HBase in Hadoop
Overview
HBase in Hadoop ecosystem is a distributed, scalable, and highly reliable NoSQL database. It's built to deal with large amounts of sparse data, making it perfect for real-time applications. HBase in Hadoop is a Hadoop Distributed File System (HDFS) database allowing fast read and write access to huge datasets. Data is organized into tables, rows, and columns using a column-family paradigm. This architecture enables fast storage and retrieval. Combining HBase with Hadoop technologies enables enterprises to dive into big data research while maintaining flexibility and performance.
HBase History
Consider a virtual storage place where you can store massive volumes of data, similar to a massive digital library. HBase in Hadoop can be utilized for this use case. HBase is an open-source, distributed database system designed to manage huge amounts of data in a reliable and scalable manner.
HBase has a fascinating backstory. It began as a Google internal project called Bigtable, which attempted to efficiently manage massive amounts of data. HBase was born in the Apache Software Foundation as a result of this. It quickly gained traction in big data due to its capacity to store and manage huge amounts of data.
HBase's horizontal scalability is one of its primary characteristics, which means adding more servers to manage more data without disturbing the system. This makes it ideal for applications where data volume grows rapidly.
Hadoop Random Access Databases
One noteworthy component of Hadoop is its capacity to manage random access databases, which marks a significant break from the company's conventional batch processing reputation.
Random access databases enable us to quickly get individual data points from enormous datasets, much like finding a needle in a haystack. Hadoop, well-known for its distributed file system (HDFS), goes a step further by incorporating random access capabilities. It combines the capabilities of HDFS with technologies such as HBase in Hadoop to enable efficient data retrieval and storage for applications that demand real-time access.
Businesses may unlock the power of interactive analytics, real-time querying, and dynamic data-driven applications by exploiting Hadoop's random access databases. This adaptability accelerates Hadoop past its early limitations, positioning it as a versatile framework for many big data applications.
What is HBase?
We have learned that HBase in Hadoop is an open-source, distributed, non-relational database system. But what makes HBase unique, and why do we require it?
Consider HBase to be a big, supercharged spreadsheet. It is built to handle massive volumes of data in both volume and speed. Traditional databases struggle when coping with big data streams, while HBase excels in them. This is critical for businesses and applications that generate massive amounts of data daily, such as social media platforms, IoT devices, and financial systems.
The architecture of HBase distributes data across numerous servers to ensure high availability and fault tolerance. If one machine fails, the others will continue functioning, and your data will remain safe and accessible. Besides, it allows for lightning-fast data retrieval, making real-time queries a reality.
HBase and HDFS
HBase and HDFS are crucial tools for managing and storing data in a distributed setting. However, they have distinct qualities that make them suited for certain use cases. A short comparison between HBase vs HDFS is as follows:
| Feature | HBase | HDFS |
|---|---|---|
| Type | NoSQL database | Distributed file system |
| Data Model | Columnar-oriented | File-oriented |
| Structure | Tables with rows and columns | Hierarchical directories and files |
| Schema | Flexible | Static |
| Data Access | Real-time reads and writes | Batch-oriented |
| Consistency | Eventual consistency | High consistency in writes |
| Use Case | Real-time applications, sensor data, time-series data | Reliable storage for large files like logs and backups |
Storage Mechanism in HBase
At its core, HBase in Hadoop stores data distributed across computer clusters. This ensures scalability as well as fault tolerance. The data is organized into rows and columns, much like a spreadsheet, except it can accommodate petabytes.
HBase implements a mechanism known as column-family to store data effectively. Each column family can have many columns stored on a disk together. This configuration improves read and write performance. Furthermore, HBase maintains data organization, allowing for faster-range queries.
The automatic sharding of data into HRegions is a critical feature. New HRegions are dynamically added as data accumulates. This optimizes performance by balancing data distribution.
