HBase Architecture - Detailed Explanation
HBase is a component of the Apache Hadoop ecosystem, it offers a scalable and distributed database solution using HDFS. Ideal for handling large-scale data with low-latency access, it addresses some of HDFS's high-latency and read/write limitations. However, HBase has its challenges, such as memory issues and single points of failure. Let's now explore what you need to know to dive into HBase architecture.
Pre-requisites
- Java and Hadoop must be installed on your Linux workstation before you can install HBase.
- Hbase may be installed in three different ways: standalone, pseudo-distributed, and fully distributed.
- Hbase may be downloaded at http://www.interior-dsgn.com/apache/hbase/stable/. then unzip it using the steps listed below.
What is HBase?
HBase is a column-oriented distributed database developed on top of the Hadoop file system. It is an open-source project that may be scaled horizontally.
HBase is a data format equivalent to Google's big table that allows for speedy random access to massive volumes of structured data. It makes use of the Hadoop File System's (HDFS) fault tolerance.
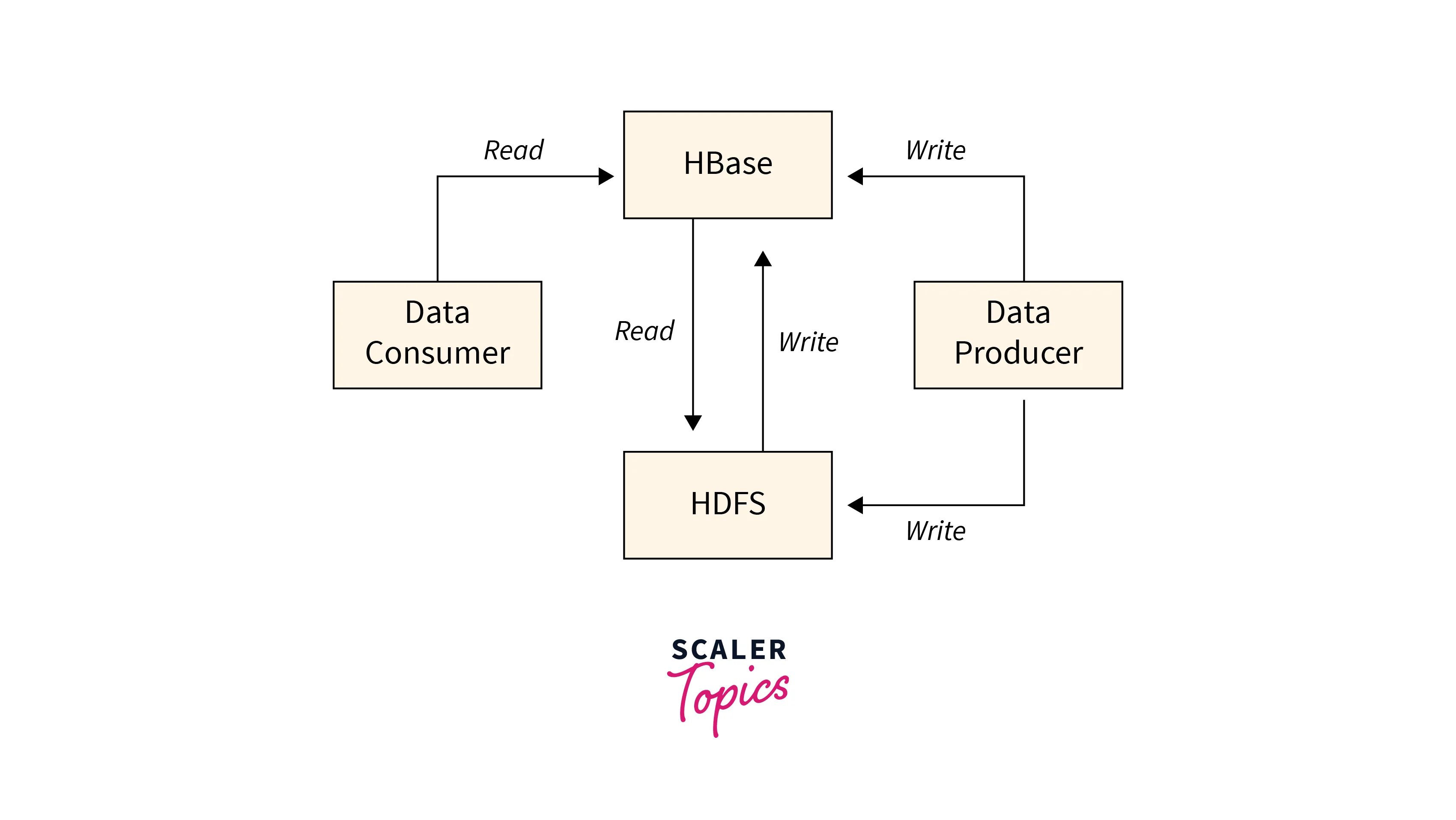
It is a Hadoop ecosystem component that allows for random real-time read/write access to data in the Hadoop File System. Data may be stored in HDFS directly or through HBase.
