Youtube Data Analysis Using Hadoop
Overview
This project focuses on YouTube data analysis using Hadoop and other Big Data related Python modules such as PySpark and PyFlink. It provides a comprehensive data analysis solution for both YouTube and data specialists. Readers may look forward to investigating numerous features and tools for their own data analysis, which will provide important insights into YouTube data trends and patterns. This project uses Hadoop and Python to maximize the potential of YouTube data analysis, making it a fascinating undertaking for tech lovers and data specialists.
What are we building?
We will collect meaningful insights from large troves of data created on YouTube using Hadoop, Python, and several Hadoop-related tools like PySpark and PyFlink. Whether you're an aspiring data scientist, a seasoned developer, or simply interested in the magic of big data, this project will provide you with the information and tools you need to get started with YouTube data analysis.
Pre-requisites
Before we dive into the project, let's ensure you have a solid foundation in the following areas:
- Hadoop Ecosystem: Learn about the Hadoop ecosystem, such as HDFS (Hadoop Distributed File System) and MapReduce here.
- Python: Brush up on your Python abilities because we'll be scripting and manipulating data with it. To learn more about it, click here.
- PySpark and PyFlink: Learn the fundamentals of PySpark and PyFlink, Python libraries that enable Hadoop clusters to process large amounts of data.
- YouTube API: Learn how to access and get data using YouTube's API. To get you started, we'll supply some sample code later in the article.
How are we going to build this?
Now that you've covered the prerequisites let's outline our approach to building this YouTube data analysis project:
- Data Collection: We'll utilize the YouTube API to retrieve video statistics, comments, and user information. We'll walk you through the login procedure and how to use API requests.
- Data Storage: We will use Hadoop's HDFS for data storage. Learn how to set up an HDFS cluster and effectively store YouTube data.
- Data Processing: We will preprocess and alter the raw data using PySpark and PyFlink. You will learn how to clean and organize data for analysis.