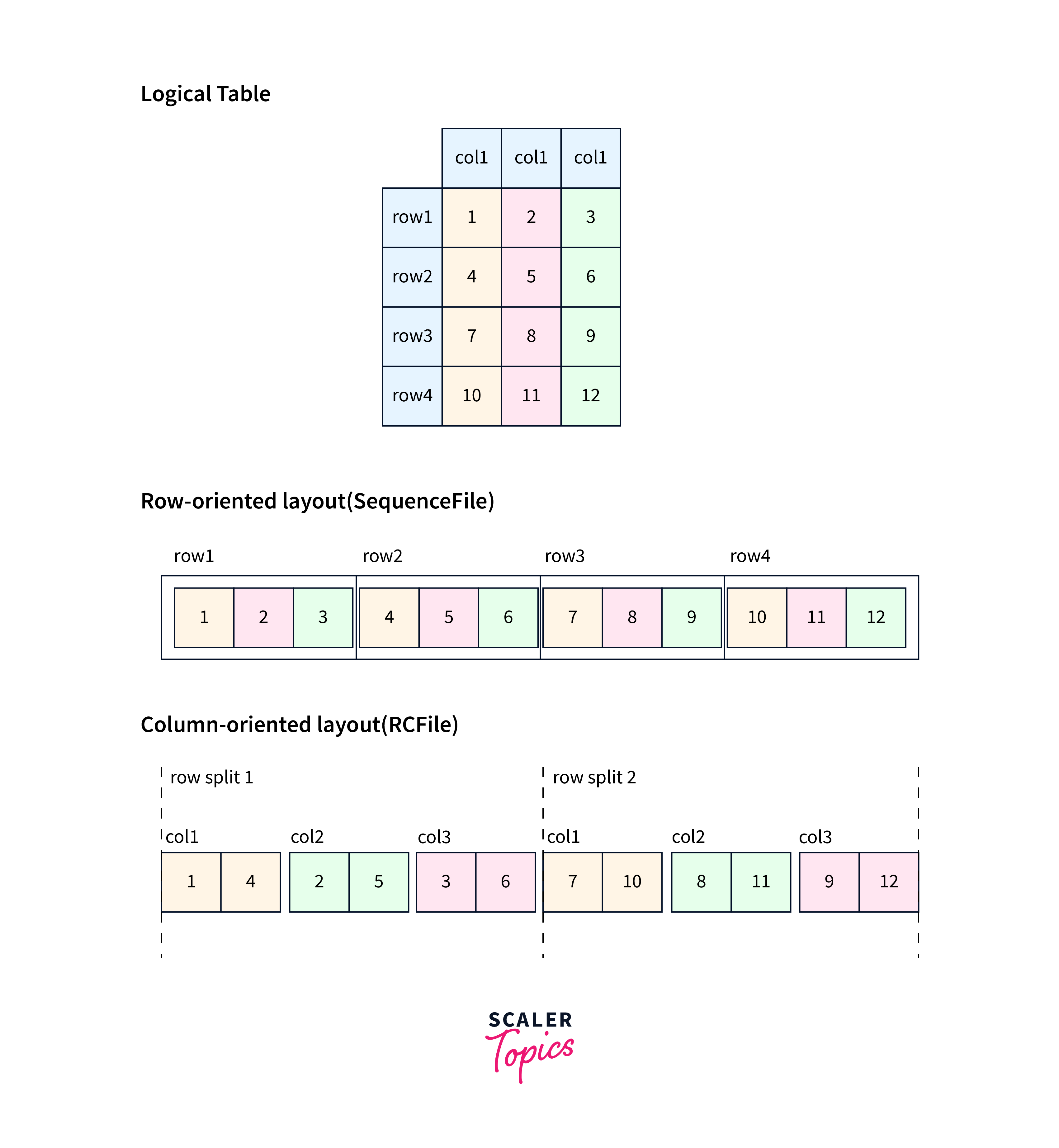
Column Oriented and Row Oriented
Column-Oriented and Row-Oriented storage are critical in managing massive volumes of data in Hadoop's HBase. These strategies impact data storage and access, affecting performance and efficiency.
