Hadoop vs. Spark What's the Difference?
Overview
Hadoop and Spark are two big data processing systems that aim to address the issues of dealing with enormous datasets. Hadoop is well-known for its distributed file system and MapReduce processing, but it also excels in batch processing and fault tolerance. However, Spark is suitable for real-time analytics and iterative algorithms because of its lightning-fast in-memory computation and versatile data processing capabilities. Although Hadoop is older and more stable, Spark's growing popularity stems from its speed and versatility. The choice between the two is based on your data needs and processing requirements.
Introduction
Before learning about Hadoop vs Spark, let us first learn about Hadoop and Spark.
Hadoop and Spark are open-source technologies that have transformed how we process and analyze large amounts of data. While both strive to address big data concerns, they have various features and functionalities that make them distinctive. In this article, we'll compare and contrast Hadoop and Spark to help you decide between the two based on your requirements.
- Hadoop: The Reliable Workhorse
Hadoop is a distributed processing system for large-scale data processing jobs. It stores data in the Hadoop Distributed File System (HDFS) and processes it using MapReduce. Hadoop's strength is its fault tolerance, which allows it to recover from faults in real-time. Hadoop's batch processing technique makes it perfect for batch analytics, data warehousing, and applications requiring fault tolerance.
- Spark: The Lightning-Fast Innovator
Spark is a highly efficient, quick, and versatile big data processing engine. Unlike Hadoop, which relies on disk storage, Spark uses in-memory computation, dramatically increasing its processing speed. Because of Spark's capacity to cache data in memory, it is perfect for machine learning, real-time analytics, and interactive querying. Furthermore, Spark's extensive API set supports several languages, giving developers greater freedom.
What is Apache Hadoop?
Before learning about Hadoop vs Spark, let us get familiar with Apache Hadoop.
Apache Hadoop has revolutionized the world of big data processing, enabling organizations to deal with massive amounts of data while gaining valuable insights. Hadoop, an open-source platform, has emerged as a game changer in dealing with the problems presented by the ever-expanding data landscape. In this article, we'll look at the core components of Apache Hadoop and how they help businesses harness the power of big data.
To learn more about Apache Hadoop, click here.
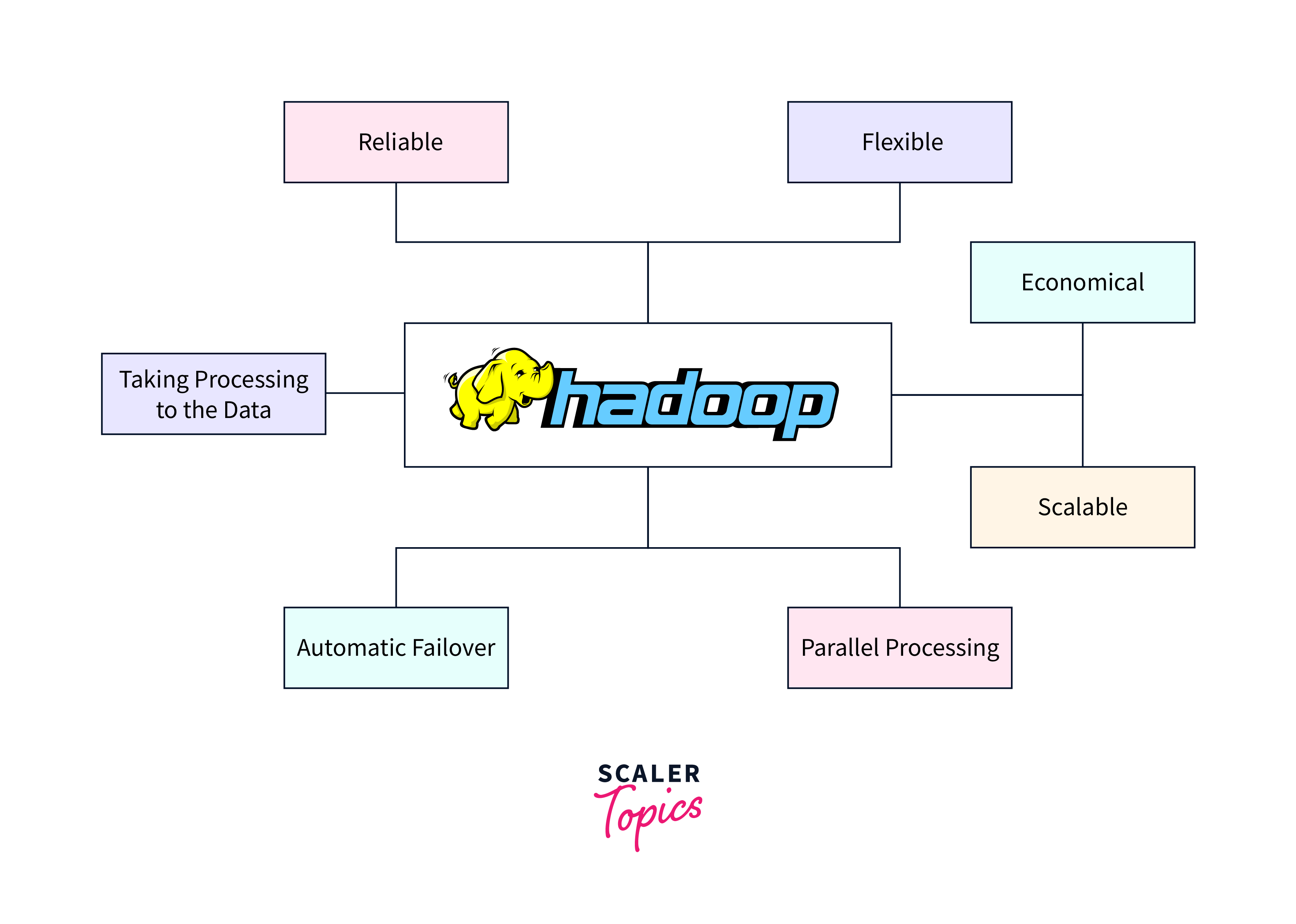
Benefits of the Hadoop Framework
Let's look at the top five advantages of using Hadoop.
-
