Recommendation System Using Hadoop
Overview
Our project, the Recommendation System Using Hadoop, is a powerful solution designed to provide personalized recommendations and enhance user experiences. Developed with Python and Hadoop, it efficiently processes large datasets, integrating key libraries like Pyspark and PyFlink for seamless data handling. Users can implement features like collaborative filtering, content-based filtering, and hybrid models to tailor recommendations, making it a valuable tool for businesses aiming to optimize user engagement and customer satisfaction.
What are We Building?
Recommendation systems are the backbone of personalized content delivery in today's digital landscape, from Netflix suggesting movies to Amazon recommending products. We'll explore the prerequisites, the approach, and the steps to create this system.
Pre-requisites:
- Hadoop
- Python
- Pyspark and PyFlink
- Data Preprocessing
- Machine Learning
How are We Going to Build This?
-
Data Collection:
Gather the data on which recommendations will be made. This can be user behavior data, ratings, or any relevant information.
-
Data Preprocessing:
Clean and prepare the data for analysis. Handle missing values and outliers.
-
Algorithm Selection:
Choose your project's appropriate collaborative filtering algorithm. You can opt for user-based, item-based, or matrix factorization methods.
-
Hadoop Integration:
Utilize Hadoop's capabilities to handle large-scale data. Distribute your data and computations using HDFS and MapReduce.
-
Python Implementation:
Write Python code using Pyspark or PyFlink to implement the selected algorithm on the Hadoop cluster.
-
Evaluation:
Evaluate the performance of your recommendation system using metrics like RMSE (Root Mean Squared Error) or precision-recall.
-
Optimization:
Fine-tune your model to enhance recommendations further.
Output
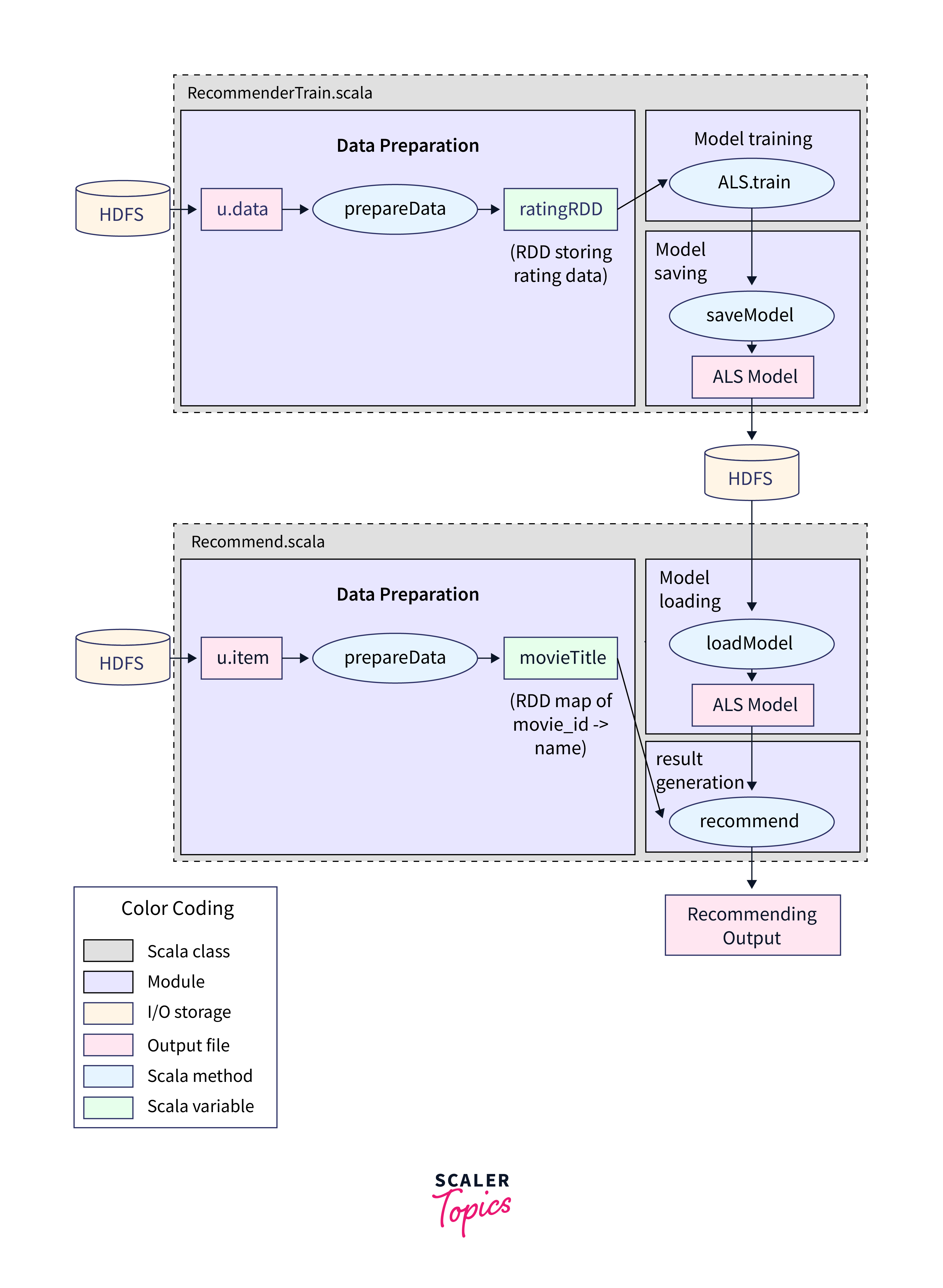
Requirements
Building a recommendation system using Hadoop in Python is an intricate task that demands meticulous planning and precise selection of libraries, modules, and other requirements. This section will outline the essential components you need to kickstart your project. Our focus will be on harnessing the power of Hadoop alongside Python and its associated libraries, such as PySpark, PyFlink, and more.
Technologies
-
Hadoop Cluster:
