Facebook Data Analysis Using Hadoop
Overview
In the digital age, companies are constantly seeking insights to make informed decisions and social media platforms like Facebook generate a vast amount waiting to be explored. Facebook Data Analysis Using Hadoop is an exploration into the world of big data analytics using Hadoop, a powerful big data processing framework. We will walk you through the process of extracting, processing and analyzing Facebook data to gain valuable insights.
What Are We Building?
The primary goal of this project is to demonstrate how to use Hadoop and Hive to analyze massive Facebook data.
Pre-requisites
Here's a list of key topics that you should be familiar with, along with links to articles that can help you brush up on these concepts:
- Hadoop: Learn about Hadoop on Hadoop and learn how to set up a Hadoop cluster on Hadoop Cluster Setup.
- Facebook Data: Check the dataset here.
- Hive: Get familiar with Hive Basics and also explore the Common Commands of Hive.
How are We Going to Build This?
Let's break down the key steps in building our Facebook data analysis using the Hadoop project:
- Data Collection: Get the data from Twitter API or using the dataset link from the above section.
- Data Preparation: Clean and preprocess the collected data to remove any missing values or irrelevant information.
- Hadoop Setup: Store the preprocessed data in the Hadoop Distributed File System (HDFS).
- Hive Setup: Create Hive databases and tables to structure the data with an appropriate schema.
- Analysis: Utilize Hive to perform analysis on the Twitter data.
- Interpretation: Interpret the insights derived from the analysis.
- Final Output: Insights on the twitter data.
Final Output
The following images show the execution of hive commands to analyse Facebook data in a Hadoop environment,


Requirements
Below is a list of the key requirements for this project:
- Software: Hadoop (HDFS, Hive), Java Development Kit (JDK), Integrated Development Environment (IDE)
- Libraries: Requests(Facebook Graph API), DateTime
- Programming Languages: Python and Java
- Data: Facebook Developer Account (for API access), Access to Facebook Graph API (Access Token Secret)
- Knowledge: Data preprocessing tools, SQL, Testing frameworks(JUnit), Terminal or Command Prompt
Facebook Data Analysis Using Hadoop
Are you ready to get started with the climatic implementation of the project?
Data Extraction and Collection
In this section, we will walk you through the steps to obtain the necessary credentials for the Facebook Graph API, provide code examples to collect data and demonstrate how to clean, preprocess, and store the data as a CSV file.
1. Obtaining Facebook API Credentials
To access Facebook data programmatically, you'll need to obtain API credentials. Follow these steps:
- Create a Facebook App: Go to the Facebook Developer portal and create a new app. This app will serve as the gateway to access Facebook's API.
- Configure App Settings: In the app dashboard, configure the settings, including platform (e.g., Website), product (e.g., Facebook Login), and permissions (e.g., user_posts, user_likes). Make sure to set up the necessary permissions to access the data you need.
- Generate Access Token: Under the Tools & Support section of your app's dashboard, navigate to Access Token Tool and generate an access token with the required permissions.
Note: Keep your access token secure and never share it publicly.
2. Collecting Data Using Python
Now that you have your access token, you can use Python to collect Facebook data. We'll use the requests library to make API calls. Code:
Explanation:
- We make a GET request to the Facebook Graph API endpoint using the access token and specify the fields we want in the response.
- If the request is successful (HTTP status code 200), we pass the JSON response to preprocess it.
3. Clean and Preprocess Data
After collecting the raw data, we will need to clean and preprocess it.
Code:
Explanation:
The preprocess_data function is critical takes raw data obtained from the Facebook API and transforms it into a cleaned and structured format for analysis.
- Python's datetime module provides the strptime method to parse the birthdate field to extract the day, month, and year components.
- It performs data type conversions
- It standardizes the gender field by removing leading and trailing spaces.
- The calculate_age function is a utility function used to compute a user's age based on their birthdate.
- The preprocess_data function returns a list of dictionaries of users' cleaned and preprocessed data in a structured format.
4. Store Data as CSV
To store the cleaned and preprocessed data, you can save it as a CSV file using Python's csv module.
Code:
Explanation:
Certainly, let's break down and explain the provided Python code:
Explanation:
- The fieldnames is a list of field names used in a CSV file.