- Analysis and Visualisation: We'll go through how to use libraries like Matplotlib and Seaborn to extract important insights, do sentiment analysis on comments, and generate visualizations.
- Results Interpretation: We'll finally understand how to interpret the analysis results, draw conclusions, and make data-driven decisions.
Final Output
Our application's ultimate output will be the collection of interesting visualizations, statistics, and conclusions that give full knowledge of the dataset's patterns and trends. The final product should be user-friendly, allowing stakeholders, policymakers, academics, or the general public to get useful insights on the data even without sophisticated technical knowledge. It should enable users to make educated decisions related to YouTube.
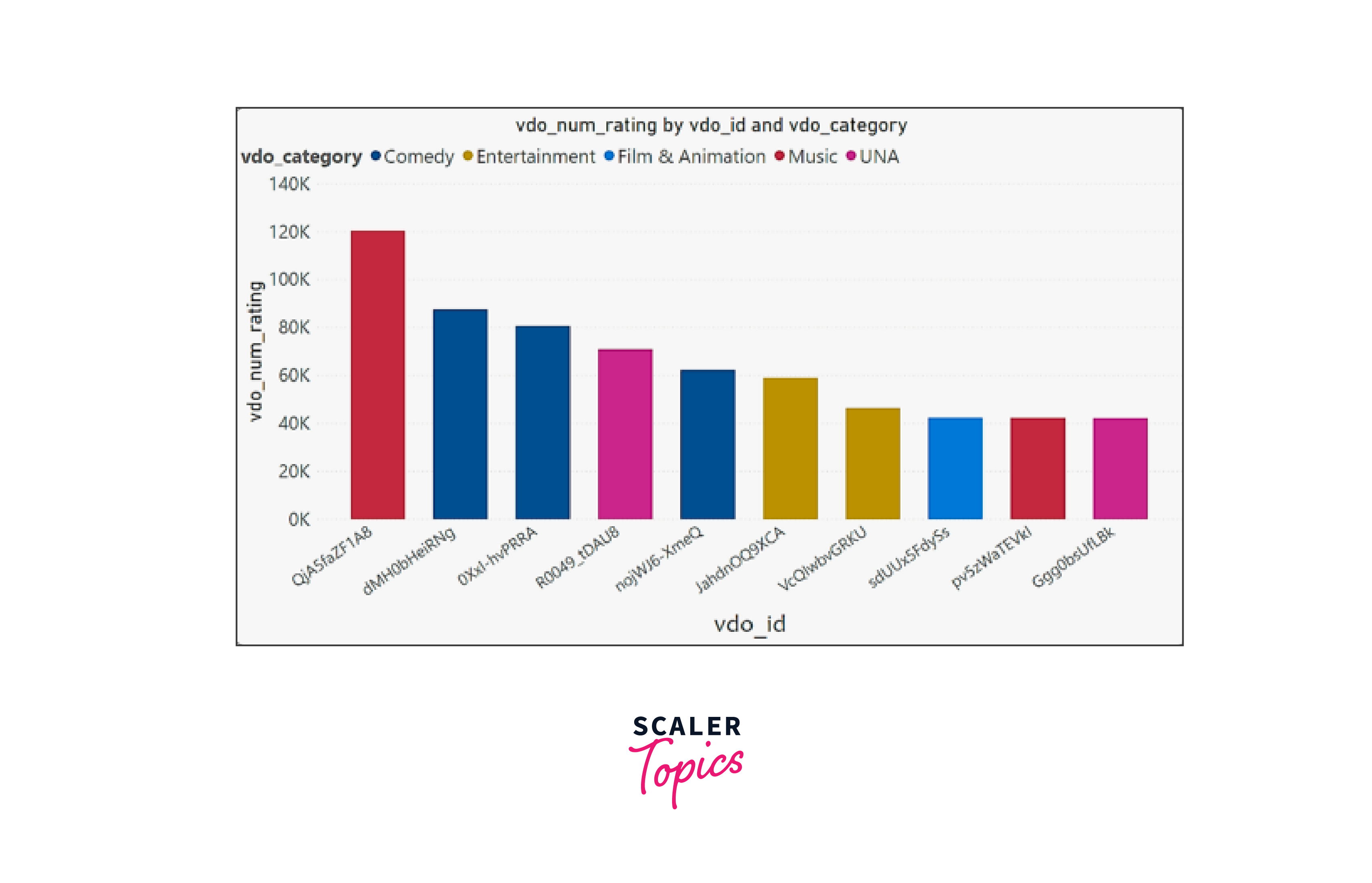
After this project, you'll have a robust pipeline for analyzing YouTube data that can draw insightful conclusions. Your final result will include visualisations, analytics, and a better understanding of YouTube patterns and user behavior.
Requirements
You'll need some key libraries, modules, and prerequisites to begin a Hadoop-based YouTube data analysis project. This project uses Python to harness Hadoop's power and uses Hadoop-related modules such as PySpark, PyFlink, and others. Here's a description of everything you'll need to get started, as well as some optional features to consider:
- Hadoop Cluster: A working cluster is the project's base. Check that Hadoop is properly installed and configured. A single-node cluster may be used for experimentation, whereas a multi-node cluster can be used for large-scale data processing.
- Python: A Python installation on your machine is a prerequisite. Python will be the major language for programming and data processing.
- PySpark: PySpark is a critical Python library for integrating Apache Spark. It provides a Python API for Spark, allowing you to process distributed data easily.
- PyFlink: PyFlink extends the functionality of Apache Flink to Python developers. It's ideal for YouTube data analysis as it is beneficial for real-time data processing and analytics.
- Hadoop Streaming API: This API enables you to construct MapReduce programs in various programming languages, including Python.
- YouTube Data API: To obtain the essential data for analysis, you'll need access to the YouTube Data API. Make sure you have the API keys and login credentials you need.
