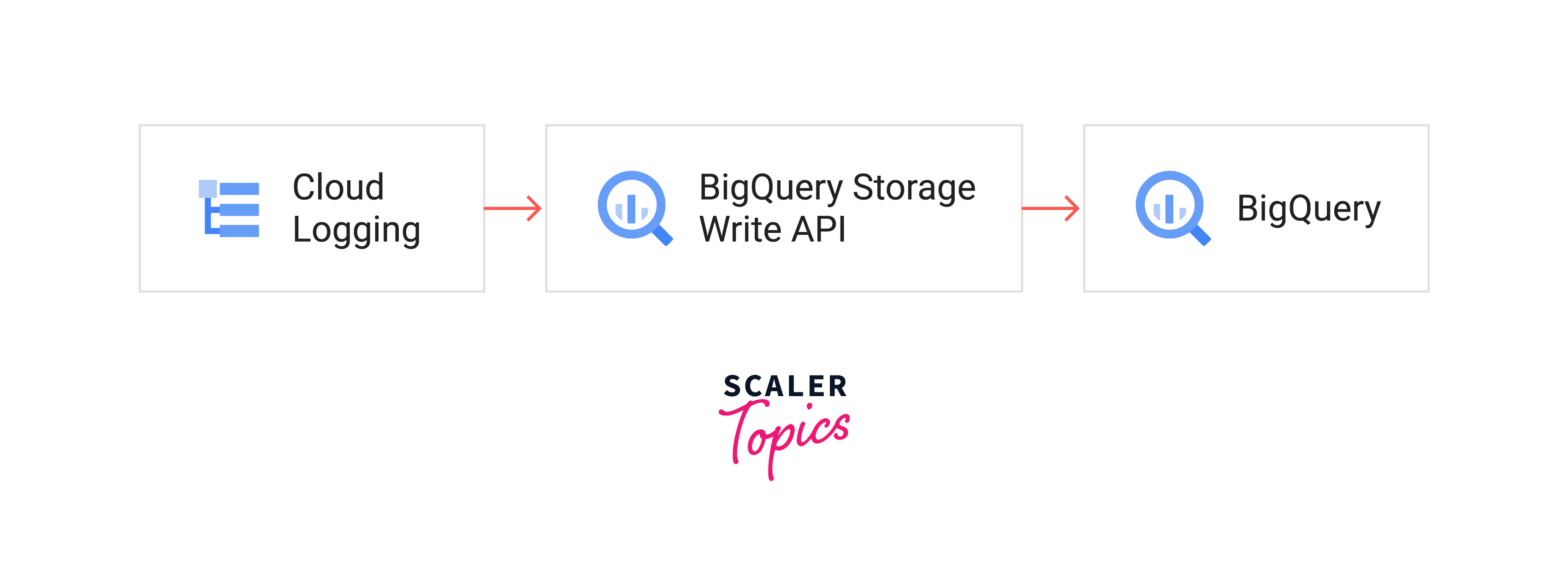
- By defining a filter in the Cloud Logging sink, essential logs necessary for the monitoring and analysis of your services are chosen for the hot path and broadcasted to several BigQuery tables.
- If huge volumes are anticipated, create distinct tables for ERROR and WARN logging levels and then further divide them per service.
- By following this best practice, queries against the data will continue to run smoothly and a maximum of 100,000 inserts per second per table will be maintained.