- Then we open a new CSV file named facebook_data.csv for writing (w) and create a DictWriter object called writer that will be used to write data to the CSV file.
- Then we write the header row containing the field names to the CSV file followed by the actual data.
You can also download the data directly from the link in the Pre-requisites section.
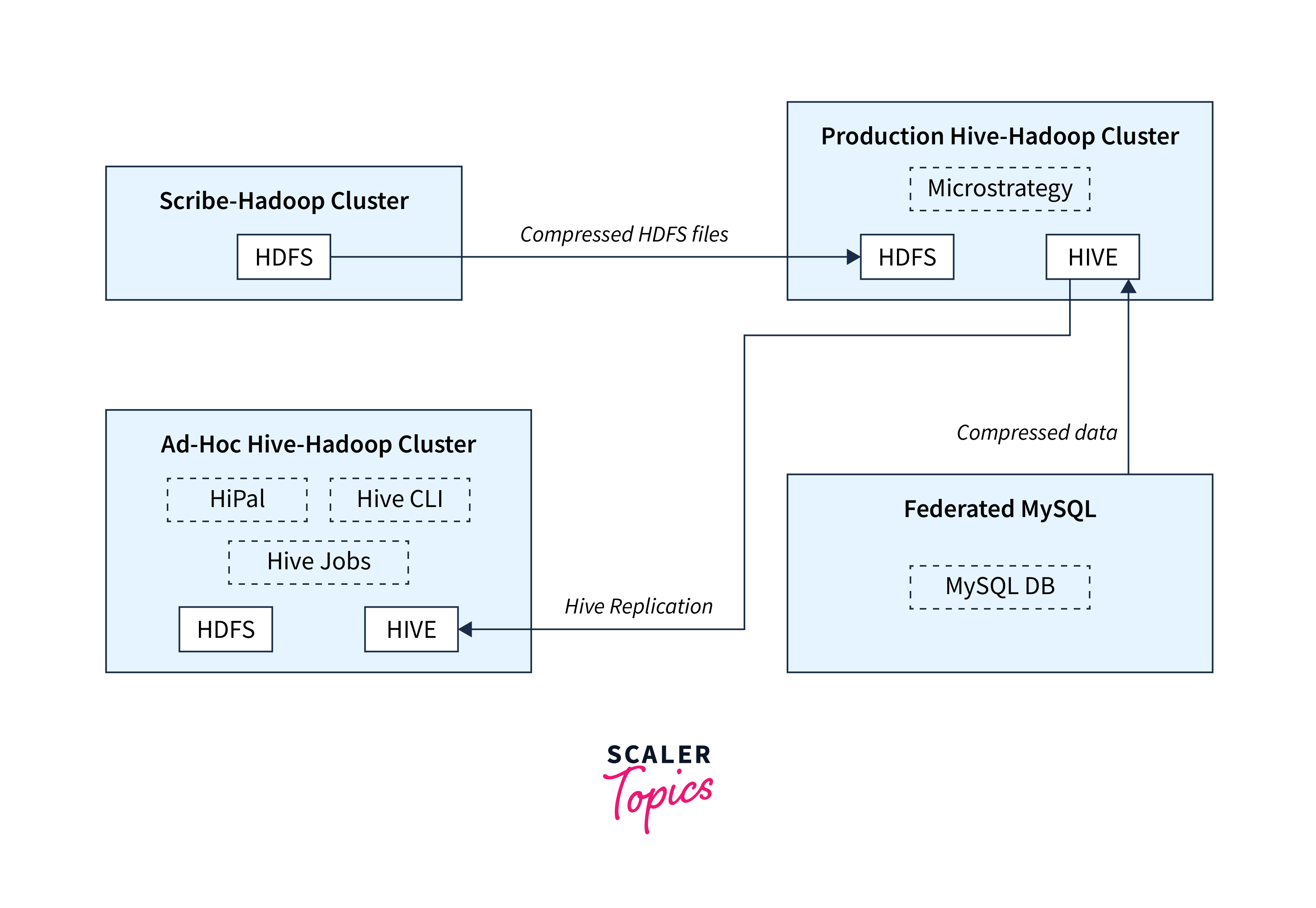
Architecture
The data flow within this architecture typically follows these steps:
- Data is collected from Facebook through the Graph API or dataset.
