Aadhar Based Analysis Using Hadoop
Overview
In today's data-driven world, harnessing the power of big data and advanced analytics has become essential for gaining valuable insights and making informed decisions. Aadhar based analysis using Hadoop is an exploration into the world's largest biometric identity system, containing a wealth of information about India's population using Hadoop, a powerful big data processing framework. We will walk you through the process of extracting, processing, and analyzing Aadhar data to gain valuable insights.
What are We Building?
The primary goal of this project is to demonstrate how Hadoop, a robust big data processing framework, can be utilized for Aadhar based analysis. By the end of this project, you'll have gained hands-on experience in harnessing the potential of big data technology to derive valuable insights from one of the world's largest biometric identity systems.
Pre-requisites
Before delving into the core details of Aadhar based analysis using Hadoop, it's essential to ensure that you have the necessary prerequisites in place. Here's a list of key topics you should be familiar with, along with links to articles that can help you brush up on these concepts:
-
Hadoop:
You should have a basic understanding of the workings of Hadoop. Learn more about Hadoop here. You should also have a functional Hadoop cluster set up for this project. Learn how to set up a Hadoop cluster by referring to the article here.
-
Aadhar Data:
Access to Aadhar data is a fundamental requirement. You can get the Aadhar data here.
-
Hive:
Hive is a critical component for data storage and querying in Hadoop. Get familiar with Hive by exploring the article on Hive Basics and also explore the commands in Hive.
How are We Going to Build This?
Let's break down the key steps in building our Aadhar based analysis using Hadoop project:
- We will start by getting the data from the Aadhar dataset in the link from the above section.
- Clean and preprocess the collected data to remove any inconsistencies, missing values, or irrelevant information.
- Store the preprocessed data in the Hadoop Distributed File System (HDFS). HDFS provides the scalability and fault tolerance.
- Create Hive databases and tables to structure the data. Define an appropriate schema.
- Utilize Hive, an SQL-like query language, to perform analysis on the Aadhar data.
- Interpret the insights derived from the analysis.
