Cricket Match Analysis Using Hadoop
Overview
Our 'Cricket Match Analysis Using Hadoop and Python' project revolutionizes data-driven sports analysis. Combining Hadoop's distributed computing with Python's flexible modules like 'PyFlink' and 'PySpark,' we extract valuable insights from cricket matches. Our goal is to provide cricket specialists, experts, and teams with in-depth player performance, team strategies, and match dynamics analysis, potentially transforming the way we perceive and analyze cricket.
What are We Building?
Let us see what are we going to build and how.
Prerequisites
Before diving into this exciting project, let's ensure we have a strong foundation. Here are the major topics and their associated articles from Scaler that you should be familiar with:
- Hadoop Ecosystem.
- Python Programming
- PySpark and PyFlink
- Data Collection
- Data Cleaning and Preprocessing
- Data Visualization
How are We Going to Build This?
- Data Collection
- Data Preprocessing
- Hadoop Integration
- PySpark/PyFlink Implementation
Final Output
To summarize, developing a Cricket Match Analysis system using Hadoop and Python is a fascinating endeavor that combines big data processing with sophisticated analytics. By following the steps given and mastering the requirements, you will be on your way to uncovering a treasure trove of cricket knowledge.
Requirements
Examining a Cricket Match Using Hadoop and Python is an intriguing project that uses big data and sophisticated analytics to get important insights into cricket games.
1. Python Libraries and Modules:
- Python 3.x
- NumPy
- Pandas
- Matplotlib and Seaborn
- PySpark
- Pyflink
2. Hadoop Framework and Related Libraries:
- Hadoop Distributed File System (HDFS)
- MapReduce
- Hive
- HBase
- YARN
- Sqoop
- Oozie
Cricket Match Analysis Using Hadoop
Let’s get started with developing the application.
Data Extraction and Collection
The initial step in our cricket match analysis is collecting crucial data from various cricket statistics websites or APIs, including player stats, match details, and ball-by-ball data. Utilize Python libraries like Pandas and web scraping tools for this purpose. Make sure to clean and organize the data before moving forward.
Architecture
A Hadoop cluster can be installed on-premises or in the cloud using services like Amazon EMR or Google Dataprep. The design should provide scalability to manage enormous amounts of cricket data properly.
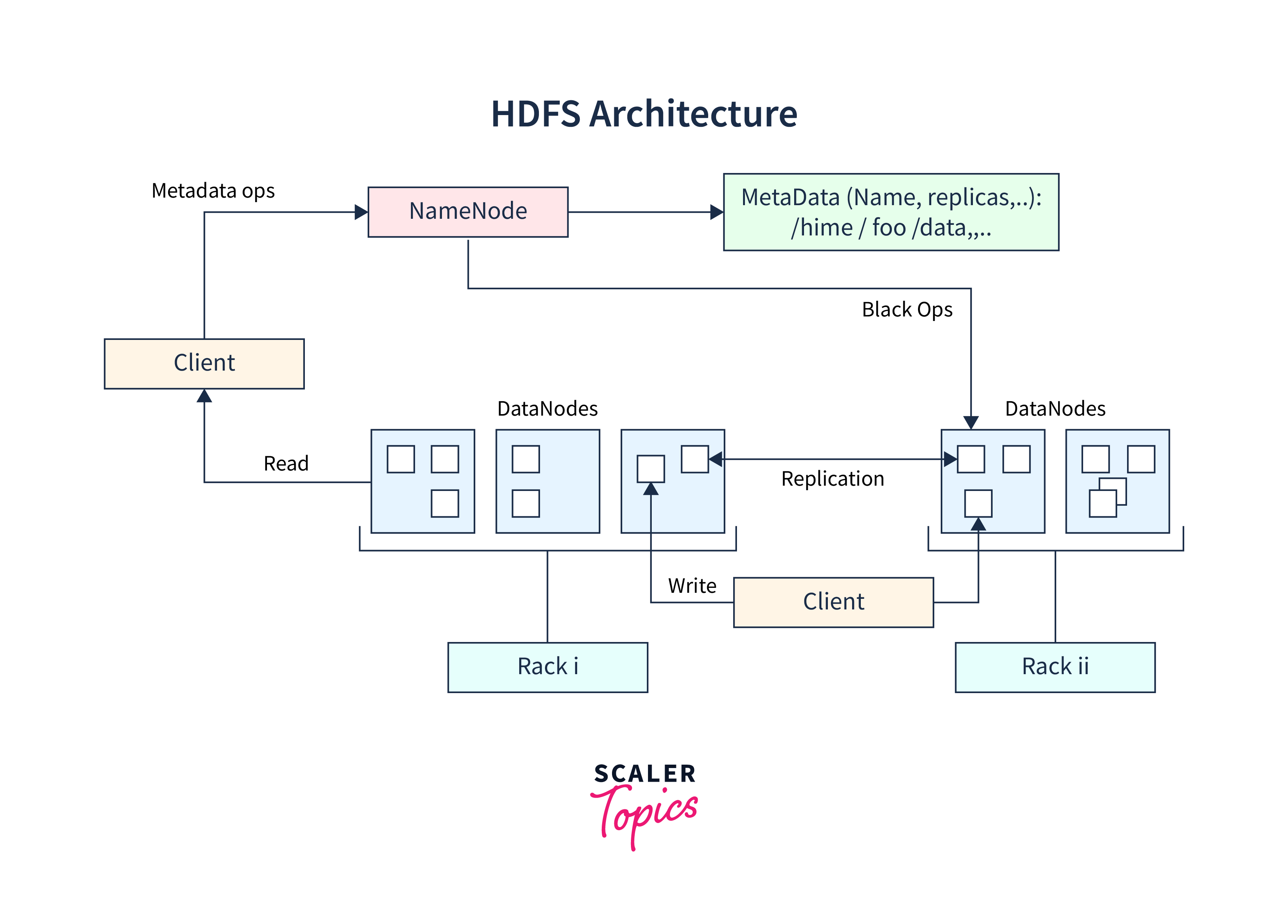
Load Data to HDFS
Now that your Hadoop cluster is running loading the cricket data into HDFS is time. HDFS commands such as 'hadoop fs' will come in helpful here. Use folders and file formats to ensure correct data organization. This is an important step since it prepares your data for distributed processing.
Explanation: This code uses the subprocess module to execute Hadoop's command-line tools. It transfers the previously gathered and cleaned cricket data to the HDFS directory, making it available for distributed processing.
Analysis with MapReduce APIs
Python has tools like PySpark that make dealing with Hadoop's MapReduce easier. To process the cricket data, write Map and Reduce routines. You can, for example, compute player averages and team performance measures or discover player trends. Use PySpark's DataFrame API for operations.
Results
