Data with Hadoop
Overview
The open-source framework Hadoop was created for the distributed processing and storing of massive amounts of data across clusters of affordable hardware. It consists of the Hadoop Distributed File System (HDFS) for storage and the MapReduce programming model for parallel processing. Hadoop enables efficient storage and analysis of structured and unstructured data, making it a cornerstone technology in big data environments.
Storing Data in Hadoop Distributed File System (HDFS)
Storing data in Hadoop Distributed File System (HDFS) involves utilizing a distributed and fault-tolerant file storage system that can handle massive amounts of data across a cluster of commodity hardware. Here's how data is stored in HDFS:
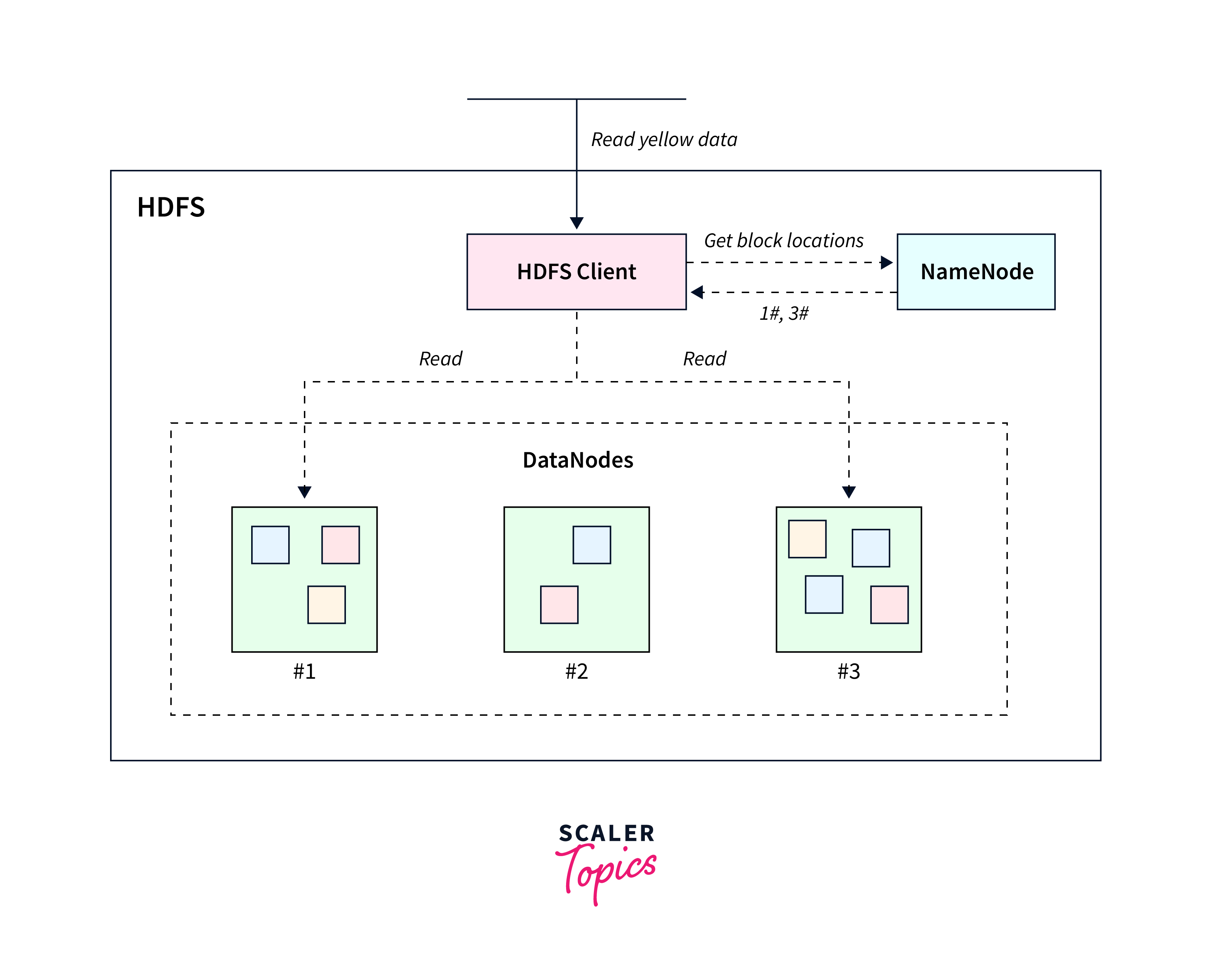
One of the key characteristics of HDFS is its approach to breaking down sizable files into smaller blocks. Typically, these blocks are of sizes like 128 MB or 256 MB. These individual blocks are then spread across the nodes present within the Hadoop cluster. This distributed storage approach offers several advantages, including efficient data management and improved data access performance.