- Thoroughly test your analysis to validate its accuracy and reliability.
Final Output
The following image shows the execution of Hive commands for Aadhar based analysis using Hadoop.
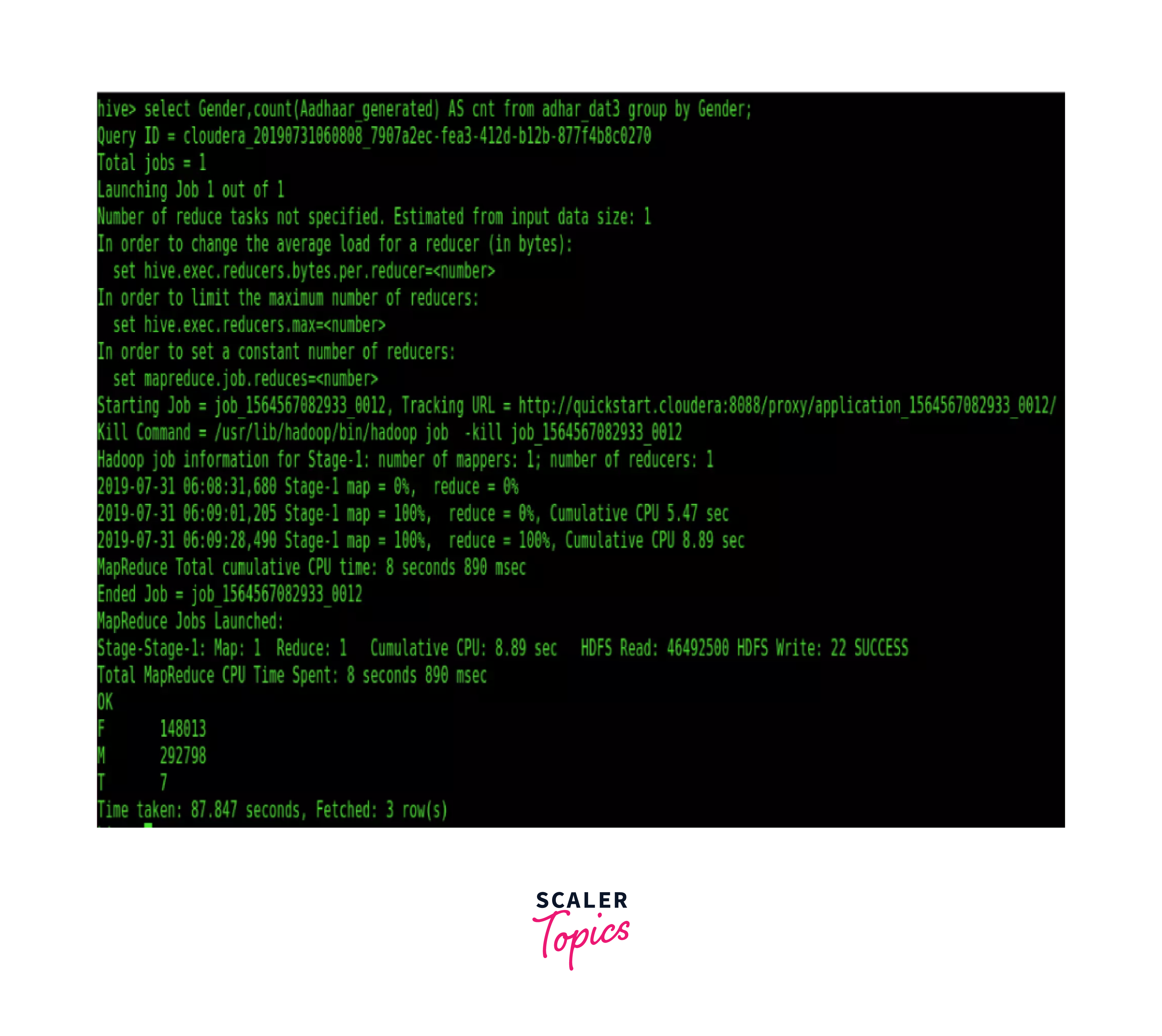
These insights can be presented using various visualization tools, enabling you to make informed decisions and gain a deeper understanding of the users.
Requirements
Below is a list of the key requirements for this Aadhar based analysis using Hadoop project:
- A Hadoop cluster should be set up with components like HDFS and YARN.
- Access to Aadhar data is essential. You'll need valid credentials to collect data from the Aadhar dataset.
- Hive should be installed and configured in your Hadoop cluster.
- Define an appropriate schema for the Hive databases to structure the Aadhar data.
- Data preprocessing tools or scripts are required to clean and prepare the data for analysis.
- Understanding of SQL is necessary for Hive data manipulation and analysis.
- Proficiency in programming languages like Python or Java is needed.
- Testing framework like JUnit is required for testing your code and analysis scripts.
Aadhar Data Analysis Using Hadoop
Data Extraction and Collection
In this section, we will walk you through the steps to get the data, clean, preprocess, and store the data as a CSV file for Aadhar based analysis using Hadoop.
Import Libraries:
To begin, we need to import the necessary Python libraries for data manipulation and analysis. We'll use the PySpark library for this purpose as PySpark with its distributed computing capability, enables us to handle larger datasets and scale across clusters seamlessly.
This initializes a Spark session named AadharAnalysis.
Load Data:
Load the Aadhar data from the aadhar_data.csv file into a PySpark DataFrame. This allows us to work with the data effectively.
In this step, we have successfully loaded the data from the CSV file into the data DataFrame. The inferSchema=True parameter helps in inferring the data types.
Data Cleaning and Preprocessing:
- Handling missing values: Identify and handle missing data, which may involve imputation or removal.
- Removing duplicates: Eliminate duplicate records to avoid redundancy.
- Data type conversion: Ensure that data types (e.g., age, Aadhar generated) are appropriate for analysis.
- Outlier detection and treatment: Identify and handle outliers that may affect the analysis.