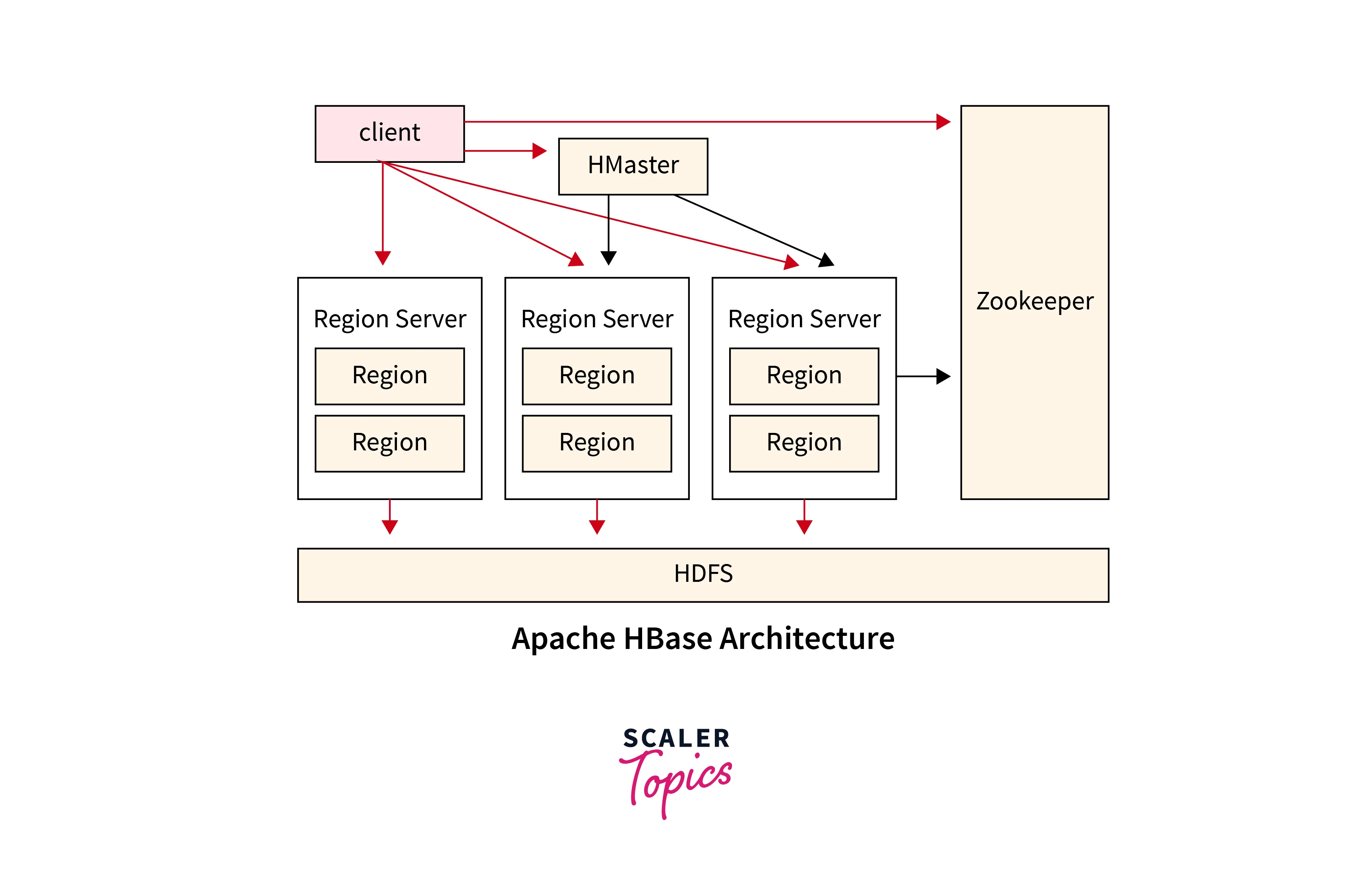
The 3 Main Components of HBase Architecture
HMaster
HMaster in HBase is the HBase architecture’s implementation of a Master server. It serves as a monitoring agent for all Region Server instances in the cluster along with as an interface for any metadata updates. HMaster runs on NameNode in a distributed cluster context.
HMaster plays the following critical responsibilities in HBase:
- It is critical in terms of cluster performance and node maintenance.
- HMaster manages admin performance, distributes services to regional servers, and assigns regions to region servers.
- HMaster includes functions such as regulating load balancing and failover to distribute demand among cluster nodes.
- When a client requests that any schema or Metadata operations be changed, HMaster assumes responsibility for these changes.
Region Server
The Region Server, also known as HRegionServer, is in charge of managing and providing certain data areas in HBase. A region is a portion of a table's data that consists of numerous contiguous rows ordered by the row key. Each Region Server is in charge of one or more regions that the HMaster dynamically assigns to it. The Region Server serves as an intermediary for clients sending write or read requests to HBase, directing them to the appropriate region based on the requested column family. Clients can connect with the Region Server without requiring HMaster authorization, allowing for efficient and direct access to HBase data.