Cold Path:
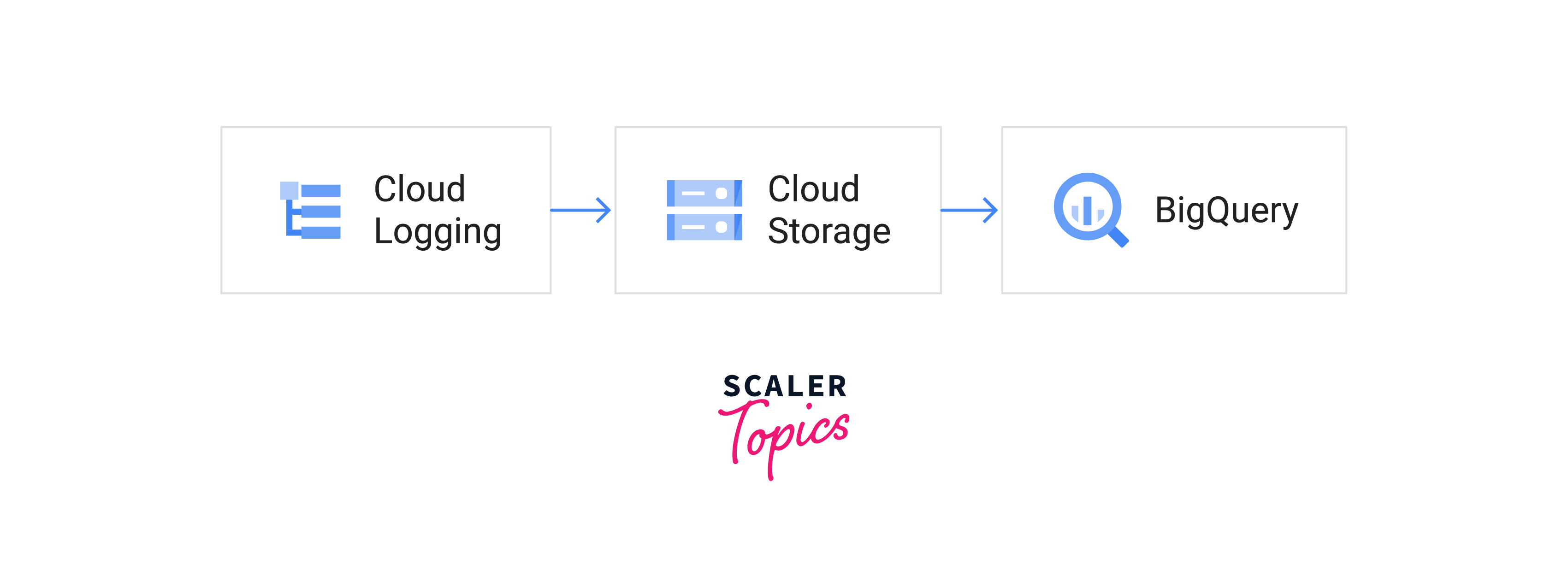
- Using a Cloud Logging sink directed to a Cloud Storage bucket, the cold path is chosen for logs that don't require near real-time processing.
- Hourly batches of logs are written to log files on cloud storage. The usual Cloud Storage file import procedure, which can be started using the Google Cloud UI, the command-line interface (CLI), or even a straightforward script, may then be used to batch load these logs into BigQuery.
Analytics Events
Analytics events may be produced by Google Cloud services used by your application or may be transmitted by distant clients. Ingesting these analytics events through Pub/Sub and then processing them in Dataflow provides a high-throughput system with low latency.