Scalability and Flexibility: Hadoop provides high scalability, allowing organizations to handle huge amounts of data easily. It stores data across multiple workstations using a distributed file system (HDFS), allowing for seamless computation as data grows. Organizations may swiftly grow their Hadoop clusters by adding or deleting nodes as needed, allowing them to meet both present and future data demands.
-
Cost-Effective Storage: Traditional data warehousing systems may be relatively expensive due to the need for specialized equipment. On the other hand, Hadoop can run on low-cost technology, considerably cutting infrastructure costs. Additionally, its distributed data storage and processing capabilities reduce the requirement for expensive storage systems. Hadoop allows businesses to store and manage massive amounts of data cost-effectively, making it an enticing alternative for many.
-
Enhanced Data Processing Speed: Hadoop's distributed processing framework, MapReduce, enables the parallel processing of huge amounts of data over multiple nodes. This considerably improves data processing performance as compared to traditional systems. With Hadoop's capacity to break down large jobs into smaller sub-tasks and distribute them across the cluster, organizations can gain faster insights and actionable results, resulting in speedier decision-making.
-
Fault Tolerance and High Availability: The fault-tolerant design of Hadoop provides data reliability and continuous availability. By replicating data across several nodes, Hadoop can withstand node outages without jeopardizing data integrity. It automatically detects faults and redistributes tasks to healthy nodes, reducing downtime and ensuring continuous data processing.
-
Advanced Analytics: Combining Hadoop with various analytical tools, including Apache Spark and Apache Hive, enables organizations to do complicated analytics on big datasets. These technologies offer powerful data processing capabilities such as machine learning, predictive modelling, and real-time analytics.
To learn more about the Hadoop framework, click here.
What is Apache Spark?
Before learning about Hadoop vs Spark, let us get familiar with Apache Spark.
Apache Spark is a distributed computing solution that is open source and built to handle large-scale data processing and analytics operations. It offers a consistent framework for various workloads, including batch processing, real-time streaming, machine learning, and graph processing.
To learn more about Apache Spark, click here.
Benefits of Spark
In this section, we will explore the top five benefits of Spark and how it can revolutionize your data-driven operations.
-
Lightning-Fast Data Processing: Spark's in-memory computation allows for extremely fast data processing. Spark reduces disk I/O by retaining data in memory rather than persisting it to the disk, resulting in much faster processing times. This real-time processing feature is crucial for time-sensitive applications such as fraud detection, analytics, and recommendation systems.
