SQOOP in Hadoop
Overview
Hadoop Sqoop is a powerful tool that is used for data transfer between Hadoop and relational databases. Hadoop is used for processing big data which may be stored in relational databases or collected from other sources and hadoop sqoop plays a vital role in simplifying the data integration process between Hadoop and databases.
Introduction
Hadoop Sqoop is a powerful data transfer tool that serves as a bridge between Hadoop and relational databases. It enables seamless integration and efficient movement of data between the Hadoop Distributed File System (HDFS) and popular databases such as MySQL, Oracle, and SQL Server.
There are Two Major Operations Performed in Sqoop
An operation in Hadoop Sqoop is an action performed to transfer data between Hadoop and relational databases.
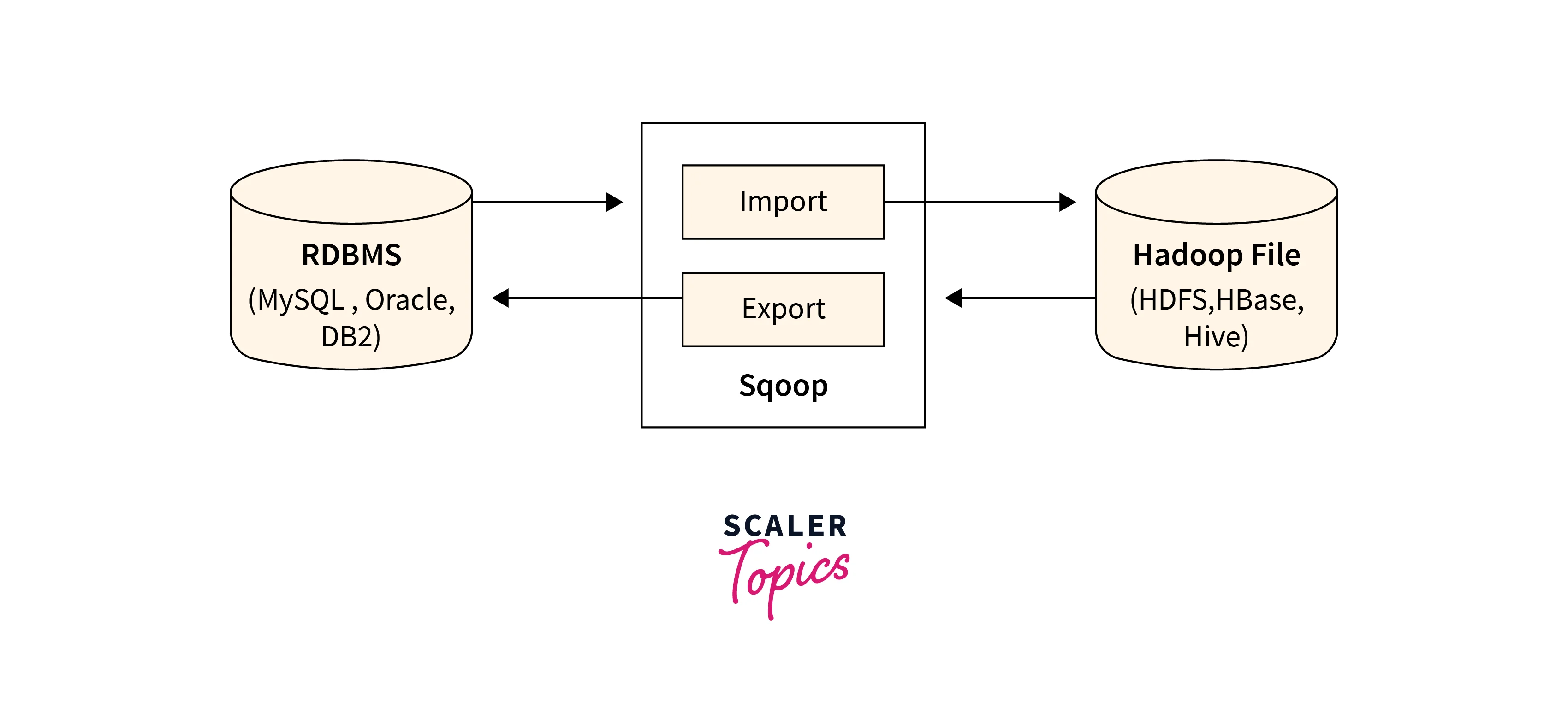
Sqoop Import
The Sqoop Import operation is used to transfer data from a relational database into Hadoop. It reads the data from tables and imports it into Hadoop, storing the results in HDFS.
Syntax:
Explanation:
- sqoop import: Initiate the import operation using hadoop sqoop.
