Apache ZooKeeper
Overview
Apache ZooKeeper is a highly dependable and scalable open-source coordination solution for distributed applications. It is a centralized repository, offering a stable and efficient framework for administering dispersed systems. ZooKeeper in Hadoop enables developers to focus on app design while handling distributed coordination intricacies through services like synchronization, configuration management, and group membership. ZooKeeper's clear and easy interface and fault-tolerant architecture ensure it runs well even in difficult circumstances.
Introduction
Apache ZooKeeper in Hadoop is a strong and highly dependable open-source coordination tool that allows developers to construct and maintain distributed systems quickly. It provides a simple yet powerful interface for distributed applications, allowing them to coordinate and synchronize processes reliably and scalable. Because of its capacity to perform complicated coordinating tasks with simplicity, ZooKeeper has become a vital component in many distributed systems.
- Functionality : ZooKeeper is a centralized service that maintains a hierarchical file system-like structure called Znodes, which stores data and serves as a naming registry. ZooKeeper can be used by distributed applications to access, manage, and monitor these Znodes, allowing them to do distributed synchronization, configuration management, group membership, and other tasks.
-
Reliable Coordination: ZooKeeper's primary strengths is its emphasis on delivering dependable coordination primitives. It employs the ZAB (ZooKeeper Atomic Broadcast) consensus mechanism to ensure that all modifications to the distributed system are performed in exact sequence, establishing robust consistency and preventing conflicts.
-
Scalability and Fault-tolerance: ZooKeeper in Hadoop is meant to scale horizontally by allowing numerous nodes to form a cluster and share the load. This distributed architecture guarantees high availability and fault tolerance, as the system continues to function even if some nodes fail.
-
Widely Adopted: Apache ZooKeeper has found widespread use in various applications, such as distributed databases, messaging systems, cloud computing platforms, and big data frameworks. Its ease of use, dependability, and extensive feature set has made it the go-to solution in various industry applications.
Why do We Need It?
Maintaining order and ensuring flawless coordination among many components is a significant issue in distributed systems. This is where Apache ZooKeeper comes in offering a dependable and efficient solution for coordinating dispersed applications. Providing coordination services, alleviate race situations, and minimize deadlocks, is important for ZooKeeper to offer stability and reliability of distributed systems.
Coordination Services
Apache ZooKeeper provides a strong coordination framework that provides a shared hierarchical namespace, analogous to a file system, where all participants can store and retrieve data. This namespace is a centralized repository for storing configuration information, status updates, and other critical data, allowing scattered components to work seamlessly.
Race Condition
Race circumstances occur when many processes or threads attempt to access or alter shared resources at the same time, resulting in unpredictable and incorrect results. By offering a distributed locking mechanism, Apache ZooKeeper helps to prevent race situations. Distributed locks ensure that only one process or thread can access a certain resource anytime, avoiding conflicts and preserving data integrity.
Deadlocks
Deadlocks occur when processes or threads wait indefinitely for each other to release resources, causing the system to freeze. ZooKeeper rescue by offering a comprehensive notification system enables processes to sign up for notifications and get notified when specified conditions are met.
What is a Distributed System?
A distributed system is a network of independent computers or nodes that work together to achieve a common goal. The purpose of a distributed system is to enhance performance, reliability, fault tolerance, and resource utilization by harnessing the collective power of multiple machines. Examples of distributed systems include cloud computing platforms, peer-to-peer networks, and distributed databases.
