What is Apache Hive?
Overview
Hadoop enjoys the honor of being one of the most widely used systems for processing massive amounts of Big Data. In the Hadoop ecosystem, Hive is a data warehouse and SQL-like query engine. To help with this potentially difficult task of converting this raw data into meaningful content, data scientists and analysts need specialized tools. Here Hive comes in. So, what is Hive, Huge datasets stored on Hadoop are exclusively accessed and analyzed using Hive, an open-source data warehousing technology.
What is Hive?
Built on top of Apache Hadoop, Apache Hive is an open-source data warehouse infrastructure and query execution engine. Large datasets stored in distributed file systems, such as Hadoop Distributed File System (HDFS) or Amazon S3, can be accessed and analyzed using its high-level interface.

Initially created by Facebook, Hive was later taken up and further developed as an open-source project under the name Apache Hive by the Apache Software Foundation. It is utilized by various businesses. Amazon utilizes it, as an illustration, in Amazon Elastic MapReduce.
Architecture of Hive
The architecture of Apache Hive consists of several components working together to enable data processing and query execution on large datasets.
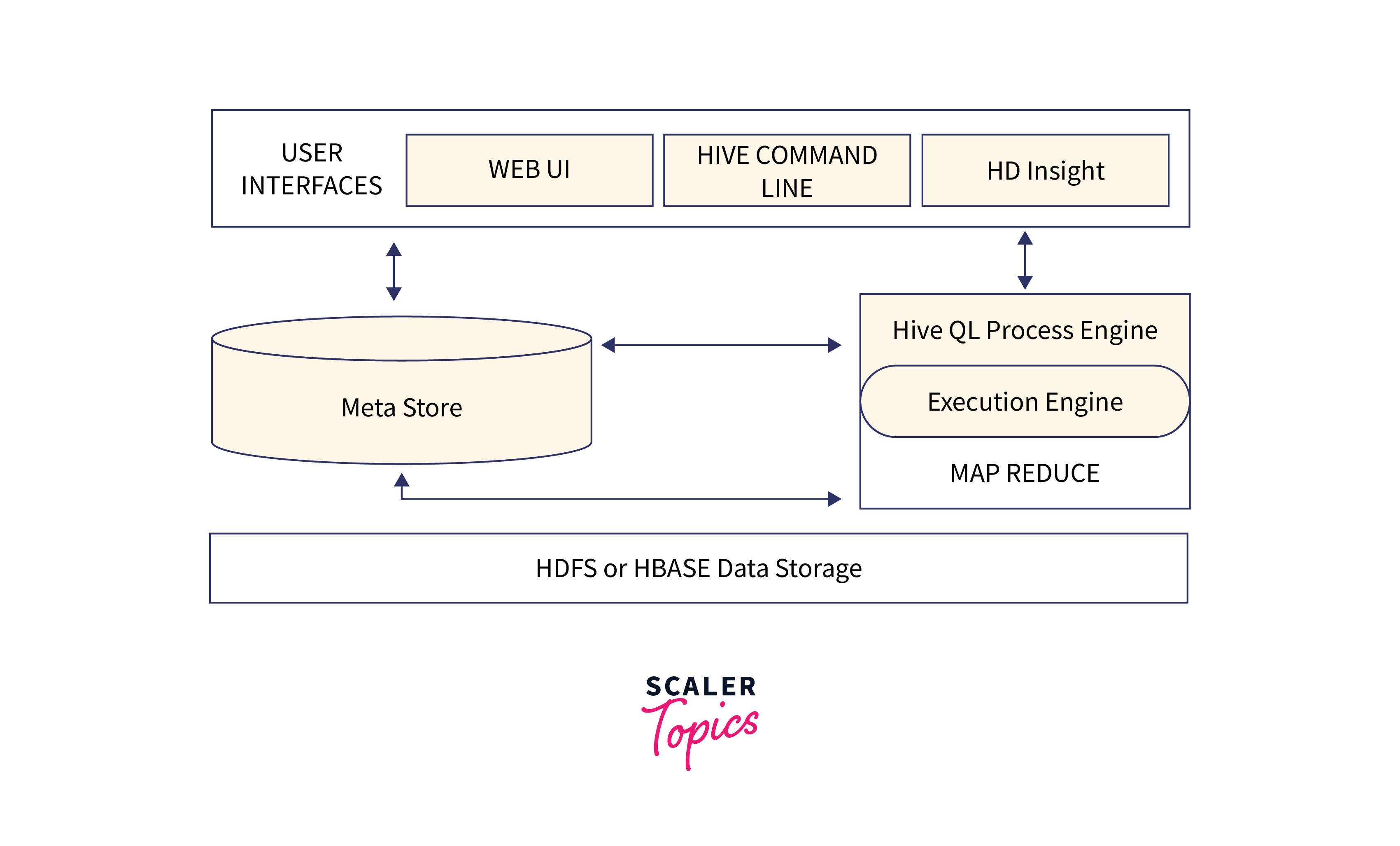
Here's an overview of the major components of the Hive architecture:
| Unit Name | Description |
|---|---|
| User Interface | Through a variety of interfaces, including the Hive CLI (Command Line Interface), Beeline (a JDBC client), or web-based interfaces like the Hive Web UI or Hue, the user can communicate with Hive. To communicate with Hive, users send instructions and queries to various interfaces. |
| Metastore | The Metastore is a centralized location where Hive's data's metadata, including details on tables, partitions, columns, storage formats, and other related topics, are kept. It offers management and retrieval services for the metadata and saves it in a database (such as MySQL or PostgreSQL). |
| HiveQL Process Engine | Hive employs the Hive Query Language (HQL), a language similar to SQL, to query and manage data. Users can create queries using the usual SQL syntax in HQL, which then converts them into MapReduce or Apache Tez tasks to be executed. |
| Execution Engine | The compiled query plan produced by the Compiler must be carried out by the Execution Engine. Apache Spark, MapReduce (the default), and Apache Tez are just a few of the execution engines that Hive supports. The execution of tasks across the distributed computing resources is scheduled and coordinated by the execution engine. |
| HDFS or HBASE | Hive uses the Hadoop Distributed File System (HDFS) as the foundation for its data storage. Large datasets can be stored in a fault-tolerant, scalable manner using HDFS. HDFS is where Hive reads and writes data. |