In the context of data replication, HDFS ensures data redundancy and reliability. Each data block is replicated multiple times to ensure fault tolerance. This means that if a node or hardware failure occurs, the data remains accessible through its replicated copies. By default, HDFS replicates each block three times. These replicas are stored in different locations, with two replicas residing on one set of nodes and a third replica stored on a separate rack. This strategy enhances data availability and durability.
Storing data in HDFS provides benefits such as scalability, fault tolerance, and efficient handling of large data sets. However, HDFS is more suitable for batch processing rather than real-time data access due to its design characteristics. When working with HDFS, it's essential to consider factors like replication settings, block size, and data organization to optimize performance and reliability.
Data Ingestion into Hadoop
Data ingestion into Hadoop involves the process of bringing external data from various sources into the Hadoop ecosystem for storage, processing, and analysis. This is a critical step in making use of Hadoop's capabilities for handling large volumes of data.
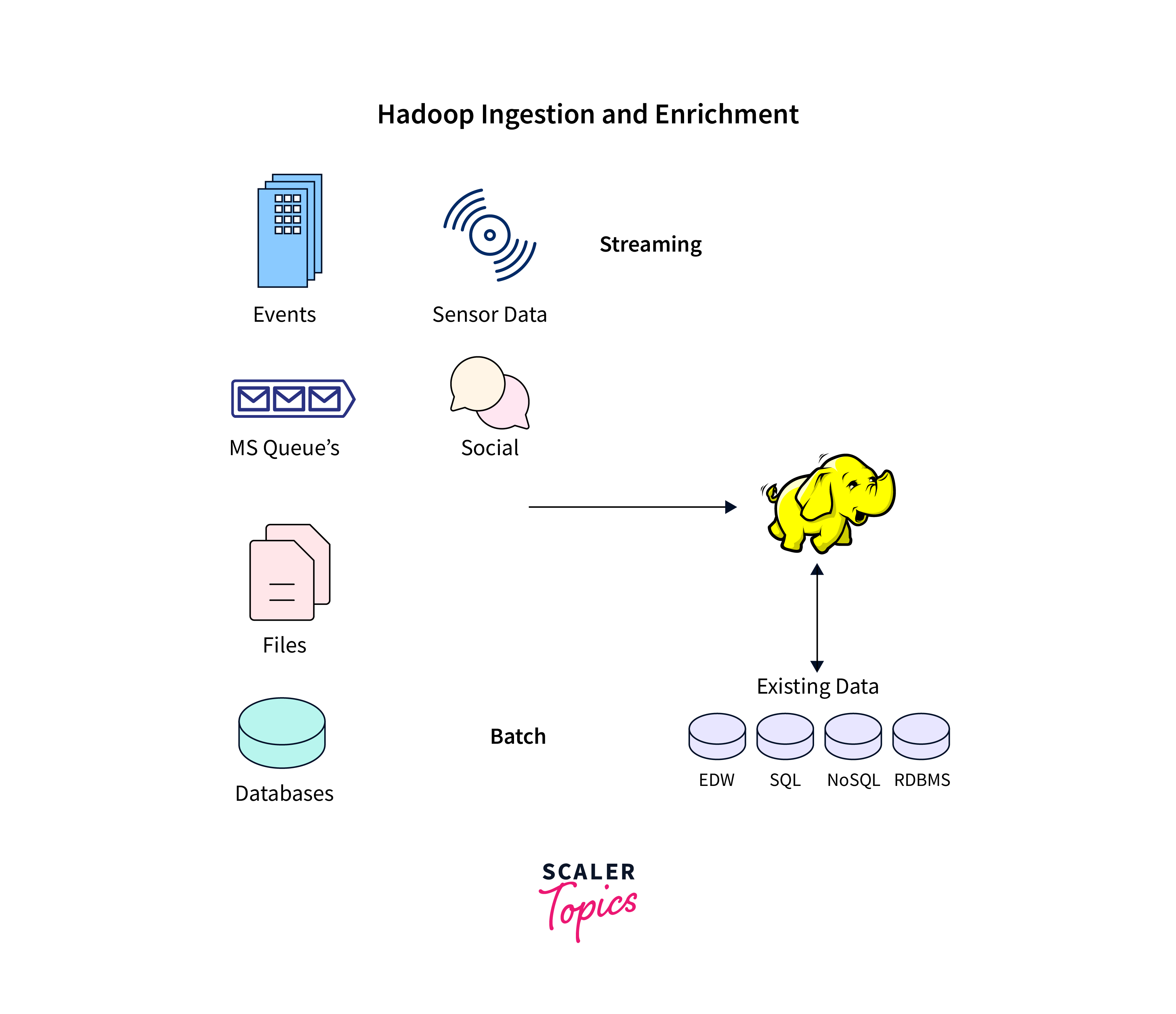