The above code drops rows with missing values and converts the relevant columns to integer data type.
Store Cleaned Data as CSV:
Once the data is cleaned and preprocessed, we can save the cleaned data to a new CSV file for future use or analysis.
This code snippet overwrites the aadhar_data.csv file with the new processed file.
Architecture
The architecture for this Aadhar based analysis using Hadoop project involves a combination of components that work together to collect, process, and analyze Aadhar data using Hadoop. The primary components include:
-
Hadoop Cluster:
At the core of the architecture is a Hadoop cluster. This cluster consists of multiple nodes, each with its own processing and storage capacity responsible for distributing and processing large volumes of data in parallel.
-
Hadoop Ecosystem:
The Hadoop ecosystem is a collection of open-source tools and frameworks.
-
Hadoop Distributed File System (HDFS):
HDFS is the primary storage system in Hadoop. It stores data across the cluster's nodes and provides high fault tolerance and data redundancy.
-
Yet Another Resource Negotiator (YARN):
YARN is a resource management and job scheduling component in Hadoop. It allocates resources to various tasks and applications running on the cluster.
-
Apache Hive:
Hive is a data warehousing and SQL-like query language for Hadoop. It provides a familiar SQL interface for querying and analyzing data stored in Hadoop.
-
-
Data Extraction and Collection:
It involves using the Aadhar dataset to collect user data.
-
Data Preprocessing:
This involves cleaning the data, handling missing values, converting data types, and ensuring data quality.
-
Hive Databases:
Within the Hadoop cluster, Hive databases and tables are created to structure the collected data.
-
Analysis Layer:
In this layer, Hive queries are used to perform data analysis.
-
Testing and Validation:
The architecture includes a testing and validation layer. Thorough testing is conducted to ensure the accuracy and reliability of the analysis. Any issues or discrepancies are addressed before finalizing the results.
Data Flow:
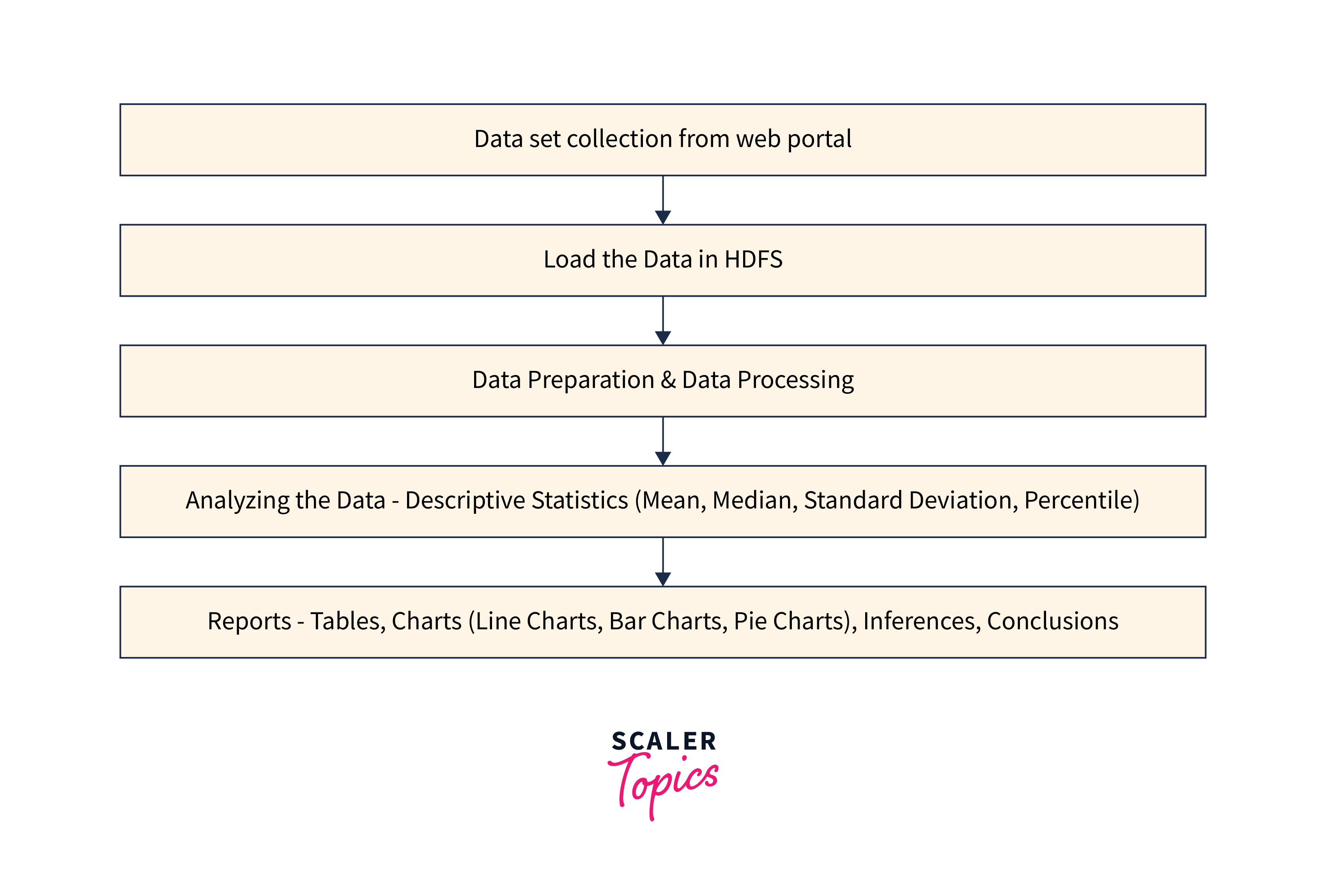
The data flow within this architecture typically follows these steps:
- Data is collected from the Aadhar dataset.
- The collected data is ingested into the Hadoop cluster and stored in HDFS.
- Data preprocessing is performed to clean, transform, and structure the data.
