Agricultural Data Analysis Using Hadoop
Overview
The Agricultural Data Analysis using Hadoop project relies on a Hadoop cluster, which handles distributed storage and data processing. The project uses the Java Development Kit for efficient Hadoop tasks and Hive for structured data storage and SQL-like queries. Data sources include meteorological data, soil quality metrics, crop production statistics, and more. Data preparation tools and efficient ingestion methods are crucial. Data is loaded into HDFS, and Hive databases structure and manage data. Results are presented visually via reports, as actionable insights, guiding improved agricultural practices.
What are we building?
The core objective of this Agricultural Data Analysis using Hadoop project is to provide an accurate analysis of the agriculture ecosystem, filling the gap in reliable insights. The dataset includes columns like state, district, market, commodity, variety, arrival date, minimum price, maximum price, and modal price, offering comprehensive agricultural insights.
Pre-requisites
-
Hadoop Cluster Requirements:
- A well-configured Hadoop cluster is essential as it serves as the backbone for managing distributed storage (HDFS) and data processing (MapReduce) efficiently.
- Accurate installation and configuration of Hadoop across the cluster is imperative.
- Follow this link for Hadoop Installation.
-
Java Development Kit (JDK):
- JDK is crucial as Hadoop relies heavily on Java for writing MapReduce tasks and cluster management.
- JDK should be appropriately installed and configured on all cluster nodes.
-
Data Sources:
- Access to diverse agricultural data sources, including meteorological data, soil quality metrics, crop production statistics, and more, is necessary.
- Data sources can include sensors, databases, or external APIs.
-
HDFS (Hadoop Distributed File System):
- Data is loaded into HDFS, a distributed file system with a master-worker pattern.
- Adequate storage capacity within HDFS is paramount to accommodate agricultural data for analysis.
- Scalability considerations should allow for future dataset expansions
- Click here to know about the Hadoop HDFS Commands.
-
Hive Configuration:
- Hive, vital for structured data storage and querying, requires proper installation and configuration within the cluster.
- It provides Hadoop with an SQL-like interface.
- To learn more about Hive, click here.
-
Hive Database Management:
- Hive databases are central to structuring and managing data.
- Creating tables and loading data from HDFS into Hive tables is a fundamental step in the data analysis process.
-
Analysis with HiveQL:
- Analysis is performed using HiveQL commands. These yield insights and recommendations benefiting the agriculture ecosystem.
- Tasks include identifying top agricultural states by sale or states with the cheapest commodity prices.
- Follow this link for an introduction to HiveQL.
How are we going to build this?
-
Data Source Access:
- Make sure you have access to a wide range of agricultural data sources, such as meteorological data, soil quality indicators, crop production statistics, and more.
- Sensors, databases, and external APIs are examples of these sources.
-
Data Preparation Tools:
- Identify and apply tools for data cleaning, preprocessing, and transformation based on the data sources.
- To prepare data for ingestion into HDFS (e.g., CSV, JSON), use technologies such as data cleaning scripts, ETL pipelines, or data integration platforms.
-
Data Ingestion Mechanisms:
- Implement effective data ingestion techniques for moving data from multiple sources into HDFS.
- For data ingestion, use Hadoop commands such as hadoop fs -copyFromLocal, data loading tools, or custom scripts.
-
Extraction and collection of data:
- Collect data from numerous sources to create a complete dataset that includes columns like state, district, market, commodity, variety, arrival date, min_price, max_price, and modal_price.
-
Loading Data into HDFS: Load data into HDFS, which is a distributed file system with a master-worker design.
-
Hive Database Configuration:
- Hive databases are used to structure and manage data.
- To facilitate data analysis, create tables and import data from HDFS into Hive tables.
-
HiveQL Data Analysis:
- Use HiveQL commands to do data analysis activities such as finding the top agricultural states by sales or the states with the lowest commodity prices.
- These inquiries will provide useful information about agricultural trends.
Final Output
In the final output of the Agricultural Data Analysis using Hadoop project, you can present your findings through visualizations, reports, or actionable insights like state-wise analysis. You can interpret the results to provide recommendations for improving farming practices.