Advantages:
- Region Servers in HBase enable distributed data management, allowing data partitioning across Hadoop cluster nodes, parallel processing, fault tolerance, and scalability.
- Region Servers process read/write requests directly, reducing network overhead and latency, and improving performance by eliminating centralized coordination and reducing latency.
- Region Servers allow HBase to automatically split regions into smaller ones as data accumulates. This assures uniform distribution and increases query speed and load balancing.
Zookeeper
ZooKeeper is a centralized service in HBase that maintains configuration information, provides distributed synchronization, and provides naming and grouping functions.
Say some advantages offered by ZooKeeper are:
- Distributed Coordination: Allows HBase components to coordinate for consistent functioning.
- Monitoring Cluster Membership and Health: Tracks node membership and health for stability.
- Metadata Storage: Storage of essential metadata for effective operation and coordination.
- Synchronization and Notification: Provides techniques for synchronization and event notification.
- Leader Election: Allows for the accurate selection of leaders for cluster management.
ZooKeeper's advantages in HBase:
- High Availability: A fault-tolerant design that ensures operational continuity.
- Scalability: Horizontal scalability to manage rising demands and bigger clusters.
- Reliable Coordination: Ensures that actions across components are consistent and ordered.
- Simplified Development: Offloads coordinating tasks, simplifying distributed system development.
Advantages of HBase
- When compared to typical relational models, operations such as data reading and processing in Hbase are much faster.
- Random read and write operations are supported by Hbase, providing quick access to select data records.
- Hbase integrates with Java client, Thrift, and REST APIs, allowing for greater flexibility in application creation and integration.
- Hbase works smoothly with MapReduce, Hive, and Pig, providing efficient and scalable data processing and analytics inside the Hadoop environment.
Disadvantages of HBase
- HBase integration with pig and Hive jobs causes some cluster memory concerns.
- In a shared cluster environment, fewer task slots per node are required to allot HBase CPU requirements.
- It features a single point of failure, which means that if HMaster fails, the entire cluster fails.
- In the Hbase table joining and normalization is very difficult.
- Hbase has no built-in authentication or permissions.
Comparison between HBase and HDFS
| HDFS | HBase |
|---|---|
| HDFS is fault-tolerant and cost-effective. | Hbase provides flexibility and strong consistency. |
| HDFS supports only sequential read and write operations. | Random access is possible in Hbase due to its underlying hash table implementation. |
| HDFS is designed with a write-once, read-many principle. | Hbase enables random filesystem read and write operations. |
| HDFS exhibits significant latency for access activities. | Hbase enables quick access to small data portions. |
Features of HBase Architecture
Distributed and Scalable
- HBase is designed to be naturally distributed, providing parallel processing, high availability, fault tolerance, and the ability to handle massive volumes of data. It also offers horizontal scalability, allowing easy addition of nodes to accommodate expanding data volumes and workloads while maintaining speed and responsiveness.
Column-oriented Storage
- HBase employs a column-oriented storage model, which means that data is organized and stored in columns rather than rows.
- This storage type allows rapid read and write operations for analytical queries and aggregations, as well as quick retrieval of specified columns.
Hadoop Integration
- HBase is intended to connect easily with the Hadoop environment, providing direct access to and integration with other Hadoop components such as MapReduce, Hive, and Spark.
- This interface allows HBase to make use of Hadoop's distributed data processing and analytics capabilities.
Consistency and Replication
- Hbase guarantees robust consistency by allowing for rigorous consistency models in which data modifications are immediately visible and consistent across all copies.
- The Hbase architecture contains built-in replication techniques for replicating data across several nodes or clusters.
Built-in Caching
- Hbase includes an in-built caching technique that boosts read speed by storing frequently requested data blocks in memory.
- The BlockCache caching system minimizes disk I/O and latency, resulting in speedier data retrieval for future read operations.
Compression
- Hbase supports several compression methods, including Snappy and LZO, to minimize the amount of data saved on disk.
- This compression function not only reduces storage space but also speeds up data movement, which is very useful when working with massive datasets.
Flexible Schema
- Hbase is based on flexible schema architecture that allows developers to add or edit columns dynamically without needing downtime or costly schema migrations.
- This adaptability enables applications to evolve and adapt to new data requirements without interfering with existing operations.
Conclusion:
- HBase is a distributed and scalable database with column-oriented storage, strong consistency, replication, caching, compression, and flexible schema. It excels in handling large volumes of data, providing fast random access and improved read performance. It seamlessly integrates with the Hadoop ecosystem, enabling efficient data processing and analytics.
- It has built-in caching mechanisms that enhance read performance by storing frequently accessed data blocks in memory.
- Hbase supports compression techniques to reduce storage requirements and improve data transfer speeds.
- The adaptable schema architecture enables dynamic column addition and adjustment in response to changing data requirements.