- --connect Connection string to the database. It begins with jdbc followed by the specific database type, host, port, and database name.
- --username: Username for accessing the database.
- --password: Password for the specified username.
- --table: Name of the table from which data will be imported.
- --target-dir: HDFS directory where the imported data will be stored.
- --fields-terminated-by: The Delimiter character that separates the fields (columns) in the imported data.
- --lines-terminated-by: Delimiter character that marks the end of a line in the imported data.
Example:
Output:
Explanation:
Upon executing the above command, hadoop sqoop will perform the following processes,
- Connect to the MySQL database using the provided credentials.
- Retrieve the data from the employees table.
- Import it into the specified /user/hadoop/employees HDFS directory.
Sqoop Import supports parallel processing, allowing it to efficiently import large datasets.
Sqoop Export
The Hadoop Sqoop Export operation is used for the transfer of data from Hadoop to a relational database. It takes data from HDFS and exports it to a target database table.
Syntax:
Explanation:
- sqoop export Initiate the export operation using Hadoop Sqoop.
- The --connect, --username and --password are similar to the previous command.
- --table: The target database table where the data will be exported.
- --export-dir: The HDFS directory containing the data to be exported.
- --input-fields-terminated-by: Delimiter character that separates the fields (columns) in the exported data.
- --input-lines-terminated-by: Delimiter character that marks the end of a line in the exported data.
Example:
Output:
Explanation:
Upon executing the above command, hadoop sqoop will perform the following steps,
- Establish a connection to the MySQL database.
- Read the data from the/user/hadoop/output_data HDFS directory.
- Format the data according to delimiters for fields and lines.
- Transfer data from HDFS to the output_table table.
Sqoop Working
The working of Sqoop involves several components and follows a series of steps to transfer data between Hadoop and relational databases. The various components of Sqoop are,
- Sqoop Client: A user interface that receives the commands and parameters provided by the user to initiate the data transfer operations.
- Sqoop Server: Receives the commands from the Sqoop Client, interacts with the Hadoop cluster, and manages the data transfer process.
- Hadoop Cluster: Collection of interconnected nodes that form the Hadoop ecosystem. It includes the HDFS for storing data and the MapReduce framework for distributed processing.
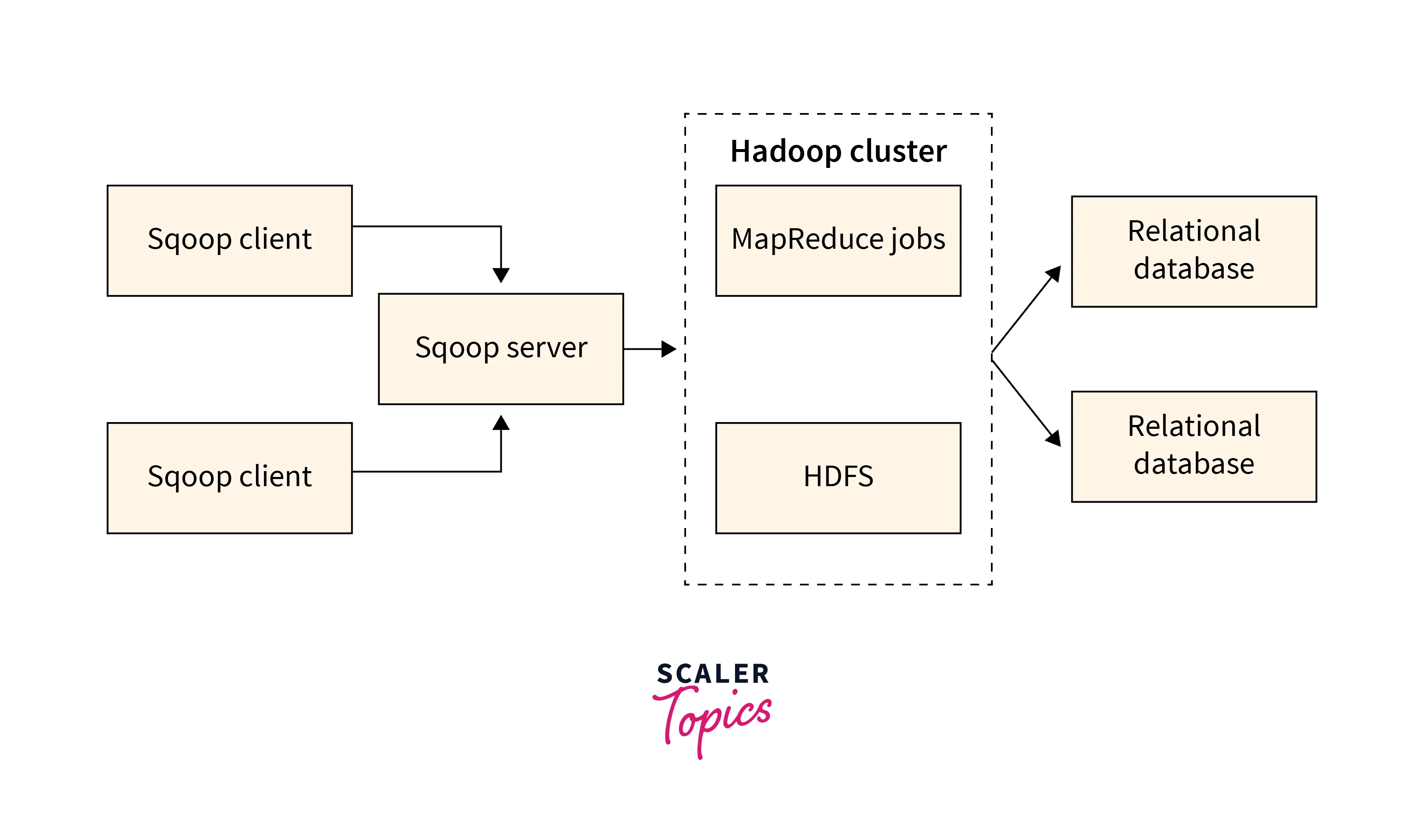
The steps for the transfer of data performed by hadoop sqoop are:
- Initiate data transfer operation by Sqoop command through the Sqoop Client.
- The Sqoop Client submits the Sqoop job to the Sqoop Server.
- The Sqoop Server interacts with the Hadoop Cluster to perform the data transfer operations. It utilizes the parallel processing capabilities of the MapReduce framework.
- During the data transfer process, Sqoop divides the data into multiple splits and assigns each split to a mapper task.
- These mapper tasks operate in parallel across the nodes in the Hadoop Cluster.