-
Seamless Scalability: Spark's distributed computing paradigm enables infinite scalability. It can easily handle large-scale datasets by splitting the workload across numerous nodes, allowing for horizontal scalability. Spark can scale to suit your demands, whether you're processing terabytes or petabytes of data, delivering smooth performance without sacrificing efficiency.
-
Comprehensive Data Processing Capabilities: Spark offers a rich set of tools and libraries to help with various data processing tasks. It has sophisticated batch processing (Spark Core), real-time streaming (Spark Streaming), interactive queries (Spark SQL), machine learning (Spark MLlib), and graph processing (GraphX) components. Spark's adaptability makes it a one-stop shop for various data processing needs.
-
Fault Tolerance and Reliability: The fault tolerance measures built into Spark provide reliable data processing. It recovers from faults automatically by transferring work to other nodes in the cluster, in case of node failure, assuring continuous functioning. This comprehensive fault tolerance method removes the possibility of data loss and ensures consistent and reliable results even in the case of hardware or network failures.
-
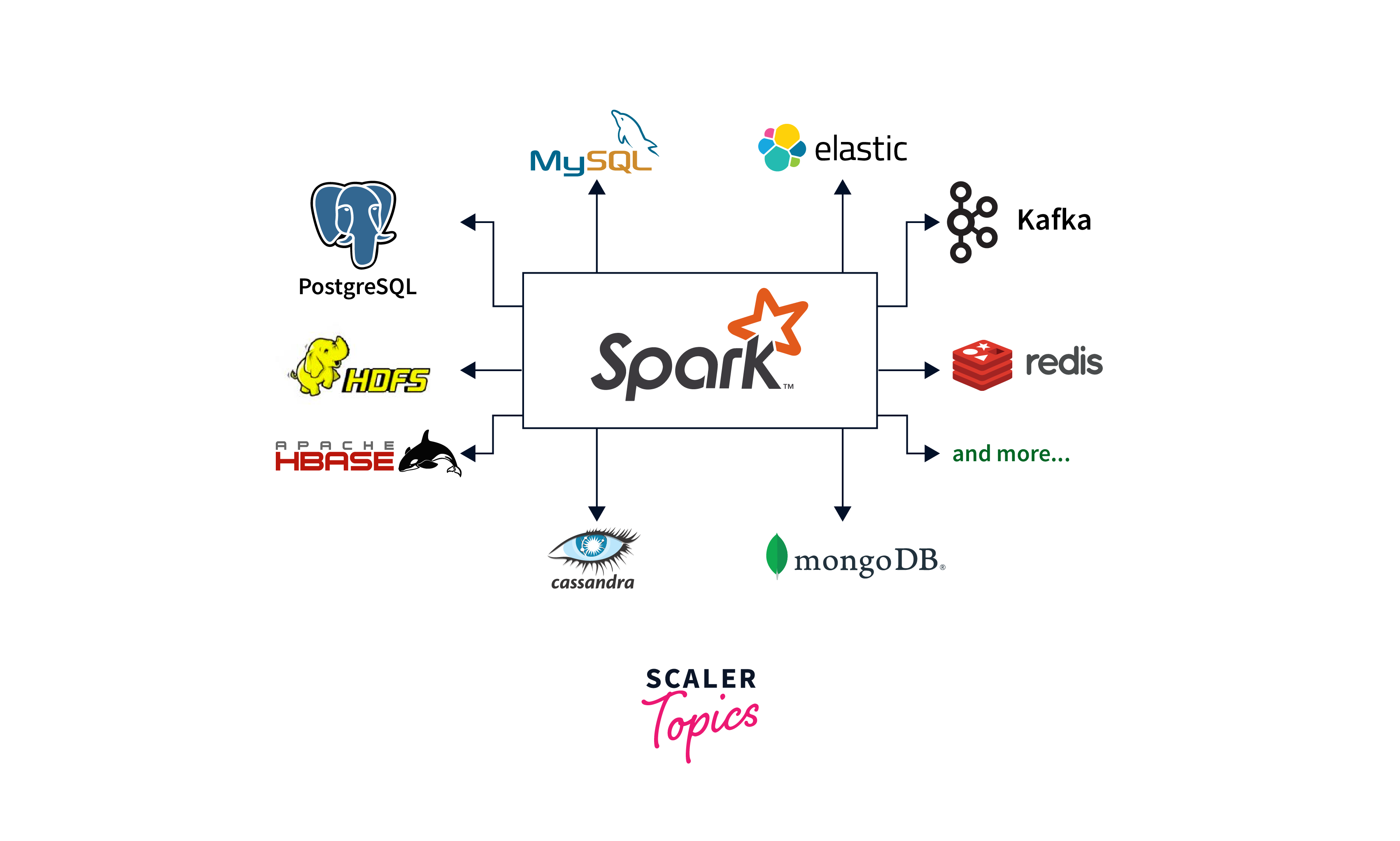
Seamless Integration and Ecosystem: Spark interfaces seamlessly with common data sources and frameworks like Hadoop, Cassandra, and Apache Kafka. This interoperability enables you to leverage infrastructure investments, making Spark more easily integrated into your data environment. Furthermore, Spark has a thriving and active community that creates new connectors, tools, and libraries, expands its ecosystem, and offers access to various resources.
