Big Data Cybersecurity
Overview
The project, Big Data Cybersecurity application, focuses on strengthening digital security using advanced data analysis techniques. Our program will examine large datasets using sophisticated tools like PySpark, PyFlink, Hive, and HDFS to discover and prevent cyber risks. We intend to improve cybersecurity measures in a streamlined and effective manner by leveraging the processing capabilities of Python libraries and distributed storage provided by HDFS. Using the power of Big Data technology, this marks a critical step in protecting sensitive information from cyber threats.
What are We Building
The security of sensitive data and networks is critical in today's society. Big Data Cybersecurity has become an important area because of the ever-increasing volume of data created. This section will discuss what we're working on in the Big Data Cybersecurity application. We'll first review the prerequisites and the technique used to construct it and then show you the finished product.
Prerequisites
To embark on this Big Data Cybersecurity journey, it's crucial to have a solid understanding of the following key topics, which are fundamental to the project:
- Big Data Fundamentals: Get familiar with the core concepts of Big Data, including its characteristics, challenges, and opportunities here.
- Python Programming: Python will be our primary language. Make sure you are comfortable with Python programming. To learn more about it, click here.
- PySpark and PyFlink: These are essential Big Data processing frameworks in Python. To master the basics of Spark for data manipulation and processing, click here.
- Hive: Understand how to use Hive for data warehousing and querying within the Big Data ecosystem here.
- HDFS (Hadoop Distributed File System): Learn about HDFS, the storage backbone for Big Data applications, and the Hadoop ecosystem here.
- Cybersecurity Basics: Familiarize yourself with cybersecurity fundamentals, including threats, vulnerabilities, and risk assessment here.
How are We Going to Build This?
Now that we've covered the prerequisites, let's outline our approach for building the Big Data Cybersecurity application:
- Data Collection: We will gather security-related data from various sources, including network logs, system logs, and application logs.
- Data Ingestion: Using PySpark and PyFlink, we'll ingest and preprocess the data, making it suitable for analysis.
- Data Storage: Store the processed data in HDFS for efficient storage and retrieval.
- Data Analysis: Utilize Hive for querying and analyzing the stored data to identify potential security threats and anomalies.
- Alert Generation: Implement algorithms to detect suspicious activities and generate real-time alerts.
- Visualization: Create insightful visualizations using libraries like Matplotlib or Seaborn to help cybersecurity analysts understand the data better.
- Reporting: Develop automated reports summarizing security incidents and trends.
Final Output
Our final output will be a strong Big Data Cybersecurity application that can:
- Constantly monitor and analyze enormous amounts of data
- Detect and respond in real time to security risks
- Provide useful insights and reports to aid decision-making
The final result will be a collection of intriguing visualizations, statistics, and conclusions that provide a comprehensive understanding of the dataset's patterns and trends. The finished result should be user-friendly, allowing stakeholders, researchers, or the general public to gain relevant insights from the data without requiring advanced technical expertise. It should help people make informed decisions and improve their understanding of the data.
Requirements
Developing an efficient Big Data Cybersecurity application involves careful planning and a thorough grasp of the technologies and libraries involved. We will focus on using popular Python libraries like PySpark, PyFlink, Hive, HDFS, and others to guarantee successful Big Data cybersecurity.
1. Python
Python serves as the foundational programming language for our Big Data Cybersecurity application. Python offers a versatile and user-friendly environment for developing and integrating various cybersecurity components.
2. PySpark
PySpark is a Python library for Apache Spark, a powerful Big Data processing framework. PySpark enables distributed data processing and provides essential data manipulation and analysis functions for identifying security threats.
3. PyFlink
PyFlink is the Python API for Apache Flink, an open-source stream processing framework. PyFlink aids in real-time data processing and analytics, allowing for swift detection and response to cyber threats as they occur.
4. Hive
Hive is a data warehousing and SQL-like query language tool built on top of Hadoop. Hive simplifies data querying and allows for the creation of structured reports and dashboards, aiding in cybersecurity analytics.
