Why Hadoop 3?
Overview
Hadoop version 3 emerges as a clear champion in big data processing, outperforming its predecessors with amazing improvements. Hadoop 3 features expanded data storage and processing capabilities, making it a great alternative for modern data-intensive challenge. Hadoop 3 optimizes cluster utilization and overall performance with features such as erasure coding, GPU support, and an enhanced resource management system.
Introduction
Before learning about, Why Hadoop 3? Let us first get to know about Hadoop itself.
Hadoop is an open-source platform for storing, processing and analyzing enormous amounts of data across distributed computer clusters. With the release of Hadoop 3, this technology has advanced significantly.
Hadoop 3 expands on the foundation established by its predecessors, delivering numerous notable improvements. One notable enhancement is more efficient resource management using the YARN Resource Manager. This provides greater control over resources, resulting in improved performance and resource utilization.

Furthermore, Hadoop 3 supports erasure coding, a technique that improves data durability while reducing storage requirements. This is an improvement over standard 3x replication methods and a more cost-effective alternative.
What is Hadoop 3?
Before learning about, Why Hadoop 3? Let us get familiar with the concept of Haddop 3.
Hadoop version 3 includes various enhancements that make it an appealing option for modern data issues. One of the most notable improvements is improved storage management through erasure coding. This novel method greatly reduces storage costs, allowing organizations to store more data while maintaining fault tolerance.
Another noteworthy innovation is the use of YARN Timeline Service v2, which provides improved insights into cluster resource utilization and performance. This allows administrators to fine-tune cluster resource allocation, which improves overall efficiency.
Hadoop 3's containerization feature speeds up its performance even further. It enables the seamless deployment of apps, improves resource isolation, and simplifies management by leveraging container technologies such as Docker.
Furthermore, adding GPU support in Hadoop 3 opens up new possibilities for data processing. GPUs have shown tremendous promise in accelerating complicated computations such as machine learning and data analytics.
Enhanced Performance and Scalability
Let us learn about the first reason - Why Hadoop 3?
The YARN (Yet Another Resource Negotiator) architecture has strong resource management capabilities to assign resources dynamically, optimizing cluster utilization. This guarantees that applications execute smoothly, utilizing available resources efficiently and without conflict.
Another noteworthy feature is the introduction of Erasure Coding, a revolutionary technique for data redundancy and fault tolerance. Erasure Coding, as opposed to typical 3x replication, dramatically decreases storage overhead, assuring data longevity while optimizing disc capacity utilization.
Containerization is central to Hadoop 3, thanks to including Docker and Kubernetes. Containers enclose applications and their dependencies, allowing for consistent deployment across several environments. Kubernetes orchestrates these containers, which improves resource management and scalability.
Erasure Coding
Let us learn about the second reason - Why Hadoop 3?
Erasure Coding provides a more efficient solution to fault tolerance than typical data replication approaches. Erasure Coding keeps multiple copies of data across nodes, uses complicated mathematical methods to break data into pieces, and then constructs error correction codes.
Erasure Coding in Hadoop 3 offers several advantages. Multiple copies of data might take up a lot of space when using standard replication. Erasure Coding reduces storage overhead and results in significant storage savings, making it an environmentally beneficial alternative in today's resource-constrained landscape.
Erasure Coding optimizes network bandwidth by transferring only necessary fragments and error codes during data retrieval, enhancing overall network efficiency for faster data recovery and reduced congestion.
Improved Storage Efficiency
Let us learn about the third reason - Why Hadoop 3?
Substituting traditional 3x replication with erasure coding significantly enhances storage efficiency by optimizing data distribution to reduce overhead while maintaining fault tolerance.
Furthermore, Hadoop Version 3 enhances the NameNode architecture by introducing the Hadoop Distributed File System (HDFS) Router. This upgrade improves NameNode's performance, allowing for a more scalable and efficient data management system. Infrequently accessed data can be moved to lower-cost storage tiers, optimizing resource utilization even further.
Storage Space Quotas enable administrators to control storage utilization properly, preventing resource hogging and guaranteeing equitable distribution.
YARN Timeline Service v2
Let us learn about the fourth reason - Why Hadoop 3?
YARN, Hadoop's resource management layer, orchestrates resource allocation and job scheduling allowing organizations to improve operational efficiency and obtain deeper insights into their data activities.
YARN Timeline Service v2 is intended to provide a comprehensive, real-time view of cluster operations and resource utilization. It serves as a historical data repository, capturing job execution information, resource consumption, and application performance indicators.
The RESTful API of the service facilitates interaction by allowing smooth integration with a wide range of monitoring tools and frameworks. Its extensibility provides versatility by letting developers include unique metrics and properties, adapting the monitoring experience to individual needs.
YARN Timeline Service v2 lays the groundwork for better security and protects important cluster data while allowing authorized workers to gain controlled access.