Hot Path:
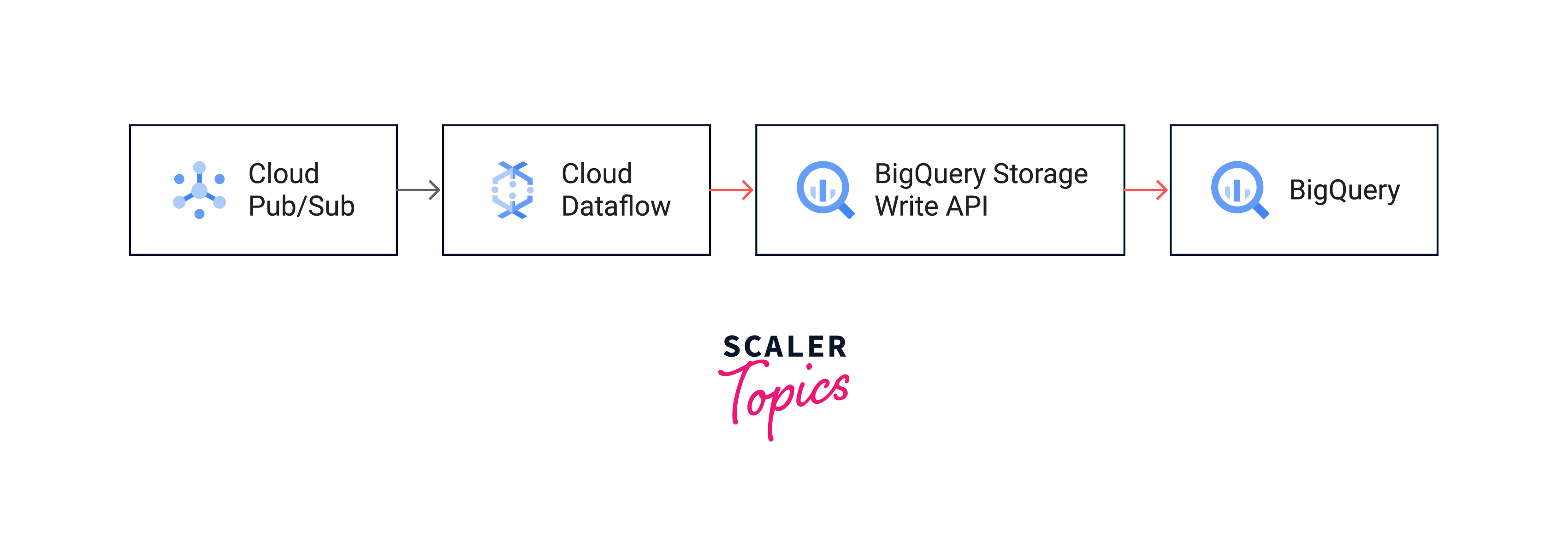
A data event can signal bad actors or undesirable client behaviour. Such events should be cherry-picked from Pub/Sub using an autoscaling Dataflow task, and sent straight to BigQuery.
Cold Path:
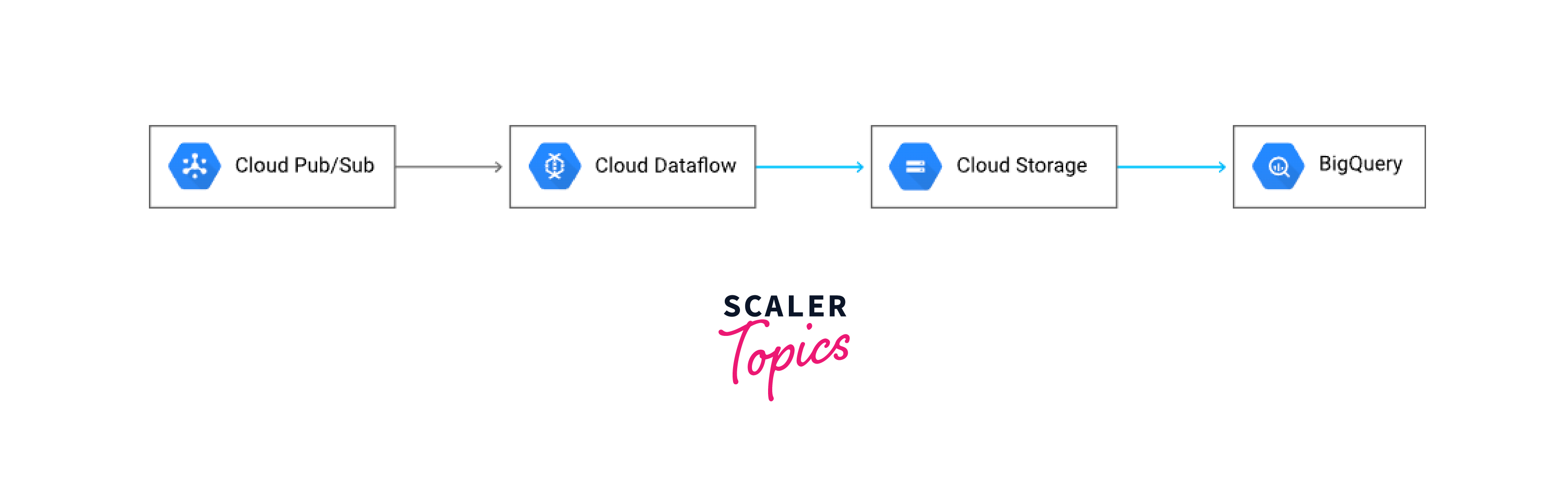
Dataflow can push events to objects on Cloud Storage that need to be recorded and examined on an hourly or daily basis but never instantly. The Cloud interface, the Google Cloud CLI, or even a straightforward script may be used to start batch loads from Cloud Storage into BigQuery.