To learn more about Spark, click here.
The Hadoop Ecosystem
The Hadoop ecosystem comprises numerous tools and technologies that work together to address big data concerns. The Hadoop Distributed File System (HDFS) and MapReduce are the two most important components.
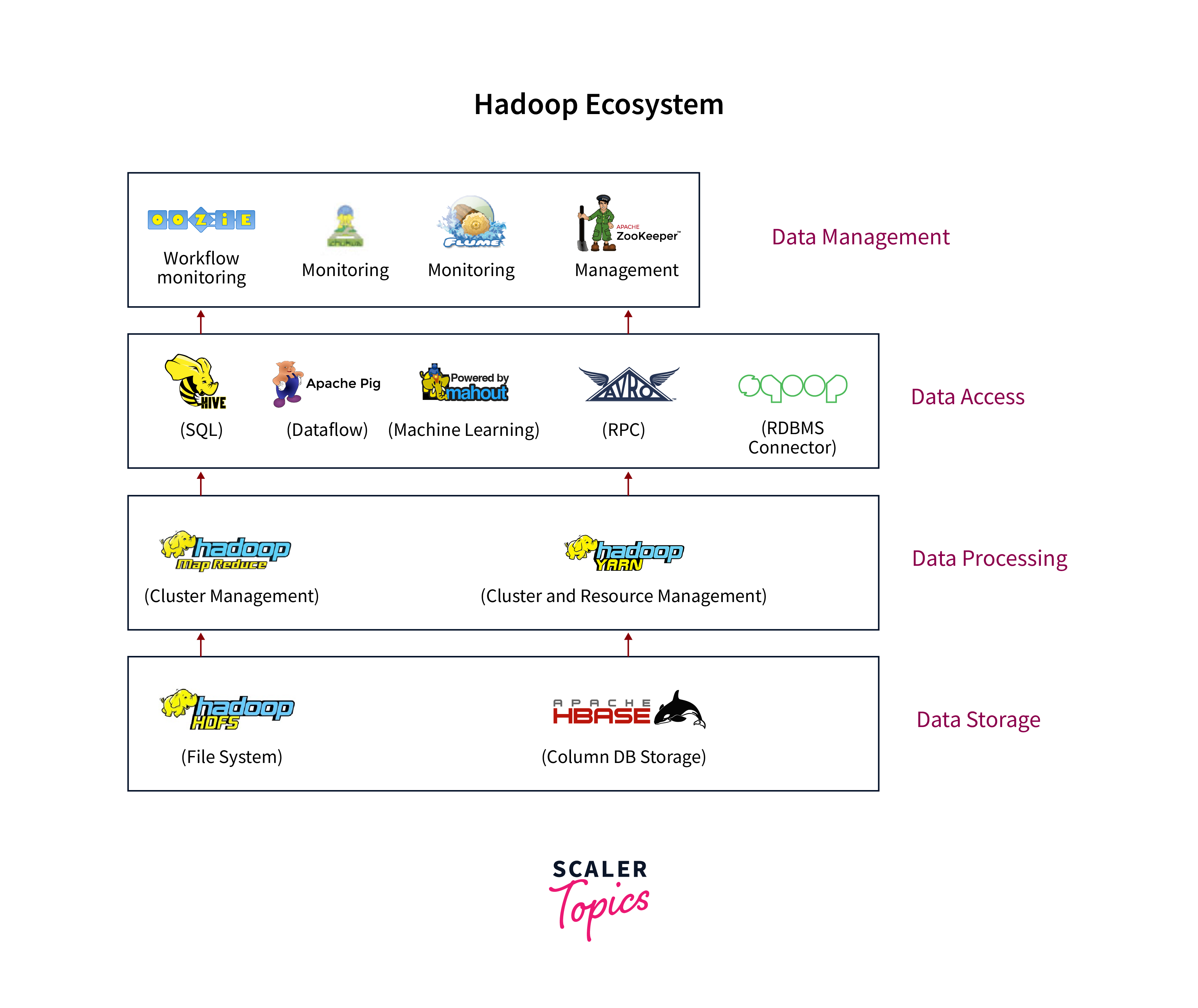
HDFS, built to store and manage massive volumes of data across several machines, ensures fault tolerance and high availability. HDFS facilitates parallel processing by dividing data into smaller pieces and distributing them across a cluster, allowing for speedy and efficient data analysis.