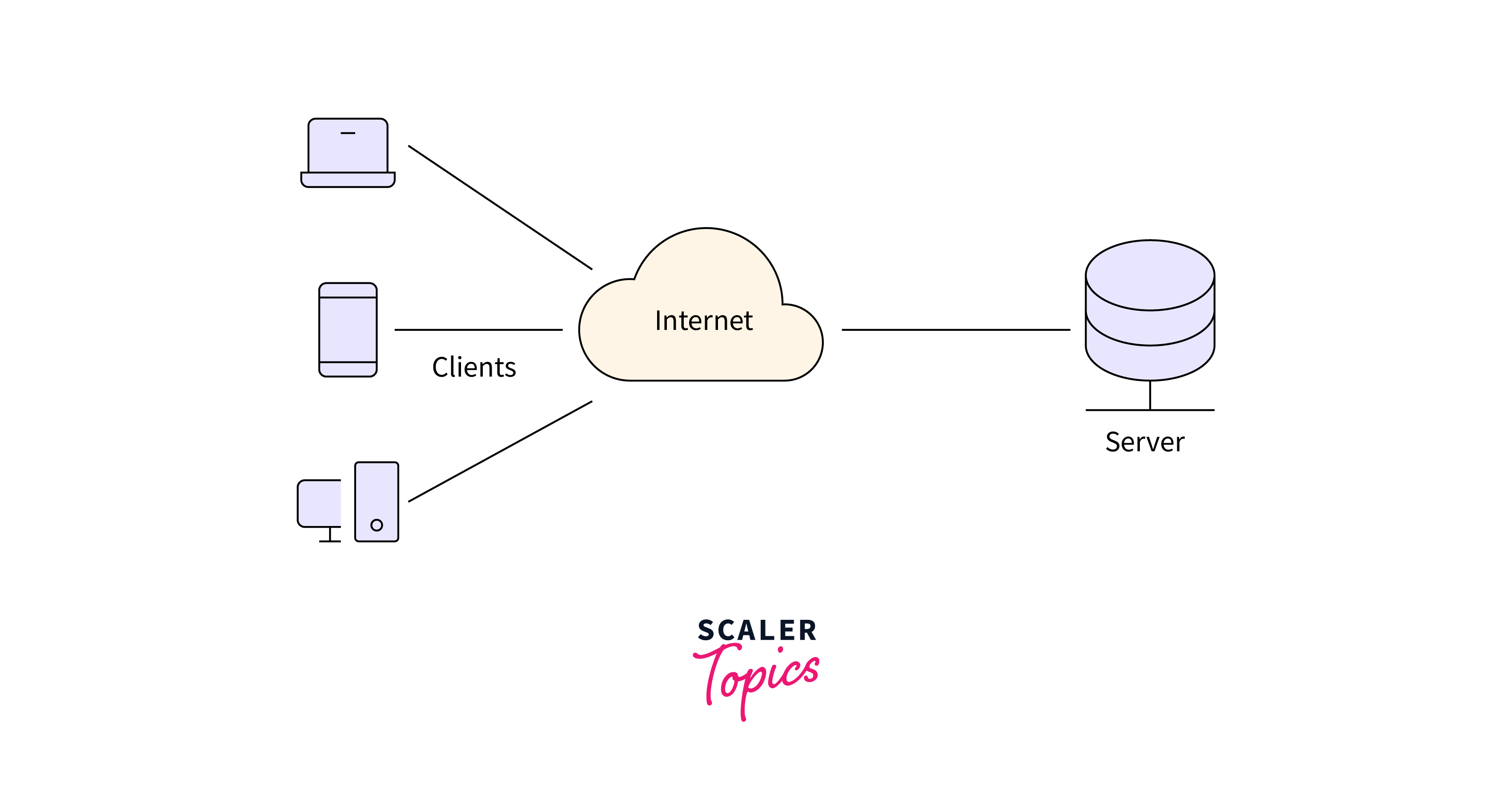
Apache Zookeeper
Apache ZooKeeper in Hadoop distinguishes out as a dependable and robust coordination solution in the large world of distributed systems. It is a central hub for distributed applications, providing configuration management, synchronization, naming, and group services.
ZooKeeper provides a hierarchical namespace, similar to a standard file system, allowing developers to organize data in a logical tree structure known as nodes. Each znode can store data as well as act as a lock or synchronization primitive.
ZooKeeper's architecture is based on a replicated server ensemble that keeps a consistent view of the system's state. Even in the event of a node loss, its design ensures fault tolerance and high availability.
Architecture of Zookeeper
Let us now see the overall architecture of Zookeeper in Hadoop.
-
Ensemble: ZooKeeper's design relies on an ensemble, which is made up of a group of servers that operate in a replicated mode. These servers work together to form a fault-tolerant cluster, assuring reliability even in the face of breakdowns. Each ensemble often comprises an odd number of servers to facilitate majority-based consensus.
-
Atomic Broadcast: ZooKeeper uses atomic broadcasts to achieve high consistency. Every write action is subject to a consensus procedure in which a quorum of servers recognizes the modification. This ensures that all updates are organized and reviewed by all participants prior to being considered committed.
-
Client Connections: ZooKeeper allows multiple client connections, allowing multiple distributed applications to access it at the same time. Clients communicate with ZooKeeper servers through sessions, which maintain a consistent picture of the distributed state.
Important Components in Zookeeper
Let's take a quick look at the critical components that ZooKeeper offers:
Leader & Follower
The leader manages all client requests, coordinates data updates, and ensures system consistency. On the other hand, followers reproduce the leader's state and serve customers in the event of the leader's failure, ensuring fault tolerance and high availability.