5. Hadoop Distributed File System (HDFS)
HDFS is the primary storage system used in Hadoop, designed for storing and managing large datasets. HDFS provides reliable storage for the vast amounts of data generated in cybersecurity operations, ensuring data integrity and availability.
6. Kafka
Apache Kafka is a distributed event streaming platform. Kafka facilitates the real-time collection and processing of security-related events and logs.
7. Elasticsearch and Kibana
Elasticsearch is a search and analytics engine, while Kibana is a data visualization tool. Together, they enable efficient storage, retrieval, and visualization of cybersecurity data, aiding in threat analysis.
8. Python Libraries
Python Libraries like NumPy, Pandas and Matplotlib offer essential data manipulation, analysis, and visualization capabilities. They enhance the data analysis and reporting aspects of our cybersecurity application.
Building a Big Data Cybersecurity application necessitates a well-defined set of prerequisites as mentioned above. Organizations can respond to cyber threats with more accuracy and agility when these components are properly linked. By using the power of these technologies, you can build a strong cybersecurity system capable of protecting your data in the Big Data age.
Big Data Cybersecurity
In this section, we'll lead you through creating a Big Data Cybersecurity application utilizing tools like PySpark, PyFlink, Hive, and HDFS. We'll divide the project into simple segments, ensuring each phase is fully understood.
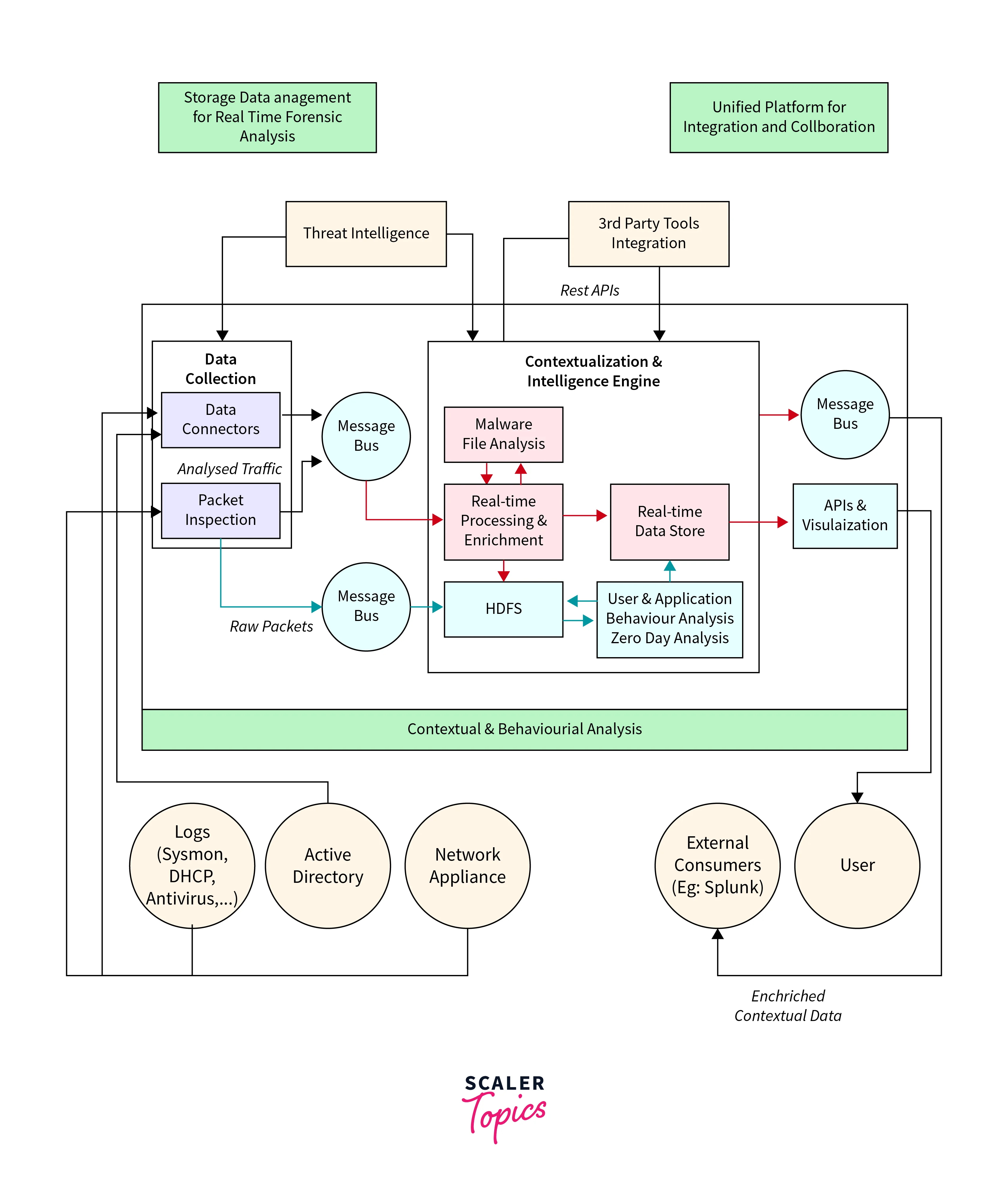
Data Extraction and Collection
Begin by collecting and extracting data on cybersecurity risks. Python modules such as PySpark and PyFlink may be used to automate data collection from various sources such as log files, network traffic, and security event logs. These libraries provide powerful data processing capabilities, allowing for fast data extraction.
Architecture
Create a resilient infrastructure that can handle the large volume of cybersecurity data. To handle the scale, apply distributed computing methods. To centralize data storage, consider creating a data lake architecture. Use systems such as Apache Hadoop and HDFS for distributed storage and processing.
Load Data to HDFS
Now that the infrastructure is in place, the extracted data can be loaded into HDFS. Due to its fault tolerance and scalability, HDFS is perfect for storing massive amounts of cybersecurity data. To upload data quickly, use Hadoop's command-line facilities.