To begin, you'll need a Hadoop cluster up and running. Ensure you have access to the Hadoop Distributed File System (HDFS) and Hadoop MapReduce for data storage and processing.
-
Python Environment:
A Python development environment is crucial for coding your recommendation system. Python offers flexibility and compatibility with Hadoop libraries.
-
Hadoop Streaming:
Hadoop Streaming allows you to use any programming language (like Python) for writing MapReduce jobs. It's handy for customizing recommendation algorithms.
Libraries
-
PySpark:
PySpark is a fundamental library for integrating Python with Hadoop. It provides APIs for distributed data processing, enabling efficient data manipulation.
-
PyFlink:
PyFlink is another powerful library that complements Hadoop. It focuses on stream and batch processing, making it suitable for real-time recommendations.
Others
-
Data Storage:
HDFS is your primary data storage, but consider external databases or cloud storage options for scalability.
-
Data Preparation Tools:
You'll require tools for data cleaning, preprocessing, and transformation. Libraries like Pandas and NumPy can be invaluable for these tasks.
-
Machine Learning Libraries:
Popular libraries like scikit-learn or TensorFlow are essential for model training and evaluation if you plan to implement machine learning algorithms for recommendation.
-
Visualization Tools:
Visualizing recommendation results can aid in understanding user preferences and system performance. Libraries like Matplotlib or Seaborn can help you create meaningful visualizations.
-
Documentation and Version Control:
Maintain a well-documented codebase using tools like Git and platforms like GitHub or GitLab. This ensures collaboration and code versioning.
-
Resource Allocation:
Adequate hardware resources, including CPU and RAM, are vital for running Hadoop jobs efficiently. Consider cloud-based services like AWS EMR or Azure HDInsight for scalability.
-
Testing and Monitoring Tools:
Implement testing frameworks like PyTest and monitoring tools like Apache Ambari to ensure the reliability and performance of your recommendation system.
Recommendation System Using Hadoop
Let's get started with developing the application.
Data Extraction and Collection
The first and most important stage is to collect and prepare the data for your recommendation system. Data may be sourced from various sources, including e-commerce websites, social media platforms, and any domain-specific dataset.
