HashSet vs TreeSet in Java

Overview
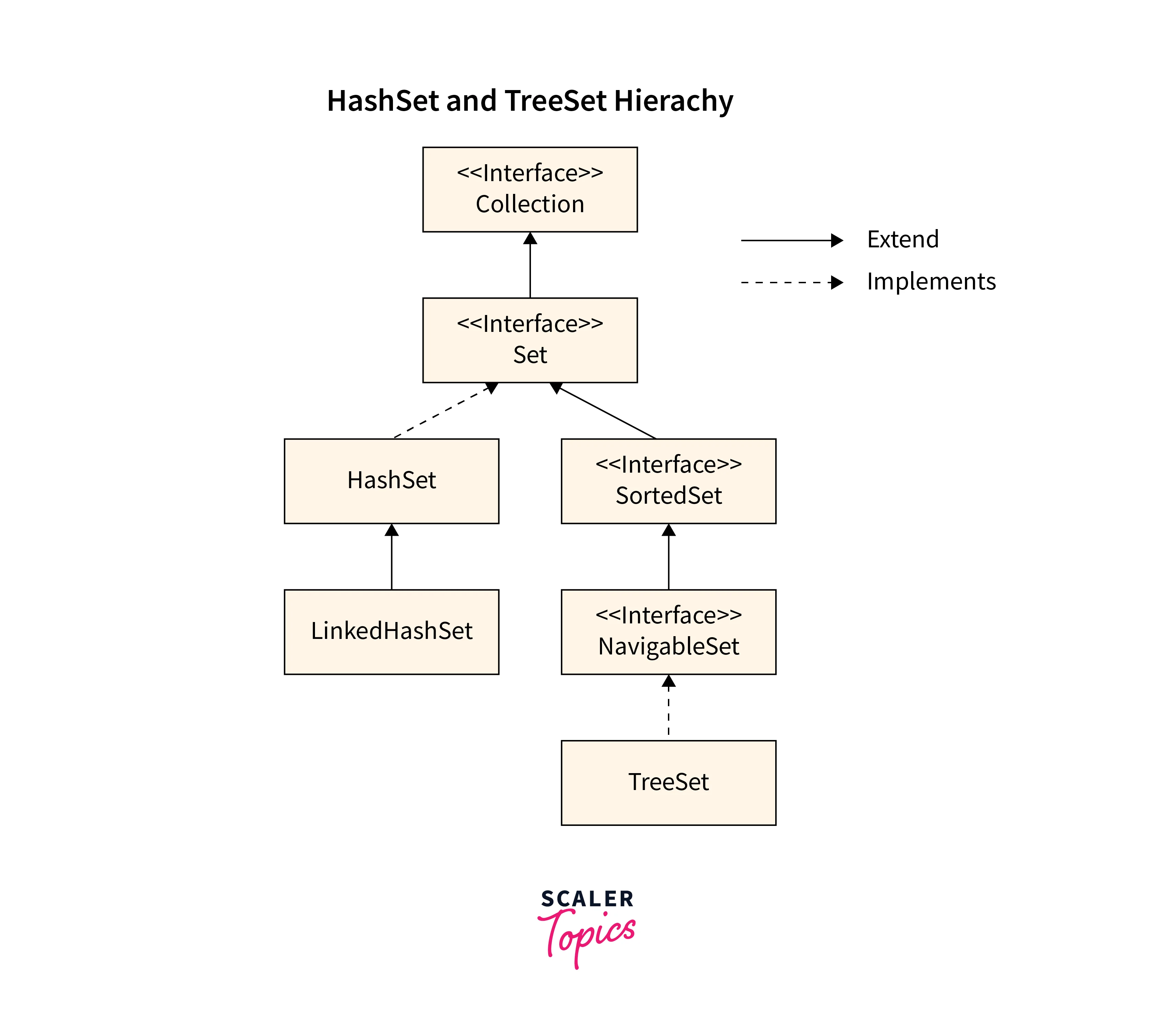
HashSet vs TreeSet are the two most popular Java implementations of the java.util.Set interface. To understand the difference between these two we must first understand how these two process elements. HashSet is a Java class implementing a Set interface and hash function, a HashMap instance. Due to the hash table, all operations' insertion, deletion, search, and size can be performed in constant time, i.e., time. In contrast, TreeSet implements the SortedSet interface, which allows storing data elements in a tree in sorted order.