- Data Storage: Plan your data storage plan thoroughly. Hadoop's HDFS is the preferable option for storing huge datasets. Ensure that your cluster's HDFS is correctly set up.
- Data Ingestion Tools: You may require data ingestion tools to acquire and load YouTube data into your Hadoop cluster efficiently. This may be accomplished with Apache NiFi, Flume, or custom scripts.
- Data analytics Libraries: Depending on your analytical needs, you may require additional Python libraries for data manipulation, visualization, and statistical analysis, such as Pandas, NumPy, Matplotlib, and Seaborn.
- Cluster Management Tools: Tools like Apache Ambari and Cloudera Manager can assist you in successfully monitoring and managing your Hadoop cluster.
- Optional Features: Consider adding features like real-time data processing using Apache Kafka, natural language processing for sentiment analysis, or machine learning models for recommendation systems to your project to improve it.
If you follow these prerequisites and explore further capabilities, you'll be well-prepared to plunge into big data analytics and extract important insights from YouTube data.
YouTube Data Analysis Using Hadoop
Let us now see how to implement YouTube Data Analysis using Hadoop.
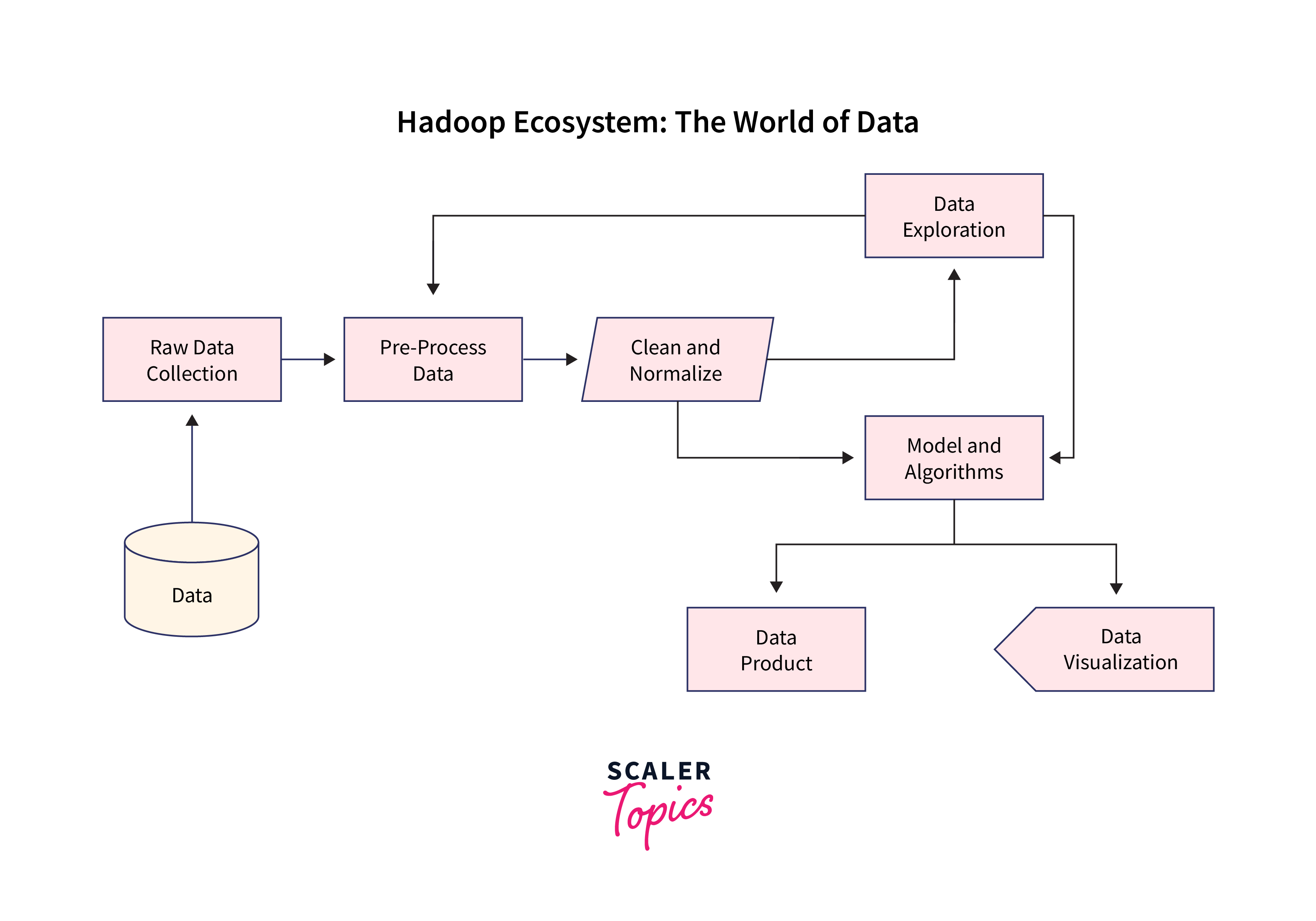
Data Extraction and Collection
To begin, extract and collect the YouTube data you wish to analyze. You may use the YouTube Data API to get information like video metadata, views, likes, and comments. Save this information in a structured format, such as JSON or CSV.
Architecture
Configure the architecture of your Hadoop cluster. Install Hadoop, HDFS, and any other required libraries. Create a scalable and fault-tolerant infrastructure to manage huge datasets effectively.
Load data to HDFS
Upload the obtained YouTube data to HDFS. You can utilize Hadoop's HDFS commands or Python modules such as hdfs3 to do this. Data stored in HDFS is easily accessible for distributed processing.
Hive Databases
To organize your data, create Hive databases and tables. Hive provides an SQL-like interface for querying your data, allowing it to be more easily analyzed. Define the schema and map it to the HDFS data.
Analysis with Hive command
Analyze your YouTube data using Hive's advanced querying features. Create HiveQL searches to extract insights such as popular videos, top commenters, and time-series patterns. You can also make use of some built-in functions and aggregations.
