Hadoop Cluster
Overview
Prior to learning about the Hadoop cluster, it is important to understand what a cluster is in general. A cluster is a collection of things, and a simple computer cluster is a collection of different computers connected to one another via LAN (Local Area Network). The nodes in a cluster share data, collaborate on the same tasks and are capable of functioning as a single unit, which enables them to all work together. Similar to this, a Hadoop cluster is made up of a variety of commodity hardware (cheap, widely accessible devices).
Introduction
Hadoop is an open-source platform for distributed data processing that handles huge amounts of data and storage for programs running in a clustered environment. Structured, semi-structured, and unstructured data can all be managed with Hadoop. Compared to conventional relational database management systems (RDBMS), it offers users more freedom for data collection, processing, and analysis.
Advanced analytics tools like predictive analytics, data mining, and machine learning are made available to big data experts by Hadoop. It is made up of the Hadoop YARN task scheduling and resource management framework and the Hadoop Distributed File System (HDFS), which stores, manipulates, and distributes data across several nodes.
What Is a Hadoop Cluster?
A Hadoop cluster is a group of linked computers or servers that work together to use the Hadoop framework to store and process enormous volumes of data. By breaking up data into smaller pieces and distributing it across several nodes, it makes distributed storage and parallel processing possible. This makes it possible to process and analyze data effectively.
The cluster is made up of components such as NameNode, which controls file system metadata, and DataNode, which stores and processes data. In addition, the Resource Manager allots and controls the computational resources, while Node Managers are in charge of managing the resources on individual nodes. Organizations can use Hadoop clusters to address big data concerns by utilizing distributed computing and fault-tolerant architecture.
Hadoop Cluster Architecture
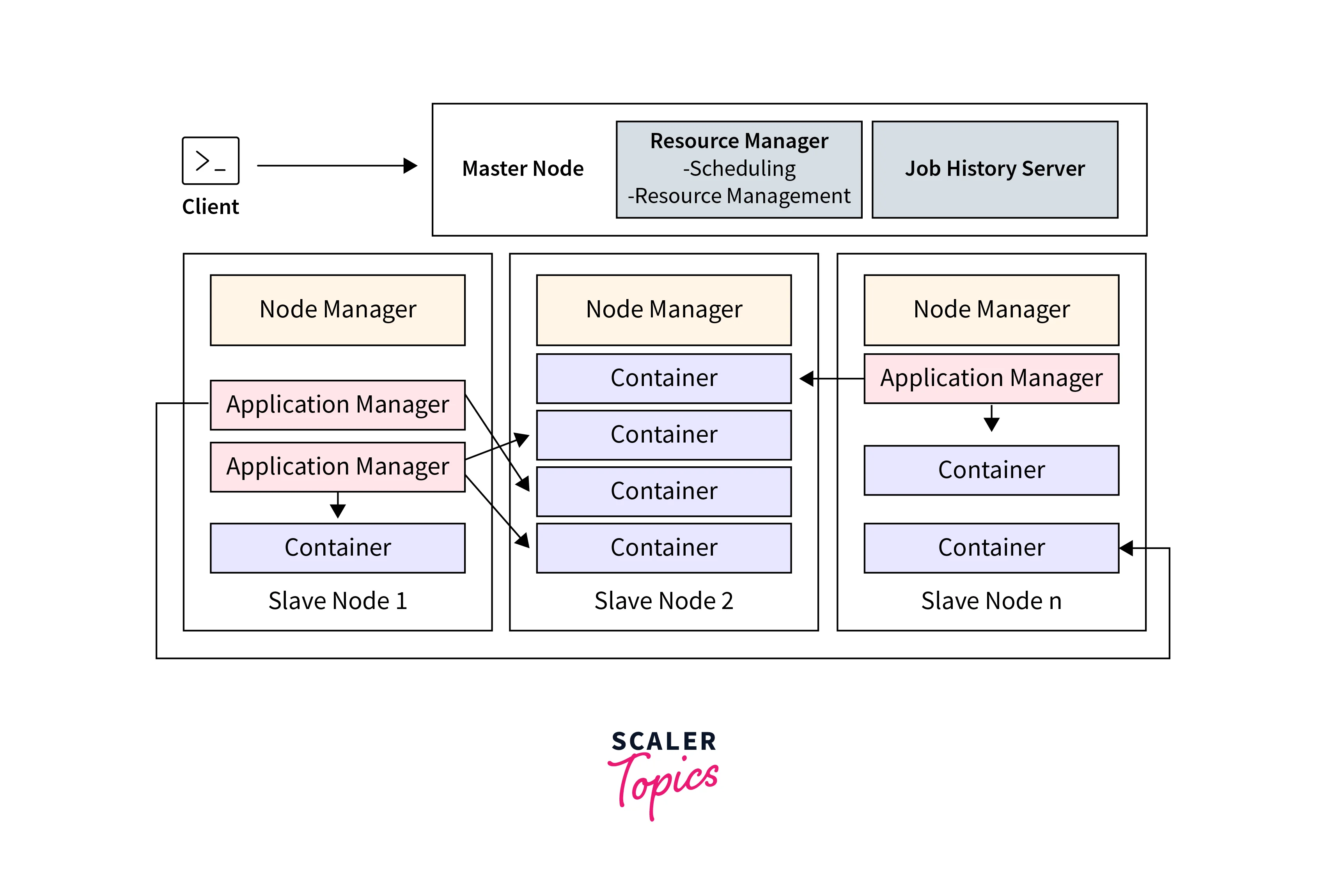
The architecture of a Hadoop cluster consists of several key components that work together to enable distributed storage and processing of data.