Difference between HashSet and TreeSet in Java
Let us compare HashSet vs TreeSet
| Feature | HashSet | TreeSet |
|---|---|---|
| Ordering | No specific order. | Elements are sorted (in natural order or based on a comparator). |
| Null Values | Allows one null element. | Does not allow null elements. |
| Duplicates | Does not allow duplicate elements. | Does not allow duplicate elements. |
| Implementation | Implemented using a hash table. | Implemented as a navigable set backed by a TreeMap. |
| Performance (Average Case) | O(1) for insertion, deletion, and retrieval. | O(log N) for insertion, deletion, and retrieval due to the underlying TreeMap structure. |
| Memory Usage | Typically uses less memory than TreeSet. | Uses more memory than HashSet due to the additional overhead of maintaining a sorted order. |
| Iterating Over Elements | Order is not guaranteed during iteration. | Iteration is in sorted order. |
| Use Cases | General-purpose set when order is not important and fast access is needed. | When elements need to be maintained in a sorted order or a custom sorting logic is required. |
| Implementation Notes | Relies on the hashCode() and equals() methods of objects for fast retrieval. | Relies on the compareTo() or a custom comparator for sorting elements. |
| Concurrency | Not synchronized. For concurrent access, external synchronization is required. | Not synchronized. For concurrent access, external synchronization is required. |
HashMap uses a hash table which is usually larger as compared to the number of values in it. This helps in time complexity for most of the operations. Now in case the number of elements increases and the table causes more collisions then, this table needs to be resized.
This resizing requires all the values to be placed again in the new table. This leads to less effectiveness of the hashtable. Thus, it is advisable to declare the size of the HashSet initially. There is no such complexity in the case of TreeSet.
In summary, choose HashSet when order doesn't matter, and you need fast constant-time operations. Use TreeSet when you need elements sorted and can tolerate the added overhead of logarithmic time complexity.
HashSet
HashSet implements AbstractSet and the Set interfaces. HashSet uses a hash table and hashing mechanism for storage.
Based on the value to be inserted inside a HashSet a hash code is calculated to determine the index to store the value. All the operations in HashSet such as insertion, deletion, updation, search, etc. can be performed in constant i.e. time complexity.
The HashSet doesn't guarantee the order of the elements. HashSet allows a null value but duplicates are not allowed in HashSet.
Let us look at an example of HashSet.
Output:
As we can see in the above example, the order of elements is not fixed and can be different from the order of insertion. Duplicate elements are not stored twice in a HashSet.
Learn more about HashSet here.
TreeSet
TreeSet class in Java implements Set, NavigableSet, and SortedSet interfaces and extends the collection framework of Java.
Elements are stored in their natural sorted order in TreeMap. We can pass a custom comparator to sort the elements in some different order. It is slower than HashSet as it stores the elements in a tree.
Storing, Deleting, and Searching of elements is done in time complexity. It is useful in cases where we want the elements in a specific order only. It internally uses a self-balancing Binary Search Tree (BST).
The null value is not allowed in TreeSet. It also doesn't store duplicates. Only one copy is stored rest are discarded.
Let us look at an example of a TreeSet in Java.
Output:
Thus, it stores the values in ascending order only. We can check if some value is present in the Set.
Which One is Better to Use?
HashSet vs TreeSet implementations are very useful in Java Programming. It typically depends on the use case. If the understanding of both data structures is good, one can accurately define where to use which one. And as programmers, the prime task is to utilize the right tool at the right place.
Let us understand in detail in which cases we can use TreeSets and HashSets.
HashSet
- If we want faster access and the order of the elements matters least to us, we must use HashSet.
- Also, HashSet uses more memory than TreeSet so memory constraint must not be a factor if you wish to use the HashSet.
- HashSet is mostly used to store unique entries that are to be accessed again and again.
- There is a scope of performance tuning in the HashSet using the initialCapacity and loadFactor which is not possible in TreeSet.
TreeSet
- TreeSet is useful for storing data that needs to be frequently sorted or searched within a range.
- Also, for some situations where we don't wish to have null values then TreeSet is helpful.
- TreeSet provides navigation methods that allow you to find the closest elements (greater, less than, etc.), making it suitable for scenarios where you need to perform range queries.
- TreeSet is often used in scenarios where you need to implement sorted sets or sorted maps.
Conclusion
- HashSet vs TreeSet both are important. HashSet uses a hash function to calculate the index in the Hash table to store the given value.
- TreeMap uses a Binary Search Tree to store the given values in sorted order.
- HashMap consumes contact time and is faster than TreeMap as it takes time for basic operations such as searching, inserting, and deleting.
- Both the sets just like mathematical sets don't allow duplicate values.
- HashMaps are used where we want unique elements and faster access. Whereas TreeSet is used to find the closest value to the given value such as minimum greatest element, element in a given range, etc.