Column-Oriented Storage
Consider it similar to a spreadsheet, where each column is saved independently rather than each row. This method is appropriate for instances where you must aggregate or analyze individual attributes across numerous rows. Assume you're tracking sales; this method lets you quickly retrieve total sales for a certain product throughout all periods.
Row-Oriented Storage
Instead of columns, row-oriented storage stores data row by row, much like traditional databases. This works best when working with multiple records at once. Row-oriented storage shines when it comes to obtaining whole record sets.
Please refer to the image provided below for more clarity.
Choosing the Right Fit
Your data's nature and planned usage should determine your decision between the two. Column-oriented storage performs well for analytical queries, but row-oriented storage performs well in transactional scenarios. To balance performance with flexibility, a combination of both is frequently used.
HBase and RDBMS
| Aspect | HBase | RDBMS |
|---|---|---|
| Data Model | Schema-less; Supports flexible columns | Schema-based; Rigid structure |
| Scalability | Horizontal scalability | Vertical scalability |
| Storage | Column-family storage | Tabular storage |
| Query Language | Limited query options (Scan API) | SQL for complex queries |
| ACID Transactions | Eventual consistency, not fully ACID | Full ACID compliance |
| Performance | Fast read/write for large datasets | Better for structured data |
| Use Cases | Big data, unstructured data | Structured data, transactional apps |
| Joins | No explicit support for joins | Supports complex joins |
| Flexibility | Schema evolution with ease | Limited schema changes |
| Examples | Sensor data, social media analytics | Financial systems, CRM |
Features of HBase
Here are some of the distinguishing features of HBase in Hadoop:
- Scalability:
HBase in Hadoop scales horizontally, allowing it to handle massive volumes of data by distributing it across numerous servers. - High Availability:
Duplicating data across several nodes maintains data availability even if some server nodes fail. - Schema Flexibility:
HBase's dynamic schema approach allows you to store data without a set structure, allowing it to adapt to changing needs. - Fast Reads and Writes:
HBase excels at rapid data read and write operations, so it is ideal for real-time applications. - Consistency:
It ensures data correctness across all nodes in the cluster by providing strong consistency. - Column-Oriented Storage:
Data is stored in columns, making accessing certain attributes of a row easier and allowing for greater compression. - Automatic Sharding:
HBase automatically divides data into regions and shards, improving performance and management. - Integrated Caching:
HBase in Hadoop connects with systems such as Apache Hadoop for efficient data caching and retrieval. - Supports Bulk Loading:
Big datasets can be imported quickly using bulk loading techniques.
Applications of HBase
Let us now examine the different applications of HBase in Hadoop.
- Real-time Analytics:
HBase allows for rapid data storage and retrieval, so it is suitable for real-time analytics. It is employed in social media trend tracking, stock market analysis, and IoT data processing. - Sensor Data Management:
HBase manages data from sensors and devices in the energy, manufacturing, and healthcare industries. Predictive maintenance, process optimization, and patient monitoring are all aided by this. - Log Data Storage:
HBase virtually stores log data created by applications, servers, and networks. This is beneficial for troubleshooting, performance analysis, and security monitoring. - Fraud Detection:
HBase is used by financial institutions to detect fraudulent activities by processing and analyzing transaction records in real time. - Recommendation Engines:
HBase is the foundation for recommendation engines, which recommend items, movies, or content based on user interests and behavior. - Personalization Engines:
Online platforms use HBase to power personalization features, delivering tailored content and experiences to users.
Conclusion
- HBase in Hadoop is a distributed, scalable, and highly reliable NoSQL database. It is built to deal with large amounts of sparse data, making it perfect for real-time applications.
- HBase's horizontal scalability makes it ideal for managing large datasets and supporting future development.
- HBase meets the real-time data processing and analysis needs because of its rapid data retrieval techniques.
- Its user-friendly interface simplifies data modeling, allowing developers to work with structured data without database experience.
- The schema-on-read approach of HBase in Hadoop enables users to work with changing and dynamic data structures.