There are several methods and tools available for data ingestion into Hadoop, each tailored to specific use cases and data sources. These methods include Hadoop's own command-line tools, specialized tools like Apache Flume for efficient log data collection, Sqoop for transferring data between Hadoop and structured databases, Kafka for real-time data streaming, and Apache NiFi for designing data flows with a web-based user interface. Moreover, organizations often develop custom scripts or applications to ingest data using Hadoop APIs, providing flexibility to cater to unique requirements.
Data Processing with MapReduce
Data processing with MapReduce is a programming model and processing framework used in the Hadoop ecosystem to analyze and transform large datasets in a distributed and parallel manner.
Here's a brief overview of how MapReduce works for data processing:
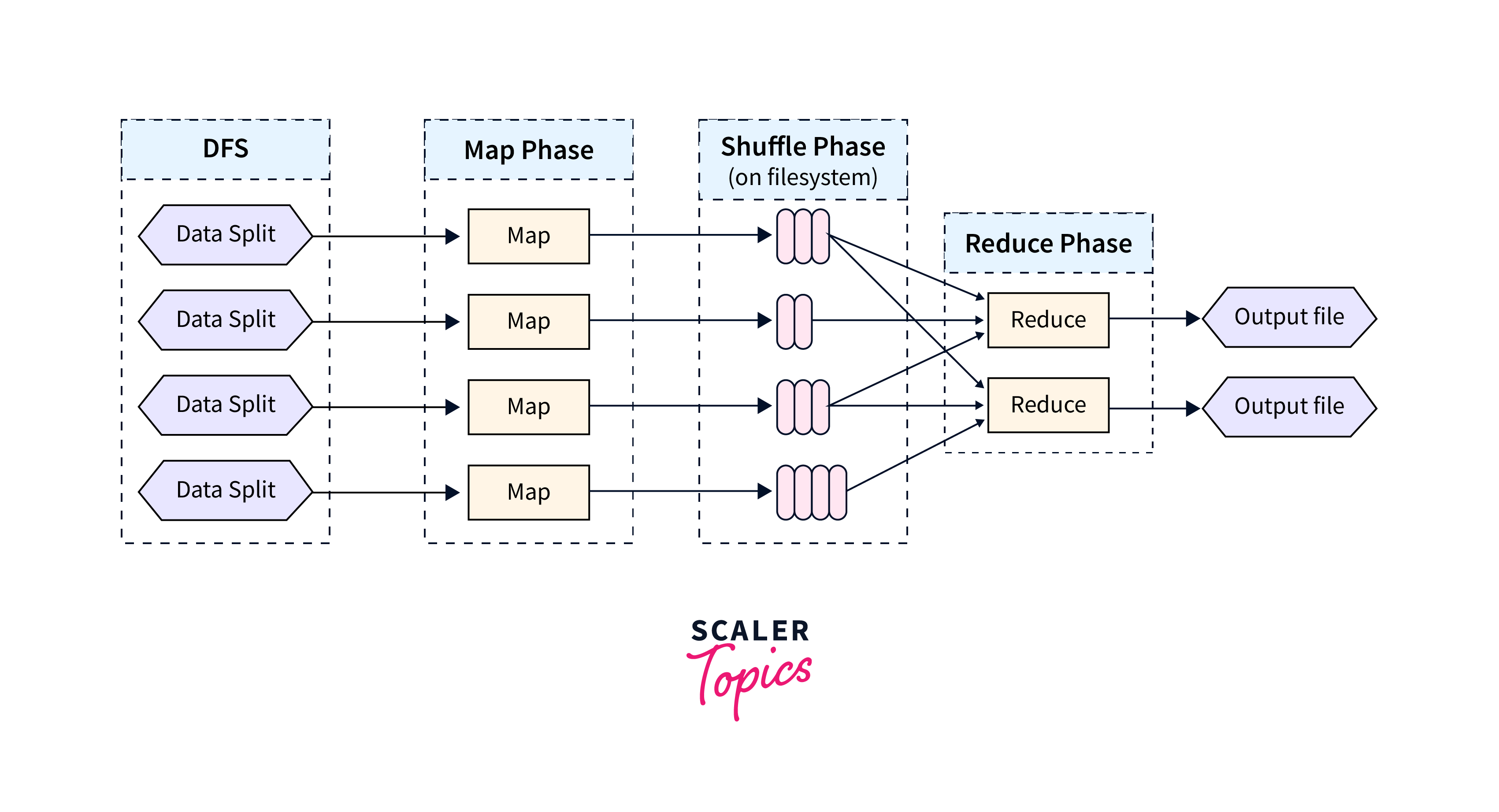
MapReduce is a programming model and processing framework designed for processing and generating large datasets in parallel across a distributed cluster. It's a core component of the Hadoop ecosystem and is widely used for batch processing and transforming data at scale. The MapReduce model consists of two main stages: the Map stage and the Reduce stage. Learn more about data processing with map reduce here.
Data Transformation with Hive
