Hadoop Ecosystem
Overview
Big data is an ever-growing large set of data. These huge collections of data are growing exponentially with time. Suppose we use traditional methodologies like Relational Database Management Systems and Non-relational Database Management Systems. In that case, they tend to fail or process quite slowly if we have tons and tons of data or big data. So, to process massive datasets, we use the Hadoop ecosystem.
Introduction
In this article, we will be discussing the Hadoop ecosystem and the various components that make up the Hadoop ecosystem. But before learning about the Hadoop ecosystem in detail, let us first discuss the term Big Data, which is the reason for the prime usage of the Hadoop ecosystem.
Big data is an ever-growing large set of data. These huge collections of data are growing exponentially with time. Some examples of big data can be data generated by social media, data generated by the stock exchange, data generated by jet engines, etc. We can divide big data into three categories:
- Structured Data
- Unstructured Data
- Semi-structured Data
Please refer to the chart provided below for more clarity.
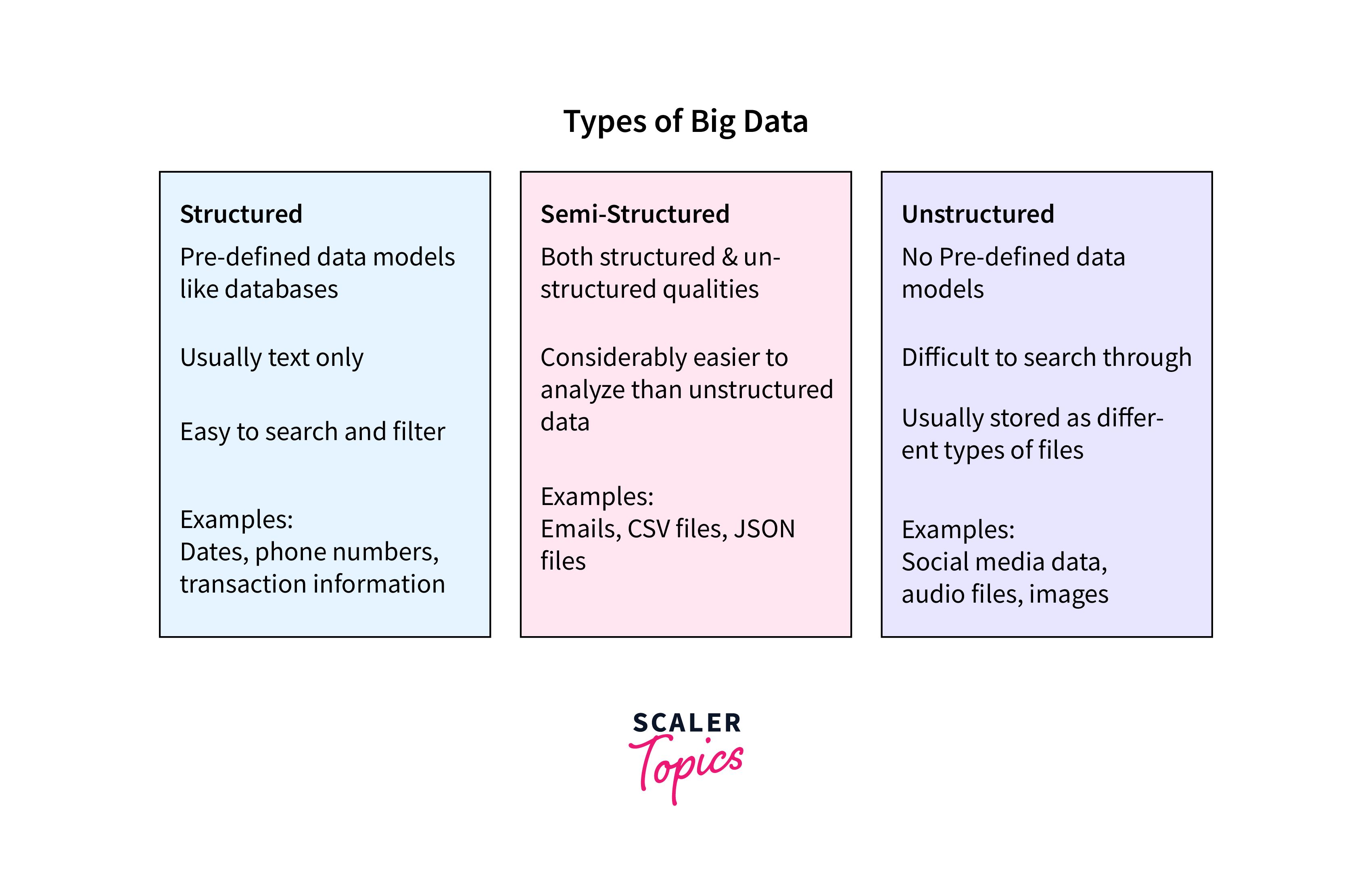
We can process data with the help of traditional methodologies like Relational Database Management Systems and Non-relational Database Management Systems. But these systems tend to fail or process slowly if we have tons of data.
The Hadoop ecosystem or Hadoop is created and maintained by Apache Software Foundation. In fundamental terms, the Hadoop ecosystem is an open-source framework comprising small components that help interact with the big data easily. Some of the components that make up the Hadoop ecosystem are:
- HDFS or Hadoop Distributed File System
- YARN or Yet Another Resource Negotiator
- MapReduce
- Spark
- Pig
- Hive
- Ambari
- HBase
- Mahout
- Spark MLLib
- Sqoop
- Zookeeper
- Oozie
We will learn about these components in detail in the next section.
