Hadoop Architecture
Overview
In a distributed computing environment, vast volumes of data can be stored and processed using the open-source Hadoop framework. Understanding the hadoop architecture become crucial as it offers a dependable, scalable, adaptable, and distributed computing Big Data platform.
Hadoop's architecture provides scalability, fault tolerance, and cost-effective storage and processing capabilities, making it a popular choice for Big Data applications and analytics. This article helps to understand key components of Hadoop's architecture.
High-Level Architecture Of Hadoop
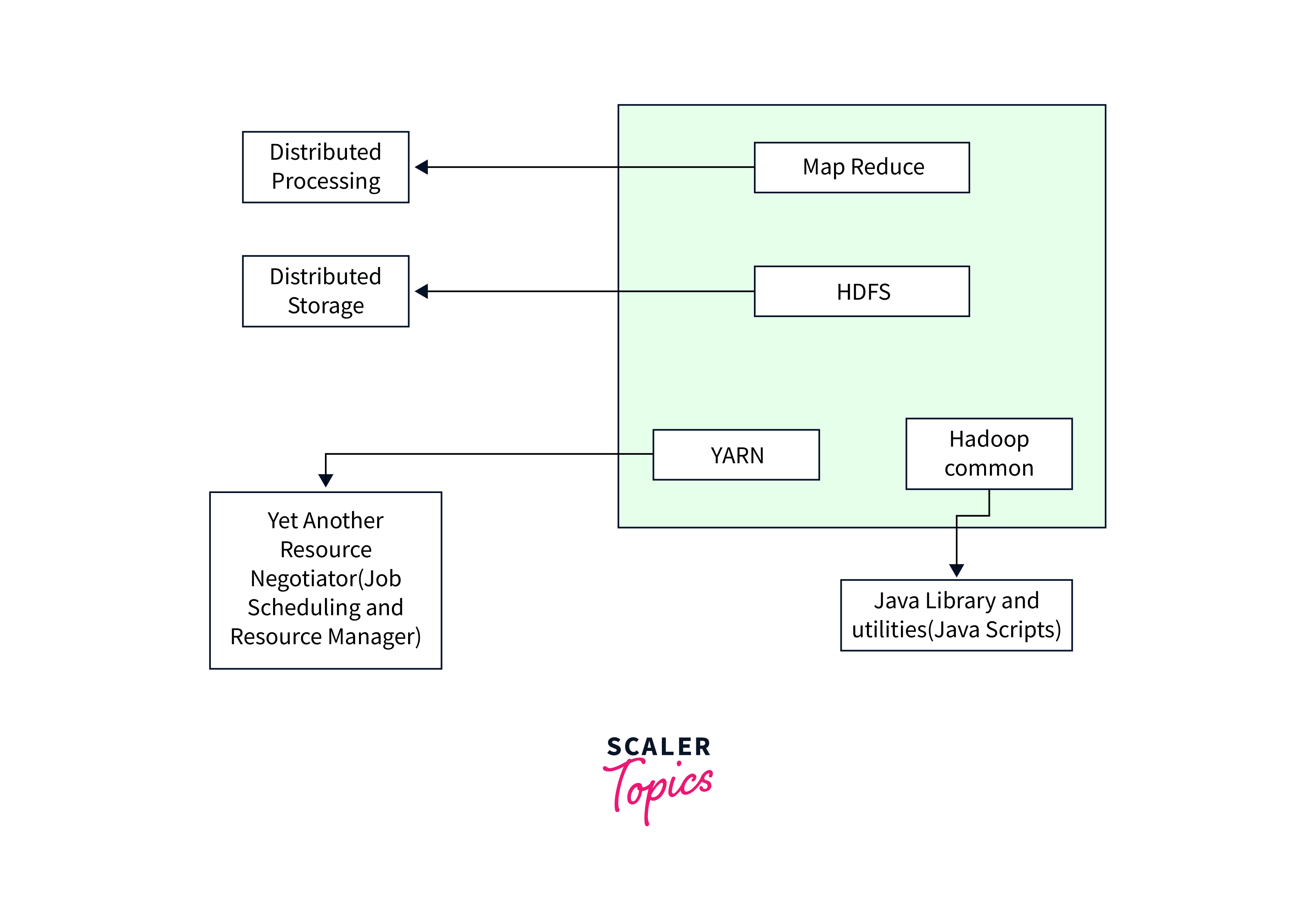
Hadoop high-level architecture proves to seamlessly handle Big data issues and enables fault-tolerant and scalable storage, processing, and analysis.
The high-level architecture of Hadoop comprises of the following core components and their interactions to enable distributed storage and processing of large datasets.
- MapReduce: A programming model for parallel processing and analyzing large datasets across a Hadoop cluster
- HDFS(Hadoop Distributed File System): Stores data across a cluster of nodes, providing fault tolerance.