Requirements
- Hadoop Cluster: This project requires a Hadoop cluster. It is made up of several nodes, including the NameNode, DataNode, ResourceManager, and NodeManager. Hadoop effectively handles distributed storage (HDFS) and data processing (MapReduce). Ensure that Hadoop is installed and configured correctly on your cluster.
- JDK (Java Development Kit): Hadoop relies heavily on Java to write MapReduce tasks and manage the cluster. Install and configure a suitable version of the JDK on all nodes in your Hadoop cluster.
- Hive: Hive is essential for storing and querying structured data. It gives Hadoop an SQL-like interface. Install Hive on your cluster and configure it to operate with Hadoop effortlessly.
- Sources of data: You'll need access to a variety of agricultural data sources, including meteorological data, soil quality information, crop production statistics, and any other pertinent information. Sensors, databases, and external APIs are examples of these sources.
- Tools for Data Preparation: Depending on your data sources, you may require tools to clean, preprocess, and transform data into acceptable forms for ingestion into HDFS (e.g., CSV, JSON). These technologies might include data cleaning scripts, ETL (Extract, Transform, Load) pipelines, or data integration platforms.
- Methods of Data Ingestion: Implement mechanisms for transferring data to HDFS from multiple sources. This might entail utilising Hadoop commands, data loading tools, or custom scripts.
Agricultural Data Analysis Using Hadoop
1. Data Extraction and Collection
The central objective of data extraction and collection is to gather agricultural data from diverse sources, ensuring that it is accurate, relevant, and comprehensive. The rationale behind this effort is the scarcity of dependable and comprehensive data in the realm of agriculture. This scarcity has hindered the ability to derive meaningful insights and make data-driven decisions, which are crucial for the improvement and sustainability of agricultural practices.
Data Sources: Data extraction and collection involve sourcing information from various channels, including but not limited to meteorological data, soil quality indicators, crop production statistics, and other pertinent agricultural metrics. These data sources can encompass a wide range of origins, such as weather monitoring stations, soil quality measurement devices, government databases, agricultural research institutions, and even external data providers or APIs. The diversity of data sources enriches the dataset and enhances its utility.
We can collect agricultural data from the following sources:
- Kaggle: It contains the data for predicting crop yield of the 10 most consumed crops in the world
- Agricultural datasets of India: https://indiadataportal.com/datasets-page
- UN Data on Agriculture and Rural Development of India: The information given here includes metrics of agricultural inputs, outputs, and productivity gathered by the Food and Agriculture Organisation of the United Nations.
Typically, you would use Spark's DataFrame API to collect data from a source and save it as a DataFrame in Apache Spark. Here are some basic Spark scripts that show how to read data from several sources and generate a DataFrame for agricultural data.
The project collects, collates, and curates essential data related to agriculture, offering a holistic view of crop production, market dynamics, and pricing trends. It empowers farmers, policymakers, researchers, and stakeholders across the agriculture value chain with the necessary information for sustainable practices.
Below is what a sample agricultural dataset might look like and how it represents an opportunity to leverage data as a catalyst for positive change in Indian agriculture, paving the way for a prosperous and sustainable future in the sector.
