The Features Of Hadoop
Overview
Hadoop is a popular framework for large data processing, and it has a number of features that contribute to its popularity. The Hadoop ecosystem, which includes HDFS, MapReduce, and YARN, provides a complete foundation for distributed storage, parallel processing, and resource management. YARN handles cluster resources and task scheduling, while HDFS guarantees fault-tolerant storage. These components, when combined, enable organisations to efficiently manage large data. The features of Hadoop include Open Source, Highly Scalable Cluster, Fault Tolerance, High Availability and Cost Effectiveness.
3 Components of Hadoop
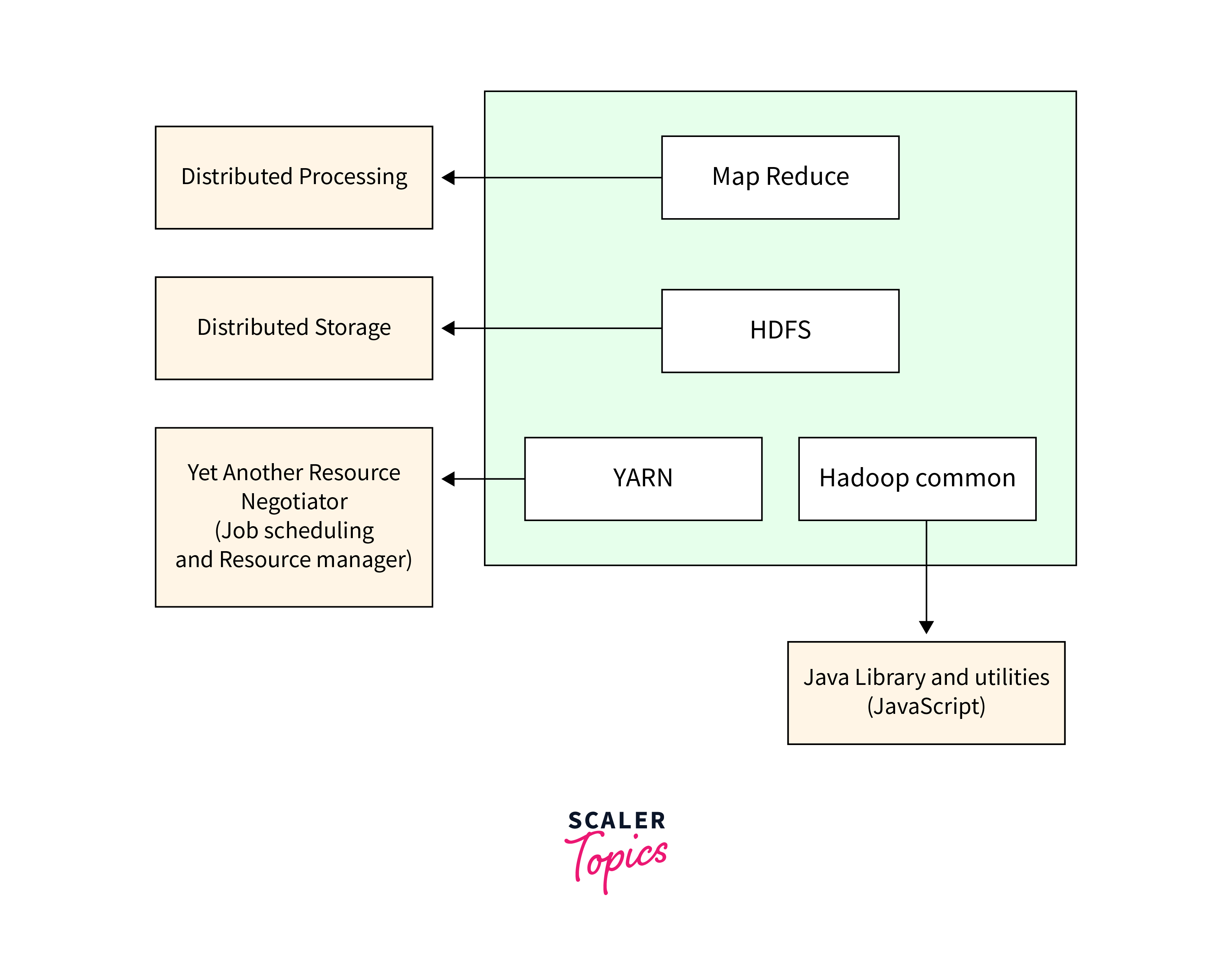
HDFS
- HDFS is a distributed file system built for commodity hardware that stores data in blocks.
- With NameNode as the master and DataNodes as slaves, HDFS offers fault-tolerance and high availability to the storage layer in a Hadoop cluster.
- NameNode holds metadata and transaction logs while advising DataNodes on the delete, create, and replicate activities.
- In a Hadoop cluster, DataNodes hold data and the number of DataNodes can range from one to 500 or more.
- HDFS stores data in 128MB blocks, which can be manually adjusted to accommodate uploaded files. This ensures efficient storage and organization of data.