- The collected data is ingested into the Hadoop cluster and stored in HDFS.
- Data preprocessing is performed to clean, transform, and structure the data.
- Hive databases and tables are created to represent the data schema.
- Hive queries are written to analyze the data and derive insights.
- Testing and validation ensure the accuracy of the analysis.
Load data to HDFS
To load data into the Hadoop Distributed File System (HDFS), follow these steps:
- Access the Hadoop cluster where you want to load the data. Ensure you have the necessary permissions and access rights.
- Use the following command to transfer data from your local file system to HDFS. The facebook_data.csv is the Local source path and /test/facebook_data.csv is the HDFS destination path with the desired HDFS destination directory.
- Confirm that the data has been successfully transferred to HDFS by listing the contents of the target HDFS directory using the command:
This command should display the files and directories within the specified HDFS directory(/test/).
Hive Databases
Step 1: Access Hive
Access the Hive environment within your Hadoop cluster using the following command,
Step 2: Create a Hive Database
Use the CREATE DATABASE command to create a new Hive database.
The facebook_data_db is the name of the database.
Step 3: Use the Database
Switch to the newly created database using the USE command:
Step 4: Create Hive Tables
Create Hive tables to represent the data schema. Define the table name, column names, and their data types using the CREATE TABLE command.
The facebook_data is the name of the table and the columns names and data types are as per the processed data. We specify that the data in the table is delimited by commas (,), as is typical for CSV files. The table is stored as a text file in Hive.
Step 5: Load Data into Hive Table
After creating the table, you can load data into it using the LOAD DATA command.
As we have our data files in HDFS, we can load them into the table, by using the LOAD DATA command:
The /test/facebook_data.csv is the path to the file on HDFS.
We can also insert data directly into the table from another table or query result, using the INSERT INTO command:
Step 7: Verify Table Creation
Verify that the table has been created and data has been loaded by running a SELECT query:
Analysis With Hive Command
Now, let's perform some simple analysis using Hive commands.
1. Find the Average Age of Users
This query calculates the average age of Facebook users from the dataset.
Calculate Average Friend Count by Gender
This query calculates the average friend count for each gender group.
2. Calculate Average Likes for Users Aged 13 to 25
Results
1. Find the Average Age of Users
This query calculates the average age of users in the dataset. The result, approximately 31.5, represents the average age of Facebook users based on the provided data.
2. Calculate Average Friend Count by Gender
This query calculates the average friend count for each gender group. In the sample output, the average friend count for "Male" users is 300, for "Female" users is 250, and for "Other" users is 180.
3. Calculate Average Likes for Users Aged 13 to 25
This query calculates the average number of likes for users aged 13 to 25. In the sample output, the result is an average of 450 likes for users within this age range.
Testing
Testing is a crucial phase in any data analysis project to ensure the accuracy, reliability, and validity of your results.
- Define Testing Objectives and Criteria
- Prepare Test Data
- Perform testing of individual components or queries within your analysis
- Verify Data Consistency of analysis results.
- Test Performance and Scalability
What’s next
Now that you've completed the Twitter Data Analysis project using Hadoop and Hive, here are a few ideas for what you can do next to further enhance your skills:
- Machine Learning Integration: Extend your analysis by incorporating machine learning models and techniques using tools like Apache Spark MLlib or scikit-learn in Python.
- Real-time Data Processing: Explore technologies like Apache Kafka and Apache Flink to process and analyze data in real-time for immediate insights.
- Automate Data Pipelines: Build data pipelines to automate the collection, preprocessing, and analysis of data. Tools like Apache NiFi and Apache Airflow can help you create robust and scalable data workflows.
Conclusion
- Facebook Data Analysis using Hadoop is a powerful approach to derive insights from large-scale social media data.
- The project involves data extraction, preprocessing, and analysis within a Hadoop ecosystem.
- The project requires a Hadoop cluster, Hadoop ecosystem tools, and an understanding of Hive for data warehousing.
- Data extraction involves using the Twitter API or data sets.
- Data preprocessing includes cleaning, handling missing values, and structuring data for analysis.
- Hive databases and tables are created to define the data schema and analysis is performed using Hive queries.