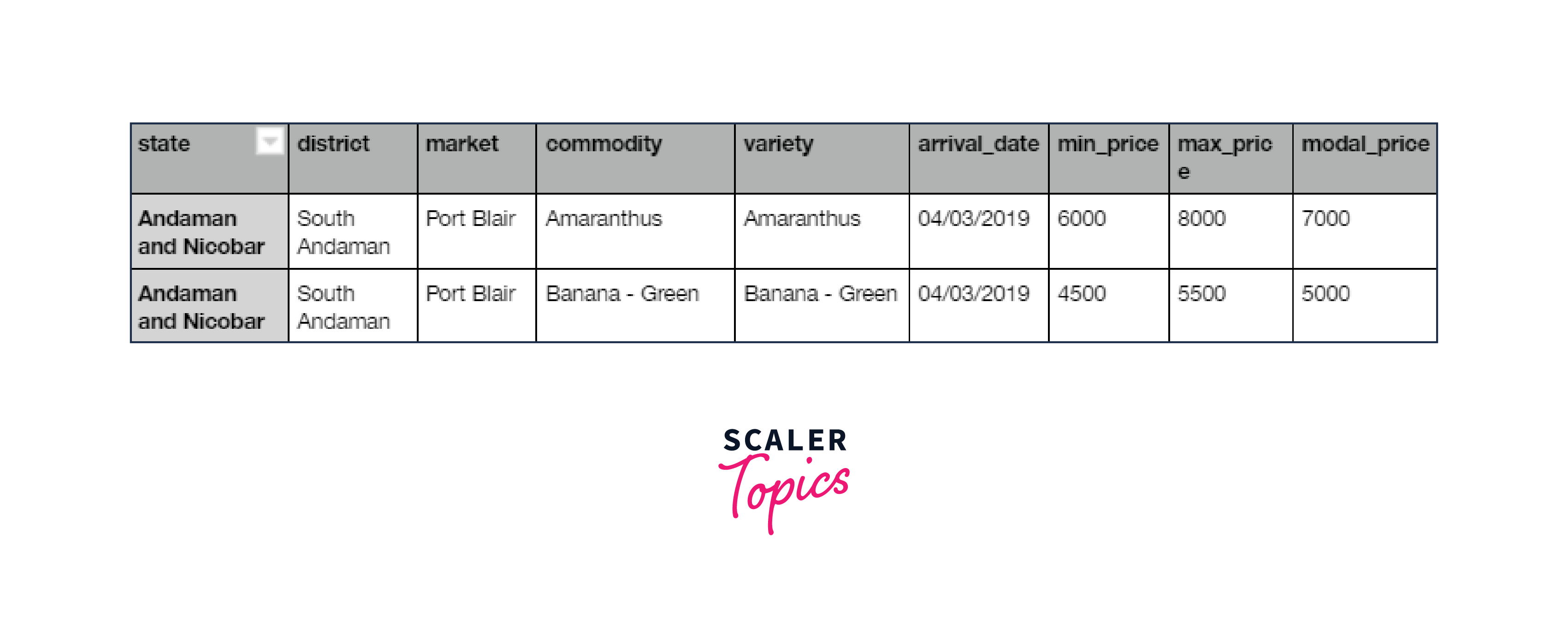
Sample Columns:
- state: Name of states
- district: Name of the district in the corresponding state
- market: Name of the market where they sell their crops
- commodity: The crop they grow
- variety: The variety of the commodity
- arrival_date: Arrival date in the market
- min_price: Minimum price of the product
- max_price: Maximum price of the product
- modal_price: Modal price is the two-month average market price for a certain commodity
2. Architecture
Creating a data model entails creating the dimensions and fact table depending on the columns supplied. In this scenario, a simple data model for agricultural data with dimensions and a fact table may be created. Here's an example of a conceptual representation:
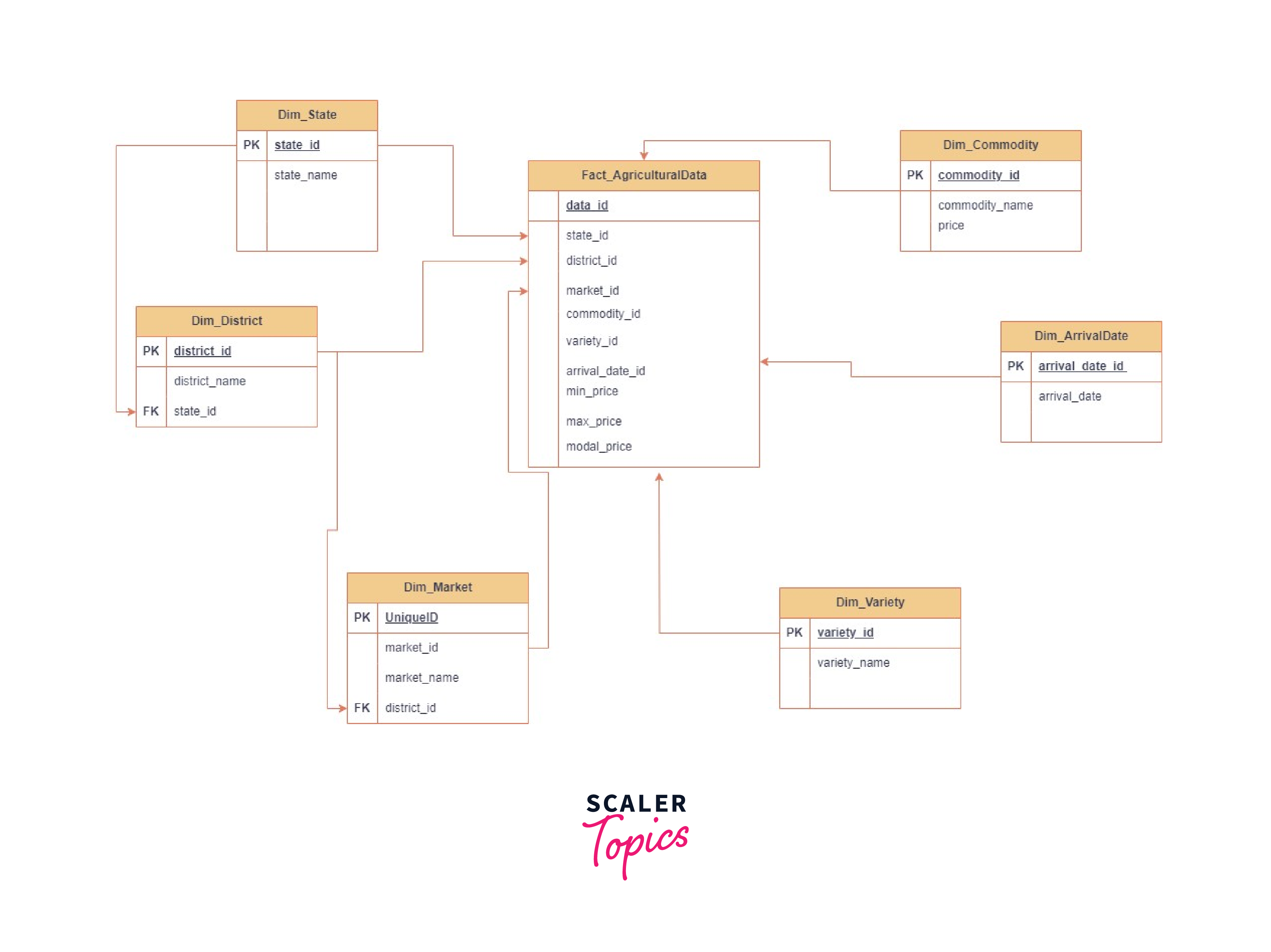
The fact table Fact_AgriculturalData contains the prices (min_price, max_price, modal_price) as well as foreign keys referring to the dimension tables. It links all aspects of the actual agricultural data.
3. Load Data to HDFS
Data storage in an HDFS provides a number of benefits like scalability, reliability, and more.
Scalability:
- HDFS is designed to handle massive amounts of data. It can easily scale out to accommodate growing datasets, making it an ideal choice for storing large volumes of agricultural data.
- As agricultural data collection increases over time, HDFS allows us to seamlessly expand storage capacity by adding more data nodes to the cluster.
Data Replication for Reliability:
- HDFS employs data replication for fault tolerance. Data is replicated across multiple nodes, ensuring that even if a node fails, the data remains accessible from the replicas.
