Elasticsearch vs Hadoop
Overview
In Elasticsearch vs Hadoop, Hadoop and Elasticsearch are strong open-source data processing and search analytics platforms. Elasticsearch specializes in real-time search and analytics, whereas Hadoop focuses on distributed batch processing via MapReduce. For diverse data formats, Elasticsearch provides full-text search and quick data exploration. Hadoop's HDFS efficiently stores data, and YARN handles resource allocation. Elasticsearch, which is built on Apache Lucene, saves data as JSON documents and allows for real-time analysis. Hadoop's flexibility is well suited to batch processing, whereas Elasticsearch specializes in real-time search.
Introduction
While Hadoop focuses on distributed batch processing via the MapReduce paradigm, Elasticsearch excels in real-time search and analytics, offering full-text search and rapid data exploration. Use Case for Elasticsearch and Hadoop:
- Elasticsearch: Real-time search and analytics for large-scale data across various sources in applications and systems.
- Hadoop: Distributed processing of big data for storage, retrieval, and analysis to enable scalable and cost-effective data handling.
What is Hadoop?
In elasticsearch vs hadoop comparison where, Hadoop is an open-source software framework used to store and analyze vast amounts of data in a distributed computing environment. It is written in Java, native C, and shell scripts, and it employs the MapReduce programming technique to handle big datasets in parallel.
Hadoop has two main components:
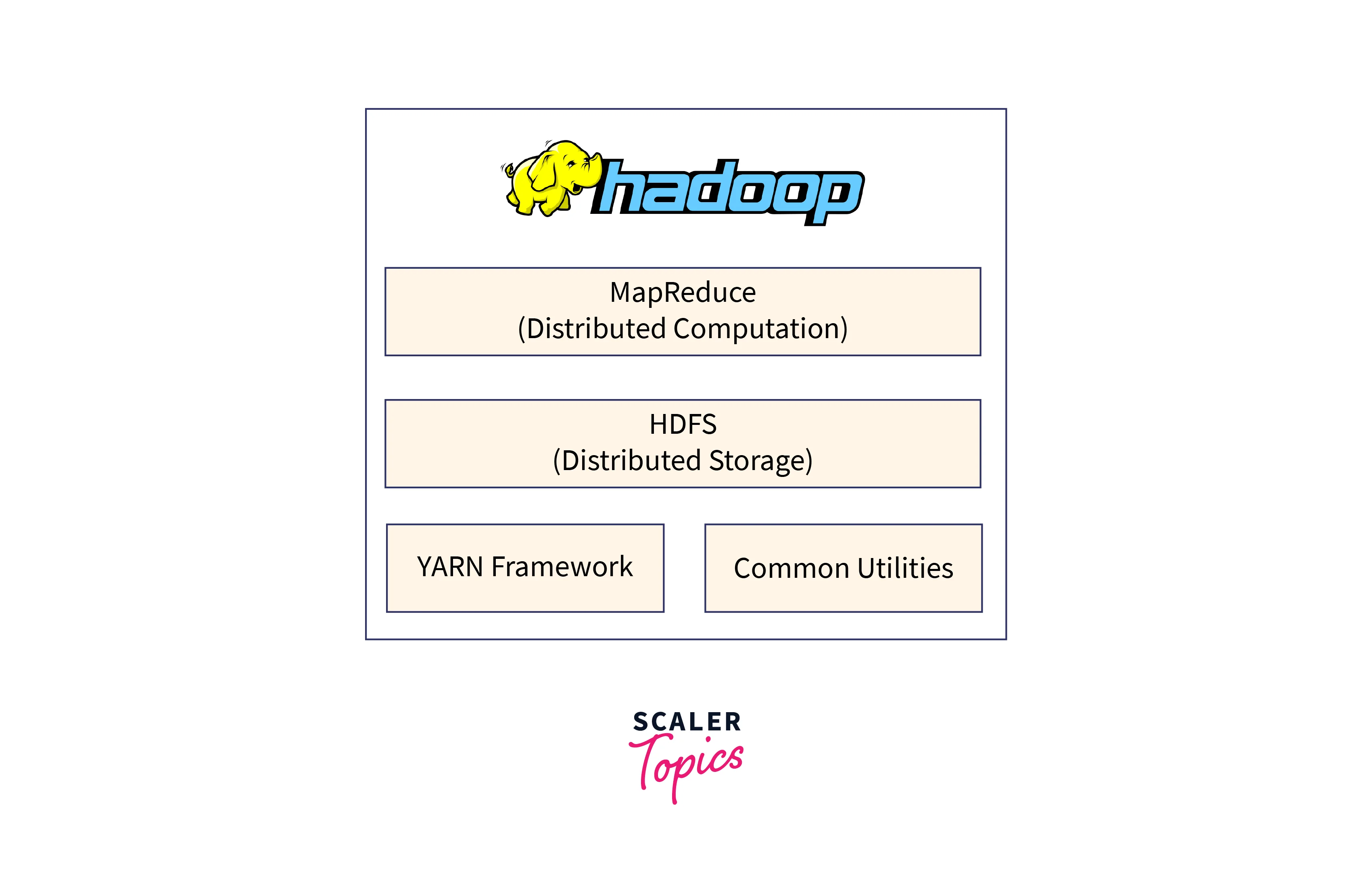
- Hadoop's HDFS is a cost-effective storage component for large amounts of data across multiple machines. It is designed to work with commodity hardware, making it cost-effective.