GCP Big Data Best Practices
Data Ingestion and Collection
- Depending on the kind, frequency, and quantity of data to be gathered, pick the best ingestion technique, such as batch processing or streaming.
- Use technologies like Cloud Dataflow or Dataproc to validate and clean the data at the source to ensure data quality.
- Utilise managed services, such as Pub/Sub, and Cloud Storage to make data input easier and cut down on administrative burden.
- To enhance data discovery, lineage, and governance, consider adopting data catalog and metadata management solutions like Cloud Data Catalog.
Streaming Insert
- For scalability and parallelism, use a partitioning approach to equally divide data among partitions.
- To minimize write operations and boost efficiency, buffer and batch the incoming data using technologies like Cloud Dataflow or Dataflow Shuffle.
- It might take up to 90 minutes for data imported via streaming insert to be accessible for operations like copy and export.
Use Nested Tables
- Nested tables enable the representation of complicated data structures in a hierarchical style.
- Rather than storing data in flat tables with each column representing a single attribute, nested tables allow you to store structured data as a group of nested columns, comparable to a tree-like structure.
- When processing invoices, for example, the individual lines inside the invoice might be saved as an inner table.
- The outer table can contain information about the entire invoice (for example, the total invoice amount).
Big Data Resource Management
Many Big Data initiatives will require you to provide specific resources to members of your team, other teams, or customers. The notion of "resource containers" is used by Google Cloud Platform, which refers to a collection of GCP resources that may be assigned to a single organisation or project.
- Use Auto Scaling: Using Auto Scaling, you may automatically alter the number of resources assigned to your Big Data workloads.
- Use Resource Pools: Resource Pools enable you to more efficiently manage and distribute resources by generating pools of resources that can be assigned to different workloads.
- Use Machine Types: GCP offers a variety of machine types that are optimised for specific workloads, such as compute-intensive or memory-intensive applications.
- Graphics Processing Unit (GPU): Consider employing GPUs to accelerate processing if your Big Data tasks need extensive calculation. GPUs have the potential to greatly boost performance and minimise processing time.
FAQs
Q. How Does Google BigQuery Work? A.
- Google BigQuery is a cloud-based data warehouse service that lets customers store and analyze large-scale datasets with SQL-like queries.
- BigQuery has a variable price plan based on the quantity of data handled, making it affordable for storing and analysing massive datasets.
- It also has strong security features such as encryption and access control.
- BigQuery interacts with several third-party technologies, making it simple to integrate into current processes.
Q. What is BigQuery BI Engine? A.
- A tool offered by Google Cloud Platform (GCP) called BigQuery BI Engine enables quick and interactive business intelligence (BI) analysis of data in BigQuery.
- By keeping frequently visited data in memory, it is intended to enhance query speed and enable nearly immediate response times.
- Users may build extremely responsive dashboards and reports that can be updated in real time using BigQuery BI Engine. It also supports a broad variety of BI tools, such as Tableau, Looker, and Google Data Studio.
Q. What is Google Cloud Data QnA? A.
- Users may ask questions about their data using plain English utilising the Google Cloud Data QnA tool.
- It makes use of machine learning to determine the purpose of the user's inquiry before giving clear responses. Users may easily uncover insights from their data using Data QnA without the need for intricate queries or specialised skills.
- Numerous data sources, such as BigQuery, Cloud SQL, and Cloud Storage, are supported by Data QnA. Additionally, it offers connections with well-known BI tools like Google Data Studio and Looker.
Conclusion
- Google Cloud Big Data is a collection of cloud computing services used for processing and analysing huge and complicated data sets.
- BigQuery is a serverless, cloud-based data warehouse that lets users store and analyse massive datasets using SQL-like queries.
- Dataproc is a managed Spark and Hadoop service that enables customers to handle huge datasets with open-source technology.
- Dataflow is a fully managed service that allows customers to extract, manipulate, and load data at scale.
- A messaging service that allows users to stream and analyse real-time data is known as Pub/Sub.
- Organisations can store, process, and analyse big data sets using Google Big Data in a cost-effective and timely manner, empowering them to make informed business decisions and uncover insightful information from their data.