Hbase vs Hadoop
Overview
HBase is a distributed, column-oriented NoSQL database that runs on top of the Hadoop Distributed File System (HDFS). While Hadoop is a big data processing framework that enables the distributed processing of large datasets, HBase provides real-time random read-and-write access to data, making it suitable for applications requiring low-latency database operations. Hadoop focuses on batch processing and MapReduce, while HBase is designed for fast retrieval and storage of structured data.
What is Hadoop?
Hadoop is an open-source, distributed computing framework designed to store, process, and analyze massive amounts of data across clusters of commodity hardware. It comprises two primary components: Hadoop Distributed File System (HDFS) and MapReduce.
- HDFS is a distributed file system that stores data across multiple machines, enabling high fault tolerance and scalability. It breaks down large files into smaller blocks and replicates them across nodes, ensuring data redundancy and availability.
- MapReduce is a parallel processing model that allows efficient data processing across the Hadoop cluster. It divides tasks into Map and Reduces phases, where data is processed in parallel on multiple nodes.
You can read more about Hadoop here.
What is HBase?
Built on top of HDFS, HBase is a distributed, open-source NoSQL database. It is designed to store and manage vast amounts of structured and semi-structured data, providing real-time read and write access to large datasets. HBase follows a wide-column store data model and offers high scalability, fault tolerance, and strong consistency for big data applications.
HBase Architecture
HBase follows a master-slave architecture and is tightly integrated with HDFS. Here is a brief overview of the key components and their roles in the HBase architecture:
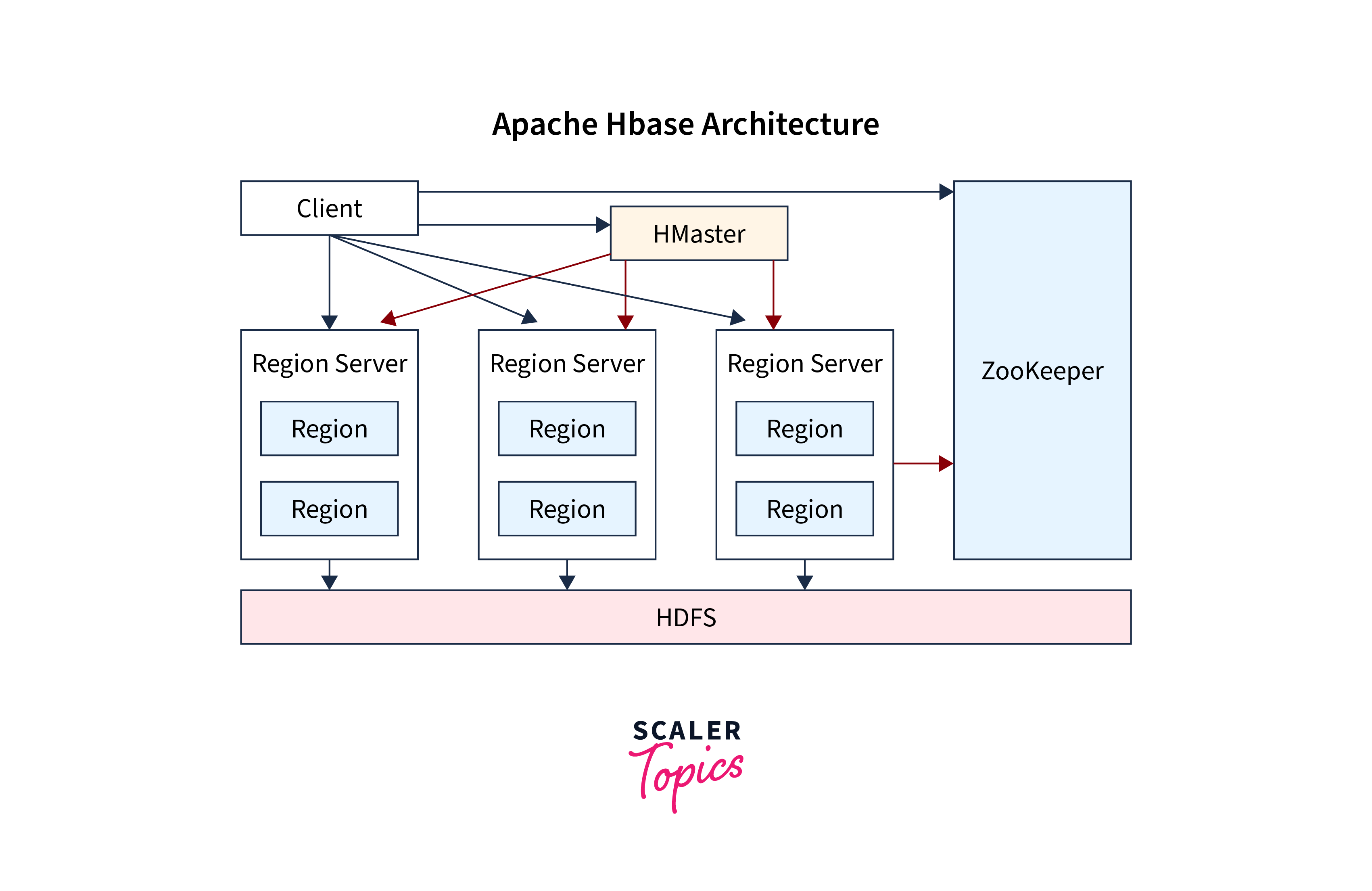
1. HMaster:
The HMaster is the master node in the HBase cluster. It is responsible for coordination and management tasks, including:
- Region Assignment: The HMaster assigns regions to RegionServers, distributing the data across the cluster.