- YARN (Yet Another Resource Negotiator): Manages cluster resources and scheduling of data processing tasks.
- Hadoop Common (Utilities): Provides shared libraries and utilities essential for the functioning of the entire Hadoop ecosystem.
The Hadoop Architecture Modules
a. MapReduce
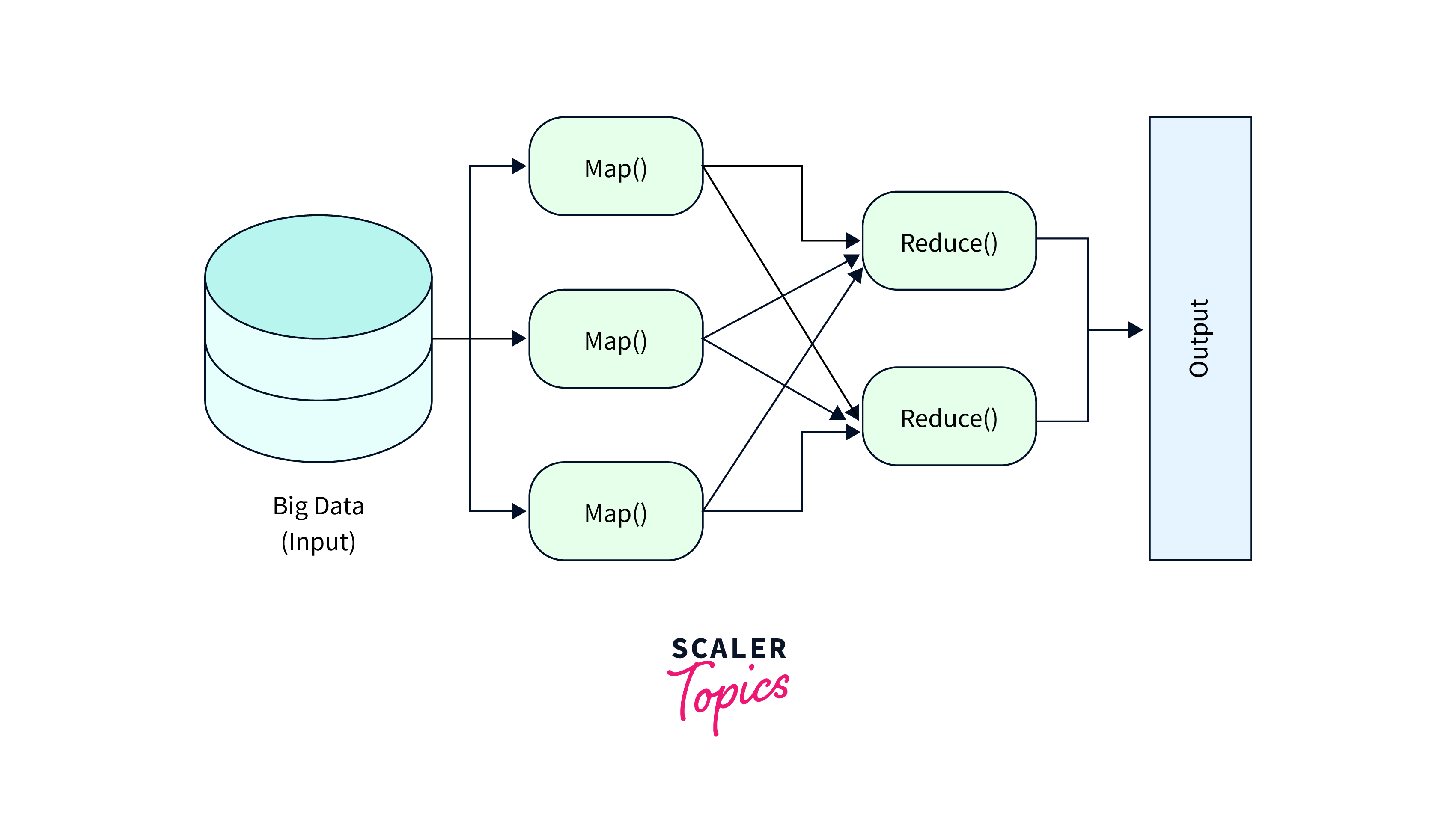
i. Map Task
- RecordReader RecordReader creates key-value pairs for the Mapper to process by reading and parsing data from input splits (small portions of the input data). Different input formats (e.g., TextInputFormat, SequenceFileInputFormat) in Hadoop have corresponding RecordReader implementations to handle the specific data formats.
- Map A map can be considered as a user define function that processes the key-value pairs retrieved from a record reader as well as applies a specified transformation to produce these key-value pairs.
- Combiner The Combiner decrease the amount of data transferred over the network and increases the MapReduce job's overall efficiency.