Many companies use the Hadoop ecosystem because of its excellent features that help them deal with sensitive data effectively and efficiently. In the next section, let us learn more about the Hadoop ecosystem and its components.
Components that Form a Hadoop Ecosystem
The Hadoop ecosystem solves one of the current scenario's major issues: how to handle large data sets easily. In the Hadoop ecosystem, we mainly focus on the term data or datasets (in particular big data). The main aim of the Hadoop ecosystem is to help us manage big data easily. So, let us now dive deep into the Hadoop ecosystem and its various components that make it so popular among other frameworks.
Before getting into the details of the Hadoop ecosystem, let us first list some of the major features of it.
- Scalability, i.e., Highly Scalable Cluster
- Free
- Open-source
- Fault-tolerant
- Easy to Use
Some of its use cases are:
- Data Absorption
- Data Analysis
- Data Processing
- Data Reliability
- Maintenance of Data
Let us look at the overall ecosystem with the help of a diagram for more clarity.
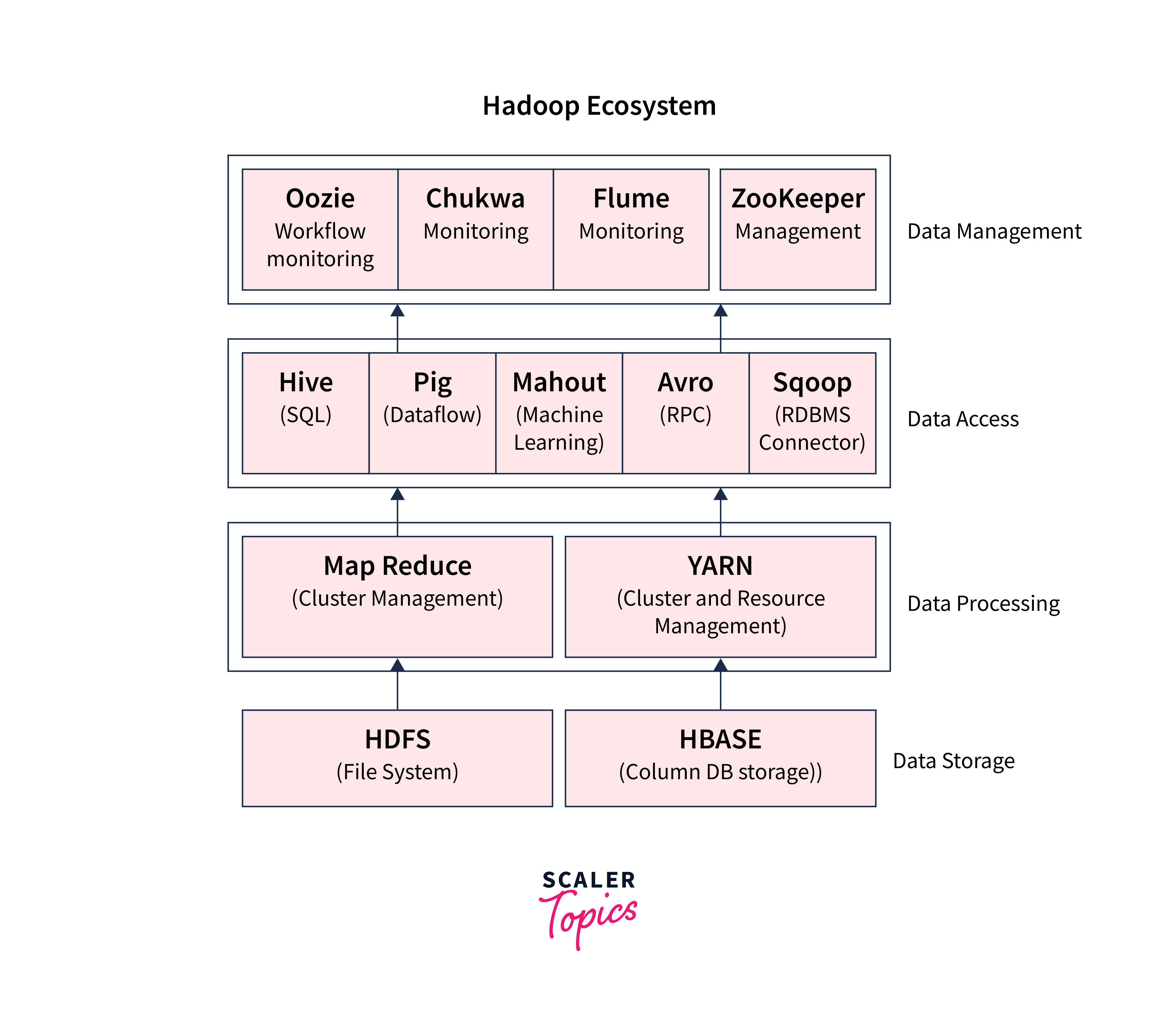
Let us now discuss these components one by one in detail.
HDFS: Hadoop Distributed File System
The HDFS or Hadoop Distributed File System is the primary component of the Hadoop ecosystem. The large sets of data (structured or unstructured) are stored with the help of HDFS. The HDFS stores our data in a tree-like structure where the root node stores the details of the children nodes, and the children nodes store the data. Before learning about the components of the HDFS, let us first see the overview with the help of a diagram for better understanding.