- Schema Management: It handles schema changes, table creation, and metadata management.
- Load Balancing: HMaster monitors the load on RegionServers and performs load balancing to ensure even data distribution.
- Failover: In case of a RegionServer failure, the HMaster facilitates the reassignment of regions to other available RegionServers.
2. RegionServer:
RegionServers are worker nodes responsible for storing and managing data in the HBase cluster. Each RegionServer manages one or more regions, which are data partitions within an HBase table. The RegionServer performs the following tasks:
- Data Storage: It stores the actual data in HDFS and manages the MemStore and HFile data structures.
- Read/Write Operations: The RegionServer handles read and write requests for the regions it owns.
- Compactions: To improve performance, the RegionServer performs compactions, which merge and clean up data in the background.
3. ZooKeeper:
HBase relies on Apache ZooKeeper for distributed coordination and maintaining cluster state. ZooKeeper helps in the following ways:
- Leader Election: ZooKeeper assists in electing the HMaster when the cluster starts up or in case of failure.
- Cluster Coordination: It keeps track of the active RegionServers and HMaster, facilitating synchronization and failover processes.
4. HDFS:
HBase uses HDFS as its underlying file storage system. Data is stored in HDFS blocks, and HBase regions map directly to HDFS files. This integration allows HBase to take advantage of HDFS's data replication and fault tolerance capabilities.
Working
The workflow of HBase can be summarised as following points:
- When a client makes a read or write request, it first contacts the ZooKeeper to discover the active HMaster and RegionServers.
- The HMaster, after processing the request, determines the RegionServer responsible for the requested region and forwards the request accordingly.
- The designated RegionServer processes the read/write request and communicates with HDFS to retrieve or store the data.
Key Features
Key features of HBase include the following:
- High Scalability: HBase can handle massive amounts of data and can scale horizontally as the data size grows.
- High Availability: HBase ensures data availability through data replication and automatic failover mechanisms.
- Strong Consistency: It provides strong consistency for read and write operations within a region.
- Automatic Sharding: HBase automatically manages data distribution across nodes through region splits.
- MapReduce Integration: HBase integrates well with Apache Hadoop's MapReduce, enabling efficient data processing.
Limitations
Limitations associated with HBase include the following:
- Schema Design: HBase requires careful schema design upfront as it doesn't support ad-hoc querying like SQL databases.
- No Joins: HBase does not support joins, which can make complex data retrieval challenging.
- No ACID Transactions: While HBase offers strong consistency within a region, it doesn't support full ACID transactions spanning multiple regions.
- Not Suitable for Small Data: HBase is designed for large-scale data storage and processing, making it less efficient for small datasets.
- Limited Query Support: It lacks the flexibility of SQL queries, which can be a disadvantage for users familiar with SQL.
HBase vs Hadoop: Comparison Table
Let's use a table to understand HBase vs Hadoop:
| Aspect | Hadoop | HBase |
|---|---|---|
| Data Model | Hadoop follows a batch processing model. | HBase is a NoSQL database with real-time capabilities. |
| Data Processing | Hadoop utilizes MapReduce for processing. | HBase supports random read and write operations, suitable for real-time applications. |
| Use Case | Ideal for batch processing and large-scale data analytics. | Suited for real-time applications requiring low-latency access to data. |
| Schema Flexibility | Hadoop's schema is rigid, requiring a predefined structure. | HBase provides dynamic schema flexibility, allowing columns to be added on-the-fly. |
Conclusion
- Hadoop:
- Open-source distributed computing framework.
- Components: HDFS (distributed file system) and MapReduce (parallel processing model).
- Designed to store, process, and analyze big data across commodity hardware.
- Ideal for batch processing and large-scale data analytics.
- Rigid schema and batch processing model.
- HBase:
- Open-source distributed NoSQL database built on HDFS.
- Components: HMaster, RegionServer, ZooKeeper.
- Designed to store and manage large amounts of structured and semi-structured data.
- Suited for real-time applications, providing low-latency access to data.
- Dynamic schema flexibility and supports random read and write operations.