- HDFS replication maintains data availability by producing copies of file blocks, with a replication factor of 3 by default.
MapReduce
- MapReduce is an algorithm based on the YARN framework. It enables distributed processing in parallel within a Hadoop cluster, contributing to Hadoop's fast performance.
- MapReduce consists of two tasks: Map and Reduce.
- Input is provided to the Map() function, and its output is used as input to the Reduce() function.

- Map() function breaks the input data into key-value pairs known as Tuples.
- These Tuples are then passed as input to the Reduce() function.
- Reduce() function combines the Tuples based on their key values and performs operations like sorting or summation.
- The data processing in the Reduce() function depends on the specific business requirements of the industry.
- The processed data is finally sent to the final Output Node.
YARN
YARN is an acronym that stands for Yet Another Resource Negotiator. It is responsible for two key tasks:
- Cluster resource management, including compute, network, and memory
- Job scheduling and monitoring
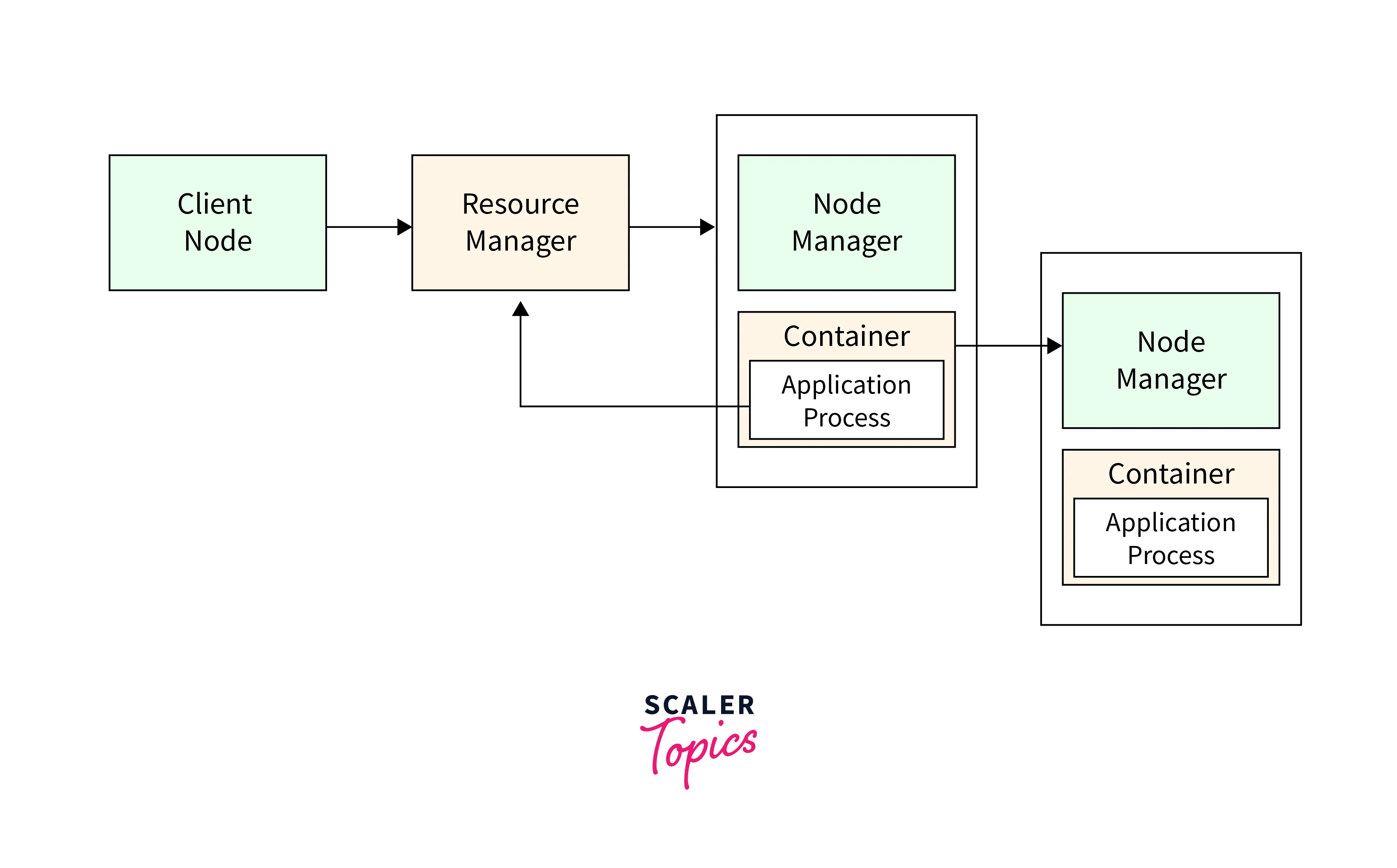
YARN achieves these aims through the use of two long-running daemons:
- Node Manager
- Resource Manager
The two components function in a manner with the Resource Manager serving as the primary node and the Node Managers serving as the secondary follower nodes. The cluster is managed by a single Resource Manager, with one Node Manager per computer.
