GPUs and CNN
Overview
Deep Learning is a subfield of machine learning which uses neural networks to train and develop models to fit the data. Neural Networks and Deep Learning are used widely in various applications such as image recognition and natural language processing. However, training large neural networks requires a lot of computational resources. This is where Graphical Processing Units(GPUs) play an important role in deep Learning by significantly reducing the time and resources required for training. We will look at how GPUs accelerate training specifically CNNs.
Introduction
In recent years, the field of Deep Learning has seen a significant increase in the use of convolutional neural networks (CNNs) for image and video analysis. One of the key factors that have enabled this rise in popularity is the availability of powerful graphics processing units (GPUs) that are well-suited to the computationally intensive tasks involved in training and running CNNs. In this article, we will explore the use of GPUs in CNNs, including how they are used to accelerate the training and inference process and their impact on computer vision.
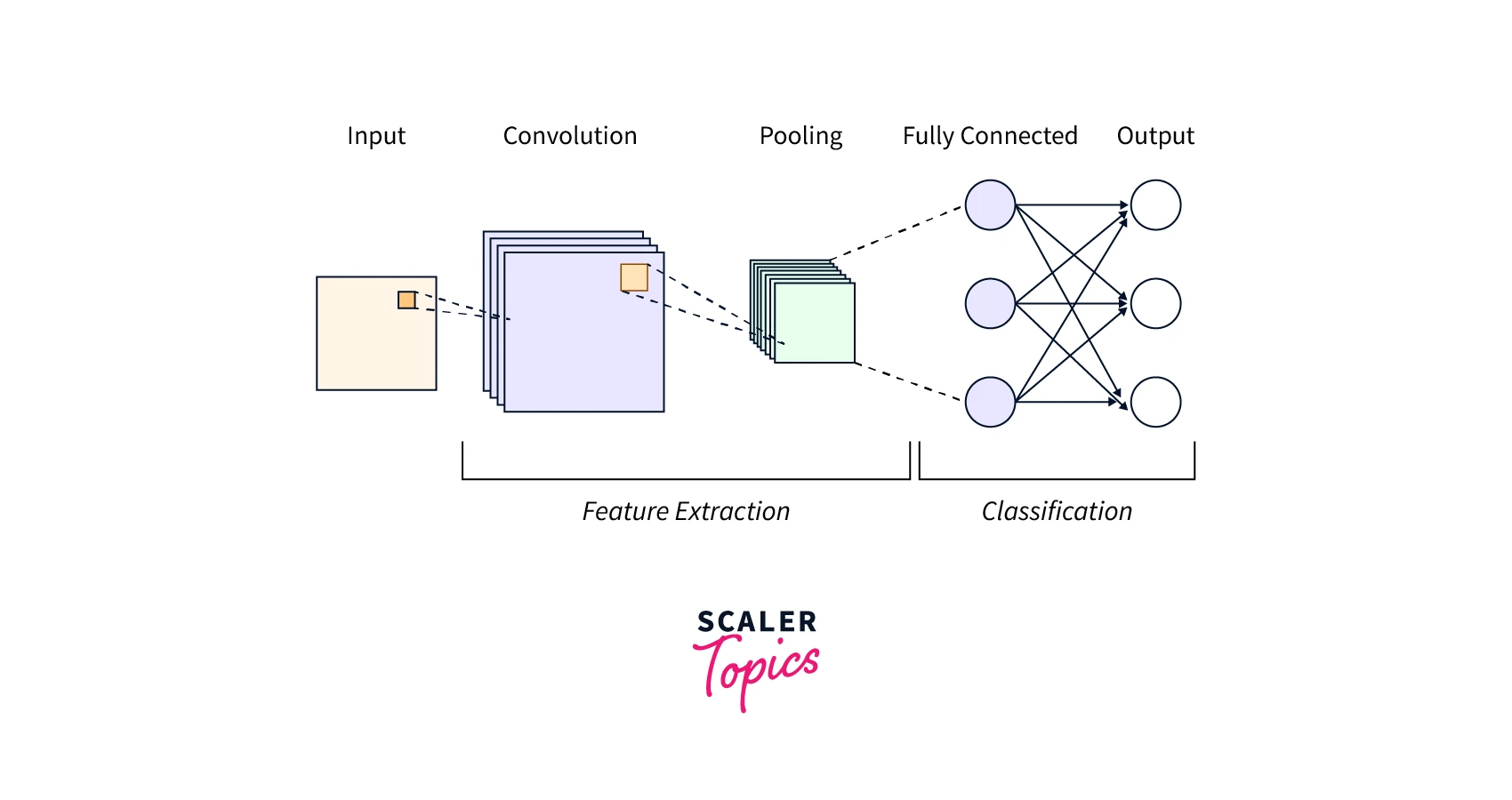
A Convolutional Neural Network (CNN) is a type of deep learning model used to analyze images and videos. It uses a process called convolution to extract features from the images.