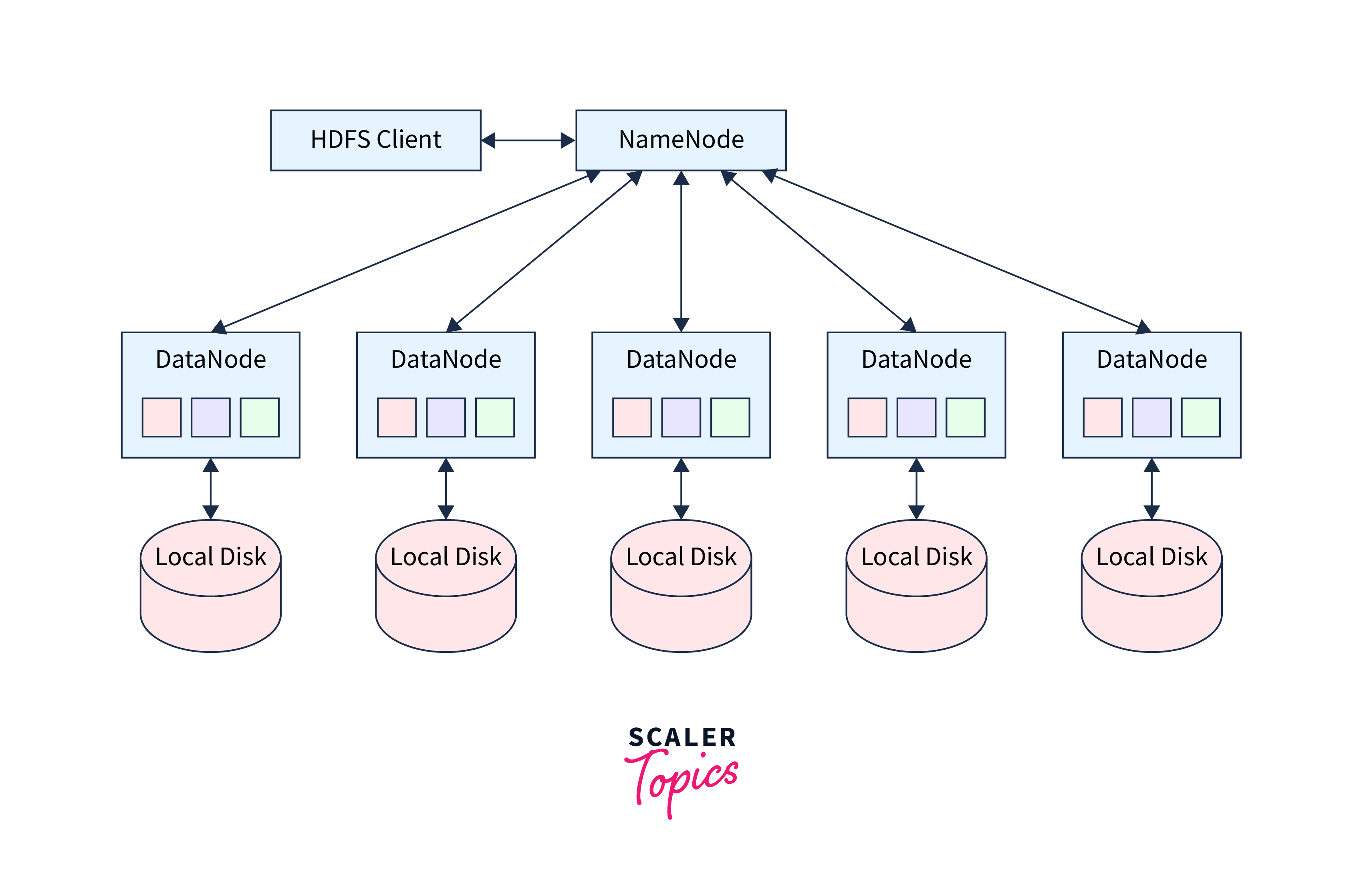
As we can see in the diagram above, the Hadoop Distributed File System consists of two main components - Name Node and Data Node.
- Name Node: The Name Node contains the data about the children node (here, Data Nodes). In simpler terms, the Name Node stores the metadata (i.e., data about the data). Now, a question that can come to our mind is why we need this Name Node if our data is stored in the Data Node. Well, the Name Node stores the log files just like the table of contents so that the searching and manipulation of the data can be done faster. The Name Node thus requires less storage and high computational resources.
- Data Node: As the name suggests, the Data Node stores the actual data, requiring more storage and fewer resources. We can visualize the Data Nodes as the commodity hardware present in the distributed environment. The Data Node stores the data in blocks of some specified size.
The HDFS is the heart of the Hadoop ecosystem as it coordinates the hardware components and the data clusters. So, whenever we query some data from the database, HDFS comes into the picture and helps the various other components to get the actual data faster and more efficiently. We will learn the entire scenario of how each component works together later with the help of an example so that our understanding can become more solid.
YARN: Yet Another Resource Negotiator
YARN, or Yet Another Resource Negotiator, is the component that handles the data clusters or cluster nodes. It is responsible for the processing of the data in the Hadoop ecosystem. In the Hadoop ecosystem, YARN acts as the resource manager and process scheduler. In addition, it manages the work of other components and provides resources like memory, RAM, and other resources.
Apart from allocating the resources, the YARN is also responsible for deciding things like:
- Who will run a particular task?
- When will the task run?
- Which node(s) are free and can take extra work?
- Which node(s) are not available?
Let us now see the overall structure of the YARN.