Architecture
Building a solid architecture is critical to the success of any recommendation system. First we will collect the data, process it (cleaning, and normalization) and then load the data (extraction) and finally analyze it as per our usage.
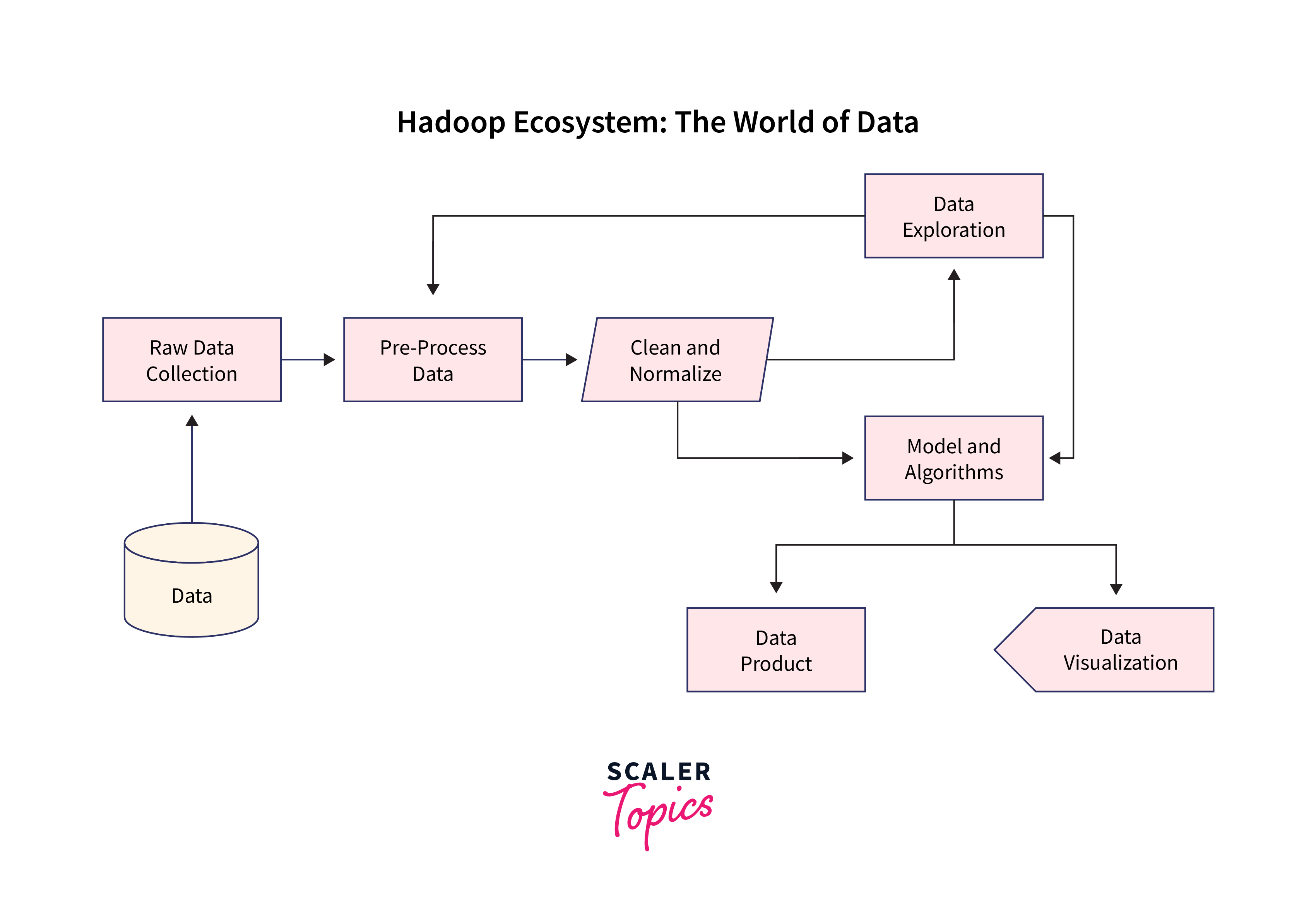
Load Data to HDFS
Hadoop Distributed File System (HDFS) is where your data will reside. You can load your data into HDFS using Hadoop's command-line utilities or Python libraries. This step ensures that your data is distributed across the Hadoop cluster, enabling parallel processing.