Python packages such as PySpark and PyFlink can help you improve your analysis. These libraries offer tools for distributed data processing and the ability to perform more complicated tasks. Machine learning models may be used for sentiment analysis, recommendation systems, and trend forecasting.
Results
Finally, describe your findings in a clear and intelligible manner. Create reports, visualizations, or dashboards to communicate your results effectively. Based on your YouTube data research, provide insights, trends, and actionable suggestions.
Using Hadoop, Python, and numerous Hadoop-related modules, you may undertake in-depth YouTube data analysis by following this strategy. This gives you a world of possibilities for gaining important insights from YouTube data and assisting you in making educated decisions or developing compelling content strategies.
Testing
Testing the YouTube data analysis application is a critical phase to ensure its accuracy, reliability, and performance. Comprehensive testing helps identify and rectify any issues, errors, or anomalies in the data analysis pipeline, ensuring that the results are trustworthy and actionable. Below, we'll discuss the various aspects of testing for this application:
Unit Testing:
- Developers should conduct unit testing for individual components and functions within the application. This involves testing each function in isolation to ensure that it produces the expected output for a given set of inputs.
- Unit testing ensures that the code for data extraction, transformation, and loading (ETL) processes, as well as data analysis algorithms, is functioning correctly.
Integration Testing:
- Integration testing focuses on verifying that different components of the application work seamlessly together. In this context, it involves testing the integration of Hadoop with Python modules like PySpark and PyFlink.
- Ensure that data flows correctly from one stage to another and that data transformations are applied accurately during the analysis.
Functional Testing:
- Functional testing checks whether the application meets its functional requirements. For YouTube data analysis, this includes verifying that specific analyses, such as sentiment analysis, trending video identification, or user behavior analysis, produce accurate results.
- Ensure that the application can handle different data sources and formats commonly found in YouTube data.