- Hive databases and tables are created to represent the data schema.
- Hive queries are written to analyze the data and derive insights.
- Testing and validation ensure the accuracy of the analysis.
Load data to HDFS
To load data into the Hadoop Distributed File System (HDFS), follow these steps:
- Access the Hadoop cluster where you want to load the data. Ensure you have the necessary permissions and access rights.
- Use the following command to transfer data from your local file system to HDFS. The aadhar_data.csv is the Local source path and /test/aadhar_data.csv is the HDFS destination path with the desired HDFS destination directory.
- Confirm that the data has been successfully transferred to HDFS by listing the contents of the target HDFS directory using the command:
This command should display the files and directories within the specified HDFS directory (/test/).
Additional Options:
-
To remove files or directories from HDFS, use the hadoop fs -rm command.
-
Adjust HDFS permissions if necessary using the hadoop fs -chmod command to control access to the data.
-
To view the content of a file in HDFS, you can use the hadoop fs -cat command:
Hive Databases
Access Hive:
Access the Hive environment within your Hadoop cluster using the following command,
Create a Hive Database:
Use the CREATE DATABASE command to create a new Hive database called aadhar_data_db.
Use the Database:
Switch to the newly created database using the USE command:
Create Hive Tables:
Create Hive tables to represent the data schema. Define the table name, column names, and their data types using the CREATE TABLE command.
The aadhar_data is the name of the table and the columns names and data types are as per the processed data. We specify that the data in the table is delimited by commas (,), as is typical for CSV files. The table is stored as a text file in Hive.
Define Data Storage Format (Optional):
You can specify the storage format for the Hive table, such as ORC or Parquet, for optimized storage and query performance. Use the STORED AS clause after creating the table:
Load Data into Hive Table:
After creating the table, you can load data into it using the LOAD DATA command.
As we have our data files in HDFS, we can load them into the table, by using the LOAD DATA command:
The /test/aadhar_data.csv is the path to the file on HDFS.