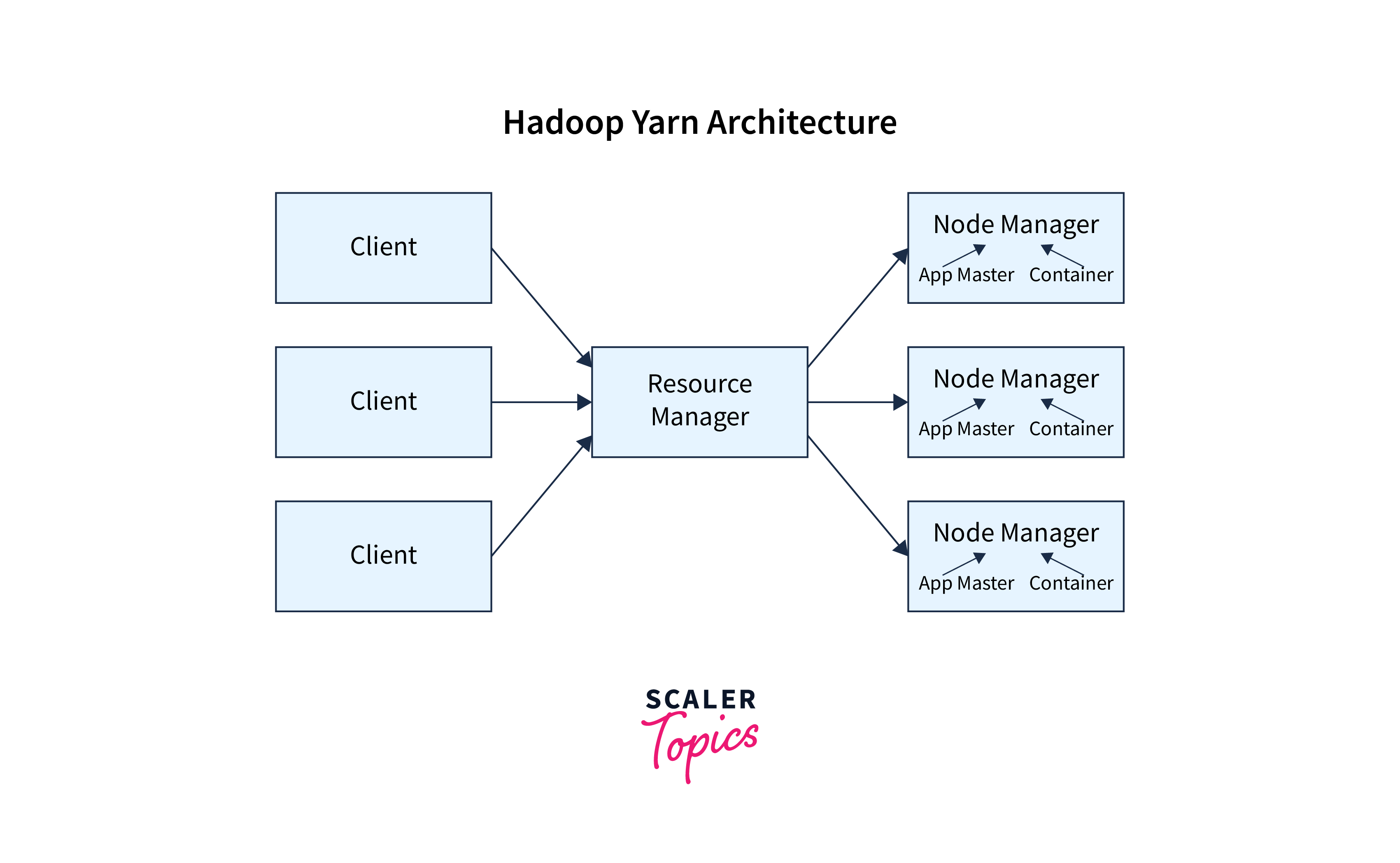
As we can see YARN is mainly comprised of two components-
- Resource Manager: The resource manager is also known as the master daemon, which manages and assigns the resources to the slave daemon (Node Manager). The Resource Manager assigns CPU, network bandwidth, and memory.
- Node Manager: The Node Manager is the slave daemon which responds and reports back the usage of the resource allocated to the Resource Manager. These Node Managers are present on all the Data Nodes of the HDFS. On the Data Node, they are responsible for getting the tasks executed.
Note:
- YARN has one more component, i.e., Application Master, which acts as an interface between the Node Manager and the Resource Manager.
- YARN also contains a scheduler which performs the scheduling algorithms and allocates the resources according to the requirement.
YARN is also called the Operating System of the Hadoop ecosystem as it manages and allocates the resources to the other components similar to what the Operating System does on a machine.
Some of the important points regarding YARN are as follows:
- It is quite flexible, enabling us to use MapReduce and other data processing models.
- It manages and allocates the resources very efficiently; even if several applications run on the same cluster.
MapReduce: Programming-Based Data Processing
MapReduce is yet another important component of the Hadoop ecosystem. Together, the MapReduce framework works on large sets of structured or unstructured data. The MapReduce framework divides the job (searching, adding, deleting, etc) into independent jobs. Now, as the jobs are divided, they can work parallelly, and thus it helps in faster working of the Hadoop ecosystem.
The MapReduce framework uses parallel processing and distributed algorithms. With the help of parallel and distributed processing, the Hadoop ecosystem can manage big data quite efficiently.
The overall structure of the MapReduce function is shown below.