Hive Databases
To arrange and organize your data, create Hive databases and tables. For quicker query performance, define schemas and optimize data storage formats such as ORC or Parquet.
Analysis with Hive Command
It's time to leverage Hive's SQL-like syntax to perform data analysis. Write Hive queries to extract meaningful insights from your cybersecurity data. Utilize its integration with PySpark or PyFlink for more complex analytics, including machine learning algorithms for anomaly detection.
Results
Finally, present your results. Visualize key cybersecurity metrics and insights using Matplotlib or Seaborn in Python. Generate reports and dashboards to provide actionable information to cybersecurity professionals.
Maintain good documentation and version control of your codebase throughout this project. Collaboration with cybersecurity professionals is essential for understanding the domain's requirements and complexities. Monitor and fine-tune your application regularly to respond to changing threats.
By taking these little steps, you'll be on your way to creating a solid Big Data Cybersecurity application. Combining Python libraries with Big Data technologies enables you to manage massive volumes of data, properly analyze it, and strengthen your organization's cybersecurity defense system.
Testing
Testing is critical to ensure any software product's reliability, security, and performance, and Big Data Cybersecurity is no different. This section will look at the most important testing components for such apps, emphasizing the methods needed to ensure the application's resilience.
-
Unit Testing Unit testing is the bedrock of every testing method. PySpark and PyFlink are useful frameworks for testing specific components and functions in Big Data Cybersecurity applications. You may check data transformations, analytics methods, and data processing processes by developing test cases in Python. These unit tests guarantee that each piece of code functions as intended before integrating them into the larger application.
-
Integration Testing Integration testing examines how various application components interact with one another. Hive, a data warehousing tool, is useful during this stage. You can create test environments to simulate real-world scenarios and ensure that data pipelines, warehousing, and SQL queries work as expected. It assures that your Big Data Cybersecurity application can efficiently handle complicated data processes.