Working of Hive
The working of Apache Hive involves several steps, from query submission to result retrieval.
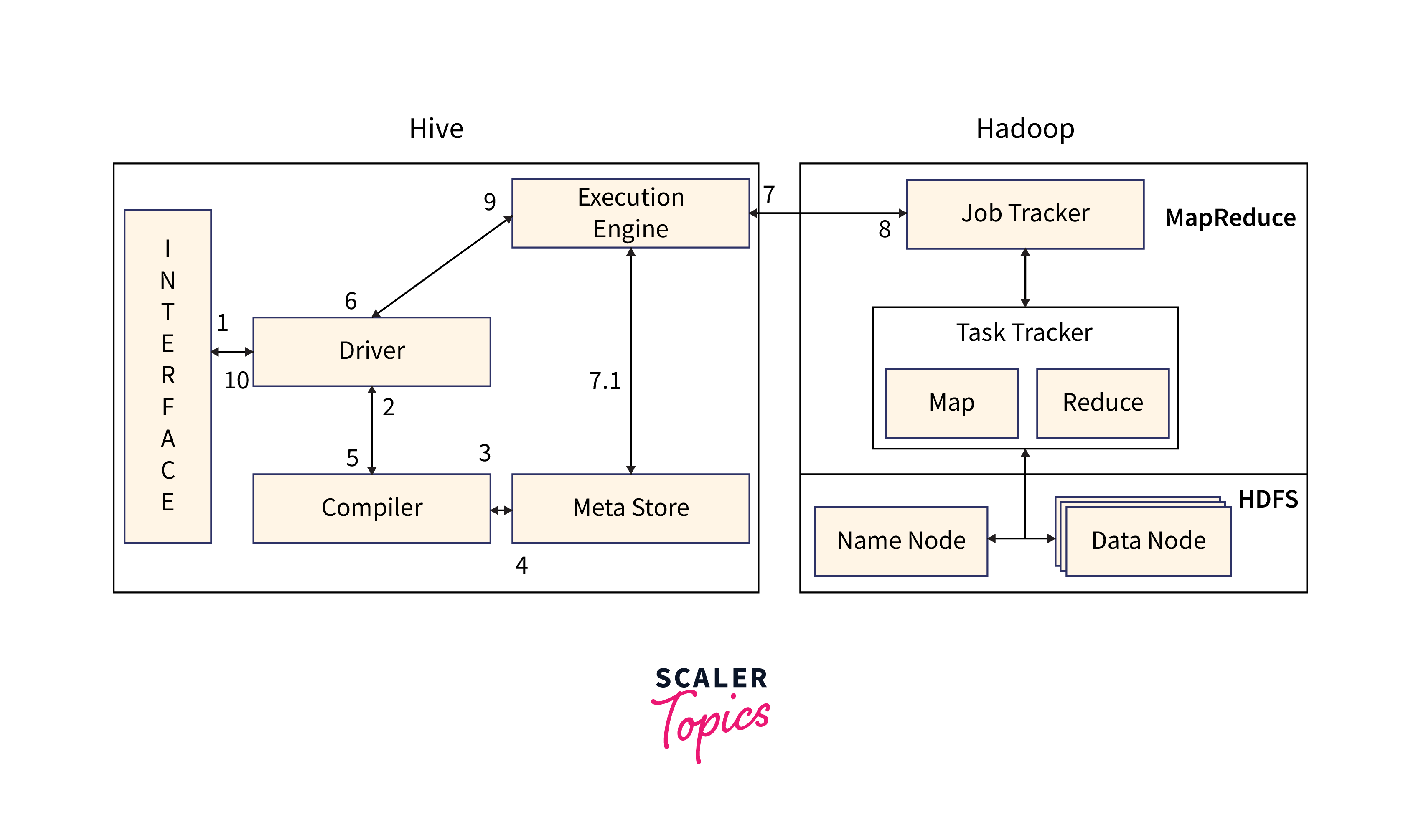
Here's an overview of how Hive works:
| Step | Description |
|---|---|
| Query Submission | Through the user interface, such as the Hive CLI or Beeline, the user sends a command or query to Hive. |
| Get Plan | The query compiler is used by the driver to parse the query and check its grammar, plan, and requirements. |
| Get Metadata | The compiler sends a request for metadata to the Metastore (or other database). |
| Send Metadata | Metastore responds to the compiler by sending metadata. |
| Send Plan | The plan is sent to the driver again after the compiler has checked the need. The processing and compilation of a query are finished at this point. |
| Execute Plan | The execute plan is sent by the driver to the execution engine. |
| Execute Job | A MapReduce job is used internally to execute the job. The job is sent by the execution engine to JobTracker in the Name node, which then allocates it to TaskTracker in the Data node. The query in this case runs a MapReduce task. In the meantime, the execution engine can use Metastore to carry out metadata operations. |
| Fetch Result | Results from Data nodes are delivered to the execution engine. |
| Send Results | These output values are sent from the execution engine to the driver, who then transmits the outcomes to Hive Interfaces. |
Features of Hive
Here are some key features of Hive:
- SQL-like Query Language:
Hive has a SQL-like query language called HiveQL that enables users to create queries for data management and analysis using the familiar SQL syntax. As a result, working with Hive is made simpler for users who are already familiar with SQL. - Data Storage Formats:
Hive is capable of storing data in a variety of forms, including text files, Apache Parquet, Apache ORC (Optimized Row Columnar), Avro, and more. These formats offer better performance and compression and are tailored for various use cases. - Partitioning and Bucketing:
Data bucketing and partitioning are supported by Hive to enhance query performance. While bucketing divides data into smaller, more manageable units called buckets based on a hash function, partitioning divides data into logical divisions depending on one or more columns. - Hive Metastore:
Hive employs a metastore to keep track of information about its tables, partitions, and schemas. The metadata can be set to be stored in the metastore using a variety of databases, including Apache Derby, MySQL, or PostgreSQL. - Integration with Ecosystem:
Hive interacts nicely with the Apache Hadoop ecosystem, which also includes the Hadoop Distributed File System (HDFS) for storage, Apache Spark for processing, Apache Tez for query execution optimization, and other components. This enables customers to use Hive along with other Hadoop ecosystem tools and frameworks.