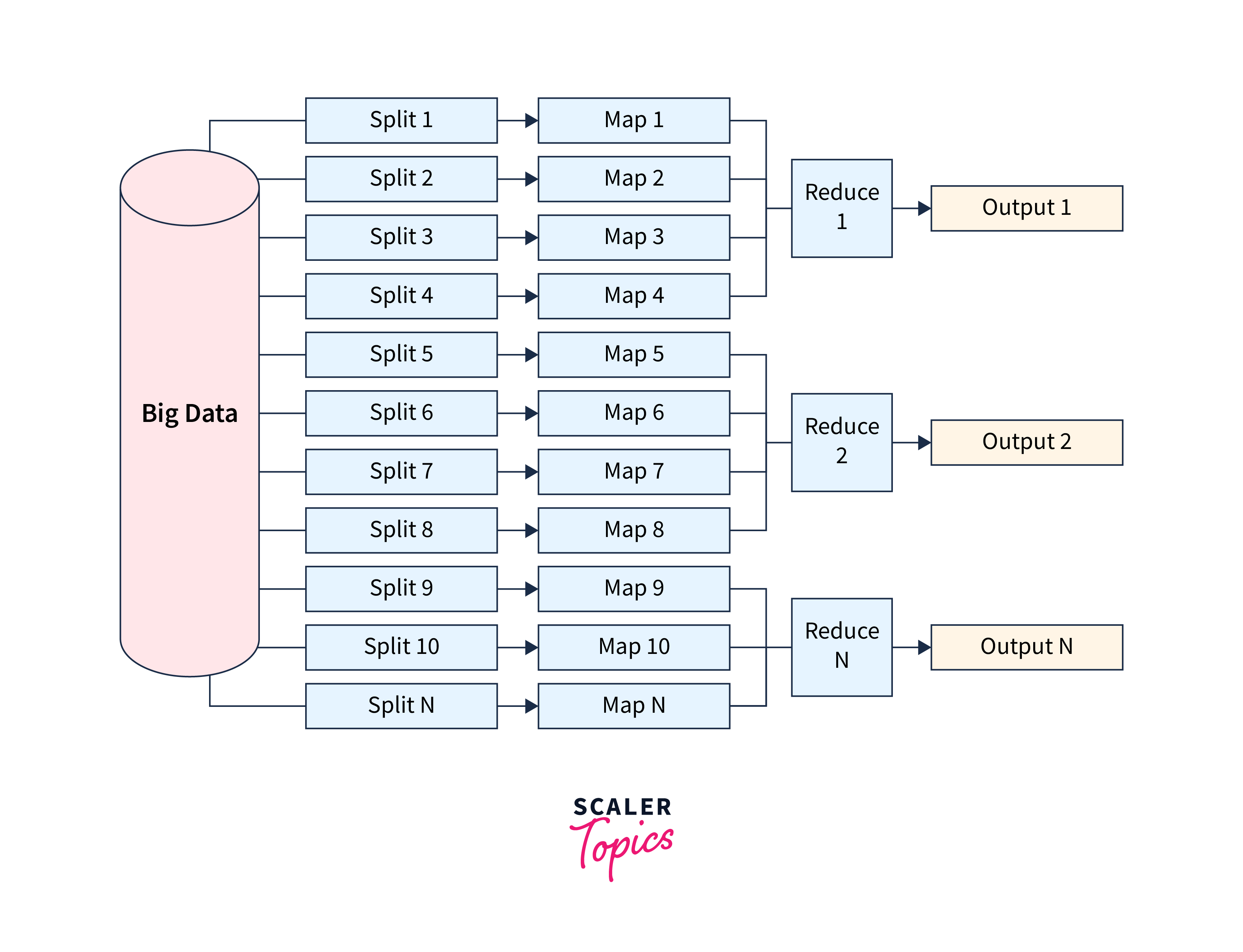
The MapReduce framework is comprised of two components or functions-
- Map(): The Map() function performs the filtering and sorting of the data and thus helps organize the data in groups. These groups contain data in the form of key-value pairs. The individual pairs of the group are known as tuples. These tuples or key-value pairs (K, V) are then processed by the Reduce() function.
- Reduce(): The Reduce() function takes the output generated by the Map() function as its input and then combines them into smaller tuples (or sets of tuples). Some of the important functions of the Reduce() function are aggregation and summarization.
Some of the important features of the Map() Reduce() functions are:
- It is highly scalable and can even process petabytes of data.
- As we know, the Hadoop ecosystem maintains several copies of data, so even if data is deleted at one place, then the same data is available in other places. With the help of parallel processing, MapReduce functions can easily work on the fault.