-
End-to-end HDFS Testing HDFS is critical in Big Data applications. End-to-end testing guarantees that the data intake, storage, and retrieval procedures work properly. It entails loading sample data into HDFS, doing data analytics, and ensuring the application returns accurate findings. This stage assures the consistency and reliability of the data.
-
Performance Testing Massive datasets must be handled efficiently by Big Data applications. The application's capacity to manage severe workloads is evaluated using performance testing tools such as Apache JMeter or custom scripts. It monitors response times, throughput, and resource utilization to discover bottlenecks and improve application performance.
-
Security Testing Security is critical in the field of Big Data Cybersecurity. Vulnerabilities, data breaches, and unauthorized access points are all investigated during security testing. Tools such as OWASP ZAP and Nessus assist in identifying possible security problems, ensuring that sensitive information is kept secure.
-
Scalability Testing Your Big Data Cybersecurity application must expand to meet rising needs as the data grows. Scalability testing evaluates an application's capacity to manage increased data volumes and user loads. It aids in the fine-tuning of infrastructure and setup for maximum performance.
The testing of your Big Data Cybersecurity application assures its reliability, security, and performance. Thorough testing is the foundation of a successful Big Data Cybersecurity solution, giving the assurance required to safeguard sensitive data in the digital era.
What’s next
In the ever-changing field of cybersecurity, getting ahead of attacks is critical. You may arm your application with cutting-edge capabilities to boost your defense against cyber threats by leveraging the power of big data technologies. Look at what's next in Big Data Cybersecurity and the features you can apply yourself.
- Real-time Threat Detection Utilise PySpark and PyFlink's real-time processing capabilities to examine incoming data streams for possible risks. You may build your machine learning models to detect abnormalities and provide notifications when suspicious behavior is discovered.
- Behavior Analytics Using Hive's past data, implement behavioral analytics. You can spot deviations and take proactive measures by analyzing user behavior trends to mitigate insider threats. This approach helps in understanding normal user activities and identifying outliers.
- Predictive Analysis Use machine learning libraries like scikit-learn and TensorFlow to forecast future cyber risks based on previous data trends. You may predict future weaknesses and take preventive measures by training your models on a large dataset.
- Automated Incident Response Using PySpark and PyFlink, implement automated incident response. When a threat is found, automatic steps such as isolating impacted systems, blocking malicious IP addresses, or contacting security personnel should be taken.
- Compliance Reporting Easily generate compliance reports by searching and analyzing Hive data. This aids in establishing compliance with regulatory regulations, which is an important part of modern cybersecurity.
- User and Entity Behavior Analytics (UEBA) UEBA tools can detect odd behavior among users and entities. This sophisticated functionality aids in the detection of insider threats and compromised accounts.
- Threat Hunting Empower your cybersecurity team with powerful search capabilities using big data tools. Allow them to do proactive threat hunting by searching massive databases in near real-time for hidden risks.
- Continuous Improvement Incorporate a feedback loop into your application. Analyze the efficiency of your security measures and fine-tune your models and rules on a regular basis to respond to emerging threats.
To summarise, the future of Big Data Cybersecurity is full of intriguing possibilities. While technically complex, these capabilities are doable with the correct skills and dedication to remain ahead in the ever-changing cybersecurity world.
Conclusion
- Due to the distributed computing powers of PySpark and PyFlink, we can process large amounts of data effectively. This enables our cybersecurity application to filter through massive real-time information quickly and efficiently identify risks.
- Using HDFS for storage and data management provides unprecedented scalability. As our application expands, HDFS can easily manage the flood of data, ensuring that our system stays flexible to changing cybersecurity risks.
- We can do extensive data enrichment and analysis by integrating Hive into our application stack. This gives us vital insights into possible risks, allowing us to handle security problems proactively.
- Our selection of Big Data technologies and libraries assures that our cybersecurity application runs in real time. This capacity to respond quickly is critical in recognizing and mitigating security breaches as they occur, averting possible data compromises.