a. Master nodes
The master node in a Hadoop cluster architecture is essential to overseeing and coordinating the cluster's overall activities.
The main Master Nodes in a Hadoop cluster are listed below:
- NameNode: In the Hadoop Distributed File System (HDFS), the NameNode serves as the main master node. It keeps track of the metadata for the cluster's files and directories, including details about where they are located and how they are organized. The NameNode looks after client requests for file operations, keeps track of the locations of data blocks, and maintains the file system namespace.
- Resource Manager: The cluster's Resource Manager is a key master node. It is in charge of overseeing the cluster's distribution of computer resources like CPU and memory, to various applications or processes running on specific nodes by keeping track of their availability.
b. Worker nodes
The worker nodes, often referred to as slave nodes, are essential for storing and processing data in a Hadoop cluster architecture. Together, these nodes carry out distributed computing operations.
The main Worker Nodes in a Hadoop cluster are listed below:
- DataNode: These are worker nodes that store and manage data blocks in the Hadoop cluster. They handle data read/write operations, replication, and ensure fault tolerance.
- NodeManager: They manage resources on worker nodes, track availability, communicate with the Resource Manager, and execute tasks on behalf of the cluster's resource management.
c. Client nodes
Client nodes are the computers that users use to communicate with a Hadoop cluster and submit requests for data processing.
The following are the salient features of client nodes in a Hadoop cluster:
- Client Machine: The client machine is where users run their applications and submit jobs to the Hadoop cluster.
- Hadoop Client Libraries: These libraries allow users to submit MapReduce or other job requests, access and modify data stored in HDFS, and keep track of the progress of their jobs.
What is cluster size in Hadoop?
A set of parameters known as Hadoop cluster size describe the storage and computing power needed to operate Hadoop workloads, specifically:
- Number of nodes, including the number of worker nodes, edge nodes, and master nodes.
- Configuration of each type of node, including RAM, disk volume, and the number of CPUs per node.
What are the advantages of a Hadoop Cluster?
Advantages of a Hadoop Cluster:
- Scalability: Hadoop clusters can easily scale by adding more nodes to handle increasing data volumes and processing requirements.
- Distributed Storage: Hadoop Distributed File System (HDFS) provides fault-tolerant storage by replicating data across multiple nodes, ensuring data availability and reliability.
- Parallel Processing: Hadoop's MapReduce framework enables parallel processing of data across the cluster, resulting in faster data processing and analysis.
- Cost-Effective: Hadoop runs on commodity hardware, making it a cost-effective solution compared to proprietary systems for handling big data.
What are the challenges of a Hadoop Cluster?
Challenges include:
- Complexity: The configuration, monitoring, and optimization of a Hadoop cluster needs knowledge that can be difficult for novice users to acquire.
- Data Locality: In a distributed system, it can be difficult to provide optimal data locality, where computation is carried out close to the data, which has an impact on performance and efficiency.
- Hardware and Network Requirements: To handle the substantial volume of data transfers between nodes, Hadoop clusters need dependable, high-bandwidth networks. The right hardware resources—including memory and storage—are also necessary for top performance.
Conclusion
- A Hadoop cluster is a collection of interconnected computers or servers that work together to store and process large volumes of data using the Hadoop framework.
- The cluster consists of master nodes (NameNode and Resource Manager) responsible for managing the overall cluster operations.
- Worker nodes (DataNodes and NodeManagers) store and process data, ensuring fault tolerance and resource management.
- Client nodes are machines used by users to interact with the Hadoop cluster, submitting data processing requests.
- Hadoop clusters offer advantages such as scalability, distributed storage, parallel processing, and cost-effectiveness for handling big data.
- Challenges of Hadoop clusters include complexity in setup and management, achieving optimal data locality, and meeting hardware and network requirements for performance optimization.