- YARN manages resource allocation for processing data stored in HDFS.
- Hadoop includes modules like Hive, Pig, and HBase, providing additional functionality.
What is Elasticsearch?

- In elasticsearch vs hadoop comparison where as Elasticsearch is a distributed search and analytics engine that is open-source and built on the Apache Lucene library.
- It was released in 2010 and provides full-text search capabilities for a variety of data types such as textual, numerical, geographic, structured, and unstructured data.
- Elasticsearch is the central component of the Elastic Stack, which includes Elasticsearch, Logstash, and Kibana, which enhance data ingestion, storage, visualization, and analysis.
- Elasticsearch offers a RESTful API and stores data as schema-free JSON documents. It can store, search, and analyze massive amounts of data in real-time, as well as uncover patterns and trends.
Components
- Index: Elasticsearch's index is a high-level container for storing data in similar documents within a specific category.
- Document: Elasticsearch uses document as a JSON object, stored in an index with unique IDs for easy identification.
- Node: Node is a single Elasticsearch instance on a system, while clusters form with multiple nodes for fault tolerance and scalability.
- Cluster: A cluster is a network of interconnected Elasticsearch nodes for efficient data storage, analysis, and distribution.
- Shard: Indexes are sharded for parallel processing across nodes, enhancing scalability and enabling multiple node processing.
- Replica: Elasticsearch enables replicating data for redundancy and availability in node failures.
- Query: Elasticsearch provides search methods for documents, including full-text, precise matches, and ranges.
Working:
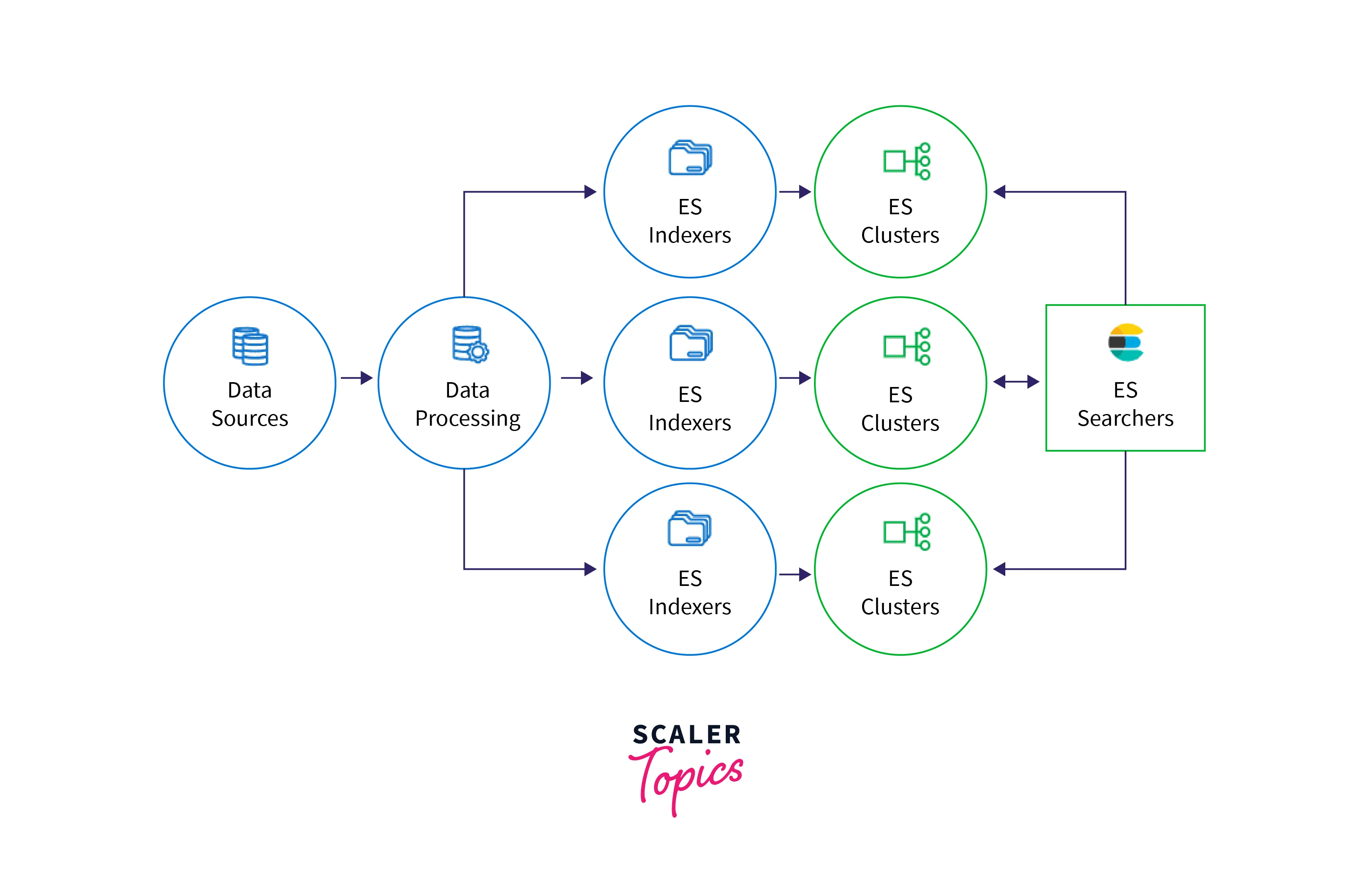
- Elasticsearch receives unstructured data from numerous sources.
- Ingestion tool like Logstash is used to gather and analyse data before it is indexed. The data is then indexed and ready for complicated searches.
- The Elasticsearch index is a collection of documents that are connected or have comparable characteristics. It enables quick full-text searches and detects every unique term in the texts.
- You may deliver JSON documents to Elasticsearch using API or ingestion tools. Elasticsearch saves the original document and adds a searchable reference to it to the index.
Key Features:
- Elasticsearch enables quick and accurate full-text search, including capabilities such as fuzzy search, autocomplete, and language-specific analyzers.
- JSON Document Store: Because data is saved as JSON documents, it is simple to manage organized and unstructured data with flexible schema.
- Real-Time Analysis: Elasticsearch enables near real-time data exploration and analysis.
- Distributed and Scalable: It is intended to offer numerous nodes horizontal scalability to handle huge datasets and heavy query loads.
Limitations:
- Setup and configuration complexity.
- Large datasets require a lot of resources.
- If not correctly set, there is a danger of data loss.
- Indexing overhead for frequent updates.
- Limited document size handling.
Difference between Hadoop vs Elasticsearch
Map then reduce
- In elasticsearch vs hadoop for Map then reduce Hadoop is a distributed batch processing technology based on the MapReduce concept. Data processing is divided into two stages: map (data processing) and reduce (aggregation).
- Elasticsearch is intended primarily for real-time data search and analytics using data aggregation and analytics.
Fault Tolerant
- Hadoop is fault-tolerant due to data replication. It distributes several copies of data blocks among cluster nodes, ensuring data availability even if some nodes fail.
- Elasticsearch is likewise fault-tolerant. It partitions data into shards and distributes multiple replicas of each shard across nodes to provide fault tolerance.
Flexibility
- In elasticsearch vs hadoop , Hadoop is a highly adaptable data and task processing system. It can perform batch processing, real-time streaming, and interactive queries via additional components such as Apache Spark and Apache Hive.
- Elasticsearch specialises at real-time search and analytics. It excels at full-text search and has significant aggregation features, making it is less suited to standard batch processing applications.
Synchronization
- The Hadoop Distributed File System (HDFS) is used to provide synchronisation and data consistency.
- Elasticsearch's distributed design and replication algorithms assure synchronisation and data consistency within its cluster.
Hadoop vs Elasticsearch: Comparison Table
| Hadoop | Elasticsearch |
|---|---|
| Hadoop is a MapReduce-based, highly scalable distributed processing technology. | Elasticsearch is a Lucene-based distributed full-text search and analytics engine. |
| For data storage and processing, Hadoop uses a master-slave architecture. | Elasticsearch uses the REST architecture to execute cluster monitoring operations. |
| It is mostly used to store data and run applications on commodity hardware clusters. | It serves as a full-text search engine as well as an analytics platform for real-time query execution. |
| It lacks Elasticsearch's advanced search and analytic search features. | It's a robust full-text search and analytics engine for document indexing. |
Conclusion
- Hadoop and Elasticsearch are both proficient open-source technologies that serve diverse functions in large data processing and analytics.
- Hadoop excels in distributed batch processing for large data sets using MapReduce, but Elasticsearch specializes in real-time search and analytics, offering full-text search capabilities for a variety of data types.
- Both frameworks play critical roles in handling large-scale data situations and offering significant insights for a variety of applications.