- Partitionar The key-value pairs produced in the Mapper Phases are fetched by the Partitioner. Each reducer's matching shard is created by the partitioner. This partition also retrieves each key's hashcode. Then partitioner performs the following formula (key.hashcode()%(number of reducers)) on each hashcode.
ii. Reduce Task
- Shuffle and Sort Hadoop Shuffle and Sort organizes and transfers data from Mapper outputs to appropriate Reducers based on keys, enabling effective data aggregation during the Reduce phase.
- Reduce Gathering the Tuple produced by Map and performing some sort of aggregation operation on those key-value pairs.
- OutputFormat Record writer is used to write the key-value pairs into the file, with each record starting on a new line and the key and value being separated by spaces.
For more information, refer [MapReduce]
b. HDFS (Hadoop Distributed File System)
i. NameNode(Master)
The NameNode (Master), is in charge of managing the file system namespace, keeping track of the metadata for files and directories, and mapping data blocks to DataNodes. The Secondary NameNode helps to improve fault tolerance because it represents a single point of failure.
ii. DataNode(Slave)
The actual data blocks that makeup files in HDFS are stored and served by DataNodes, which are "Slave" nodes in HDFS. They manage block replication, issue recurrent heartbeats to signal availability and communicate block status to the NameNode.
iii. Job Tracker
The HDFS job tracker manages and carries out MapReduce jobs.
iv. Task Tracker
The "TaskTracker" was in Hadoop 1.x as it was in charge of carrying out certain tasks within MapReduce jobs. However, in Hadoop2.x it was abandoned."
For more information, refer [HDFS (Hadoop Distributed File System]
YARN (Yet Another Resource Negotiator)
The resource management framework known as YARN, or "Yet Another Resource Negotiator," was first included in Hadoop 2.x where it worked by separating resource management from data processing.
YARN offers scalability, multi-tenancy, flexibility and effective resource allocation.
To know more visit Introduction to Apache Hadoop YARN.
Hadoop Common (Utilities or Hadoop Common)
Essential shared libraries and utilities utilized by all Hadoop components are provided by Hadoop Common Utilities. File I/O, networking, configuration management, logging, security, compression, and other features are all included. The construction of distributed applications and data processing activities is made simpler by these tools, which guarantee the seamless integration and operation of Hadoop ecosystem components.
For more information, refer to [Hadoop Common]
Advantages of Hadoop
- Scalability: Hadoop's outstanding scalability enables businesses to store and analyze enormous volumes of data across a distributed cluster of affordable technology.
- Fault Tolerance: By duplicating data over numerous nodes, Hadoop has built-in fault tolerance which helps to automatically recover lost data from the replicated copies in the event of hardware failures.
- Cost-Effectiveness: By utilizing inexpensive commodity technology, Hadoop greatly lowers the infrastructure expenses associated with storing and processing massive datasets.
- Flexibility: The Hadoop ecosystem is flexible and supports several data processing frameworks, including MapReduce, Apache Spark, Apache Hive, Apache Pig, and others.
- Parallel Processing: Data parallel processing is made possible by Hadoop's distributed computing approach, which helps to accomplish quicker and more effective data analysis by segmenting jobs into smaller units and spreading them across the cluster.
History of Hadoop
| Year | Release | Description |
|---|---|---|
| 2002 | Nutch Project | Hadoop was started as a web crawler software project, by Doug and Mike. |
| 2004 | Release of paper | A white paper on MpaReduce was published by Google. |
| 2006 | Hadoop (v0.1) | The Apache Software Foundation formally launched and named Hadoop as an open-source project. MapReduce and HDFS were included in the original release. |
| 2013 | Hadoop (v2.2) | This version included updates to YARN that enhanced cluster resource management and permitted the running of many applications concurrently. |
| 2017 | Hadoop (v3.0) | Several critical features were added in Hadoop 3.0, including support for erasure coding in HDFS, enhanced resource management in YARN, and enhancements to the Hadoop Shell. |
| 2020 | Hadoop (v3.3) | Hadoop's most recent stable release, version 3.3, enhanced performance and introduced several new capabilities that further cemented Hadoop's position as a top big data platform. |
Conclusion
- Hadoop is a powerful open-source framework designed for distributed storage and processing of large volumes of data.
- The Hadoop architecture comprises core components like MapReduce, HDFS, YARN, and Hadoop Common utilities.
- Hadoop Common Utilities offer essential shared libraries and utilities, simplifying the development and integration of Hadoop ecosystem components.
- Hadoop offers several advantages, including scalability, fault tolerance, cost-effectiveness, flexibility, and parallel processing
- The history of Hadoop shows its evolution from a project that started in 2002 to becoming a mature and widely adopted platform for big data analytics.