In convolution, a small matrix called a kernel or filter is moved over the image in a process called sliding window. The kernel is multiplied element-wise with the part of the image it currently covers, called element-wise matrix multiplication.
The result of the multiplication is then summed up to create a single value; this is the output of the convolution operation. This process is repeated by sliding the kernel to a different image location. The output of this operation is a feature map, a condensed version of the input image that highlights certain features of the image.
The CNN is then composed of multiple convolutional layers, where different filters (kernels) are used to extract different features. These feature maps are then passed to pooling and fully-connected layers.
The pooling layers are used to reduce the spatial dimensions of the feature maps, while the fully-connected layers are used to classify the image.
Why do we Need More Hardware for Deep Learning?
Deep learning models, particularly those based on neural networks, require a large amount of computational resources because they involve a large number of parameters. These models often have millions or even billions of parameters that need to be trained using a large dataset. The training process involves iteratively adjusting the parameters through backpropagation to minimize the error between the predicted and actual output. The more parameters a model has, the more computation is required to train it.
One of the primary reasons that deep learning models require a lot of computational resources is that they are highly parallelizable. This means that many computations that need to be performed can be done simultaneously. This makes GPU an ideal hardware platform for deep Learning.
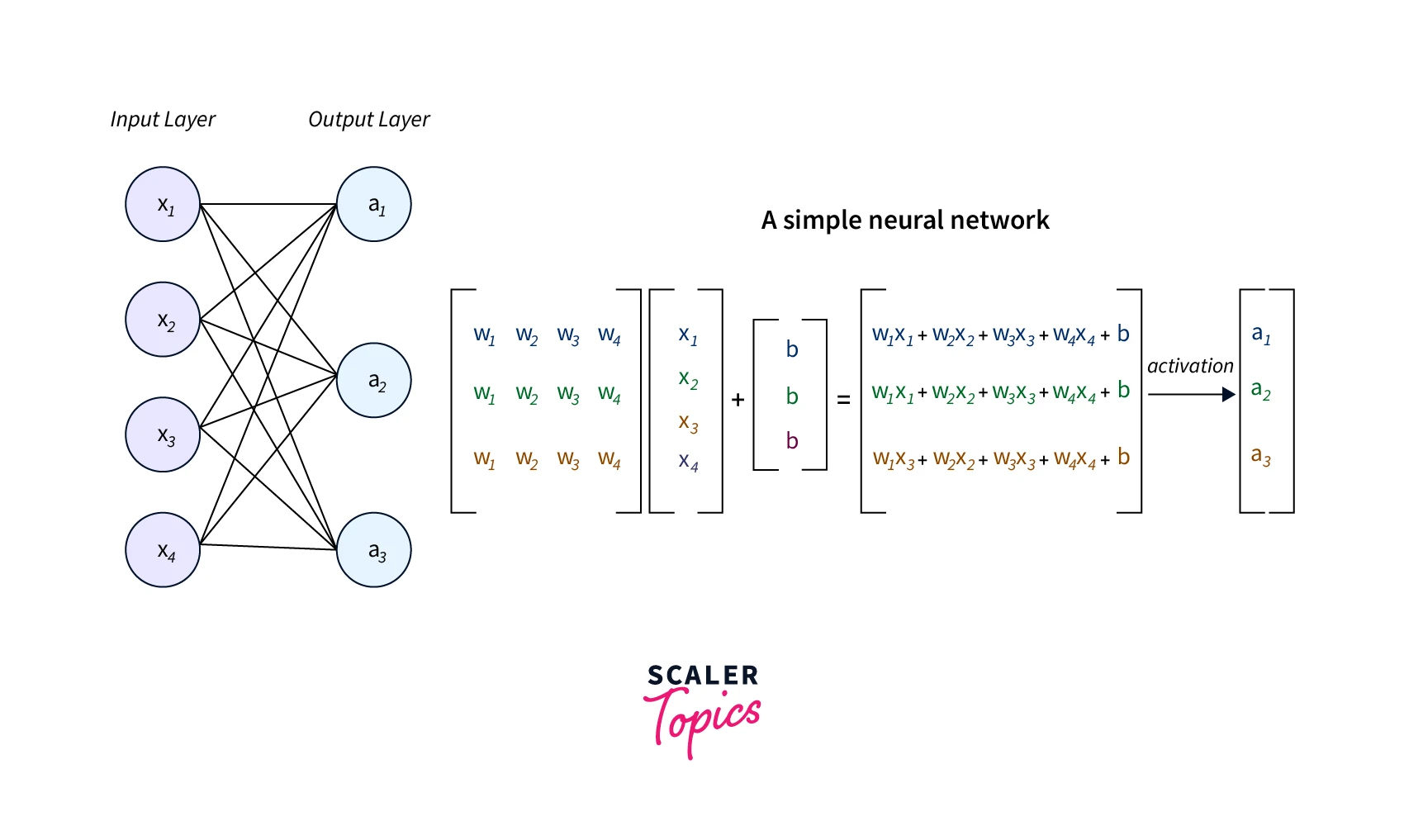
For example, let's say we have a fully connected layer that receives an input of size () and a weight matrix of size (). The input data is a 4-dimensional vector, and the weight matrix has 3 rows and 4 columns. To compute the output of this layer, we need to perform a matrix multiplication between the input data and the weight matrix.
The matrix multiplication process is used to compute the dot product between the input data and the weight matrix and to update the weights. This process is repeated many times during the training phase, and the weights are updated through backpropagation to minimize the error between the predicted and actual output.
As you can see in this example, matrix multiplication is a fundamental operation in Deep Learning. It is used in both the training and inference phase of a neural network, and it's computationally expensive but can be performed efficiently on GPUs.
Making Deep Learning Models Train Faster
A key metric for comparing the performance of CPUs and GPUs is the number of floating-point operations per second (FLOPS) they can perform. Floating-point operations are the basic building blocks of many mathematical operations, such as matrix multiplications, commonly used in deep Learning. The more FLOPS a device can perform, the faster it can perform these operations, and the faster it can train or run deep learning models.
Generally speaking,GPUs have a much higher FLOPS capability than CPUs. This is because GPUs are designed to perform large numbers of simple mathematical operations in parallel, whereas CPUs are designed to perform fewer more complex operations. As a result, GPUs in Deep Learning can perform many more FLOPS per second than CPUs.