Limitations of Hive
While Hive offers several advantages for data processing and analytics, it also has certain limitations.
Here are some common limitations of Hive:
- Latency:
Hive is not intended for real-time or interactive searches, therefore query latency is higher. - Lack of Update/Delete Operations:
Hive has limited native support for Update and Delete operations. - Limited Support for Complex Data Types:
Hive might be difficult to use when dealing with complex data structures. - Lack of Real-Time Data Ingestion:
Hive is not the best tool for processing streaming data or ingesting real-time data. - Small-Query Performance Issues:
Hive's query execution overhead can hurt the performance of small queries.
Differences Between Hive and Pig
| Hive | Pig |
|---|---|
| Used by Data Analyst. | Used by general programmers. |
| Hive employs a query language called HiveQL that is similar to SQL and enables users to write queries using the familiar SQL syntax. | Pig, on the other hand, makes use of a procedural scripting language known as Pig Latin that offers a language for data flow while transforming data. |
| Similar to a relational database, Hive treats data as organized tables with rows and columns. | Pig, on the other hand, views data as semi- or unstructured and frequently represents it as bags, tuples, and maps. |
| It operates on the HDFS cluster's server side. | It operates on the HDFS cluster's client side. |
| Slower than pig due to the overhead of query translation, job management, and the lack of data flow optimization. | Faster than hive |
| Hive uses a schema-on-read methodology in which the schema is applied when the data is queried | Pig, on the other hand, adopts a schema-on-write methodology in which the schema is established during the data loading process |
Conclusion
- what is hive, Hive is a data warehousing technology built on top of Apache Hadoop, used by data analysts to access and analyze large datasets stored in distributed file systems.
- Hive follows a query submission and execution process, involving steps like query submission, plan generation, metadata retrieval, execution plan execution, job execution, and result retrieval.
- Hive also has limitations such as higher latency for real-time queries, limited support for update/delete operations, challenges with complex data types, and performance issues with small queries.
- On the other hand, Pig is a general-purpose data processing tool that uses a procedural scripting language called Pig Latin and views data as semi-structured or unstructured.
- Pig operates on the client side of the HDFS cluster and is generally faster than Hive due to optimized data flow and query execution.