Let's finally visualize and analyze the findings from your cricket match analysis. Python packages such as Matplotlib and Seaborn can assist in the creation of informative graphs and charts. Share crucial discoveries such as player rankings, team performance patterns, or data comparisons from the past. These observations might benefit cricket fans, coaches, and even team strategists.
In conclusion, using Hadoop and Python to analyze cricket matches is a fantastic technique to extract useful insights from the massive quantity of cricket data accessible today. By breaking the process down into five phases, you can take a more systematic approach to harnessing the potential of big data in cricket.
Testing
Testing is a crucial phase in any data analysis project to ensure the accuracy, reliability, and validity of your results.
- Testing Objectives and Criteria: This involves outlining what you aim to achieve through testing, such as verifying recommendation accuracy, ensuring data consistency, and assessing system performance and scalability.
- Preparing Test Data: Generate or collect representative test data that mirrors real-world scenarios. This data should encompass various user profiles, item interactions, and edge cases to assess recommendation quality comprehensively.
- Verifying Data Consistency: Cross-verify the analysis results against the original data sources or ground truth data to ensure data consistency.
- Testing Performance and Scalability: Assess the system’s performance and scalability by subjecting it to different loads, such as varying user volumes and concurrent requests.
What’s next
Now that we've successfully constructed a Cricket Match Analysis application with Hadoop and Python let's look at what's next in our quest to improve this application. Below, we'll review some extra features and enhancements that readers may use to make the program more effective and informative.
1. Real-time Data Streaming
Consider adding real-time data streaming to keep up with ongoing cricket matches. You can use technologies such as Apache Kafka or Apache Flink to gather and handle live match data. Real-time information on player statistics, results, and performance can give vital insights during live matches.
2. Predictive Analytics
Implement predictive analytics to take your analysis to the next level. Use machine learning algorithms to forecast match results, individual performances, or even the outcome of the next ball. Python libraries like Scikit-Learn or TensorFlow can be valuable here.
3. Advanced Visualizations
Enhance the visualization of your analysis results. Implement more advanced data visualization techniques using libraries like Plotly or Tableau to create interactive charts, heatmaps, and dashboards. These visuals can make it easier to interpret and communicate your insights.
Conclusion
- Data Extraction and Collection: Accurate cricket analysis is built on solid data gathering and cleansing.
- Architecture: A well-structured Hadoop architecture ensures scalability for handling extensive cricket datasets.
- Load Data to HDFS: Efficient data loading to HDFS is critical for distributed analysis.
- Analysis with MapReduce APIs: Leveraging PySpark for analysis unlocks the power of distributed computing for cricket insights.
- Results: Effective visualization and interpretation of results provide actionable insights for cricket enthusiasts and strategists.