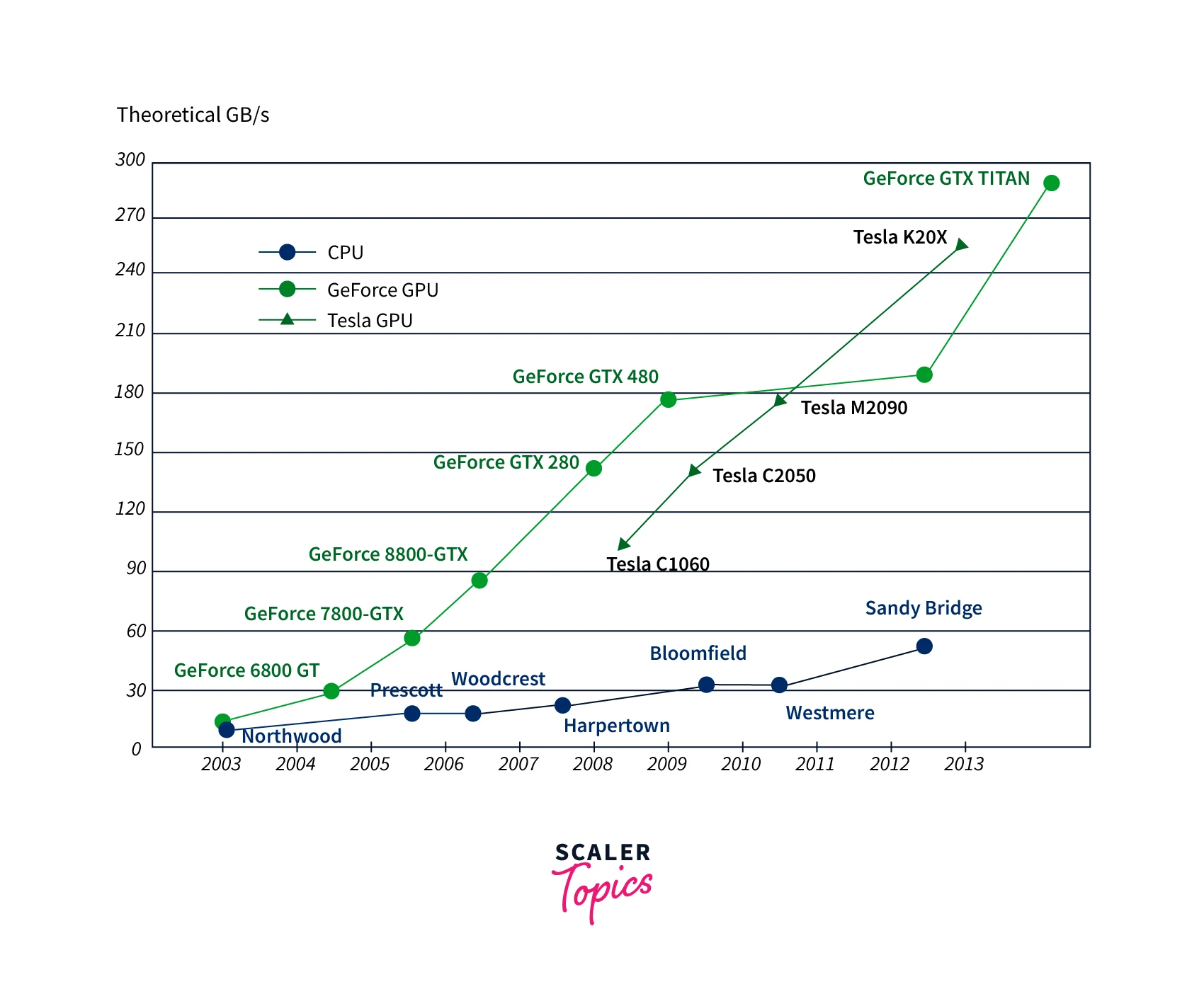
For example, the most powerful consumer GPU currently available has over 300 Teraflops of performance (as of 2021), while the most powerful consumer CPU has around 20 Teraflops. The GPU can perform around 15 times more FLOPS than the CPU.
The ability of the GPU in Deep Learning to perform many FLOPS per second is critical, as deep learning models often involve millions or even billions of parameters. These models require large amounts of computation to train, and performing many FLOPS per second allows the GPU to train models much faster than a CPU.
Why Choose GPU for Deep Learning?
The GPU architecture is designed for parallel computation and to perform repetitive tasks. This makes it well-suited for matrix multiplication. GPUs in Deep Learning have a large number of cores, which allows them to perform many matrix multiplications simultaneously. This is done by dividing the matrices into smaller sub-matrices and computing the dot product of the sub-matrices in parallel.
In addition to its many cores, GPUs have specialized hardware called "Single Instruction Multiple Data (SIMD)" units that can simultaneously perform the same operation on multiple data points. This is also used in matrix multiplication, allowing the GPU to perform many matrix multiplications simultaneously, greatly increasing the performance.
On the other hand, CPUs are not as well suited for matrix multiplication. They have fewer cores and are optimized for single-threaded performance. As a result, they are not able to perform the same level of parallel computation as a GPU. Additionally, CPUs do not have the same specialized hardware as a GPU, making them less efficient at performing matrix multiplications.