- This redundancy enhances data reliability, a critical factor when dealing with essential agricultural data that needs to be preserved and protected.
Data Distribution:
- HDFS distributes data across the cluster, facilitating parallel processing.
- This distribution accelerates data retrieval and analysis, making it efficient for data-intensive agricultural tasks.
Here is the Hadoop command to load the data from a local path into HDFS:
Hive Databases
In Hive, databases are used to logically group and organize tables. They provide a way to manage and access related datasets efficiently. The creation of a database is a preparatory step to defining tables within that database. Databases help in maintaining data separation and organization.
Create a Table in Hive:
Load the data from HDFS to the newly created Hive Table using the command:
4. Analysis with Hive Command
We will now analyse the output of our agricultural data analysis using Hadoop project using Hive queries. These queries leverage Hive's SQL-like capabilities to extract meaningful insights from the agricultural data, aiding decision-making and understanding trends within the agriculture ecosystem.
- Top 5 agricultural states having the highest sale
- Cheapest commodity prices per state
- Market performance
5. Results
Finally, you can present your findings through visualizations, reports, or actionable insights. You can further interpret the results to provide recommendations for improving farming practices.
Below are some of the sample visualizations and insights you can gain from this agricultural data analysis using Hadoop application:
Let's look at the distribution of the most crop-producing states based on this data.