Compatibility with Apache Hadoop 2. x
With the release of Hadoop version 3, the community saw a considerable improvement in performance and capabilities. However, an important concern arises: Can this new version work nicely with the existing Apache Hadoop 2. x ecosystem? Yes, because Hadoop 3's compatibility with Hadoop 2. x provides a smooth transfer without affecting your data operations.
-
Backward Compatibility:
Hadoop 3 maintains compatibility with Hadoop 2.x, enabling smooth migration of workflows and applications without major changes.
-
Enhanced YARN Resource Manager:
Hadoop 3 upgrades YARN, offering better resource allocation for new and existing apps, while smoothly handling Hadoop 2.x workloads.
-
Improved HDFS Storage Policies:
Hadoop 3 introduces enhanced storage policies, granting users greater control over data location and replication, and enhancing data availability and reliability.
Support for Cloud Platforms
Let us learn about the fifth reason - Why Hadoop 3?
Whether you prefer Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform (GCP), or another provider, Hadoop 3 ensures that your data lives in harmony in the cloud environment of your choice.
With the support for object storage systems such as AWS S3 and Azure Data Lake Storage. This eliminates the need for complex HDFS configurations, allowing data engineers to streamline their workflows and concentrate on what counts - data analysis.
Hadoop 3 embraces cloud-native security techniques such as AWS Identity and Access Management (IAM) and Azure Active Directory integration. This ensures that data is safeguarded by industry standards and regulations throughout its lifecycle.
Use Cases and Success Stories
Let's discuss some of the use cases of Hadoop 3.
-
Accelerated Data Processing:
The redesigned YARN has enabled organizations to distribute resources more efficiently and achieve lightning-fast data processing.
-
Healthcare Analytics:
The increased data storage and processing capabilities of Hadoop 3 have enabled the healthcare sector to get significant insights from patient records, medical pictures, and genomic data.
-
Financial Fraud Detection:
To combat fraud and improve security, financial institutions have used Hadoop 3. These institutions can discover abnormalities and patterns indicative of fraudulent activity by analyzing real-time transaction data from many sources. As a result, financial losses have decreased, and customer trust has risen.
-
Precision Agriculture:
Hadoop 3 has made its way into agriculture, transforming traditional farming practices. Farmers can collect data on soil quality, meteorological conditions, and crop health using IoT devices and sensors. This data may be processed using Hadoop 3's capabilities to optimize irrigation, anticipate agricultural yields, and reduce resource waste, consequently enhancing total production.
-
Climate Modeling:
Hadoop 3 has been used by climate scientists to study and simulate complicated climate scenarios. The scalability of the system enables them to analyze massive amounts of information from satellites, weather stations, and ocean buoys, assisting in accurate climate predictions.
Conclusion
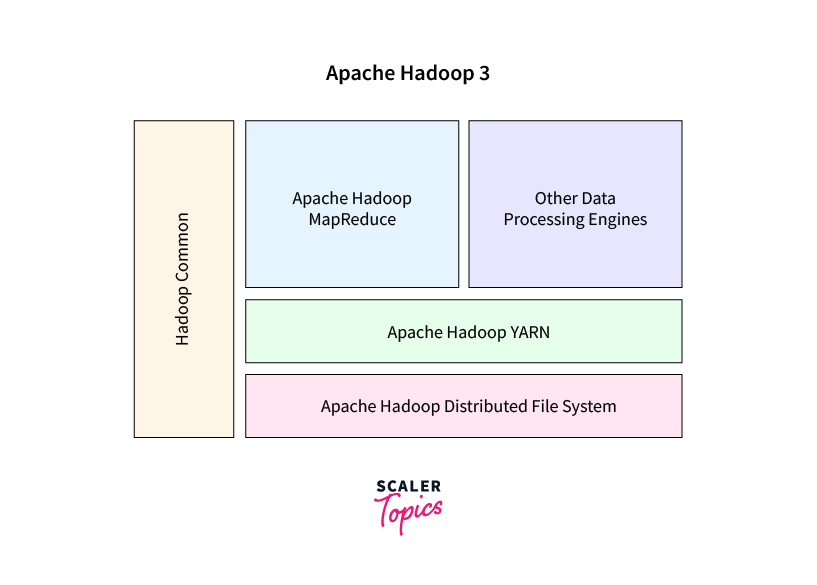
- The introduction of YARN breaks the rigid MapReduce monopoly, allowing for different data processing models. This elasticity improves resource utilization, creating a more diverse and efficient data environment.
- Erasure coding is used in Hadoop V3 to optimize storage. Traditional 3x replication is replaced, resulting in significant storage savings.
- Introducing the Hadoop Distributed File System (HDFS) Router in Hadoop 3 addresses the NameNode constraints. This eliminates single points of failure, increasing cluster stability and performance.
- Integrating containerization technologies such as Docker and Kubernetes seamlessly improves resource segregation, cluster utilization, and deployment flexibility.
- TLS/SSL encryption for data in transit and flexible Access Control Lists (ACLs) strengthen the fortress around your data, ensuring strict compliance.
- Hadoop Version 3 integrates its ecosystem components, such as Hive and HBase, with its core innovations.