Hashing in DBMS

Overview
Hashing is an advantageous technique that tells the exact location of the data using a hash function. For quicker retrieval of data in DBMS hashing technique is vastly used as it does not use the index structure to find the location of desired data.
Hashing in DBMS is classified into two types viz. Static hashing and Dynamic hashing.
What is Hashing in DBMS ?
In huge databases it is very impractical to search all the index values to get the desired data as searching all the index values through all the levels is not an efficient way to reach destination data block to retrieve the desired data.
Therefore, hashing in DBMS is an effective technique used to directly search the location of data without using index structure. It uses a hash function (a mathematical function) to find the exact location of a record in the minimum amount of time.
Before diving deep into the concept, let's have a look at the important terminologies which will be frequently used in the article.
Important Terminologies
-
Data Bucket
Data buckets are the memory locations where the actual data records are stored. -
Hash function
A mathematical function that returns the value of the address of the desired data block. Mostly, it uses the primary key to generate the address of a data block. -
Hash Index
It denotes the address of a data block generated by the hash function. -
Linear Probing
It is used when a record already exists on the memory location calculated by Hash Function. It linearly searches for an empty bucket until it is found. -
Quadratic Probing
It is similar to linear probing with the only difference as it uses an arbitrary polynomial function to search for the next empty bucket instead of searching linearly. -
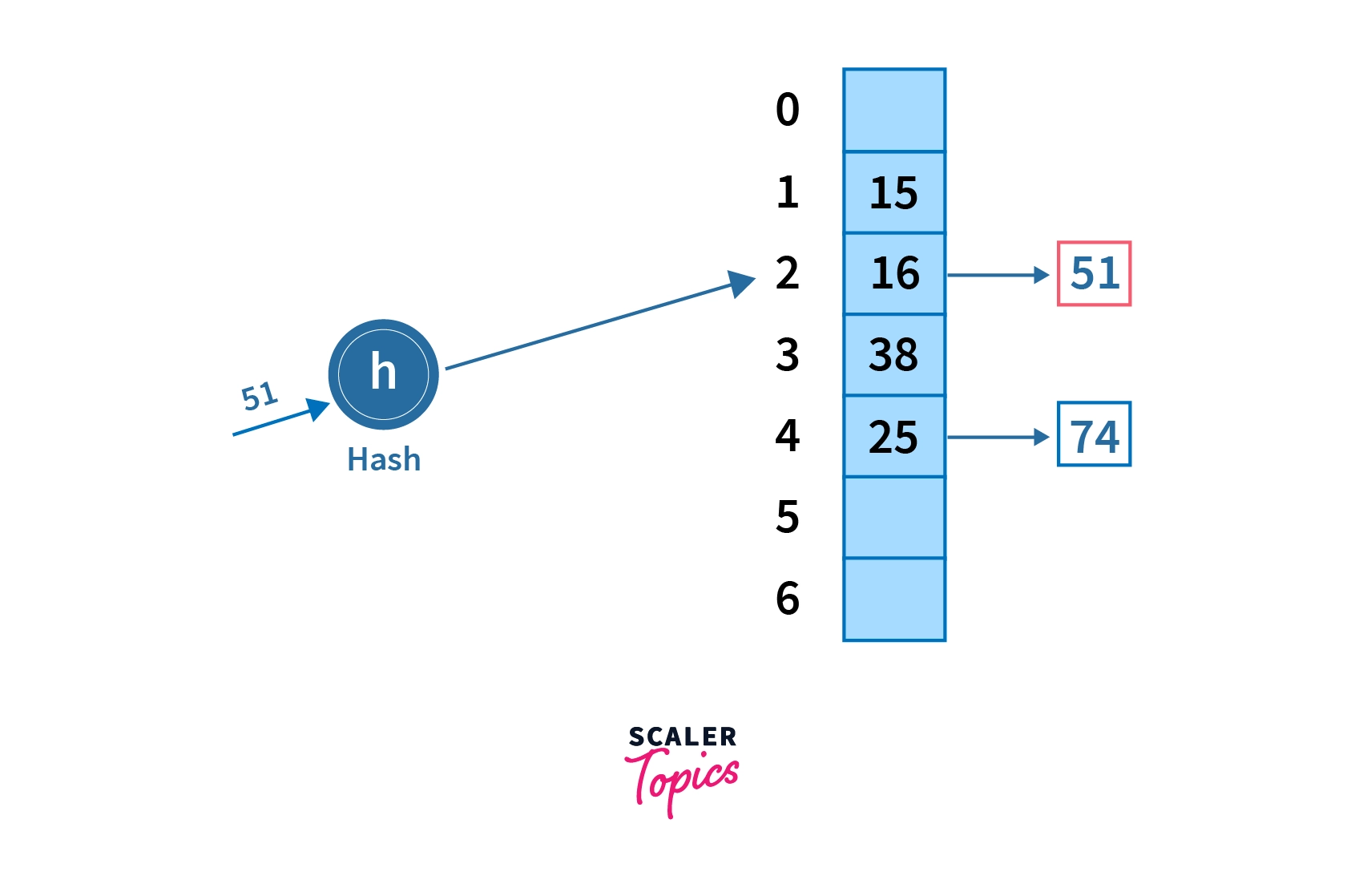
Bucket Overflow
The condition when the memory address generated by the hash function is not empty( it already contains some data record) is known as bucket overflow as shown in the image below -
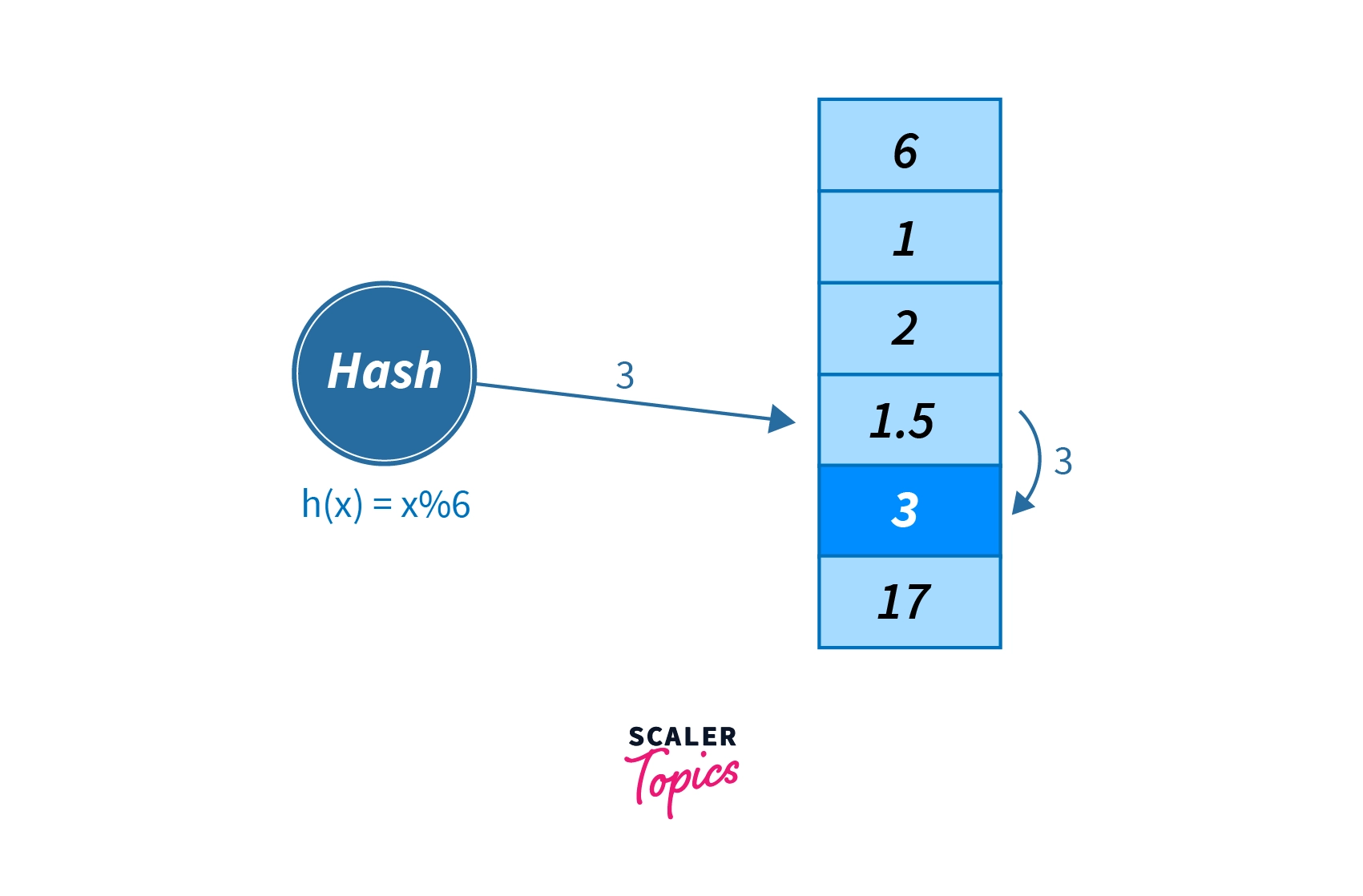
Types of Hashing in DBMS
Hashing techniques can be further divided into two types, static hashing and dynamic hashing.
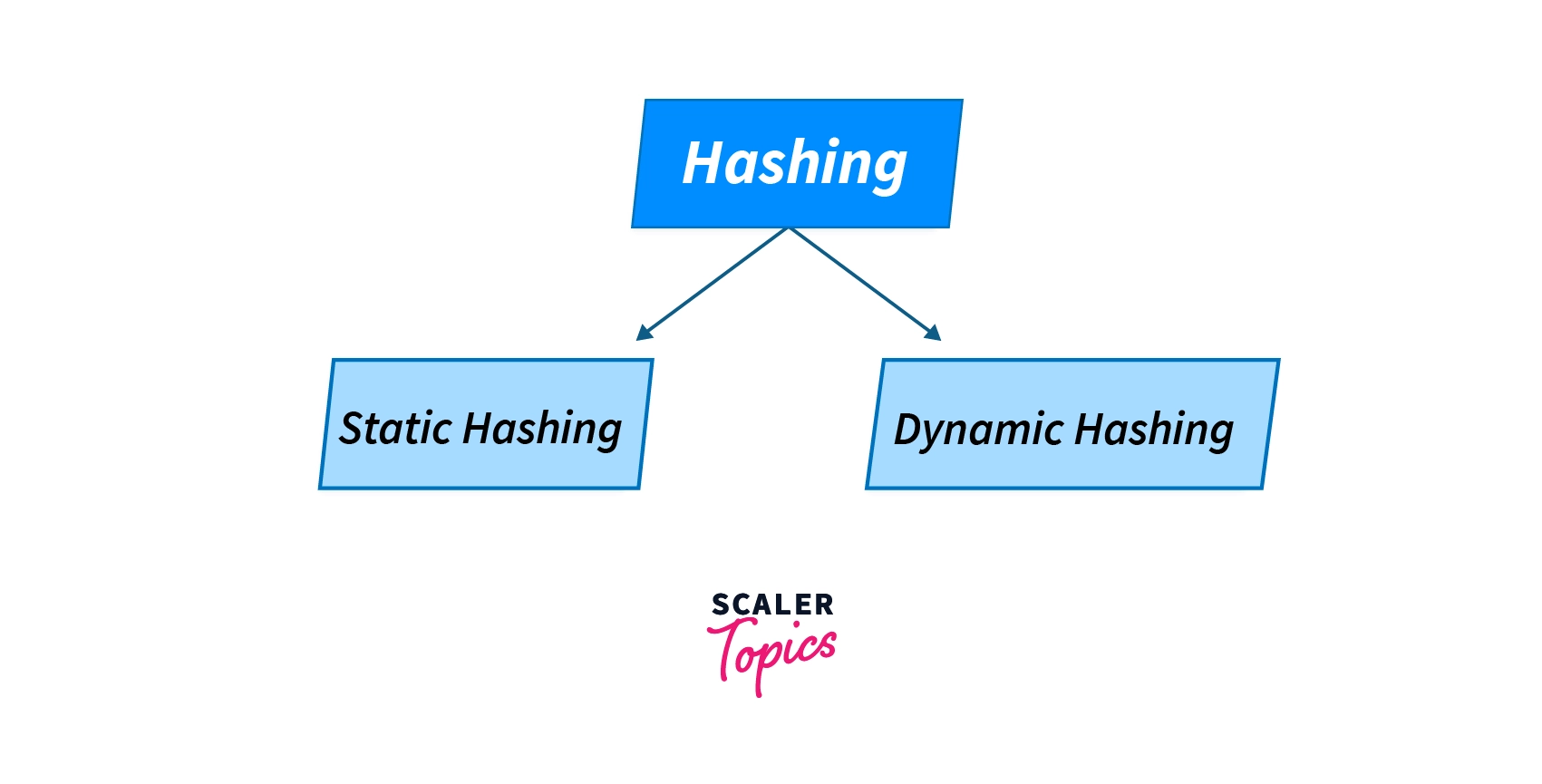
Static Hashing