Features of Hadoop Which Makes It Popular
a. Open Source
- One of the features of Hadoop is that it is an open-source project, which means its source code is available to all for modification, inspection, and analysis.
- Because the code is open-source, firms may alter it to meet their own requirements.
- Because of the code's adaptability, enterprises may customise Hadoop to their own needs.
b. Highly Scalable Cluster
- Hadoop is extremely scalable and capable of handling massive amounts of data by distributing it over several computers running in parallel, which is one of the features of Hadoop.
- Unlike typical relational databases, Hadoop allows businesses to manage enormous datasets spanning thousands of gigabytes by executing applications over numerous nodes.
c. Fault Tolerance is Available
- Another one of the features of Hadoop is that it achieves fault tolerance by creating replicas, which spread data blocks from a file among multiple servers in the HDFS cluster.
- By default, HDFS duplicates each block three times on separate machines in the cluster, providing data access even if a node fails or goes down.
d. High Availability is Provided
- By duplicating data across numerous DataNodes, Hadoop's fault tolerance feature assures excellent data availability even in adverse situations.
- High availability Hadoop clusters have multiple NameNodes, with active and passive nodes in hot standby setups. Passive nodes ensure file accessibility even if active node fails.
e. Cost-Effective
- Hadoop offers businesses working with large data a cost-effective storage alternative to conventional relational database management systems, which may be expensive to scale.
- Hadoop's scale-out design allows cost-effective storage of all data, reducing raw data loss and enabling organizations to store and use their entire dataset at a fraction of the cost.
f. Hadoop Provides Flexibility
- Hadoop is extremely adaptable and can handle a wide range of data types, including structured, semi-structured, and unstructured data.
- Hadoop can handle and analyse data that is organised and well-defined, somewhat organised, or even fully unstructured.
g. Easy to Use
- Hadoop reduces the need for clients to perform distributed computing jobs by handling all of its intricacies, making it user-friendly.
- Users of Hadoop may concentrate on their data and analytics activities rather than the complexities of distributed computing, making it easier to use and run.
h. Hadoop uses Data Locality
- The data locality feature of Hadoop allows computation to be conducted near the data, eliminating the need to transport data and lowering network congestion.
- Hadoop enhances system throughput and overall performance by minimising data transport and putting computing closer to the data nodes.
i. Provides Faster Data Processing
- Hadoop prioritises distributed processing, which results in speedier data processing capabilities.
- The data is distributedly stored in Hadoop HDFS, and the MapReduce architecture allows for concurrent processing of the data.
j. Support for Multiple Data Formats
- Hadoop supports numerous data formats, allowing users to work with a wide range of data.
- Hadoop offers versatility in managing numerous data types, making it flexible for varied data processing and analysis needs, whether structured, semi-structured, or unstructured data.
k. High Processing Speed
- One of the other features of Hadoop is that it is well-known for its fast processing speed, which enables effective handling of massive amounts of data.
- Hadoop may greatly expedite data processing processes by exploiting parallel processing and distributed computing capabilities, resulting in quicker results and enhanced overall performance.
l. Machine Learning Capabilities
- Hadoop has machine learning capabilities, allowing users to do advanced analytics and predictive modeling on massive datasets.
- Users may utilize machine learning algorithms to identify insights and trends, and create data-driven predictions at scale using frameworks like Apache Spark and other integrated libraries with Hadoop.
m. Integration with Other Tools
- Hadoop integrates seamlessly with a wide range of tools and technologies, allowing data ecosystem interoperability.
- Users may easily link Hadoop with a wide range of data processing frameworks, databases, analytics tools, and visualization platforms, increasing the flexibility and value of their data infrastructure.
n. Secure
- Hadoop delivers comprehensive security capabilities to protect data and maintain secure ecosystem operations.
- It contains measures for authentication, authorization, and encryption to protect data privacy and prevent unauthorized access, thereby making Hadoop a secure platform for storing and processing sensitive data.
o. Community Support
- One of the main features of Hadoop is that it benefits from a vibrant and active community of developers, users, and contributors.
- The community support for Hadoop is extensive, offering resources, documentation, forums, and continuous development, ensuring users have access to assistance, updates, and a wealth of knowledge for leveraging Hadoop effectively.
Conclusion
- Hadoop consists of HDFS, MapReduce, and YARN for efficient and scalable handling of large data workloads in distributed storage, parallel processing, and resource management.
- HDFS is a distributed storage system for large datasets, while MapReduce is a parallel programming model for data processing and analysis across clusters. YARN is the resource management and job scheduling framework.
- Features of Hadoop include scalability, fault tolerance and flexibility, making it a popular choice for handling big data.
- It offers cost-effective storage, high processing speed, and machine learning capabilities for advanced analytics.
- Integration with other tools and strong community support further enhance its value and usability.