Performance Testing:
- Performance testing assesses the application's speed, scalability, and resource utilization. YouTube data analysis can involve processing massive datasets, so it's crucial to evaluate its performance under different loads.
- Test the application's response time when dealing with varying data sizes, and ensure it can efficiently distribute processing tasks across Hadoop's cluster.
Security Testing:
- Security testing is vital to ensure the protection of sensitive YouTube data and to prevent vulnerabilities that could be exploited by malicious actors. Test for data encryption, access controls, and secure communication between components.
- Verify that the application adheres to YouTube's API usage policies and terms of service.
User Acceptance Testing (UAT):
- UAT involves testing the application with end-users or stakeholders to ensure it meets their expectations and serves their needs.
- Gather feedback from potential users and incorporate their suggestions for improving the user interface, reporting features, or any other user-facing aspects.
Regression Testing:
- After making changes or updates to the application, perform regression testing to ensure that new code modifications do not introduce new bugs or break existing functionality.
Error Handling and Recovery Testing:
- Test the application's ability to handle unexpected errors gracefully. Ensure it logs errors, provides meaningful error messages, and implements a recovery strategy to minimize data loss or disruption.
Scalability Testing:
- As YouTube data continually grows, it's essential to test the application's scalability. Evaluate how well it can adapt to increasing data volumes and processing demands.
Data Quality Testing:
- Ensure that the data used for analysis is of high quality. Implement data validation checks to identify and address inconsistencies or anomalies in the YouTube data.
Finally, document the testing process, results, and any issues encountered. This documentation can be invaluable for future maintenance and for onboarding new team members.
In conclusion, thorough testing is an integral part of the development process for an application that analyzes YouTube data using Hadoop and Python. It ensures the application's reliability, accuracy, and performance, ultimately enabling data specialists and tech enthusiasts to derive meaningful insights from YouTube data with confidence.
What’s next
YouTube data analysis using Hadoop and Python has become a powerhouse in extracting significant insights from the immense sea of video information. You can implement even more features as mentioned below to further your step in YouTube data analysis project.
- Real-time Analytics: Real-time analysis of YouTube data is an interesting frontier. Consider the possibility of tracking trends and interactions as they occur, allowing instantaneous value and insights. Technologies like Apache Kafka are being investigated to help with real-time data streaming and processing.
- Integration of Machine Learning: Machine learning algorithms are becoming increasingly important in data analysis. Future YouTube data analysis using Hadoop applications may include advanced machine learning algorithms to anticipate trends, detect anomalies, and offer content enhancements.
- Configurable Dashboards: Look for creating user-friendly, configurable dashboards that visually display YouTube data. These dashboards will allow you to customize your statistics to meet your requirements, making insights more accessible.
- Enhanced Security: As data privacy becomes a priority, security measures will evolve to ensure compliance with regulations like GDPR. Try to make use of data encryption, access controls, and auditing tools wherever applicable.
- Cloud Integration: Cloud computing is reshaping data analysis. You can integrate the application with cloud platforms like AWS, Azure, or GCP to eliminate infrastructure management headaches.
YouTube data analysis using Hadoop and Python will continue to allow data professionals to extract useful insights from the huge YouTube ecosystem with better scalability, real-time analytics, machine learning integration, and improved security. Opportunities to delve further into data analysis will grow as these technologies advance.
Conclusion
- YouTube data analysis using Hadoop provides a solid foundation for collecting, analyzing, and deriving insights from massive volumes of video data.
- Thanks to Hadoop's scalability and Python's adaptability, developers can easily gather YouTube data, execute complicated transformations, and even add machine learning for predictive analysis.
- Incorporating machine learning and visualization technologies improves the YouTube data analysis process, allowing for the development of recommendation systems, predictive models, and engaging data-driven reports.
- In the world of YouTube data analysis, Hadoop and Python are indispensable allie to navigate the rich landscape of online video content.