In static hashing, for a key , hash function always generates the same memory address. For example, if then for any the value will always be the same.
Thus if we generate the address for a key , then will always return the same bucket address, 3. There will be no change in the bucket address. Hence the number of buckets in the memory always remains constant.
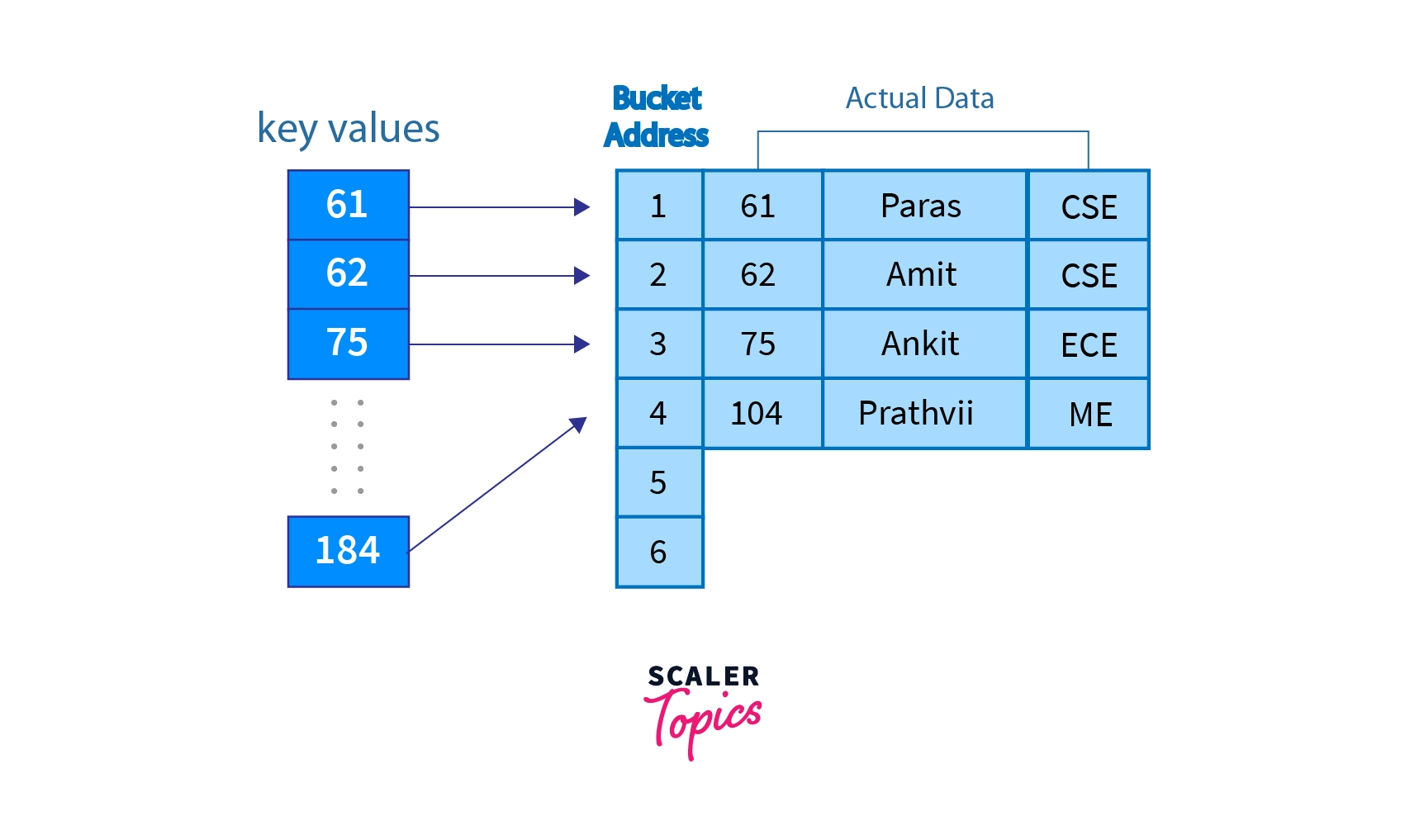
Operations in Static Hashing
- Insertion - To insert a new record in the table we will calculate the bucket address for search key , and the record will be stored there.
- Search - To search a record we will use the same hash function to get the bucket address of the record and retrieve the data from there.