Request Processor
In Zookeeper, the request processor component accepts incoming client requests, conducts required operations, and ensures consistency across different copies. It handles read and write requests by checking permissions, coordinating data access, and managing distributed locks, ensuring that operations are carried out consistently and reliably.
Atomic Broadcast
Atomic broadcast is a crucial mechanism Zookeeper uses to establish system-wide consensus and order guarantee. It ensures that all Zookeeper ensemble nodes receive and process updates in the same order, preventing inconsistencies and ensuring that actions are done atomically as a single unit of work.
In-memory Databases (Replicated Databases)
Zookeeper stores and replicates its hierarchical data structure using in-memory databases. Because the data is maintained in memory, this technique offers fast and efficient data access. Furthermore, because the databases are replicated, they provide fault tolerance and high availability.
Client
The client component of Apache ZooKeeper is in charge of connecting to and interacting with the ZooKeeper server. It enables applications to connect to the server and send requests, such as creating, reading, updating, and removing data nodes in the ZooKeeper hierarchy.
Server
Apache ZooKeeper's server controls data storage and processing in a fault-tolerant and highly available manner. The server keeps a consistent and coordinated picture of the distributed system, ensuring that all data updates are synchronized and duplicated across numerous servers. It includes robust coordination primitives like distributed locks and barriers, enabling reliable application coordination.
Ensemble
In Apache ZooKeeper, an ensemble is a group of numerous ZooKeeper servers that work together in a replicated mode. This setup improves the system's scalability, dependability, and fault tolerance. The ensemble forms a distributed coordination service in which each server actively serves client requests and keeps the system consistent and up to date. Even if some servers fail, the remaining servers can continue to provide uninterrupted service, enabling high availability and resilience in distributed systems.
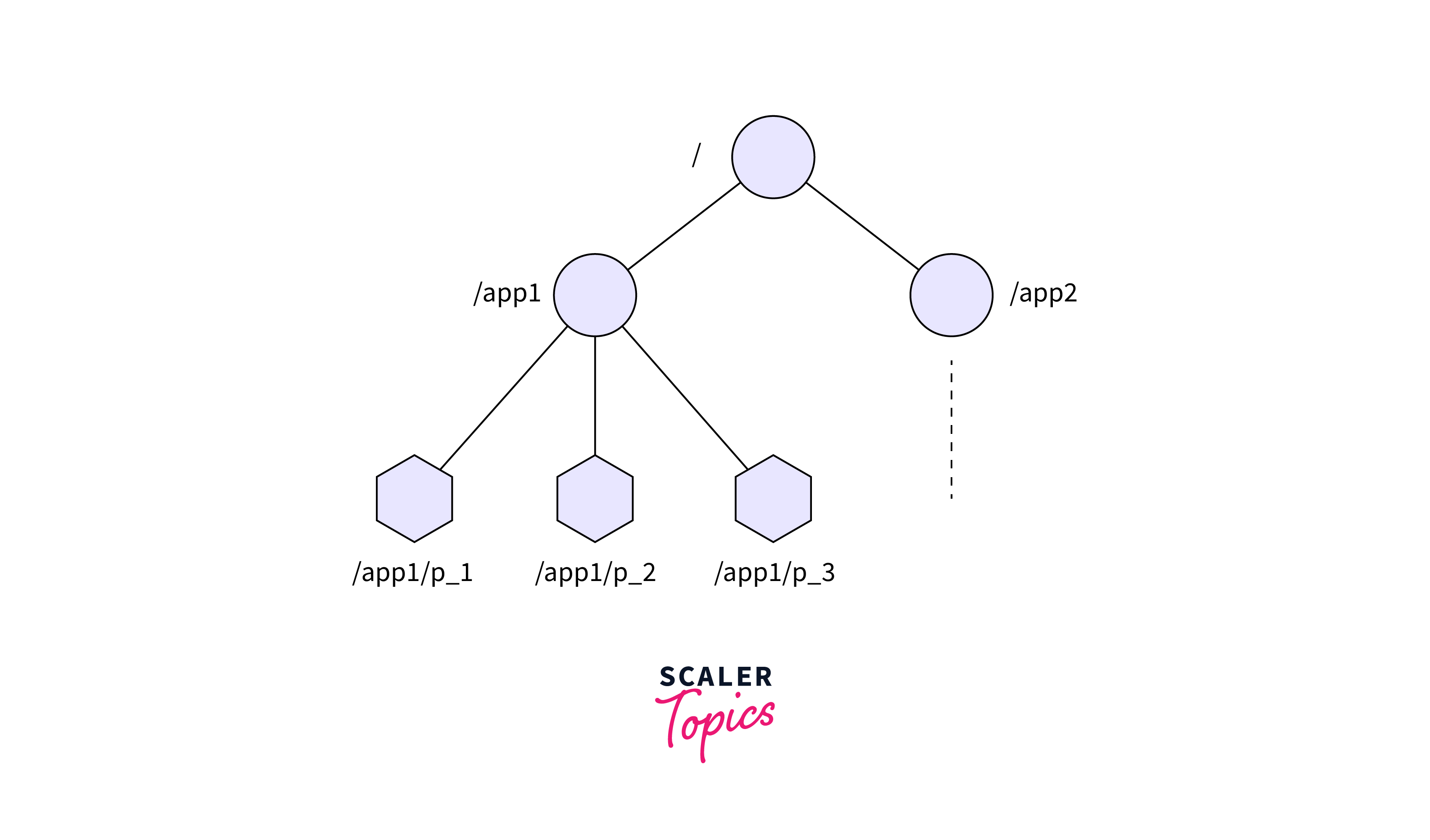
Zookeeper Data Model
ZooKeeper’s data is organized in a hierarchical namespace, analogous to a file system. Each node in the hierarchy, referred to as a znode, represents a distinct path. Developers can construct, read, update, and remove nodes, with changes propagating seamlessly across the ensemble.