Data transformation with Hive provides a higher-level abstraction that allows users to perform data transformations and analysis using SQL-like queries, making it more accessible to those familiar with traditional relational databases.
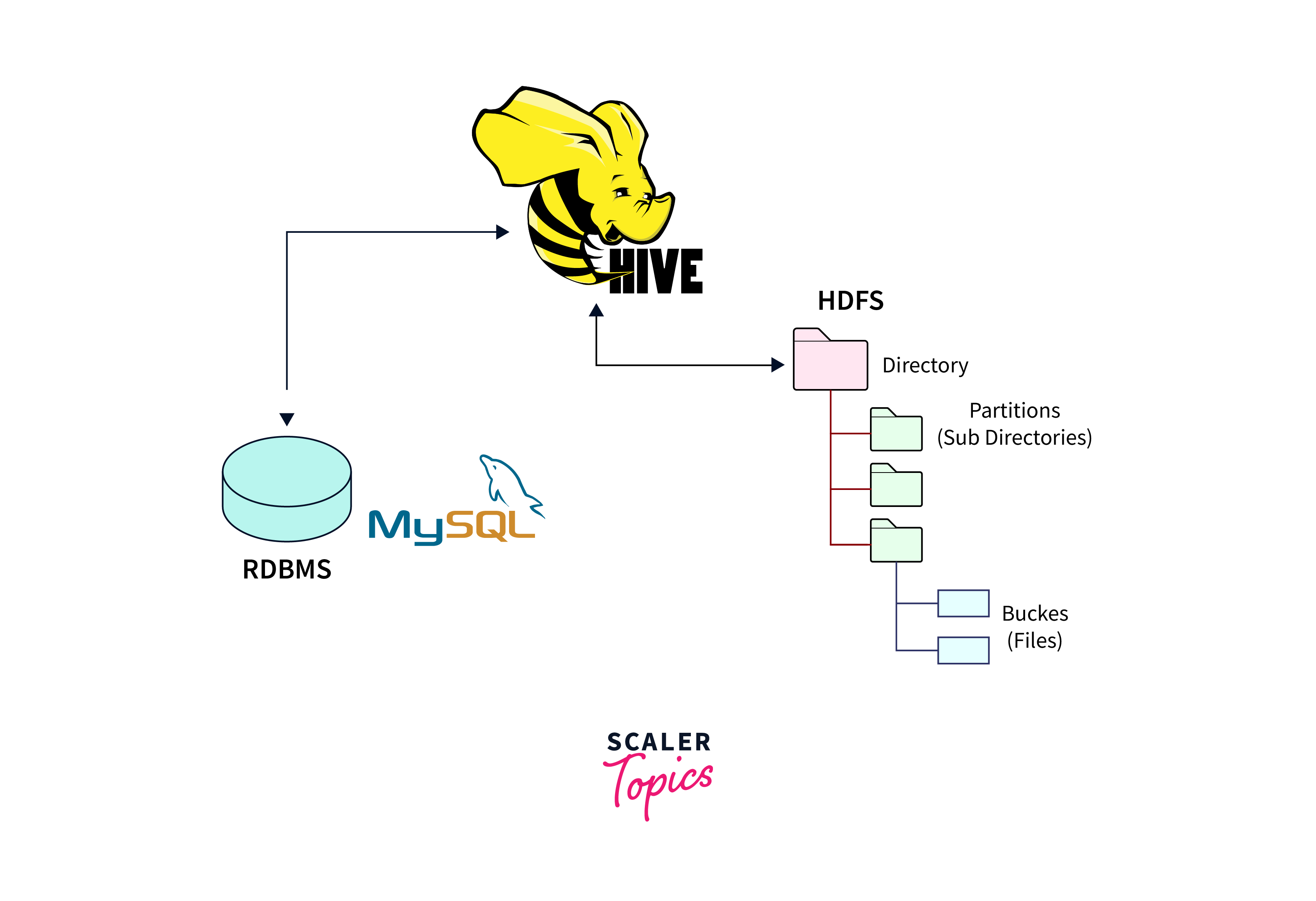
Data transformation with Hive involves using HiveQL queries to manipulate and reshape structured data stored in Hadoop Distributed File System (HDFS).
- Data transformation with Hive involves using HiveQL queries to reshape, aggregate, filter, and manipulate structured data.
- You can apply SQL-like clauses for normalization, aggregation, filtering, and joining.
- Functions and expressions help modify data within queries. The transformed data can be stored back in Hive tables for further analysis or processing.
Data Processing with Spark
Data processing with Apache Spark is a powerful and flexible framework for distributed data processing in the Hadoop ecosystem. It offers faster and more versatile processing compared to traditional MapReduce.
Data processing with Spark involves leveraging its in-memory computation and Resilient Distributed Datasets (RDDs) to efficiently manipulate and analyze large datasets:
-
In-Memory Processing:
Spark processes data in-memory, enabling faster computation compared to traditional disk-based approaches.
-
RDD Abstraction:
Spark's core abstraction, RDDs, allows data to be divided into partitions and processed in parallel across a cluster.
-
SQL Queries:
Spark SQL enables querying structured data using SQL syntax, bringing familiarity to data processing tasks.
-
Batch and Real-Time:
Spark handles both batch processing and real-time streaming through Structured Streaming.
Data Processing with Pig
Data processing with Apache Pig involves using Pig, a high-level scripting language and platform built on top of the Hadoop ecosystem, to simplify and automate data processing tasks. Pig abstracts complex MapReduce tasks into simpler, more human-readable scripts, making it easier to work with large datasets.
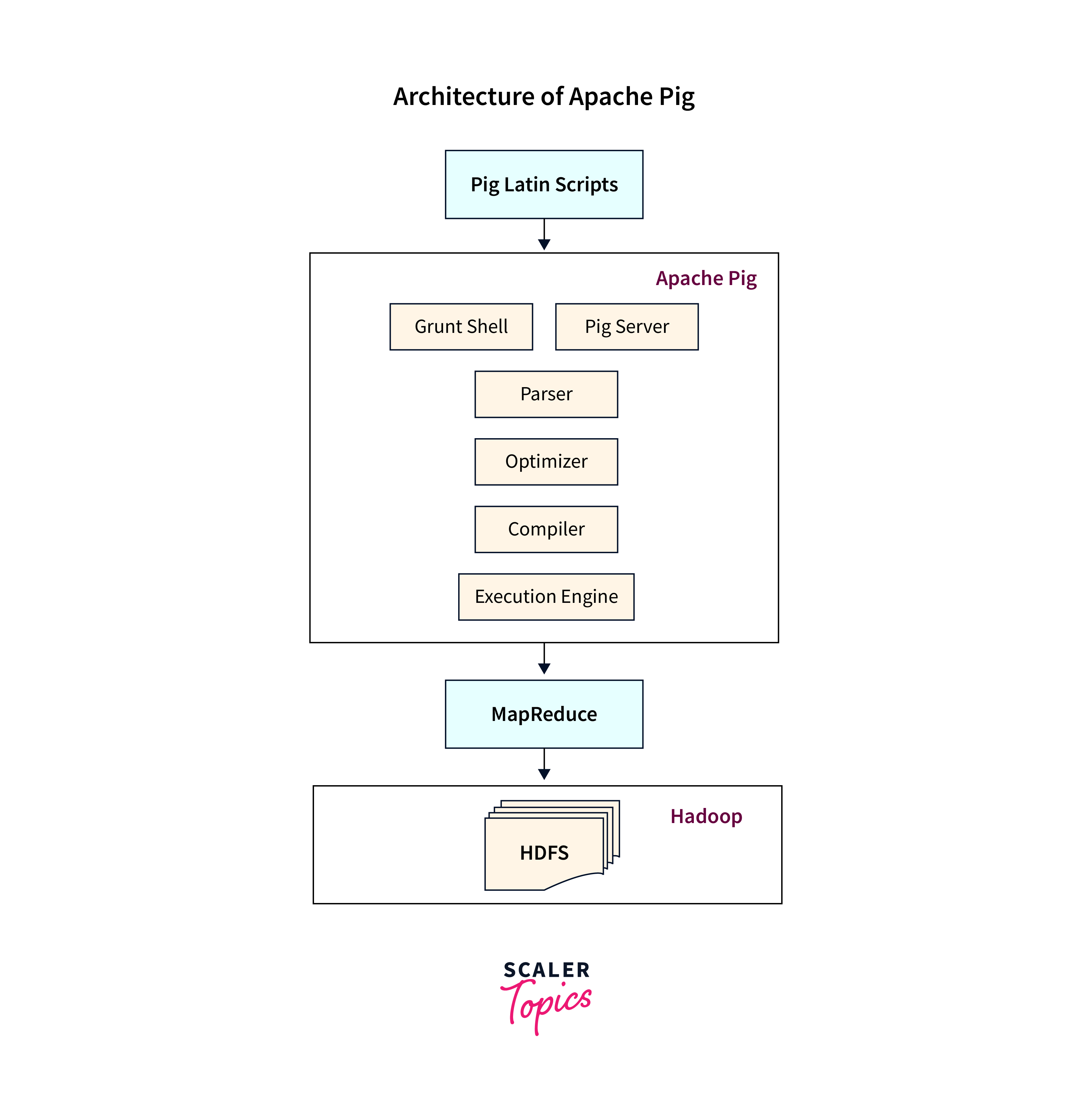
Pig, a high-level scripting language and platform in the Hadoop ecosystem, is used in data processing with Apache Pig to streamline and automate data processing tasks.
In Apache Pig, data processing is performed using a high-level scripting language called Pig Latin. Pig is a platform that simplifies the process of analyzing large datasets by providing a higher-level abstraction over the complexities of writing MapReduce jobs directly.
-
Pig Latin Scripting:
Pig uses Pig Latin, a high-level scripting language, to express data transformations, making tasks more intuitive and concise.
-
Declarative Programming:
Pig offers a declarative approach where users specify operations, and Pig translates them into MapReduce jobs.
Real-Time Data Processing with Kafka and Hadoop
Real-time data processing with Kafka and Hadoop involves using Apache Kafka to collect and buffer data streams from various sources. This data is organized into topics and partitions and then pushed into Kafka by producers. The data is then processed and analyzed in real-time within the Hadoop ecosystem using tools like Spark Streaming. Kafka's low latency, scalability, and fault tolerance make it suitable for real-time use cases, enabling timely insights from streaming data.
Conclusion
- Data with Hadoop refers to the utilization of the Hadoop framework to manage, store, process, and analyze large volumes of data.
- HDFS stores data in a fault-tolerant, distributed manner across a cluster of nodes.
- Data ingestion involves bringing external data into the Hadoop ecosystem for processing and analysis.
- MapReduce divides tasks into map and reduce phases for distributed data processing.
- Hive offers SQL-like querying to transform structured data in HDFS.
- Spark processes data in memory across a cluster, offering versatility and speed.
- Pig simplifies data processing with high-level scripts, abstracting complex tasks.
- Kafka streams real-time data to Hadoop components like Spark for instant insights.