Introduction to HiveQL
Overview
A query language called HiveQL (Hive Query Language) is used to communicate with Apache Hive, a Hadoop data warehouse and SQL-like query language. For searching and managing massively distributed data held in Hadoop's HDFS (Hadoop Distributed File System) or other comparable storage systems.
Introduction
A data warehousing and query tool built on top of the Hadoop environment, Apache Hive, uses the domain-specific query language known as hadoop hiveql (Hive Query Language). Users can interact with and manage massively distributed data stored in Hadoop's HDFS (Hadoop Distributed File System) or other compatible storage systems using hadoop hiveql, which offers a familiar SQL-like user interface.
HiveQL is intended to make big data analysis and querying easier, especially for individuals who are already comfortable with SQL. It makes difficult underlying Hadoop operations, such MapReduce tasks, more approachable for analysts, data scientists, and other users who are familiar with SQL.
HiveQL Basics
To interact with tables, databases, and queries, Hive provides a SQL like environment through hadoop hiveql. To execute various types of data processing and querying, we can have different types of Clauses for improved communication with various nodes outside the ecosystem. HIVE also has JDBC connectivity.
Following features provide by Hive:
- Creating databases, tables, and other forms of data modelling, etc.
- ETL features such data extraction, transformation, and table loading.
- Joins to combine various data tables.
- User-specific customised scripts for coding simplicity.
- A quicker querying tool built upon Hadoop.
Creating Databases and Tables
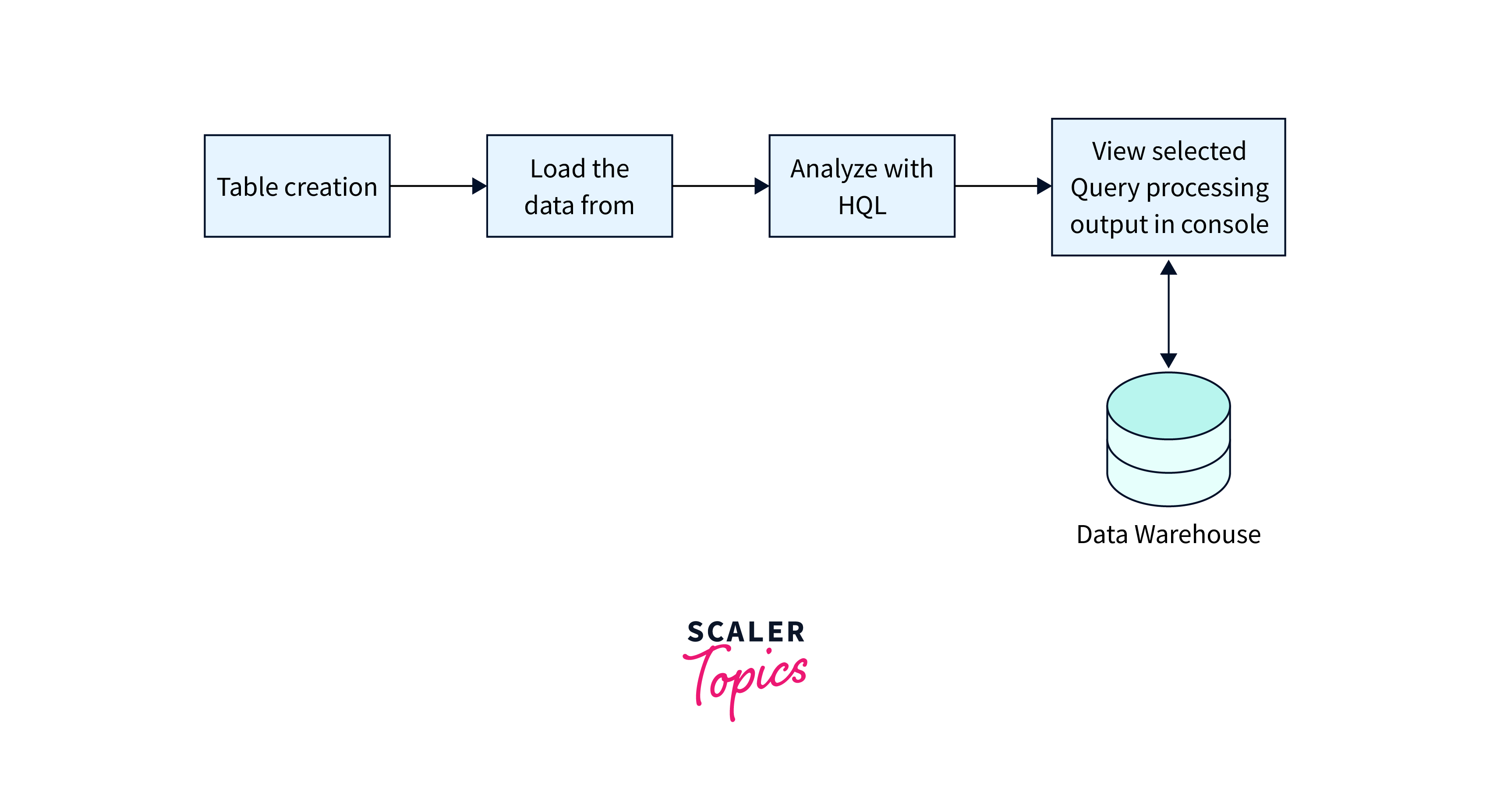
In Hive, a table is a collection of data that is sorted according to a specific set of identifiers using a schema.