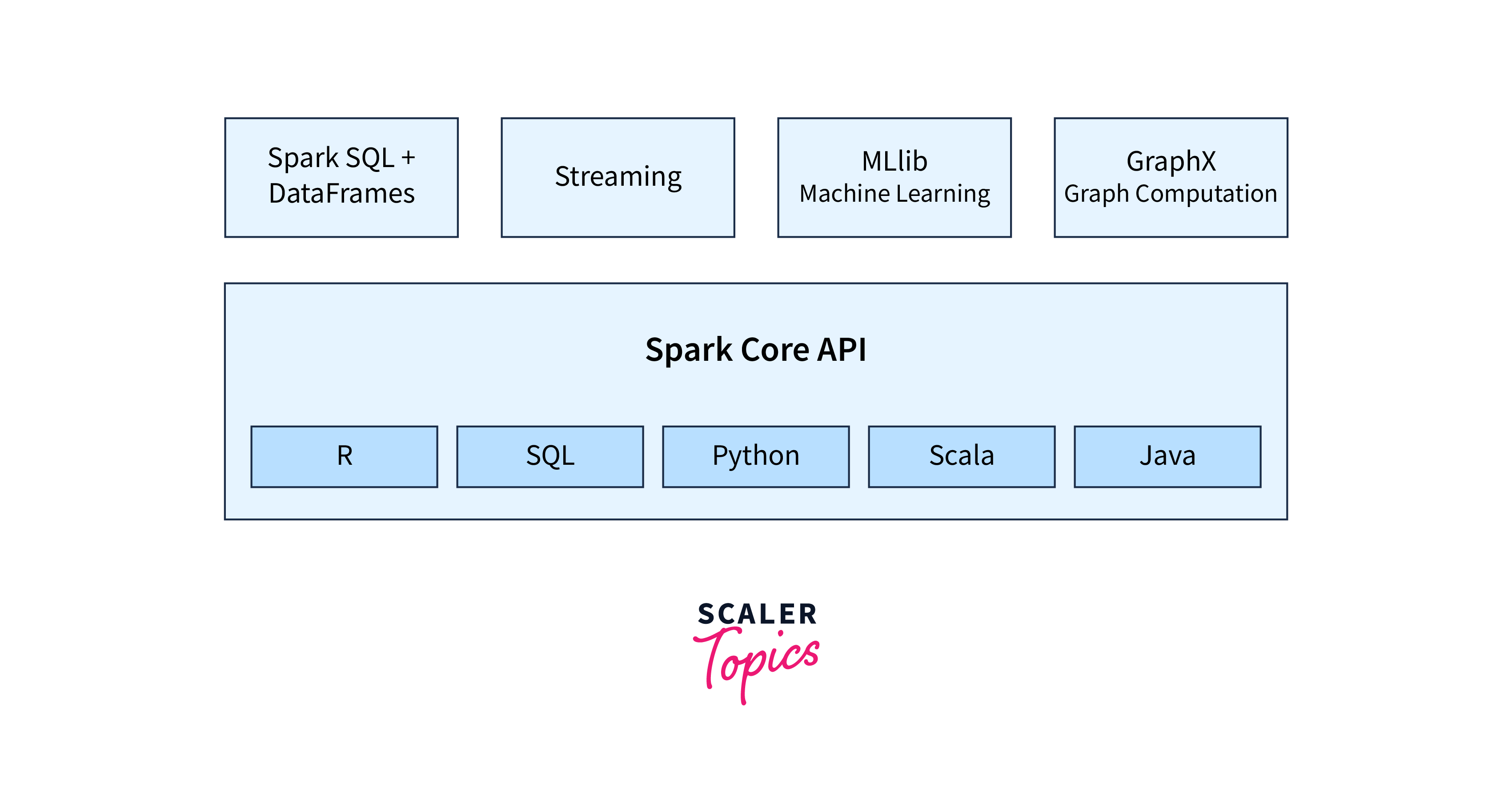
Spark: In-Memory Data Processing
Apache Spark is a platform that handles tasks like graph conversion, visualization, iterative and interactive real-time processing, batch processing, etc. Spark platform uses the memory resources of a cluster thus it is quite fast and optimized. Spark is a data processing engine supporting multiple languages like Python, Java, Scala, R, SQL, etc.
Some of the important points regarding Apache Spark are:
- It is faster (100 times) than Hadoop in terms of data processing because it resides in the memory of the data cluster.
- It is used for data processing and analytics in a distributed environment.
- Spark is written in Scala language and was developed in Berkeley at the University of California.
Let us see the overview of the Spark ecosystem.
Pig, Hive: Query-Based Processing of Data Services
Yahoo originally developed Pig or Apache Pig in Pig Latin language. Pig Latin is a Query base language similar to the Structured Query language. Pig is a high-level language platform used for structuring, processing, and analyzing huge amounts of data. Pig runs on the Pig Runtime Environment (similar to Java which runs on JVM).
Whenever we send a query through Pig, it internally executes the commands and then MapReduce handles the activities of searching and fetching the results. Now, after the processing has been done by MapReduce, Pig stores the result in the Hadoop Distributed File System.
The overall structure of Pig is shown below.

Hive is somewhat similar to Pig as both are used for data analysis, but Hive has many features other than Pig. Hive is used to perform writing and reading operations on large data sets. It provides us with an SQL-like environment and interface with the help of HQL, i.e., Hive Query Language.
The overall structure of HIVE is shown below.