Hadoop's processing engine, MapReduce, enables distributed data processing. It breaks data into smaller parts, distributes them among cluster nodes, and executes parallel calculations. MapReduce breaks down complex jobs into Map and Reduce functions, allowing for faster data processing and analysis.
The Hadoop Ecosystem - Primary Modules
Let's take a quick overview of the four primary modules of the Hadoop ecosystem.
Hadoop Distributed File System (HDFS)
HDFS is the backbone of Hadoop's storage system. Large files are divided into smaller blocks and distributed across numerous servers in a cluster, ensuring high availability and fault tolerance. Hadoop's distributed nature enables it to handle large datasets effectively.
Yet Another Resource Negotiator (YARN)
YARN serves as the Hadoop cluster's operating system. It controls and distributes resources to the various apps running on the cluster. Because of YARN's versatility, Hadoop can run multiple workloads simultaneously, including MapReduce, Spark, and Hive, making it a versatile and adaptable architecture.
Hadoop MapReduce
Hadoop MapReduce is a programming model and processing engine that enables developers to process and analyze massive volumes of data concurrently. It breaks down difficult distributed computing jobs into smaller, manageable subtasks that are subsequently executed across the cluster. MapReduce's fault tolerance and scalability make it excellent for efficiently processing large-scale datasets.
Hadoop Common (Hadoop Core)
This module contains the libraries and utilities required by other Hadoop ecosystem components. It offers critical features, including input/output activities, networking, and security. Hadoop Common is the backbone of the ecosystem, ensuring seamless integration and interoperability across its numerous components.
The Main Components of Apache Spark
Let's take a quick overview of the components of Apache Spark.
Spark Core
Spark Core is at the heart of Apache Spark, providing the fundamental functionality for distributed task scheduling, memory management, and fault recovery. It allows Spark to distribute data across a cluster and do jobs in parallel, ensuring fast processing and fault tolerance.
Spark SQL
Spark SQL includes a robust engine and a programming interface for working with structured and semi-structured data. It enables users to access and manipulate data using SQL-like language, making integration with existing data processing tools and workflows easy.
Spark Streaming and Structured Streaming
Spark Streaming allows for real-time data processing by splitting continuous data streams into discrete batches that Spark's core engine can handle. Structured streaming expands this functionality by offering high-level APIs for processing of streaming data, making it easier to design robust and scalable streaming applications.
Machine Learning Library (MLlib)
MLlib is a comprehensive Apache Spark library with many machine-learning tools. It makes machine learning pipeline construction and deployment easier, allowing data scientists and developers to build and train models at scale.
GraphX
GraphX is a graph processing toolkit that allows Spark to handle graph-structured data. It features a set of optimized graph algorithms and an API for defining graph computing workflows. Users may efficiently analyze and process large-scale graph data with GraphX.
Comparing Hadoop and Spark
Let us look into the differences between Hadoop and Spark (i.e. Hadoop vs Spark) based on some parameters.