- Deletion - To delete a record from the table we will firstly search for that record and then simply delete it from that location.
Static hashing can also be further divided to open and closed hashing.
Open Hashing
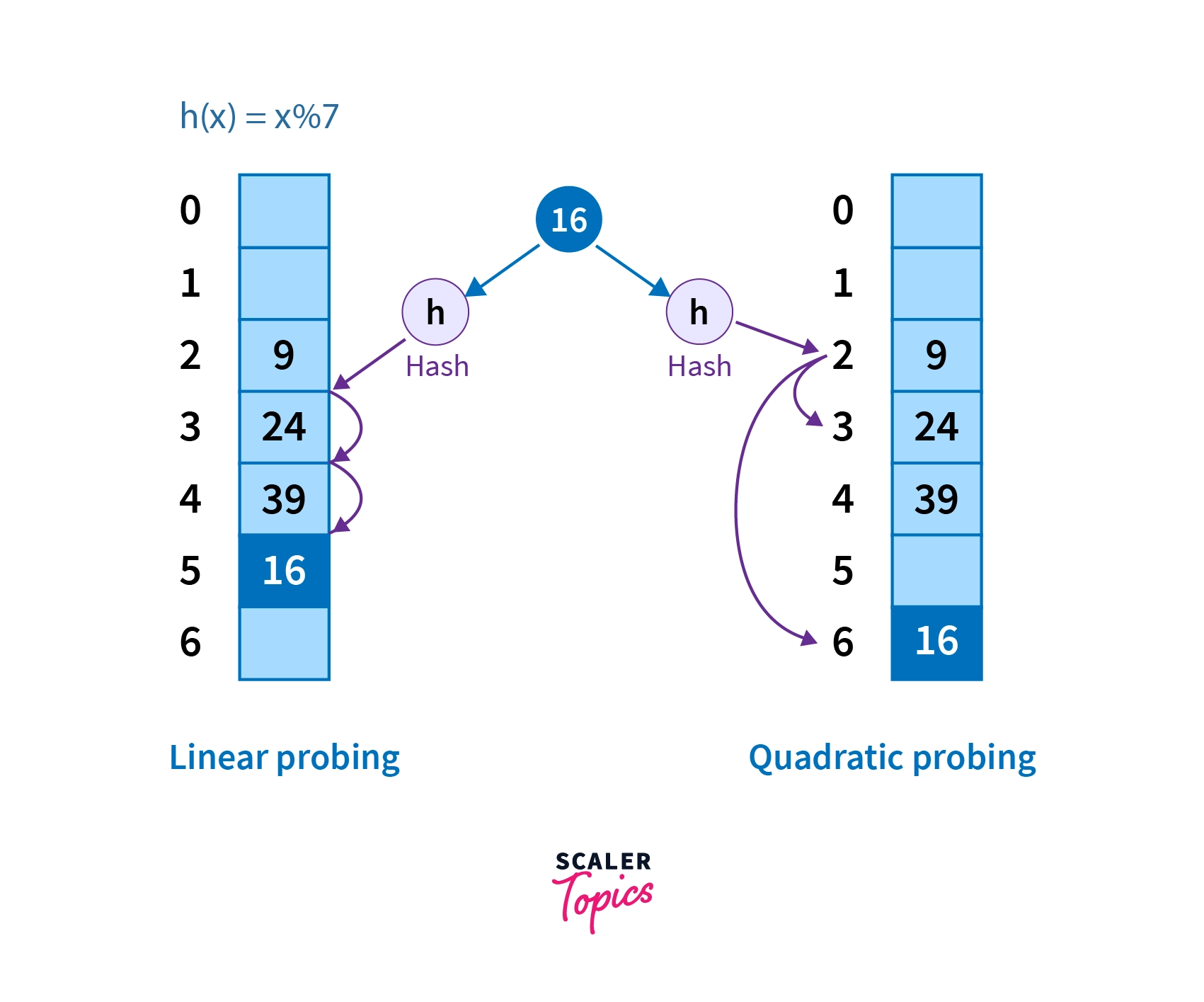
In open hashing, whenever a collision occurs, we probe for the next empty bucket to enter the new record. The order of checking are majorly of two types -
- Linear Probing
- Quadratic Probing
For example -
Closed Hashing
In closed hashing, the collision condition is handled by linking the new record after the previous one, due to which is also termed as "Hashing with separate chaining".
For example -
Dynamic Hashing
The main disadvantage of static hashing is that it does not expand or shrink as the size of the database expands or shrinks.