The ZooKeeper tree is organized hierarchically where each node is known as a znode, can store data and be assigned a path. This route adheres to Unix file system rules, with slashes (/) separating node names.
For example, if we have a znode called if we have a znode named node1 residing in the root ("/") of the tree, its full path would be /node1.
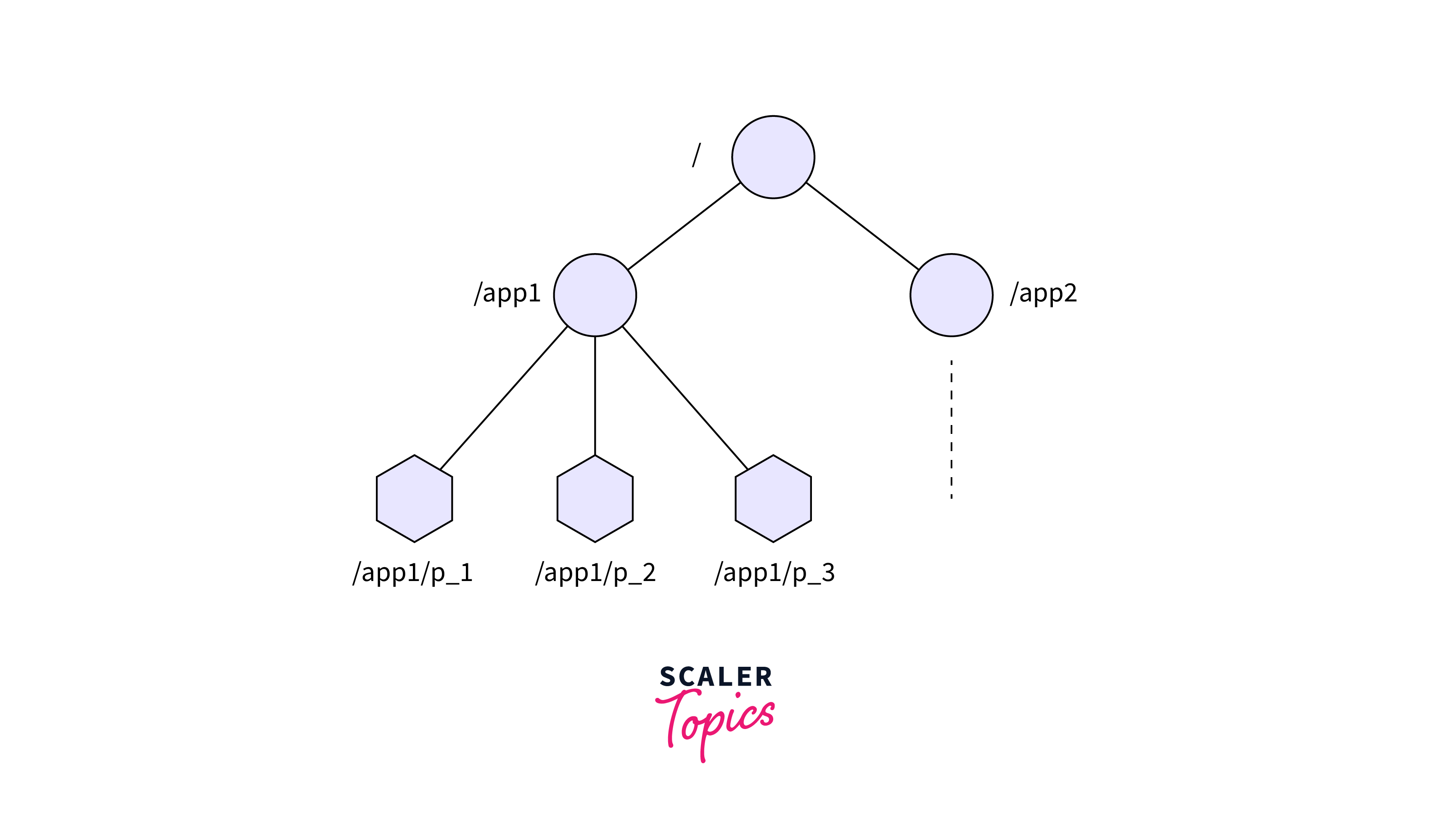
ZooKeeper supports various operations to manipulate and interact with the ZooKeeper tree. These operations include:
- Create: Generates a new znode at a given path, complete with optional data and ACL.