Performance
Hadoop is well-known for its capacity to manage enormous amounts of data. It is based on MapReduce, a batch-processing framework that excels at handling large amounts of data. However, Spark offers faster data processing and real-time analytics thanks to its in-memory processing engine. It improves performance by reducing disk I/O, making it excellent for iterative computations.
Cost
Hadoop is an open-source software that can be run on commodity hardware, making it a low-cost option. Although Spark is also open-source, its in-memory processing demands more resources, potentially increasing infrastructure expenses.
Processing
Hadoop's batch-processing nature is ideal for applications that require substantial data transformations and aggregations. It is useful for offline processing and long-running operations. In contrast, Spark's ability to store data in memory enables iterative processing, making it appropriate for real-time analytics and interactive queries.
Scalability
The distributed computing concept of Hadoop allows for infinite scalability. It can handle large datasets by dividing the burden among numerous nodes. Spark, built on top of Hadoop, inherits this scalability but adds extra benefits with its resilient distributed dataset (RDD) abstraction, allowing quicker data processing.
Security
Security capabilities such as authentication, authorization, and data encryption are available in both Hadoop and Spark. Hadoop has a more established ecosystem with extensive security frameworks such as Kerberos and Apache Ranger, making it a preferred choice for organizations with rigorous security requirements.
Machine Learning (ML)
With its MLlib library, Spark has gained traction in the machine learning industry. MLlib includes a comprehensive range of machine learning algorithms and tools that make creating and deploying scalable ML models easy. While Hadoop supports machine learning with libraries such as Mahout, Spark's in-memory processing and integration with other data processing capabilities offer it an advantage in ML jobs.
Misconceptions about Hadoop and Spark
Myth: Hadoop and Spark Cannot Coexist
Reality: While both are used for big data processing, Hadoop uses HDFS to work in a distributed manner, whereas Spark is a data processing engine that is lightning-fast. They work well together, with Hadoop providing storage and Spark offering real-time analytics.
Myth: Hadoop and Spark are Only Appropriate for Large Businesses
Reality: Hadoop and Spark benefit small and medium-sized organizations equally. The scalability of Hadoop and the speed of Spark make them adaptable and cost-effective for organizations of all sizes.
Myth: Spark is a Replacement for Hadoop
Reality: Although Spark provides better processing speeds, it does not replace Hadoop. On the other hand, Spark uses Hadoop's distributed storage architecture to improve data processing capabilities. They collaborate to provide effective big data solutions.
Myth: Hadoop and Spark Require Substantial Programming Knowledge
Reality: While programming knowledge can be advantageous, both Hadoop and Spark provide high-level abstractions that simplify development. Tools like Hive and Pig make it possible to work with these technologies without deep coding expertise.
Hadoop and Spark Use Cases
Hadoop Use Cases
- Scalable Data Warehousing: Enterprises can develop scalable data warehouses utilizing Hadoop's distributed file system. Organizations may obtain deeper insights and confidently make data-driven choices by storing and analyzing huge volumes of structured and unstructured data.
- Log Analytics: Because of Hadoop's capacity to efficiently process massive volumes of log data, it is a good candidate for log analytics. Businesses may extract important insights from log files, discover anomalies, find patterns, and improve operational efficiency by exploiting their distributed processing capabilities.
Spark Use Cases
- Real-Time Stream Processing: Because Spark's processing engine is so quick, it's suited for real-time stream processing. Organizations can analyze and respond in near real-time to continuous data streams, allowing them to detect fraud, monitor network activity, and generate actionable insights instantly.
- Machine Learning and Artificial Intelligence: Spark's machine learning library (MLlib) enables enterprises to design and deploy advanced AI models at scale. Organizations can effectively train complicated machine learning algorithms on big datasets by exploiting Spark's distributed computing capabilities, and facilitating activities like image recognition, natural language processing, and recommendation systems.
Conclusion
- Hadoop is great for data-intensive applications because it is well-suited to batch processing and large-scale data storage.
- In contrast, Spark excels at real-time data processing and iterative algorithms, allowing for speedier performance and interactive analytics.
- The MapReduce paradigm in Hadoop is reliable and fault-tolerant, ensuring high data integrity and fault recovery.
- Spark's in-memory processing feature improves performance significantly, allowing for faster data analysis and iterative computations.
- The Hadoop ecosystem provides a broad set of tools that work together to address big data concerns.