Step 1: Create a Database
If a database with the name "mydatabase" doesn't already exist, this statement creates one. The database is only created if it doesn't already exist, thanks to the IF NOT EXISTS condition.
Step 2: Switching to a Database:
By switching to the "mydatabase" database using this line, further activities can be carried out in that database.
Step 3: Creating a Table::
The "employees" table is created with this statement. It has three columns: "id" (integer), "name" (string), and "age" (integer). The table is only generated if it doesn't already exist thanks to the IF NOT EXISTS condition.
Step 4: Creating an External Table::
This hadoop hiveql command creates a new external table called "ext_employees." External tables point to data that is kept in a location independent of Hive, preserving the original location of the data. The HDFS path where the data is located is specified by the LOCATION clause.
Loading Data into Tables
- Load data from HDFS
- Insert data into the table
The LOAD DATA statement inserts data into the designated table from an HDFS path. The "employees" table receives a specific row of data when the INSERT INTO TABLE query is executed.
Querying Data with HiveQL
One of the core functions of using Apache Hive is data querying with HiveQL. You may obtain, filter, transform, and analyse data stored in Hive tables using HiveQL, which is a language comparable to SQL.
Following are a few typical HiveQL querying operations:
1. Select All Records:
This hadoop hiveql command retrieves all records from the "employees" table.
2. Filtering: Example: Select employees older than 25
Only those records from the "employees" table that have a "age" greater than 25 are chosen by this.
3. Aggregation: Example: Count the number of employees
Example: Calculate the average age
These hadoop hiveql queries count the number of employees and determine the average age using aggregation operations on the "employees" table.
4.Sorting: Example: Sort by age in descending order
In order to extract employee names and their related departments, this query connects the "employees" and "departments" databases based on the "department_id" field.
5. Joining Tables: Example: Join employees and departments based on department_id
The "department_id" column is used to link the "employees" and "departments" databases in order to access employee names and their related departments.
6. Grouping and Aggregation: Example: Count employees in each department
This query counts the number of employees in each department and organises employees by department.
7. Limiting Results: Example: Get the top 10 oldest employees
This search returns the ten oldest employees in order of age.
Data Filtering and Sorting
HiveQL offers the means to carry out these actions on your data contained in Hive tables. Data filtering and sorting are crucial data analysis activities. To filter and sort data using HiveQL, follow these steps:
1. Data Filtering: You can use the WHERE clause to filter rows based on specific conditions.
Example: Select marks which are more than 60.
The "marks" table's field must be greater than 60 in order for this query to return all items with that value.
2. Sorting Data: You can use the ORDER BY clause to order the result set according to one or more columns.
Example: Consider ranking the by marks in increasing order.
3.Combining Filtering and Sorting: To obtain particular subsets of data in a specified order, you can combine filtering and sorting.
Example: Select and sort marks more than 60.
Data Transformations and Aggregations
Some examples of data aggregations and transformations you can make with HiveQL:
1. Data Transformations: HiveQL provides a number of built-in functions for changing the data in your query.
Example: Change the case of names
This hadoop hiveql query pulls the "name" column from the "employees" table and uses the UPPER function to change the names to uppercase.
2.Aggregations: Using functions like COUNT, SUM, AVG, and others, aggregates let you condense data.
Example: Calculate the average age of the workforce, for instance.
Using the AVG function, this query determines the average age of every employee in the "employees" table.
3. Grouping and Aggregating: To group data into categories, the GROUP BY clause is used with aggregate functions.
Example: For instance, total the personnel in each department.
The COUNT function is used in this query to count the number of employees in each department and group the employees by the "department" column.
4.Filtering Before Aggregating: Before doing aggregations, data transformations and filtering might be used.
Example: Calculate the typical age of your staff members that are over 35.
This hadoop hiveql query determines the average age of the filtered subset of employees by first excluding those over the age of 35.
Joins and Subqueries
HiveQL's advanced features, including as joins and subqueries, let you aggregate data from various tables and run sophisticated searches.
Using HiveQL, let's examine how to use joins and subqueries:
1. Joins: With the use of joins, you can merge rows from various tables based on a shared column. The INNER JOIN, LEFT JOIN, RIGHT JOIN, and FULL OUTER JOIN are examples of common join types.
Example: As an illustration, retrieve the employees and the corresponding departments from an inner join.
Based on the "department_id" column, this query combines information from the "employees" and "departments" tables to retrieve employee names and their related departments.
2. Subqueries: A subquery is a query that is nested inside another query. The SELECT, WHERE, and FROM clauses can all use them.
Example: Determine the typical age of employees in each department using a subquery in the SELECT statement.
The average age of employees for each department in the "departments" dataset is determined by this query using a subquery.
3. Correlated Subqueries: An inner query that depends on results from the outer query is referred to as a correlated subquery.
Example: Find employees whose ages are higher than the department's average, for instance.
To locate employees whose ages are higher than the mean ages of employees in the same department, this query uses a correlated subquery.
Conclusion
- HiveQL (Hive Query Language) is used to communicate with Apache Hive, a Hadoop data warehouse and SQL-like query language.
- Hive provides a SQL-like environment through hadoop hiveql for interacting with tables, databases, and queries.
- Hive offers features like creating databases, tables.
- HiveQL allows data retrieval, filtering, transformation, and analysis. Common querying operations include SELECT, WHERE, ORDER BY, and JOIN.
- HiveQL provides built-in functions for data transformations and aggregation. Aggregations use functions like COUNT, SUM, AVG, etc., to condense data.