- Read: Retrieves information about a given znode.
- Write: This function updates the data associated with a znode.
- Delete: This command removes a znode from the tree.
- Watch: Allows apps to set watches on znodes, triggering notifications anytime a znode's state changes.
Why do We Need ZooKeeper in Hadoop?
Let us now look at some of the reasons why we need a Zookeeper.
-
Distributed Coordination: ZooKeeper in Hadoop provides a solid basis for distributed coordination, facilitating synchronization and consensus among Hadoop cluster nodes. ZooKeeper enables different components, such as NameNodes, DataNodes, and JobTrackers, to function harmoniously by establishing a single view of the system's state. This coordination avoids disputes and ensures the distributed system runs smoothly.
-
Configuration Management: ZooKeeper excels at managing dynamic setups, allowing for real-time changes to be made across the cluster. ZooKeeper's distributed configuration service enables administrators to alter and disseminate configuration parameters while the cluster remains operational.
-
Leader Election and Failover: ZooKeeper supports leader election, guaranteeing that Hadoop's important components, such as the NameNode, always have a single leader. In a breakdown, ZooKeeper initiates a failover process to elect a new leader, preventing data inconsistency and ensuring ongoing operation. This fault tolerance method decreases the chance of downtime while also providing continuous data availability and enhancing Hadoop's ability to manage huge workloads.
How ZooKeeper in Hadoop Works?
In this section, we'll look at how ZooKeeper works, focusing on the operations of reading and publishing data within Apache ZooKeeper.

-
Reading in ZooKeeper: ZooKeeper adheres to a hierarchical data architecture which is organized in a tree-like structure known as a znode hierarchy. Here, reading entails accessing the znodes to get data. When a client requests data from ZooKeeper, it establishes a connection to a ZooKeeper server and obtains the required information. Because ZooKeeper maintains a uniform view across all connected clients, the client always gets most up-to-date data.
-
Writing in ZooKeeper: Writing in ZooKeeper entails changing or adding znodes to the hierarchy. Clients can store or change data by creating, updating, or deleting nodes. All write requests in the same order. When the write operation is completed, ZooKeeper tells all connected clients of the changes, allowing them to update their views as needed.
Session and Watches
Apache Zookeeper offers features such as Sessions and Watches.
A Session is a transitory connection between a client and the Zookeeper a logical environment for the client to engage with the distributed system. The session guarantees that the client's operations are carried out orderly and consistently, ensuring dependability and fault tolerance. It enables the client to conduct various actions like creating, reading, updating, and deleting data.
Conversely, Watches are event notifications that clients can set on specified Zookeeper ensemble data nodes. The Zookeeper server tells the client ( established the node) when the data associated with a watched node changes. This event-driven technique notifies clients without polling the server continuously. Watches are very useful in cases requiring real-time updates.
Conclusion
- Apache ZooKeeper provides a centralized and highly available service in distributed systems for maintaining configuration information, naming, synchronization, and group services.
- ZooKeeper assures that all clients get the same view of the system state because of its high consistency guarantees.
- The fault-tolerant design of ZooKeeper and its automatic leader election mechanism contribute to its high availability and resilience in the face of failures.
- Apache ZooKeeper has a thriving and active community constantly improving and expanding its features, making it a dependable solution for distributed coordinating needs.
- A Session is a transitory connection between a client and the Zookeeper a logical environment for the client to engage with the distributed system.