- The mappers retrieve data from the source database (in case of import) or from HDFS (in case of export) and perform the necessary operations.
- Sqoop can also perform data transformation and serialization tasks based on the specified configurations.
- Once the data transfer process is complete, Sqoop provides feedback on the progress or any encountered errors or warnings.
Advantages of Sqoop
- Provides a seamless integration between Hadoop and relational databases.
- Automates the process of importing and exporting data, saving time and effort.
- Utilizes the scalability of Hadoop, allowing it to handle large volumes of data efficiently.
- Supports parallel processing, enabling faster data transfer and processing.
- Allows users to customize the import and export process by different configuration options.
- Supports incremental imports, allowing users to import only the new or modified data from the source database.
- Hadoop Sqoop can also be integrated with other components of the Hadoop ecosystem, such as Hive and Pig for advanced analytics.
- Ensures data integrity during the import and export process.
- Supports a wide range of relational databases, including MySQL, Oracle, SQL Server, and more.
- Strong community support, making it easier to resolve issues and stay updated with the latest features.
- Hadoop Sqoop is an open-source** tool, making it a cost-effective solution for data transfer.
- Provides security features such as authentication and encryption, ensuring the privacy and protection of transferred data.
Disadvantages of Sqoop
- Primarily focuses on batch processing and doesn't provide low-latency data transfer capabilities making it not suitable for real-time data integration scenarios.
- Does not offer built-in complex data transformations capabilities.
- Does not have built-in change tracking mechanisms and relies on users to explicitly specify incremental imports to transfer only the changed or new data.
- Does not provide built-in mechanisms for data validation during the import/export process.
- Hadoop Sqoop may not handle complex data structures, such as nested or hierarchical data, as effectively as other specialized tools.
- Sqoop is primarily command-line driven, lacking a graphical user interface (GUI).
- During the data export process, Sqoop can impact the performance of the database system.
Conclusion
- Hadoop Sqoop is a tool for data transfer between Hadoop and relational databases.
- Sqoop offers import and export operations.
- Import operation transfers data from a database into Hadoop and Sqoop Export exports data from Hadoop to a database.
- Hadoop sqoop works by dividing data into splits, assigning them to mapper tasks, and performing parallel processing in the Hadoop cluster.
- Advantages of Sqoop include integration with Hadoop and ecosystem, simplicity, community support, scalability, and customizable import/export operations.
- Disadvantages of Sqoop include its focus on batch processing, lack of real-time capabilities, limited support for data structure and data transformation, and performance issues.
- Despite its limitations, Hadoop Sqoop remains a valuable tool in the big data landscape, simplifying data transfer and integration between Hadoop and relational databases.