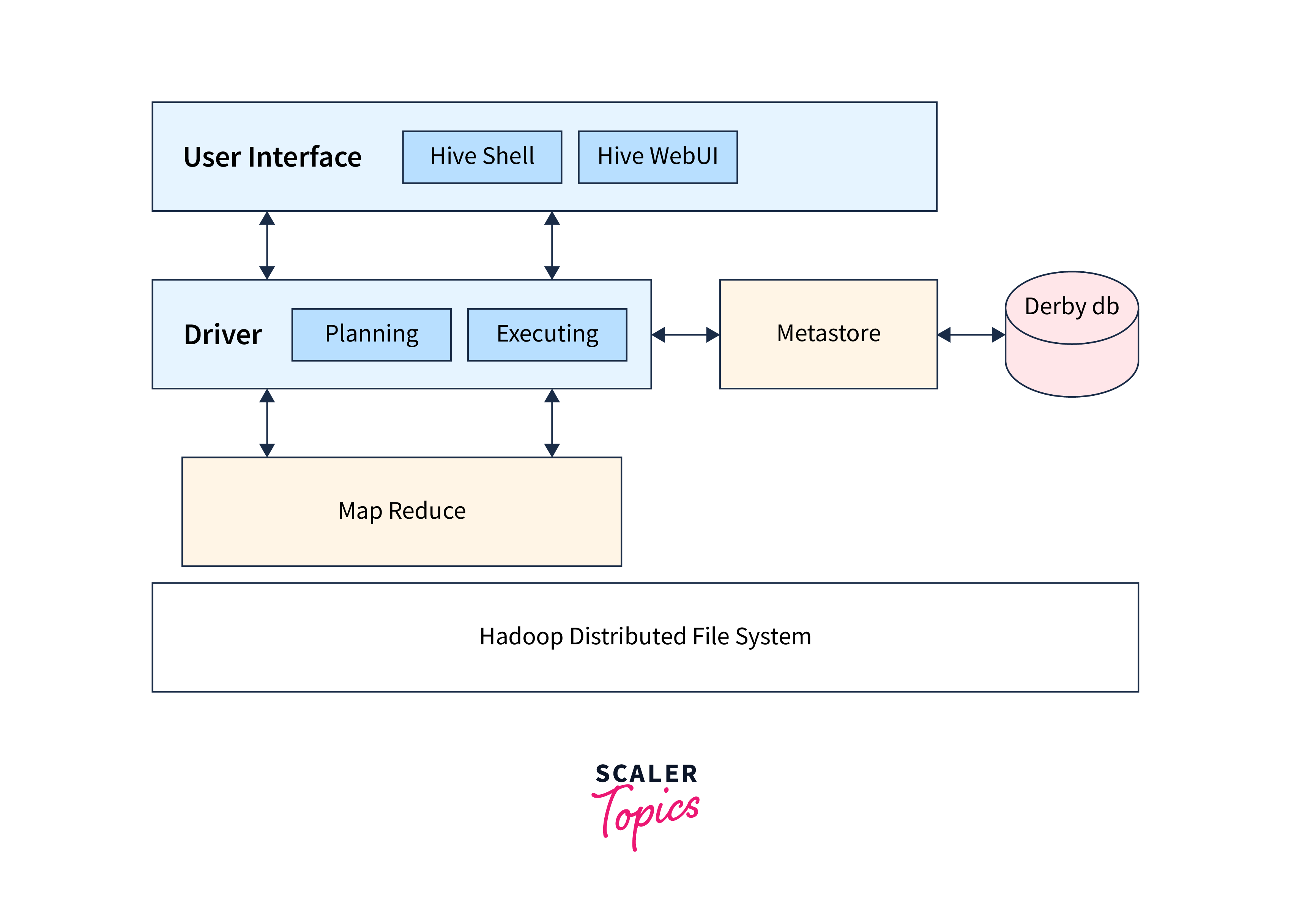
Some of the important features of Hive are:
- Hive is highly scalable as it can process batch and real-time data.
- It comes with two components, i.e., Hive CLI and JDBC Drivers.
Ambari
Apache Ambari can be termed as the management platform of the Hadoop ecosystem. We can also visualize Ambari as an open-source administrative tool that tracks the status of clusters. It helps monitor, provision, manage, and secure the Hadoop clusters.
Some of the important features of Apache Ambari are as follows:
- It is highly customizable and extensible.
- It maintains the Hadoop cluster's security and configurations. It is easy to install, configure, and manage.
- Apache Ambari has three major works:
- Hadoop cluster provisioning
- Hadoop cluster management
- Hadoop cluster monitoring
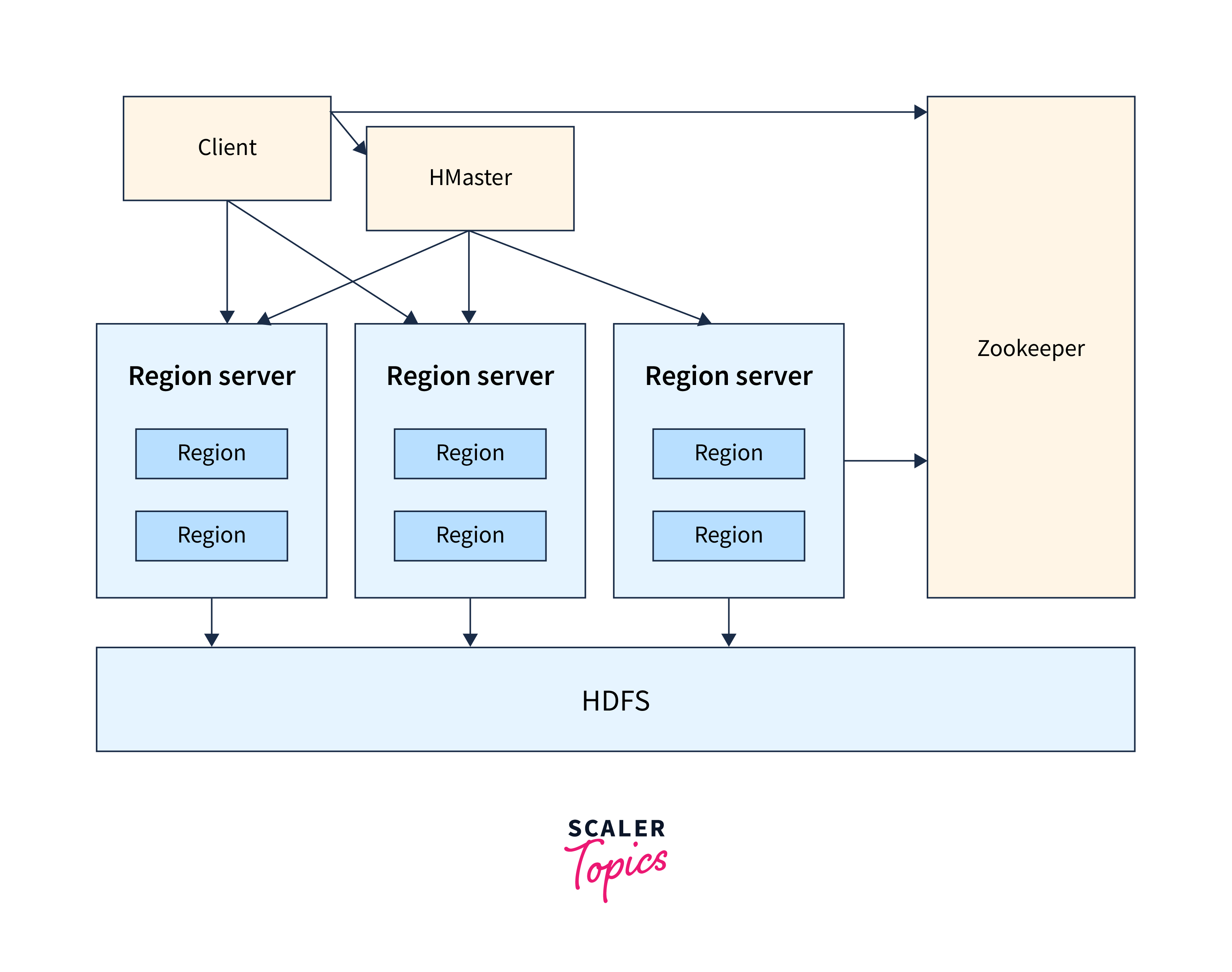
HBase: NoSQL Database
Apache HBase is a NoSQL database that can work with all kinds of data. Google's BigTable inspires it, and thus, it can work with large data sets quite efficiently.
Some of the important features of Apache HBase are as follows:
- It is designed to run on the Hadoop Distributed File System.
- HBase is fault-tolerant and can even store sparse data.
- HBase is written in Java Language.
- It is scalable and distributed.
- HBase has two major components, i.e., HBase master and Regional Server.
- HBase master handles the load balancing activities and is not a part of data storage.
- Regional Server is a slave node that works under HBase master. It runs on the data nodes of the Hadoop Distributed File System.
The overall structure of HBase is shown below.
Mahout, Spark MLLib: Machine Learning Algorithm Libraries
Apache Mahout is an open-source framework that helps us to create scalable Machine Learning algorithms and various data mining libraries.
When the data is loaded into the HDFS, Mahout comes into the picture and provides various tools that help extract meaningful patterns among big data sets.
Some of the famous algorithms using Mahout are:
- Classification
- Clustering
- Frequent Pattern Mining
- Frequent Item Set Mining
- Collaborative Filtering
Let us now look at some of the important points regarding Mahout.
- Mahout creates a scalable environment for machine learning applications.
- Mahout helps to create self-learning machines and applications that can learn through big data without being explicitly programmed.
- Mahout also provides us with a CLI to invoke machine learning algorithms.
Earlier, we discussed Apache Spark. MLLib is Apache Spark's scalable machine learning library with APIs written in languages like Scala, Python, Java, R, etc.