To counter this problem, we use dynamic hashing which allows on-demand addition and removal of data buckets. It is also known as _extended hashing_. Since this method is dynamic in nature, it always allows efficient insertion and deletion operations.
For example -
Let's say we have to insert records with the following keys as shown in the image given below along with their hash index in binary form.
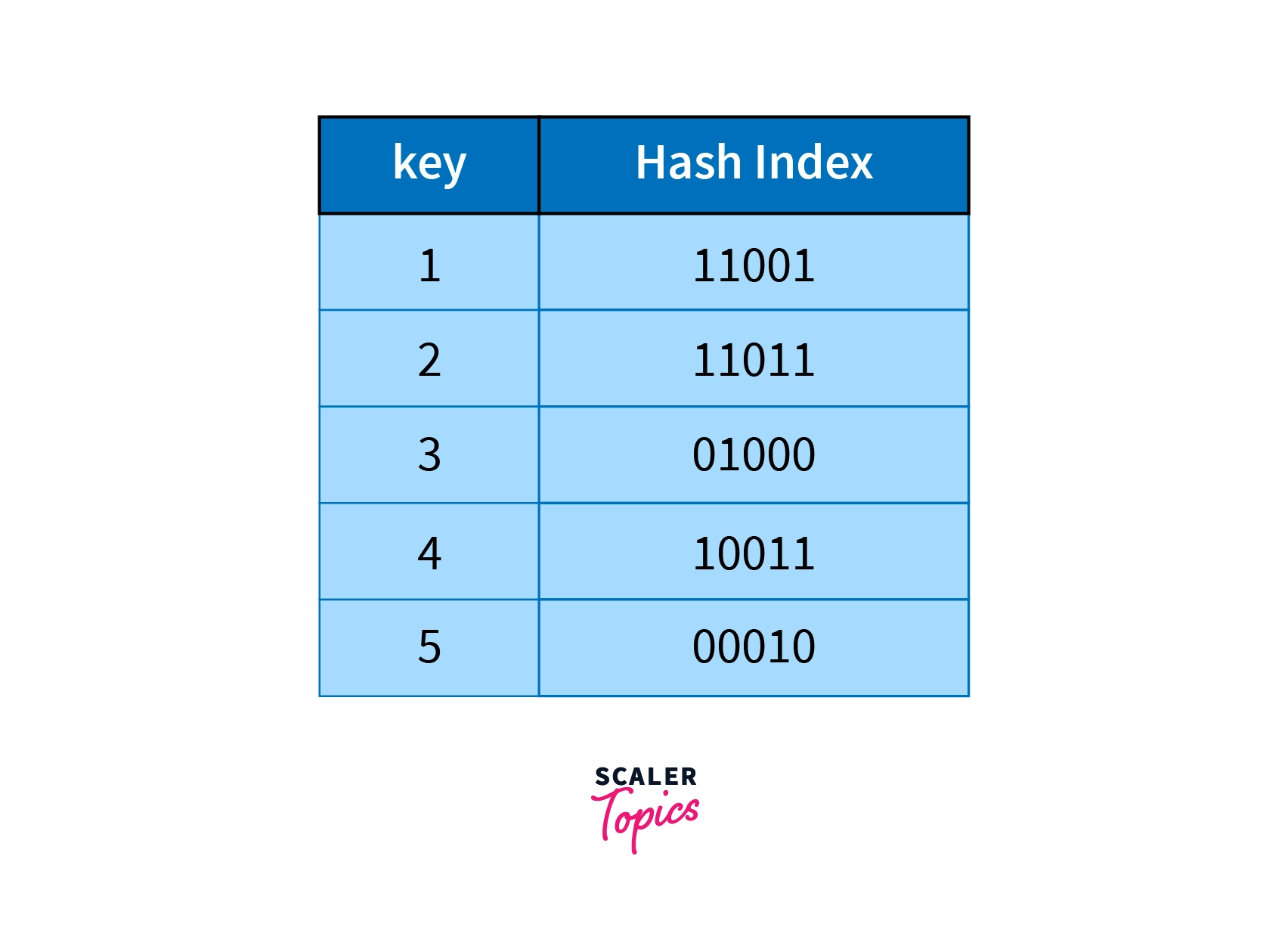
Now, if the global depth is 2 then we will select two LSBs of the hash index. Therefore the obtained values are .
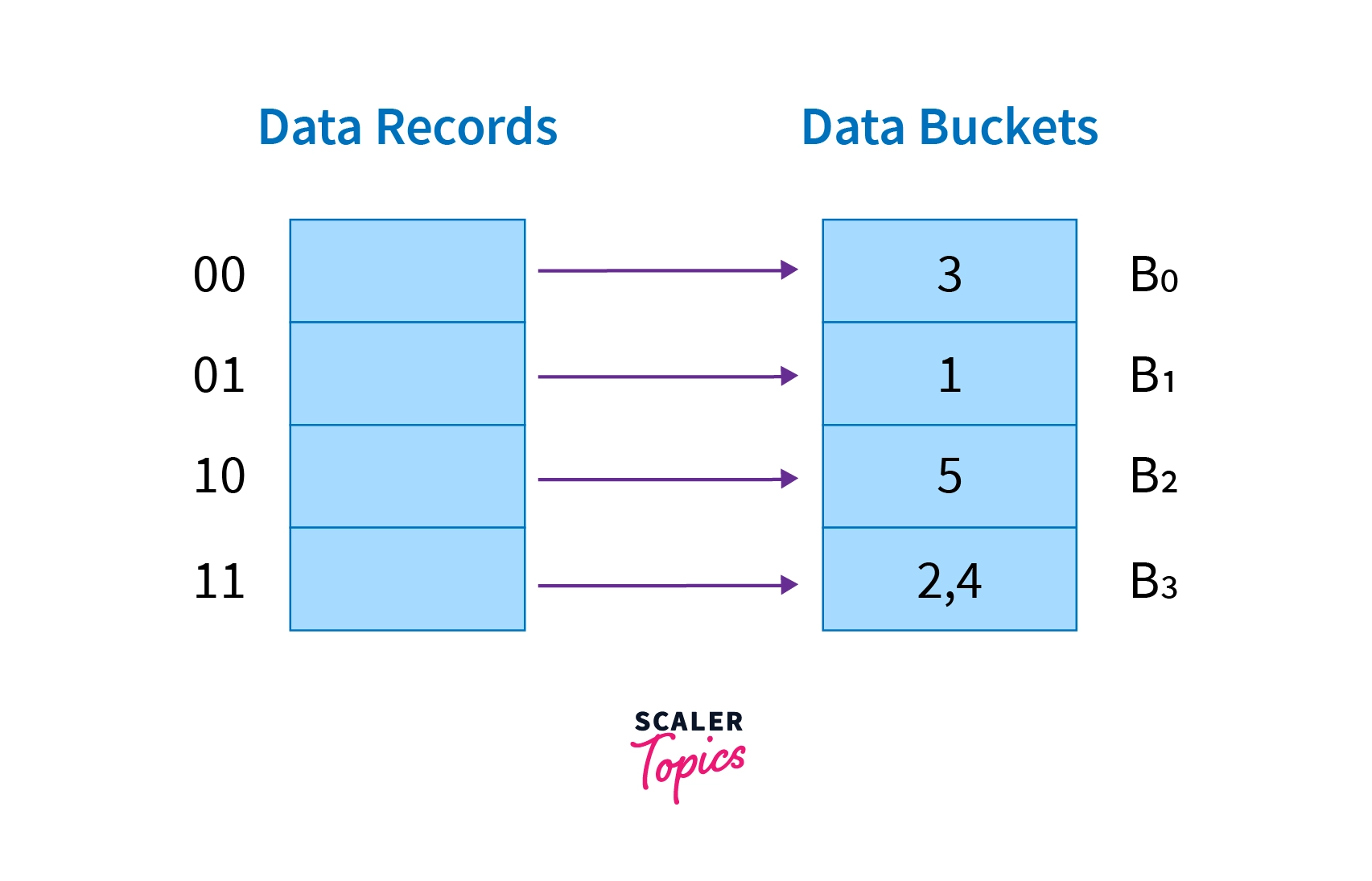
Now we will insert the records accordingly in the buckets with their respective ids as shown below -
Before proceeding with the operations of dynamic hashing let us define two more terminologies -
- Directories - These are the containers that store pointers to the buckets. Each bucket has an "id" associated with them.
- Global depth - Global depth can be defined as the "number of bits in directory id".
Operation in Dynamic Hashing
-
Search -
- Calculate hash address of the record based on the primary key of the record.
- Convert hash address into binary form, let's say we have 13 as hash address then its binary form is .
- Select LSBs from the binary form, where is the global depth of the directory. If then we select
1101. - Now navigate to the bucket with directory id and search the record.
-
Insertion -
- Repeat the first three steps of the searching procedure, getting and converting the hash address in binary form and then selecting LSBs from it.
- Now, go to the bucket with the obtained address and insert the record there.
-
Deletion -
- Again repeat the first 3 steps of the searching procedure.
- Now go to the bucket with the obtained address and delete the record from there.
Conclusion
-
Hashing is an efficient process used in DBMS for quick retrieval of the data.
-
There are two types of hashing in DBMS, Static hashing and Dynamic hashing.
-
Static hashing can be further classified to open hashing and closed hashing.
-
Dynamic hashing is more advantageous than static hashing because it can expand or shrink with the size of the database.