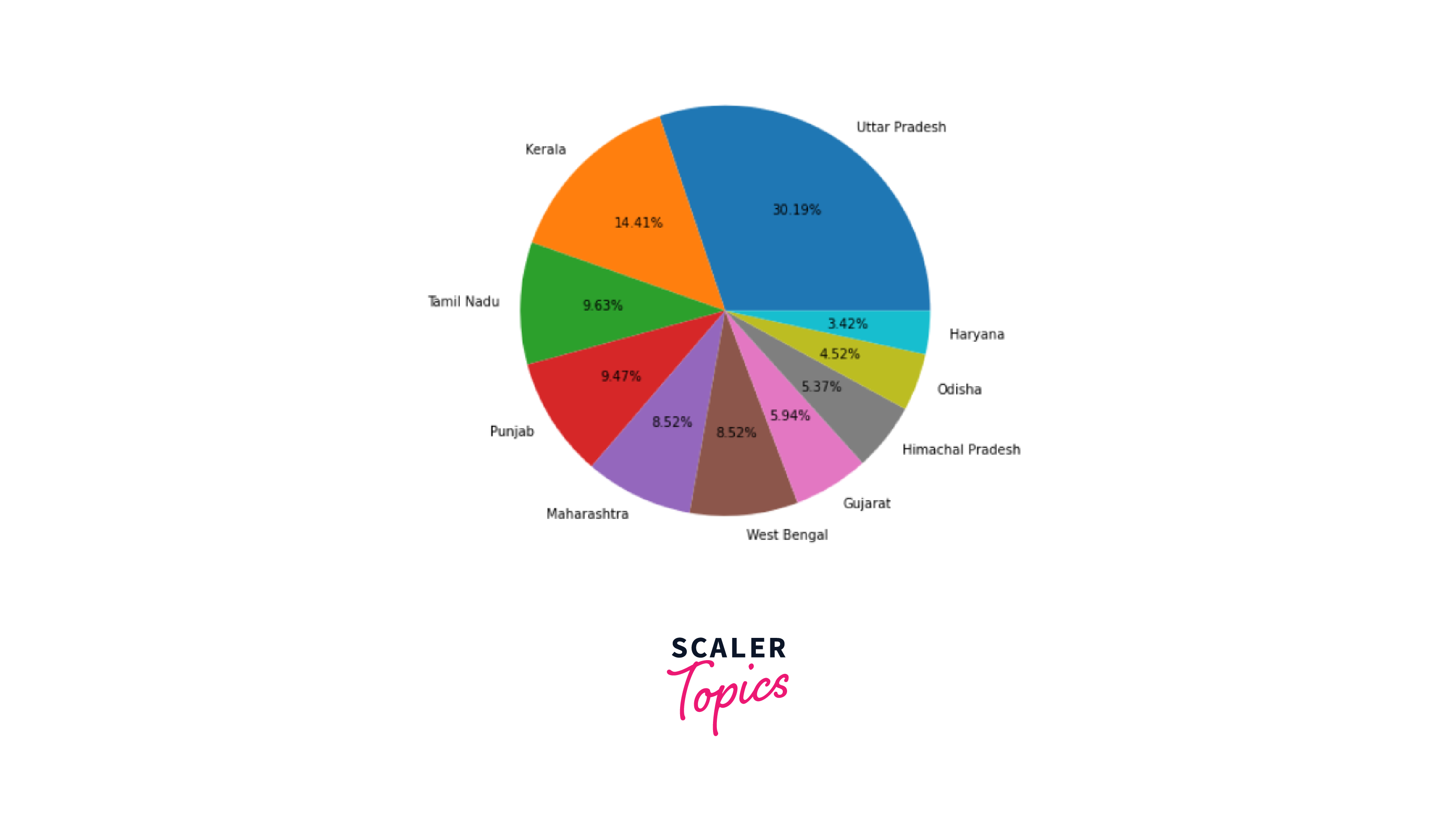
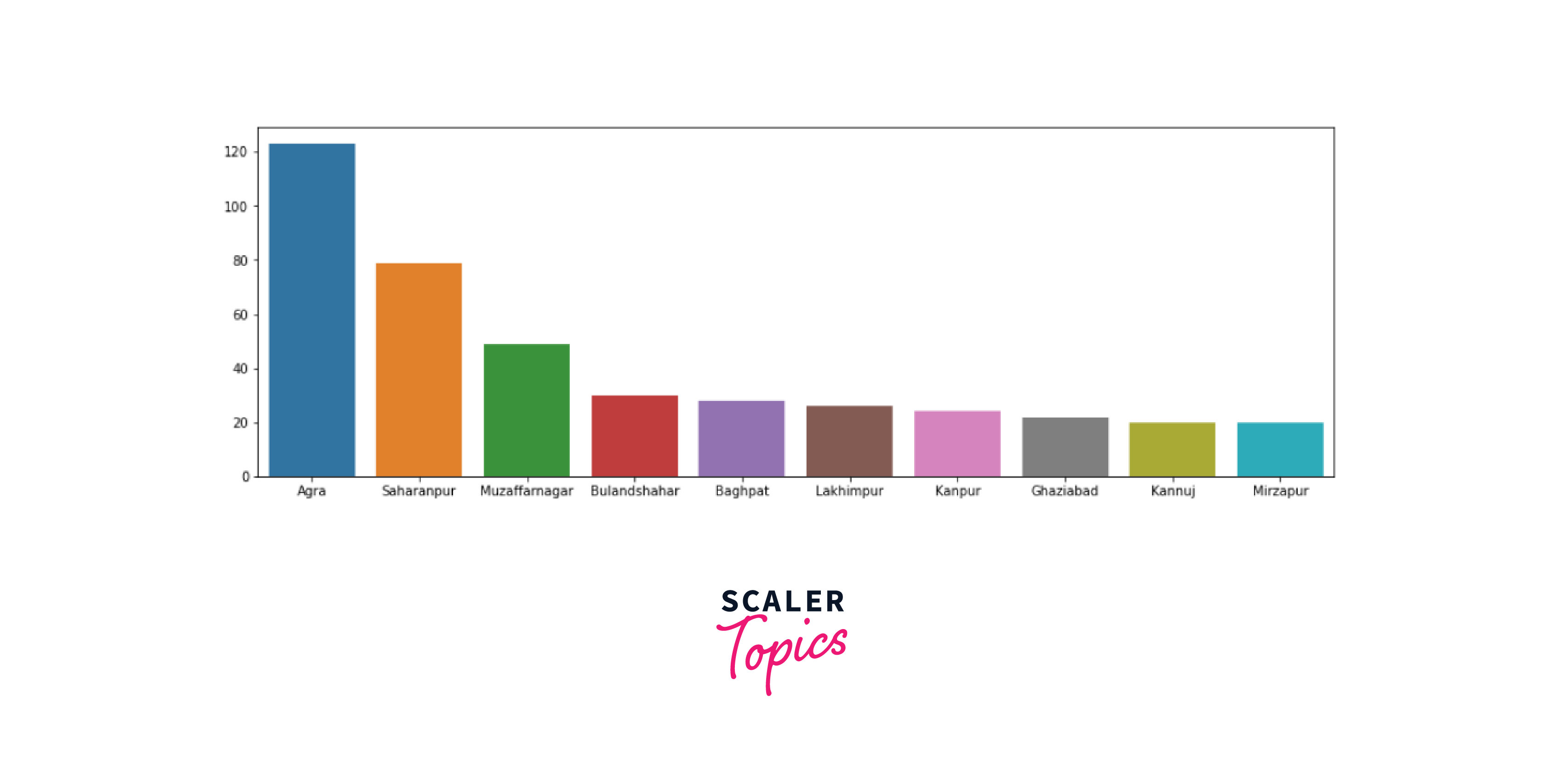
Now, let us look at the district-wise distribution of Uttar Pradesh, the state which is the most involved in agriculture.