Other Components
Sqoop
Sqoop is an ingesting data service that can export and import only structured data from an Enterprise Data Warehouse or RDBMS to a distributed File System and vice versa.
Sqoop tasks internally use Map and Reduce functions. So, whenever we query the database, this main task is internally divided into a series of sub-tasks. These sub-tasks are transferred to Mapper (as Map tasks). For example, the Map task is importing data to the Hadoop ecosystem and then forwards it to the Reduce() function.
Zookeeper: Managing cluster
Zookeeper, as the name suggests, is the management unit whose main work is to coordinate and synchronize the various components or resources of the Hadoop ecosystem. Some of the important functions of the Zookeeper are communication among resources, maintenance, synchronization, etc.
Oozie
Oozie is a type of task scheduler which schedules jobs and binds them together as a single unit. Oozie has two types of jobs, i.e., Oozie coordinator jobs and Oozie workflow.
Oozie workflow is the set of jobs that are executed one after the other i.e. in a sequential manner. On the other hand, Oozie Coordinator jobs are triggered when we provide some external stimulus or some external data.
Conclusion
- Big data is huge collections of data that are growing exponentially with time. Some examples of big data can be data generated by social media, data generated by the stock exchange, etc.
- The Hadoop ecosystem is an open-source framework comprising small components that help interact with the big data easily. It is created and maintained by Apache Software Foundation (Apache).
- The HDFS or Hadoop Distributed File System is the primary component of the Hadoop ecosystem. The large sets of data (structured or unstructured) are stored with the help of HDFS. The HDFS is the heart of the Hadoop ecosystem as it coordinates the hardware components and the data clusters.
- YARN, or Yet Another Resource Negotiator, is the component that handles the data clusters or cluster nodes. It is responsible for the processing of data in the Hadoop ecosystem. YARN is also called the Operating System of the Hadoop ecosystem as it manages and allocates the resources to the other components.
- MapReduce framework works on large sets of structured or unstructured data. It divides a job into smaller independent jobs.
- Spark is a platform that handles tasks like graph conversion, visualization, iterative and interactive real-time processing, batch processing, etc. Spark platform uses the memory resources of the cluster thus it is quite fast and optimized.