In Deep Learning, GPUs allow us to perform matrix multiplications much faster than CPUs, enabling us to train and run large-scale models with millions of parameters. This improves the accuracy and generalization of the models on unseen data; it also makes it practical to train deep networks with many layers, which were impractical to train with CPUs.
-
Memory Bandwidth:
GPUs have a much higher memory bandwidth than CPUs. Memory bandwidth is the amount of data that can be transferred to and from memory per second. This is important in deep Learning because neural networks require a lot of memory to store the parameters and the input data. The higher memory bandwidth of a GPU allows it to access and transfer large amounts of data from memory much faster than a CPU. This is particularly important when working with large datasets, as it allows the GPU to access and process the data quickly, enabling faster training times. -
Dataset size:
GPUs can also handle larger datasets than CPUs because they can perform the computations required for deep learning much faster. This means that a larger dataset can train a model without running into memory constraints or other performance issues. Additionally, GPUs can perform more computations in parallel; this allows them to process a larger batch size which can lead to better generalization and accuracy of the models. -
Optimization:
Many deep learning frameworks, such as TensorFlow, PyTorch, and Caffe, are optimized to take advantage of the parallel processing capabilities of a GPU. They are designed to automatically divide the computations across multiple GPU cores, which allows them to perform the computations required for deep learning much faster than a CPU. Additionally, many libraries and frameworks offer GPU-specific optimization, such as CUDA, cuDNN, TensorRT, etc., which are specialized libraries to accelerate deep learning computation on NVIDIA GPUs.
Cloud GPU Instances
GPU instances in the cloud refer to the use of cloud-based GPU servers for running deep Learning and other computationally intensive workloads. These GPU instances can be rented on-demand from cloud providers such as Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure.
These GPU instances are typically accessed via remote access, such as through a web browser or via the command line. They allow users to run their computations on powerful GPU hardware without owning and maintaining the physical hardware themselves.
When renting GPU instances in the cloud, users can choose the type and number of GPUs they want to use and the amount of memory and CPU resources. This allows users to scale their resources up or down as needed based on the demands of their workloads.

Additionally, cloud-based GPU instances often come with pre-installed deep learning libraries and frameworks such as TensorFlow, PyTorch, and Caffe, which makes it easy for users to start running their deep learning models without having to set up the software environment themselves. One of the benefits of using GPU instances in the cloud is the flexibility and scalability; since you pay as you go, you can scale up or down your resources as your workloads change. Also, it's very convenient for users who don't want to invest in costly hardware and maintenance. This allows them to focus on their model development without worrying about hardware and maintenance.
Creating your First CNN and Training on CPU
We will see the difference in time taken between the CPU and GPU to train a CNN model. To implement this, we will need to use a dedicated GPU machine. If the machine you're using doesn't have a dedicated GPU, we can use the cloud-based GPU provided by Google Colab to implement our model. We'll use the MNIST dataset to train our model.
If you're using Colab, the first step is to change the run-time type to GPU.
Let's see the GPU provided in your machine(or by colab)
Output:
The GPU we're provided with is an Nvidia Tesla T4. Next, we'll import the libraries required and build a CNN model using the Keras Sequential API.
We'll compile the model with Adam Optimizer, Sparse Categorical Cross Entropy as our loss function, and accuracy as the metrics.
Next, we'll load and reshape the MNIST dataset to our model requirements. We'll also normalize the data so that the pixel values are between 0 and 1.
Let's train our model with the CPU as our device and check the time elapsed while training the model. We'll train the model for five epochs.
Output:
Training on GPU
Now, let's train our model on the GPU and see if there is any significant difference in the time taken to complete the training.
We do the same steps as before to create, compile and train the model but change our device to GPU.
Output:
We can see there is a huge difference in training time. GPU is much faster than CPUs in training a deep learning model.
Conclusion
- GPUs are crucial for the efficient training of deep learning models.
- They accelerate the process by efficiently handling complex mathematical computations, specifically matrix multiplications
- Most of the deep learning frameworks are optimized to take advantage of GPU's parallel processing capabilities
- Use of GPUs in Deep Learning leads to faster training, more complex models, and more accurate results