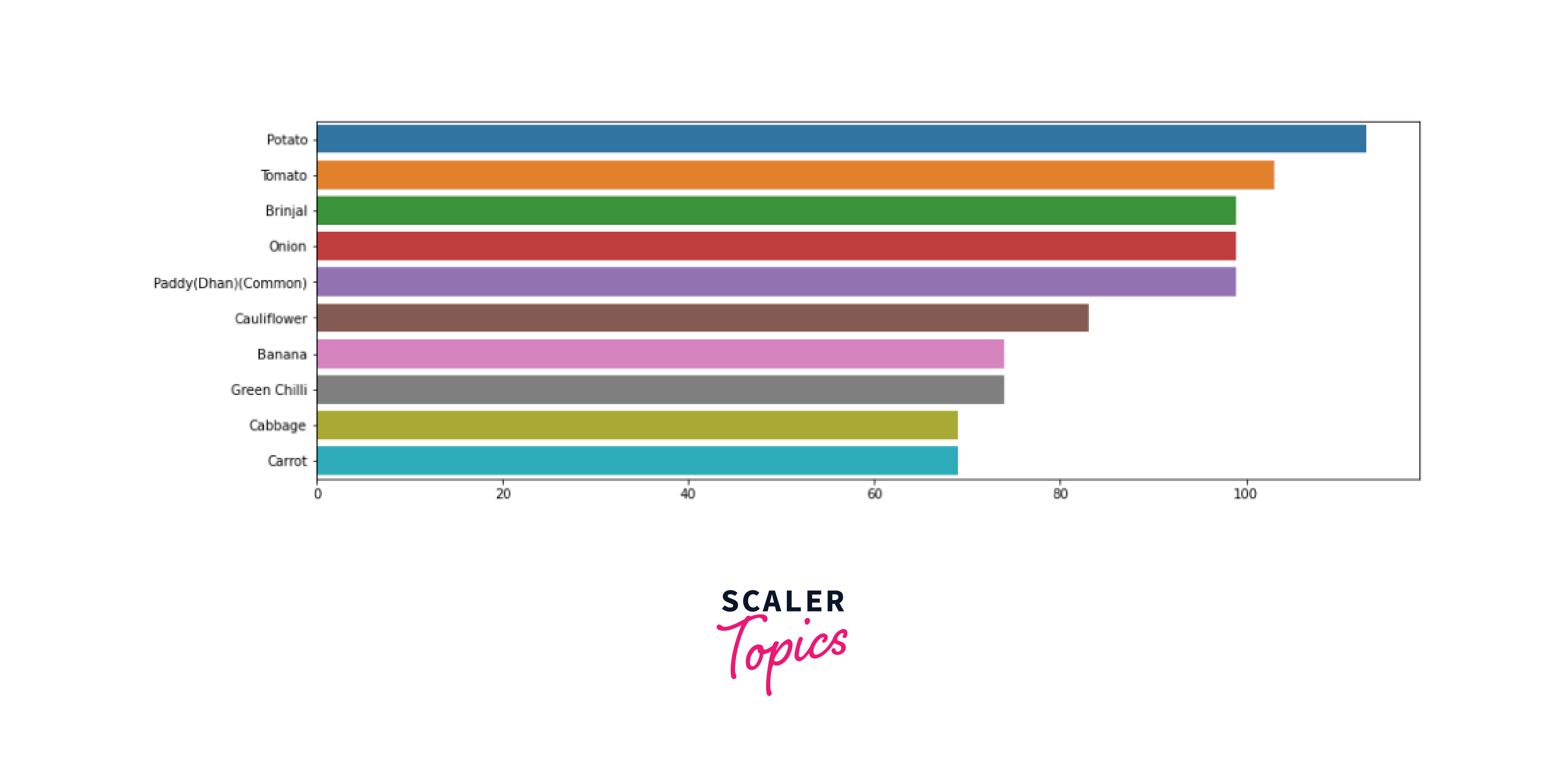
Finally, let us visualize which commodity is produced the most widely.
Conclusion
- The Agricultural Data Analysis using Hadoop project focuses on how to provide accurate analysis for the agriculture ecosystem.
- It relies on a well-configured Hadoop cluster with components like HDFS and MapReduce for distributed storage and data processing.
- It also requires the integration of Hive for structured data storage and HiveQL queries for analysis.
- Access to various agricultural data sources, including meteorological data, soil quality metrics, and crop production statistics, is essential.
- Data preparation involves the use of data cleaning, preprocessing, and transformation tools, followed by efficient data ingestion methods.
- The project's core objective is to provide insights into Indian agriculture, utilizing data from attributes such as geography, commodity, variety, and price range.
- Visualizations, reports, and actionable insights are presented to support data-driven decisions and enhance agricultural practices.