Analysis with Pig Command
Apache Pig simplifies data analysis on Hadoop. You can write Pig scripts to process and transform your data. For instance, you can aggregate user-item interactions and calculate item similarities.
Results
Finally, it's time to provide suggestions based on your research. Pig script findings may be used to produce personalized suggestions for users. These suggestions can be shown on a website or within your application.
Example of Recommendation
In the above Pig script:
- We load the recommendations from a data source (e.g., HDFS) into the recommendations relation. The data is assumed to have a structure with a user_id and a bag of recommended_items, where each recommended item has an item_id.
- We specify the user_id_to_query, which represents the user for whom we want to retrieve recommendations.
- We filter the recommendations based on the user_id_to_query. You can also modify the script to filter recommendations for a specific item if needed.
- Finally, we use the DUMP command to display the recommendations for the selected user or item.
Developing a recommendation system using Hadoop is a difficult but rewarding undertaking. You may utilize Python and Hadoop-related libraries to harness the power of distributed computing to deliver useful suggestions to your consumers. Feel free to experiment with additional features, such as collaborative filtering or real-time updates, to improve your system further.
Testing
Testing is a crucial phase in any data analysis project to ensure the accuracy, reliability, and validity of your results.
-
Testing Objectives and Criteria:
Begin by defining clear testing objectives and criteria. This involves outlining what you aim to achieve through testing, such as verifying recommendation accuracy, ensuring data consistency, and assessing system performance and scalability. Criteria should be specific and measurable, such as achieving a certain level of recommendation accuracy or response time.
-
Preparing Test Data:
Generate or collect representative test data that mirrors real-world scenarios. This data should encompass various user profiles, item interactions, and edge cases to assess recommendation quality comprehensively.
-
Testing Individual Components or Queries:
Isolate and thoroughly test individual components or Pig queries within the recommendation system. This includes validating the correctness of data preprocessing, transformation, and recommendation generation steps. Ensure that each component produces the expected results.
-
Verifying Data Consistency:
Cross-verify the analysis results against the original data sources or ground truth data to ensure data consistency. This helps in identifying any data ingestion, transformation, or calculation errors.
-
Testing Performance and Scalability:
Assess the system's performance and scalability by subjecting it to different loads, such as varying user volumes and concurrent requests. Measure response times, resource utilization, and system behavior under different workloads to ensure it meets performance expectations.
What's Next
You can implement several more features to take your recommendation system to the next level. Let's delve into some technical aspects of these enhancements.
-
Real-time Recommendation:
Transitioning from batch processing to real-time recommendations is a major advancement, achievable by integrating streaming tools like Apache Kafka and Apache Flink. This empowers recommendation engines to provide instant suggestions based on user behavior.
-
Personalization Algorithms:
Enhance recommendation quality through advanced algorithms like Matrix Factorization, Collaborative Filtering, or Content-Based Filtering, tailoring suggestions to individual user preferences and thereby boosting user satisfaction.
-
Scalability:
As your user base expands, you must guarantee that your recommendation system can manage additional pressure. To achieve horizontal scalability, consider deploying your system on a distributed computing cluster utilizing technologies such as Hadoop's YARN.
Conclusion
-
Data Extraction and Collection:
Gather and preprocess relevant data for analysis.
-
Architecture:
Design the system architecture, incorporating Hadoop and Python for efficient processing.
-
Load Data to HDFS:
Ingest and store data in Hadoop Distributed File System (HDFS) for distributed processing.
-
Analysis with Pig Command:
Utilize Pig commands for data transformations and analysis within the Hadoop ecosystem.
-
Results:
Extract valuable insights and recommendations from the analyzed data for actionable decision-making.