We can also insert data directly into the table from another table or query result, using the INSERT INTO command:
Verify Table Creation:
Verify that the table has been created and data has been loaded by running a SELECT query:
Analysis with Hive Command
Let us explore how to perform basic analysis using Hive commands on the Aadhar based analysis using Hadoop project.
Count the Number of Records:
You can start by counting the total number of records in your dataset.
Calculate Summary Statistics:
You can calculate summary statistics for numerical fields like 'Age', 'Aadhar generated' and 'Enrolment Rejected'. For example, to find the average age of the individuals:
Gender Distribution:
Here's a Hive command to retrieve the gender-wise count of Aadhar cards generated.
Regional Analysis:
You can analyze data based on regions, such as states and districts. For instance, to find the number of Aadhar cards generated by the state:
Age Distribution:
To analyze the age distribution, you can create a histogram of age groups:
Results
Let us explore the output of basic analysis done with Hive commands in the Aadhar based analysis using Hadoop.
Count the Number of Records:
This output displays the total number of records in the aadhar_data table, and the result is 1000 records in this example.
Calculate Summary Statistics:
Here, we compute the average age of the individuals in the dataset, which is 35.2 years in this sample.
Gender Distribution:
Here, we select the Gender column and calculate the count of Aadhar generated for each gender. We group the results by the Gender column, which provides a breakdown of Aadhar cards generated for males and females.
Regional Analysis:
This output groups the data by the state column and calculates the total number of Aadhar cards generated in each state.
Age Distribution:
Here, we categorize individuals into age groups and calculate the count of individuals in each group.
Testing
Testing is a crucial phase to ensure the accuracy, reliability, and validity of the results of your Aadhar based analysis using Hadoop. Below are some of the tests and their steps you can perform for the testing of your data analysis project.
- Define testing objectives and criteria
- Prepare test data
- Perform testing of individual components or queries within your analysis
- Verify data consistency of analysis results
- Test performance and scalability
What’s Next
Now that you've completed the Aadhar based analysis using Hadoop project, you might be wondering what you can do next to further enhance your skills and explore additional features or improvements. Here are a few ideas for what you can do next:
-
Machine Learning Integration:
Extend your analysis by incorporating machine learning models and techniques. You can use tools like Apache Spark MLlib or scikit-learn in Python to build predictive models based on your Aadhar data. For example, you could predict user engagement or identify patterns in user behavior.
-
Real-time Data Processing:
If you want to work with real-time data, explore technologies like Apache Kafka and Apache Flink to process and analyze data as it arrives. Real-time data analysis can provide immediate insights and is essential in applications like social media monitoring and recommendation systems.
-
Data Security and Privacy:
Dive into the realm of data security and privacy. Implement data anonymization techniques, encryption, and access controls to safeguard sensitive information in your analysis. Understanding data privacy regulations (e.g., GDPR) and compliance is also valuable.
-
Optimizing Hadoop Cluster Performance:
If you're working with large datasets, delve into Hadoop cluster optimization. Learn about resource management with YARN, tuning HDFS settings, and configuring Hive for better performance. Optimization can significantly speed up your data processing.
-
Automate Data Pipelines:
Build data pipelines to automate the collection, preprocessing, and analysis of data. Tools like Apache NiFi and Apache Airflow can help you create robust and scalable data workflows.
Conclusion
- Aadhar based analysis using Hadoop is a powerful approach to derive insights from large-scale datasets.
- The project involves data extraction, preprocessing, and analysis within a Hadoop ecosystem.
- Preparing for this project requires a Hadoop cluster, Hadoop ecosystem tools, and an understanding of Hive for data warehousing.
- Data extraction involves getting data from the Aadhar dataset.
- Data preprocessing includes cleaning, handling missing values, and structuring data for analysis.
- Hive databases and tables are created to define the data schema.
- Analysis is performed using Hive queries, enabling data-driven decisions.
- Testing ensures the accuracy and reliability of the analysis, involving unit, integration, and performance testing.
- Further, one can dive into advanced steps like machine learning integration, real-time data processing, and data governance.