Apache Oozie in Hadoop
Overview
Hadoop is a data processing framework that empowers organizations to process vast amounts of data efficiently in today's data-driven world. Apache Oozie is a prominent workflow scheduler and coordinator which plays a crucial role in the Hadoop ecosystem by enabling users to define, manage, and execute complex data workflows. Let us explore the key features and needs of Oozie Hadoop for data processing in Hadoop environments.
What is Apache Oozie in Hadoop?
Apache Oozie is a workflow scheduler and coordinator, allowing users to define and manage complex data workflows seamlessly. By automating the execution of interdependent tasks and monitoring their progress, Oozie Hadoop ensures that data processing tasks run smoothly and efficiently in Hadoop environments.
Consider a scenario where a leading e-commerce company needs to process and analyze sales data from various sources daily. The data workflow involves multiple steps:
- Data ingestion
- Data cleansing
- Data transformation
- Generating reports
As the scale of data and the number of processing steps increase, manually orchestrating these tasks becomes impractical. This is when Apache Oozie becomes indispensable, enabling the automation and coordination of these complex workflows within the Hadoop ecosystem.
Types of Oozie Jobs
Oozie Hadoop supports various types of jobs for specific data processing requirements within the Hadoop ecosystem. Let's explore these types of Oozie Hadoop jobs:
Hadoop MapReduce Jobs
- Hadoop MapReduce is the processing engine of Hadoop, designed for parallel data processing on large-scale datasets.
- MapReduce jobs are well-suited for batch processing tasks, where large datasets are divided into smaller chunks, processed in parallel across the Hadoop cluster, and then aggregated to generate the final output.
Apache Hive Jobs
- Apache Hive is a data warehousing and SQL-like query language for Hadoop.
- It allows users to perform analysis on structured data stored in Hadoop's HDFS (Hadoop Distributed File System).
- Oozie can handle Apache Hive jobs, enabling users to schedule and automate the execution of Hive queries for data extraction, transformation and loading as part of their data workflows.
Apache Pig Jobs
- Apache Pig is a high-level data flow language that simplifies the analysis of large datasets on Hadoop.
- Pig scripts enable users to create data processing tasks in a concise and readable manner, making it easier to manipulate and analyze data.
Spark Jobs
- Apache Spark is a fast and general-purpose data processing engine that supports in-memory processing, making it suitable for real-time and iterative data processing tasks.
- With Apache Spark jobs, users can use Spark tasks in their workflows to perform advanced analytics, machine learning, and real-time data processing on Hadoop.
- Oozie's automation features allow users to execute Spark jobs at the desired intervals, ensuring timely data processing and analysis.
How does Oozie work?
Apache Oozie operates in a workflow-driven approach, where users define complex data processing tasks and their dependencies as workflows. Let's explore how Oozie works with an example.
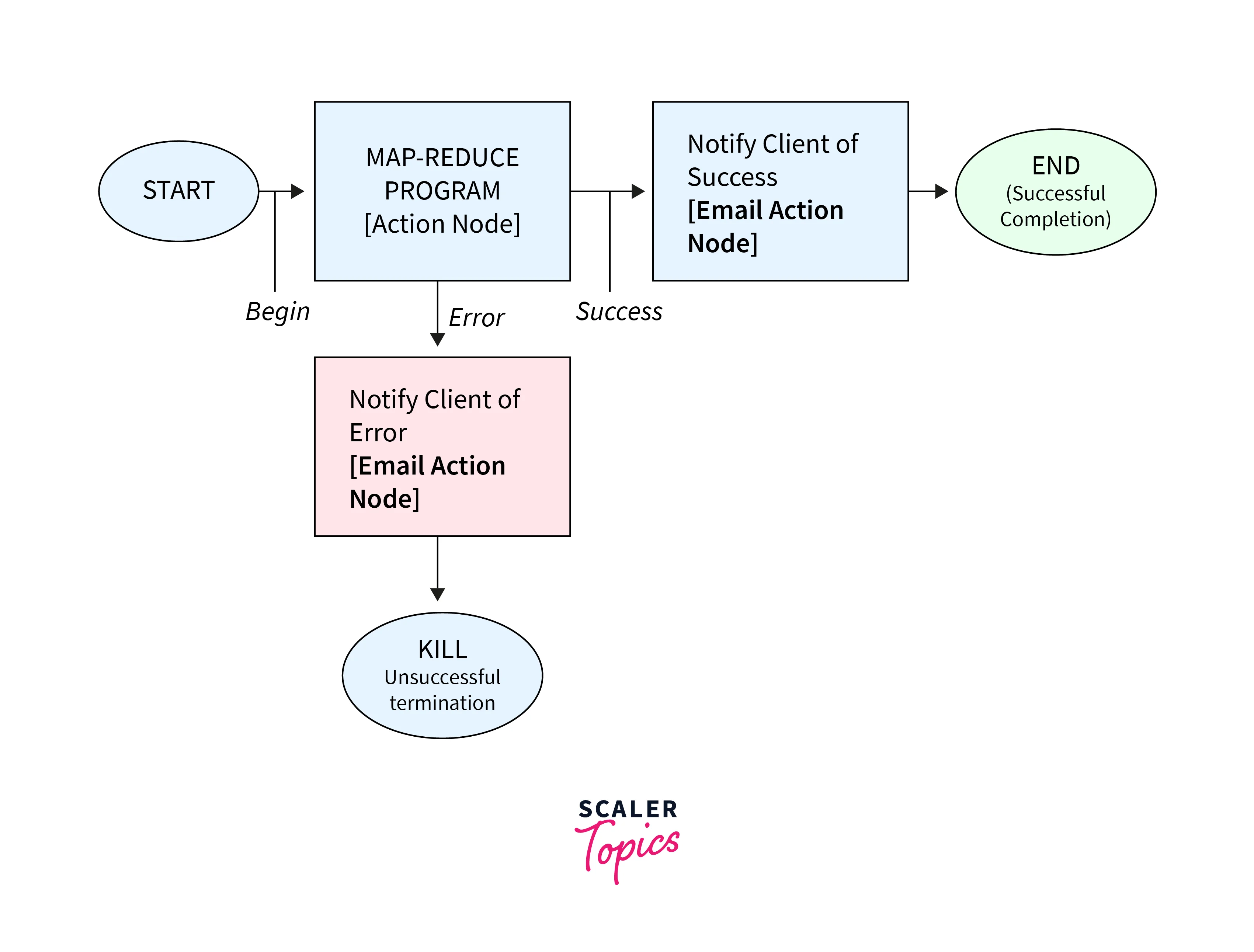
Example:
Explanation:
- workflow-app: Defines the entire Oozie workflow application with the name attribute for the name of the workflow and the xmlns attribute for the XML namespace.
- <start>: Starting point of the workflow. The to attribute connects to the first action named task1.
- <action>: Represents the action within which this job is defined.
- <map-reduce>: Configuration and properties for the MapReduce job.
- <ok>: Next action to be executed after a job completes successfully. In this case, it is task2.
- <error>: Directs the workflow to the fail action, if an error occurs during the job execution.
- <hive>: Configuration and properties for the Hive job.
- <kill>: Serves as the error-handling mechanism for the workflow. It represents the fail action and if any action in the workflow fails, it will be redirected to this action.
- <message>: Custom error message.
- <end>: End of the workflow where all actions have been completed successfully.
Once the workflow is defined, it is submitted to the Oozie server. Oozie's coordinator or scheduler component takes charge of managing and executing the workflow. Each action in the workflow can have ok and error transition nodes, which determine the next actions to be executed based on the success or failure of the current action.
Why Oozie?
Oozie Hadoop brings several advantages to the Hadoop ecosystem:
- Simplifies the management of complex data workflows, making it easier to schedule and execute tasks.
- Handles the coordination of interdependent tasks, ensuring proper sequencing and avoiding data inconsistencies.
- Provides extensive logging and monitoring capabilities, allowing users to track the progress of workflows and diagnose any issues that arise.
- As Oozie is designed for distributed environments, it can scale seamlessly to handle large workloads efficiently.
- Integrates with Hadoop components like MapReduce, Hive, Pig and Spark, and also with other custom actions and external services.
Features of Apache Oozie
Here are the key features that make Oozie Hadoop an important part of the Hadoop ecosystem:
- Oozie's ability to schedule and coordinate workflows ensures that data processing tasks are executed in a controlled and timely manner.
- Oozie is extensible and can integrate with various Hadoop components, making it a versatile tool for diverse data processing needs.
- Oozie provides an intuitive web-based user interface that simplifies workflow management and monitoring.
- Oozie is fault-tolerant, capable of handling failures and retries, ensuring reliable execution of data workflows.
Conclusion
- Apache Oozie is a workflow scheduler and coordinator for the Hadoop ecosystem.
- It enables users to define, manage, and execute complex data workflows involving various Hadoop components.
- Oozie Hadoop supports multiple types of jobs, including Hadoop MapReduce jobs, Apache Hive jobs, Apache Pig jobs and Apache Spark jobs.
- Oozie's workflow execution is based on XML-based definitions with actions representing individual tasks.
- The key features of Oozie include automation, coordination, handling dependencies, scalability, and fault tolerance.
- Oozie Hadoop also provides monitoring, logging, and a web user interface.
- Oozie is an important part of the Hadoop ecosystem by enhancing Hadoop's capabilities by simplifying workflow management.